
LangChain Structured Output: A Guide to Tools and Methods


The most popular LangChain tools for getting structured outputs are:
- `.with_structured_output`, a class method that uses a schema like JSON to guide the structure and format of a language model’s response.
- `PydanticOutputParser` that parses raw LLM text and uses a Pydantic object to extract key information.
- `StructuredOutputParser` which extracts information from LLM responses according to a schema like a Python dictionary or JSON schema.
These tools modify or guide LLM responses to simplify further processing by other systems or applications.
For example, if you needed to extract a JSON object containing fields for “name," "date," and "location” out of the model’s response, you could use `StructuredOutputParser` to ensure the model’s output adheres to the specific schema.
LangChain’s extensive set of off-the-shelf parsers gives you a tool for many different use cases. That said, some of the outputs of these tools — like runnables — introduce a fair amount of complexity as they require you to learn new, LangChain-specific abstractions.
For this reason we built our own lightweight toolkit for working with LLMs, Mirascope, for specifying structured outputs using the Python you already know rather than having to use new, complex abstractions required by the big frameworks.
In this article, we describe useful ways of working with LangChain to get structured outputs, and compare these with how you’d do them in Mirascope.
How to Get Structured Outputs in LangChain
Although LangChain offers many different kinds of off-the-shelf parsers, most developers find the following three tools to be particularly useful:
This class method takes an input schema to guide the LLM to generate specific responses.
You can only use this with LLMs that provide APIs for structuring outputs, such as tool calling or JSON mode (this means it only works for providers like OpenAI, Anthropic, Cohere, etc.).
If the model doesn’t natively support such features, you’ll need to use an output parser to extract the structured response from the model output.
You typically use `with_structured_output` to specify a particular format you want the LLM to use in its response, passing this format as schema into the prompt.
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
# Instantiate the LLM model
model = ChatOpenAI(model="gpt-4o-mini", temperature=0)
class Trivia(BaseModel):
question: str = Field(description="The trivia question")
answer: str = Field(description="The correct answer to the trivia question")
# Define the prompt template
prompt = ChatPromptTemplate.from_template(
"Give me a trivia question about {topic}, respond in JSON with `question` and `answer` keys"
)
# Create a structured LLM using the `with_structured_output` method
structured_llm = model.with_structured_output(Trivia, method="json_mode")
# Chain the prompt and structured LLM using the pipe operator
trivia_chain = prompt | structured_llm
# Invoke the chain
result = trivia_chain.invoke({"topic": "space"})
# Output
Trivia(question='What is the largest planet in our solar system?', answer='Jupiter')
Here, we define `Trivia` as a Pydantic model whose definition and fields we want the model’s output to follow. To ensure the output is returned as a JSON object, we use the `method="json_mode"` argument in `with_structured_output`.
Thanks to Pydantic’s built-in validation, if the LLM’s output doesn’t match Trivia’s structure (e.g., missing fields or incorrect types), the Pydantic model will raise an error at runtime.
`with_structured_output` also wraps the LLM call in a runnable that binds the LLM to the output schema defined by the `Trivia` model.
This runnable allows us to later combine `prompt` and `structured_llm` into a chain using LangChain’s pipe moderator (`|`).
When it comes to runnables, such workflows offer certain conveniences, like handling concurrency with methods such as `async`, `await`, and `astream`. But runnables become harder to manage and debug in more sophisticated scenarios, like when you need to add more components to chained calls.
That’s because runnables are LangChain-specific abstractions that come with their own learning curve. They’re part of LangChain expression language (LCEL), which uses them to define and execute workflows. But all this adds overhead to understanding what’s going on under the hood, and stands in contrast to Mirascope’s pythonic approach to constructing chains.
Finally, the schema you provide to `with_structured_output` can be a `TypeDict` class, JSON schema, or a Pydantic class (note that LLM outputs in all three cases below are ultimately returned to the user by the runnable):
- If providing `TypedDict` or JSON schema, the model's output will be structured as a dictionary.
- If a Pydantic class is used, the model’s output will be a Pydantic object.
- When using a JSON schema dictionary, the model’s output will be a dictionary.
Streaming from Pydantic models is also supported for outputs of type `dict` (such as `TypedDict` or a JSON schema dictionary).
Not all models support tool calling and JSON mode, so another approach for getting structured outputs is to use an output parser like `PydanticOutputParser` to extract the needed information.
This parser works best in situations where type safety is an obvious concern, as it ensures that LLM responses adhere strictly to a Pydantic model schema.
This parser also implements the LangChain runnable interface.
