After testing several libraries, and even building our own, we’ve figured out what makes a great prompt engineering tool. It should:
* **Track prompt versions and log every LLM call automatically**, so you don’t waste time doing it by hand. That way, you can tweak, test, and compare results with confidence.
* **Keep your code organized**, so every change to your prompts, logic, or model behavior is easy to trace and understand.
* **Make it easy for non-developers to review outputs**, add labels, and give feedback in a prompt editor or playground while keeping prompts tightly integrated with code, so developers can run exactly what’s tested in the playground without relying on brittle, decoupled systems.
Below, we present eight different prompt engineering tools, beginning with our open-source framework, [Lilypad](https://github.com/mirascope/lilypad), which allows developers to optimize entire LLM workflows, not just prompts.
In our list, we highlight the approach and strengths of each tool:
* [Lilypad](#lilypad-collaborative-prompt-engineering-for-business-users-and-software-developers) — Collaborative prompt engineering for business users and software developers.
* [Mirascope](#mirascope-lightweight-and-user-friendly-llm-toolkit-for-software-developers) — Lightweight and user-friendly LLM toolkit for software developers.
* [LangSmith](#langsmith-specialized-in-logging-and-experimenting-with-prompts) — Specialized in logging and experimenting with prompts.
* [Weave](#weave-trace-based-debugging-and-scoring-for-llm-applications) — Trace-based debugging and scoring for LLM applications.
* [Langfuse](#langfuse-streamlined-prompt-management-and-evaluation) — Streamlined prompt management and evaluation.
* [Haystack](#haystack-effective-for-structuring-prompt-pipelines) — Effective for structuring prompt pipelines.
* [Agenta](#agenta-rapid-and-collaborative-llm-application-development) — Rapid and collaborative LLM application development.
* [LangChain](#langchain-scalable-and-customizable-llm-application-framework) — Scalable and customizable LLM application framework.
## Lilypad — Collaborative Prompt Engineering for Business Users and Software Developers
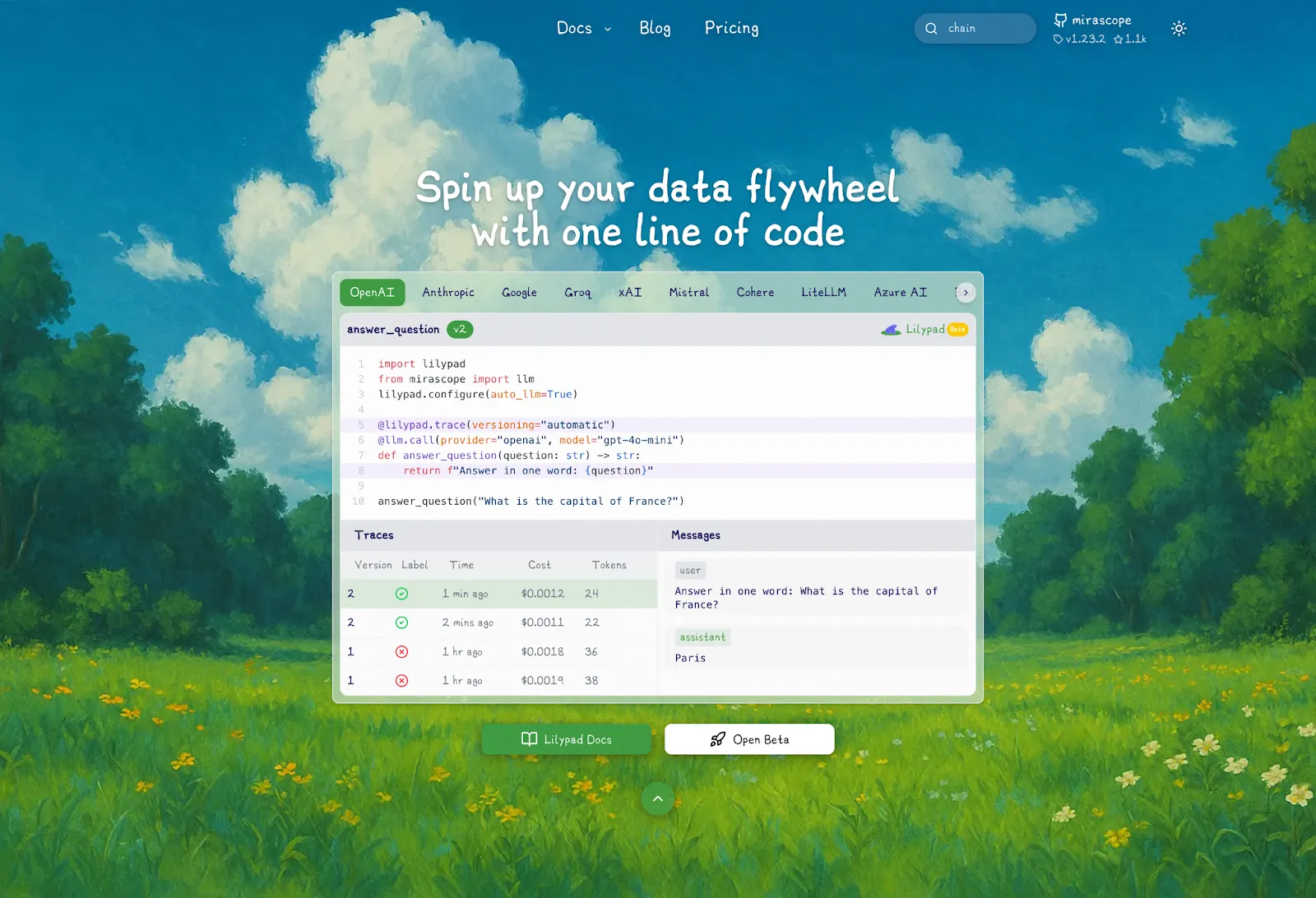
[Lilypad](https://github.com/Mirascope/lilypad) is built on the understanding that LLM calls are non-deterministic, and so every change to the prompt, along with other crucial artifacts like their callables and parameters, needs to be recorded, as even a small adjustment can have an unpredictable effect on the result.
This comprehensive tracking stands in contrast to other tools that often focus solely on prompt changes, potentially missing the broader context influencing the model’s output. It also makes the system flexible enough to handle any non-deterministic function, even beyond LLMs, such as embedding lookups in retrieval augmented generation (RAG) pipelines.
Unlike traditional unit tests that assume fixed, predictable outputs, you have to evaluate results often using fuzzy metrics, pass/fail annotations, or similarity scoring — all of **which require a systematic approach to tracking changes**.
Lilypad provides this systematic approach and, with its tool-agnostic design, supports any other prompt engineering library you might be using, offering a platform that helps you organize your code and prompts (with LLM’s unpredictability in mind) to more easily improve on them.
Below are some of Lilypad’s core features.
### Structuring Code for Prompt Engineering
Lilypad encourages you to organize your code around Python functions that encapsulate LLM calls.