Below, we use `PydanticOutputParser` to specify a `Book` schema to ensure the title in the LLM’s output is a string and the number of pages an integer:
from typing import List
from langchain_core.output_parsers import PydanticOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
class Book(BaseModel):
"""Information about a book."""
title: str = Field(..., description="The title of the book")
pages: int = Field(
..., description="The number of pages in the book."
)
class Library(BaseModel):
"""Details about all books in a collection."""
books: List[Book]
# Set up a parser
parser = PydanticOutputParser(pydantic_object=Library)
# Prompt
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"Answer the user query. Wrap the output in `json` tags\n{format_instructions}",
),
("human", "{query}"),
]
).partial(format_instructions=parser.get_format_instructions())
# Query
query = "Please provide details about the books 'The Great Gatsby' with 208 pages and 'To Kill a Mockingbird' with 384 pages."
# Print the prompt and output schema
print(prompt.invoke(query).to_string())
System: Answer the user query. Wrap the output in `json` tags
The output should be formatted as a JSON instance that conforms to the JSON schema below.
As an example, for the schema {"properties": {"foo": {"title": "Foo", "description": "a list of strings", "type": "array", "items": {"type": "string"}}}, "required": ["foo"]}
the object {"foo": ["bar", "baz"]} is a well-formatted instance of the schema. The object {"properties": {"foo": ["bar", "baz"]}} is not well-formatted.
# Output schema
{
"type": "object",
"properties": {
"books": {
"type": "array",
"items": {
"type": "object",
"properties": {
"title": {
"type": "string",
"description": "The title of the book"
},
"pages": {
"type": "integer",
"description": "The number of pages in the book."
}
},
"required": ["title", "pages"]
}
}
},
"required": ["books"]
}
Human: Please provide details about the books 'The Great Gatsby' with 208 pages and 'To Kill a Mockingbird' with 384 pages.
Next, we invoke the chain:
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(temperature=0)
chain = prompt | llm | parser
chain.invoke({"query": query})
The output conforms to the schema defined by `Library`, with the `books` list containing two `Book` objects, each with a `title` and `pages` field. The JSON tags would be added based on the instructions given in the prompt.
{
"books": [
{
"title": "The Great Gatsby",
"pages": 218
},
{
"title": "To Kill a Mockingbird",
"pages": 281
}
]
}
The parser raises a validation error if the output doesn’t match the expected structure or data types.
This parser works with many different language models and uses a `ResponseSchema` object defined by you to extract key information from the model’s response. It’s especially useful when out-of-the-box parsers don’t handle the structure you need.
Each `ResponseSchema` corresponds to a key-value pair and has the following structure:
- Name: The key or field name expected in the output
- Description: A brief explanation of what this field represents
- Type: The data type expected for this field, such as `string`,` integer`, or `List[string]`
Below is an example of using `StructuredOutputParser` to ask for a recipe and ingredients list for Spaghetti Bolognese.
We first define two `ResponseSchema` objects, one for `recipe` and the other for `ingredients`, both of which are expected to be strings.
from langchain.output_parsers import ResponseSchema, StructuredOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
# Define the schema for the expected output, including two fields: "recipe" and "ingredients"
response_schemas = [
ResponseSchema(name="recipe", description="the recipe for the dish requested by the user"),
ResponseSchema(
name="ingredients",
description="list of ingredients required for the recipe, should be a detailed list.",
),
]
# Create a StructuredOutputParser instance from the defined response schemas
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)
# Generate format instructions based on the response schemas, which will be injected into the prompt
format_instructions = output_parser.get_format_instructions()
# Define the prompt template, instructing the model to provide the recipe and ingredients
prompt = PromptTemplate(
template="Provide the recipe for the dish requested.\n{format_instructions}\n{dish}",
input_variables=["dish"],
partial_variables={"format_instructions": format_instructions},
)
model = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# Create a chain that connects the prompt, model, and output parser
chain = prompt | model | output_parser
# The output will be structured according to the predefined schema with fields for "recipe" and "ingredients"
chain.invoke({"dish": "Spaghetti Bolognese"})
We then create the `StructuredOutputParser` using the defined `response_schemas` to ensure the LLM’s output conforms to the structure defined by the schemas.
We also specify `format_instructions` based on the `StructuredOutputParser` created previously to tell the language model how to format its response so this matches the structure defined by the `ResponseSchema` objects.
Our prompt template then asks the language model to provide a recipe and the list of ingredients for a specified dish, and includes the format instructions we previously specified.
Lastly, we create a chain (which returns a runnable) using the pipe moderator and invoke it to run, receive, and parse the response according to our defined schemas:
{
"recipe": "To make Spaghetti Bolognese, cook minced beef with onions, garlic, tomatoes, and Italian herbs. Simmer until thickened and serve over cooked spaghetti.",
"ingredients": "Minced beef, onions, garlic, tomatoes, Italian herbs, spaghetti, olive oil, salt, pepper."