Such functions contain all the inputs that go into a call:
* Input arguments, such as the user query or prompt, chat history, and response length
* The prompt itself
* LLM provider and model version (e.g., `gpt-4o-mini`), along with settings like temperature
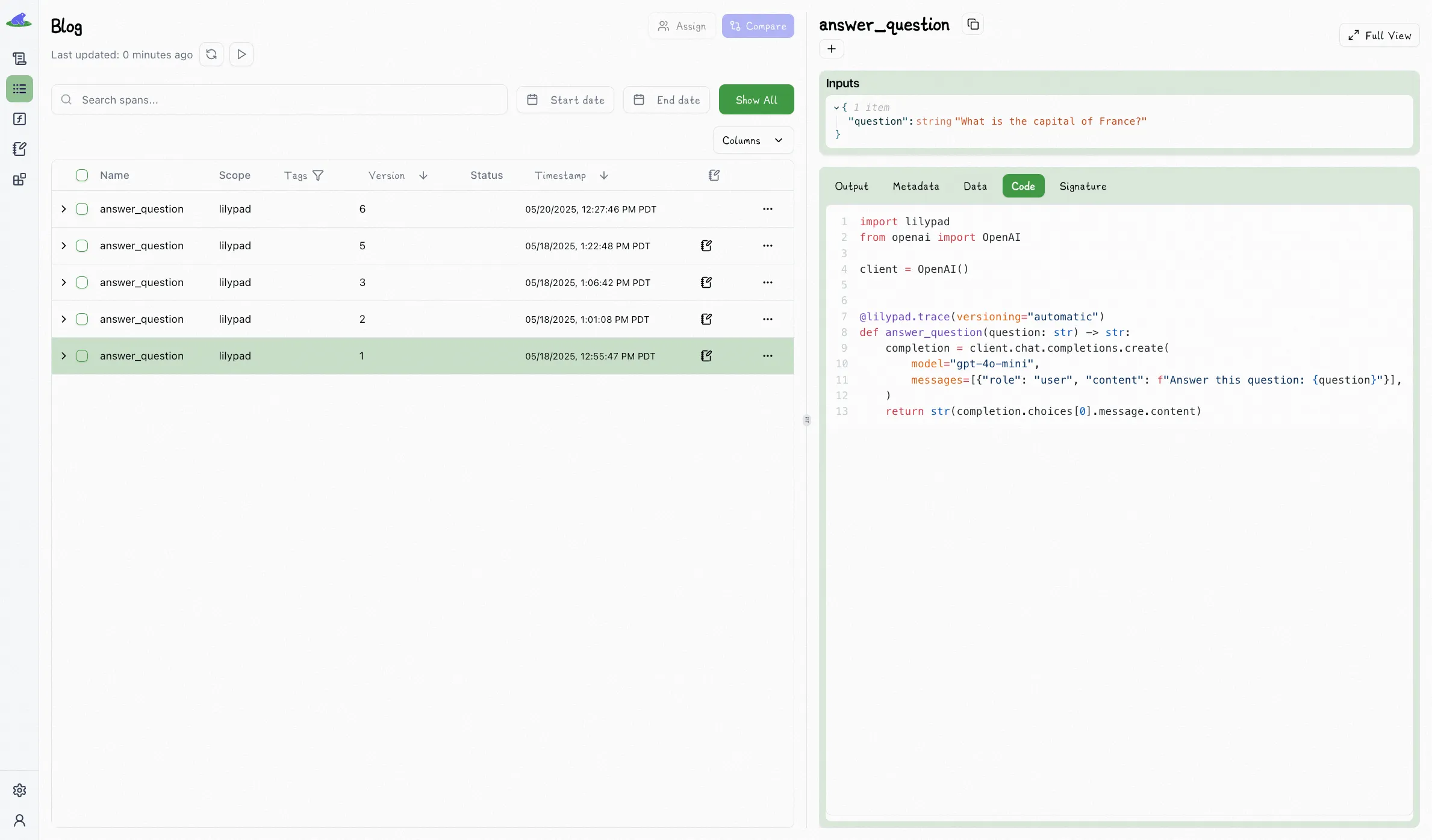
To begin using Lilypad, you first configure it within your application using `lilypad.configure(auto_llm=True)`. This initial step enables tracing of all LLM API calls made by your code, providing visibility into requests and responses, including details like token usage and cost.
However, while `lilypad.configure(auto_llm=True)` captures the data of these API calls, it’s not sufficient on its own for versioning and comprehensive tracing of the logic behind those calls.
That’s why we structure LLM interactions as non-deterministic functions using the `@lilypad.trace` decorator setting `versioning="automatic"`.
This tells Lilypad that the function contains an LLM call or non-deterministic code and to version and trace it automatically:
```py
import lilypad
import os
from openai import OpenAI
lilypad.configure(auto_llm=True) # [!code highlight]
client = OpenAI()
@lilypad.trace(versioning="automatic") # [!code highlight]
def answer_question(question: str) -> str:
completion = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": question}],
)
return str(completion.choices[0].message.content)
response = answer_question("Why is the sky blue?")
print(response)
```
We see this data in Lilypad playground (which we introduce further below), where the run (`answer_question`) is indicated as V1:
Lilypad automatically creates a nested trace whenever the function is executed, basing its tracking on the function’s closure.