}How to Get Structured Outputs in Mirascope (Differences Versus LangChain)
While LangChain offers specialized tools for extracting structured outputs, Mirascope’s approach emphasizes simplicity and the use of familiar Python constructs.
Our structured output tools are also tightly integrated with Pydantic, unlike in LangChain, which relies on specialized abstractions like `PydanticOutputParser`, or wrapping Pydantic models in runnables.
Output Parsing in Mirascope
In Mirascope you write output parsers as Python functions that work together with call decorators, which you can add to any function to turn it into an LLM API call. Call decorators let you easily switch between models or compare different outputs, since our decorators work with a growing list of providers.
Like LangChain, we support OpenAI’s JSON mode and structured outputs (for both JSON schema and tools).
The code below shows a custom output parser where we extract outputs against `Movie` and add a decorator to call Anthropic for our prompt.
from mirascope.core import anthropic, prompt_template
from pydantic import BaseModel
class Movie(BaseModel):
title: str
director: str
def parse_movie_recommendation(response: anthropic.AnthropicCallResponse) -> Movie:
title, director = response.content.split(" directed by ")
return Movie(title=title, director=director)
@anthropic.call(
model="claude-3-5-sonnet-20240620", output_parser=parse_movie_recommendation
)
@prompt_template("Recommend a {genre} movie in the format Title directed by Director")
def recommend_movie(genre: str):
...
movie = recommend_movie("thriller")
print(f"Title: {movie.title}")
print(f"Director: {movie.director}")
Note that we pass `output_parser` as an argument in the call decorator to change the decorated function’s return type to match the parser’s output type. While you could run the output parser on the output of the call, by including it in the decorator you ensure it runs every time the call is made. This is extremely useful since the output parser and prompt are ultimately tightly coupled.
Notice we also separate the prompt instructions from the prompt function by implementing the instructions as a `@prompt_template` decorator. These decorators are particularly useful for creating consistent prompts across multiple calls and for easily modifying prompt structures
It also separates prompt logic from specific functions like output parsing, which improves code reusability and maintainability.
Below are some additional ways in which Mirascope works differently than LangChain:
Documentation and Linting for Your IDE
As part of good coding practices, Mirascope provides type hints for function return types and variables to support your workflows by (for example) flagging missing arguments:
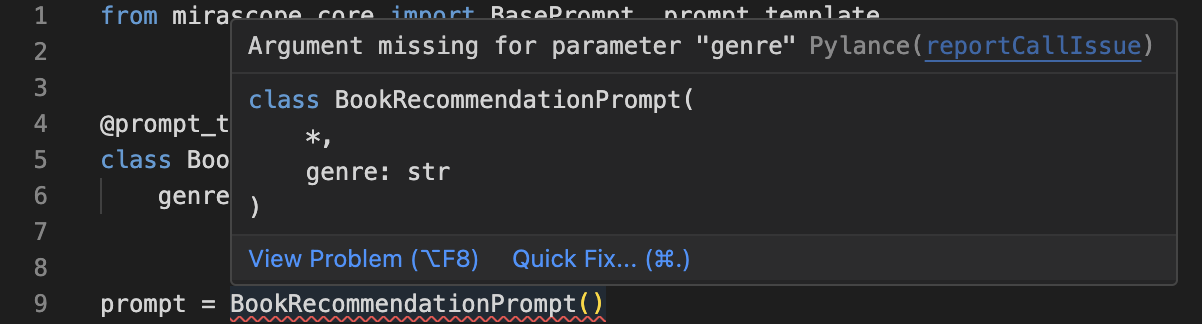
This aspect of type safety is available for all functions and classes defined in Mirascope, including output parsers and response models (discussed later on).
We also offer auto suggestions:
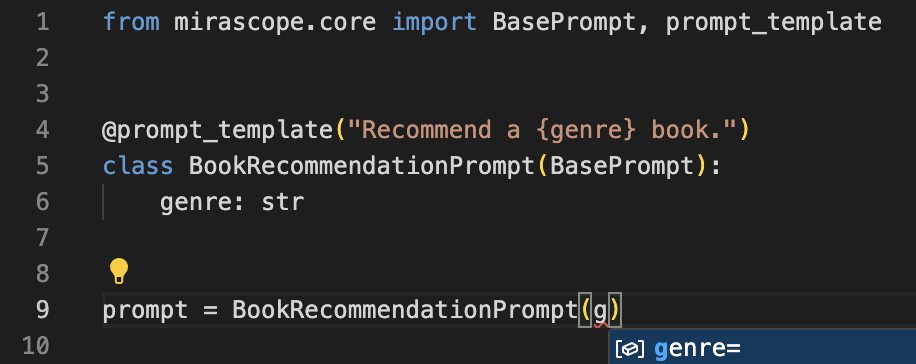
This is handy for catching errors without even needing to run your code, and is an aspect of Mirascope’s promotion of best coding practices.
Pydantic V2
Pydantic is critical middleware for ensuring the integrity of structured outputs, and Mirascope fully supports V2, which was released in July, 2023. Note that Pydantic V2 isn’t backwards compatible with V1.
This is in contrast to LangChain, which relies on V1. A few of the new release’s features include:
- Implementation in Rust — known for its performance, strong memory safety, and extensibility
- Simplified custom validators
Support for generic types, asynchronous validation, type hints, improved data validation, and more
Specifying Language Model Outputs with Response Models
Mirascope’s `response_model` lets you define the type of responses that you want to receive from the LLM.
It’s based on a Pydantic model that you specify, such as `Recipe` below. Once you’ve defined the model against which to extract the output, you insert the model name into the argument of the call decorator as `response_model` in order to specify the LLM’s return type:
from mirascope.core import openai, prompt_template
from pydantic import BaseModel
class Recipe(BaseModel):
dish: str
chef: str
@openai.call(model="gpt-4o-mini", response_model=Recipe)
@prompt_template("Recommend a {cuisine} dish")
def recommend_dish(cuisine: str):
...
dish = recommend_dish("Italian")
assert isinstance(dish, Recipe)
print(f"Dish: {dish.dish}")
print(f"Chef: {dish.chef}")
This automatically validates and structures the LLM’s output according to your predefined model, making the output easier to integrate into your application logic.
As with LangChain’s `.with_structured_output` method, Mirascope response models pass Pydantic models and configuration settings into the LLM to guide it towards the desired responses.
Below, we describe a few of the most convenient settings available for response models.
Returning Outputs in Valid JSON
Setting `json_mode=True` in the call decorator will apply JSON mode — if it’s supported by your LLM — rendering the outputs as valid JSON:
import json
from mirascope.core import openai, prompt_template
@openai.call(model="gpt-4o-mini", json_mode=True)
@prompt_template(
"""
Provide the following details about the movie {movie_title}:
- director
- release year
- main genre
""")
def get_movie_info(movie_title: str):
...
response = get_movie_info("Inception")
print(json.loads(response.content))
# > {"director": "Christopher Nolan", "release_year": "2010", "main_genre": "Science Fiction"}
Adding Few-Shot Examples to Response Models
Mirascope response models also let you add few-shot examples as shown below, where we add `examples` arguments in the fields of `Destination`:
from mirascope.core import openai, prompt_template
from pydantic import BaseModel, ConfigDict, Field
class Destination(BaseModel):
name: str = Field(..., examples=["KYOTO"])
country: str = Field(..., examples=["Japan"])
model_config = ConfigDict(
json_schema_extra={
"examples": [
{"name": "KYOTO", "country": "Japan"}
]
}
)
@openai.call("gpt-4o-mini", response_model=Destination, json_mode=True)
@prompt_template("Recommend a {type} travel destination. Match example format.")
def recommend_destination(type: str): ...
destination = recommend_destination("cultural")
print(destination)
# > name='PARIS' country='France'
Streaming Response Models
You can also stream response models by setting `stream=True` in the call decorator so it returns an iterable.
from mirascope.core import openai, prompt_template
from pydantic import BaseModel
class City(BaseModel):
name: str
population: int
@openai.call(model="gpt-4o-mini", response_model=City, stream=True)
@prompt_template("Extract {text}")
def describe_city(text: str): ...
city_stream = describe_city("Tokyo has a population of 14.18 million")
for partial_city in city_stream:
print(partial_city)
# > name=None population=None
# name=None population=None
# name='' population=None
# name='Tokyo' population=None
# name='Tokyo' population=None
# name='Tokyo' population=None
# name='Tokyo' population=None
# name='Tokyo' population=141
# name='Tokyo' population=141800
# name='Tokyo' population=14180000
# name='Tokyo' population=14180000
# name='Tokyo' population=14180000
# name='Tokyo' population=14180000Generate Structured Outputs with Ease and Consistency
Mirascope’s close integration with Pydantic, along with its use of Pythonic conventions, allow you to code using the Python you already know, rather than trying to make sense of new abstractions and complex frameworks. This makes generating structured outputs simpler and more intuitive.
Want to learn more about Mirascope’s structured output tools? You can find Mirascope code samples both on our documentation site and the GitHub repository.