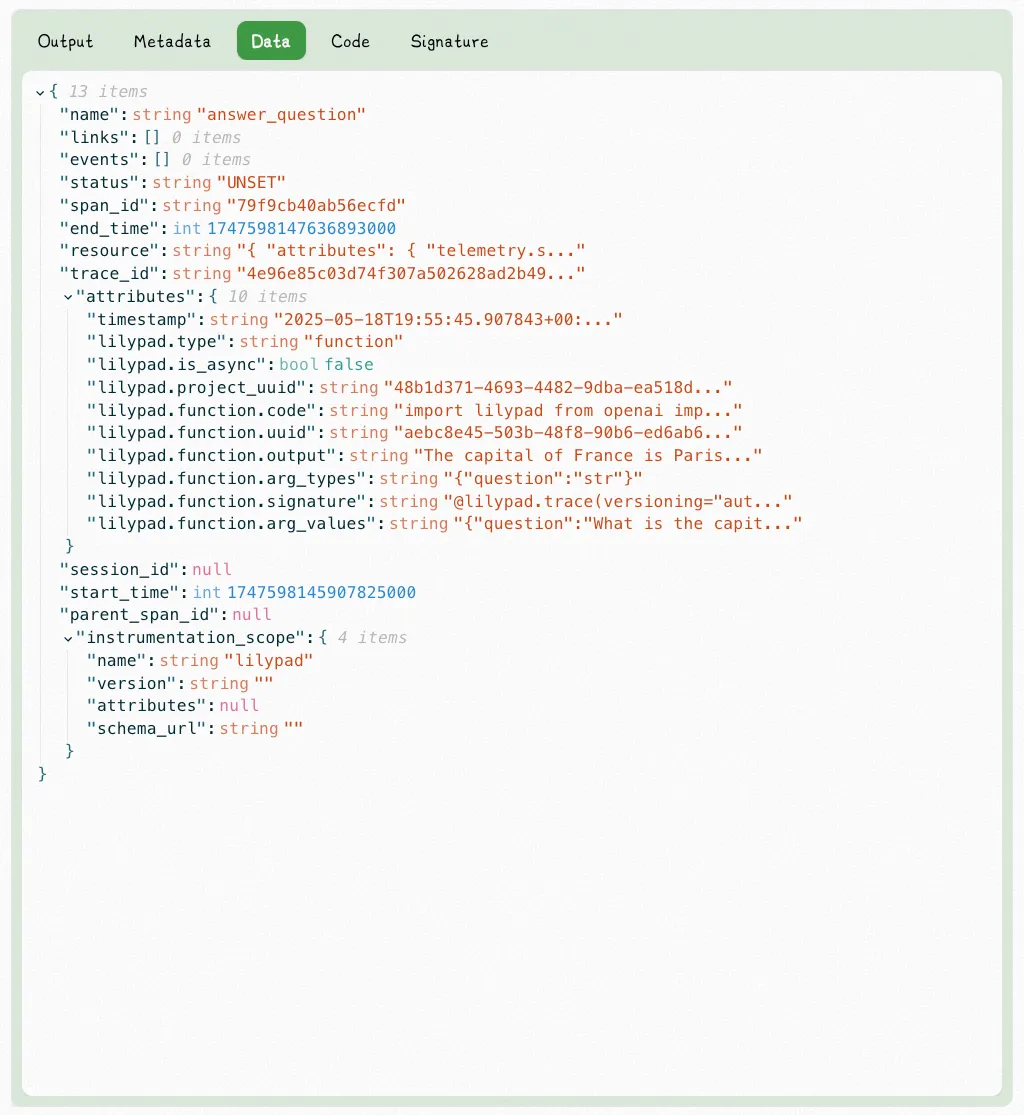
This creates a snapshot of the exact state of the code that produced a given output, and any change made inside the function automatically produces a new version, which you can roll back when needed.
Lilypad also recognizes identical functions (and their prompts) to prevent the creation of duplicate versions.
All this allows you to compare outputs over time and measure the impact of these changes against the same inputs.
This ability to apply the `@trace` decorator to any Python function (whether it contains an LLM call or not) to track changes and trace calls means you can use Lilypad with any underlying prompt engineering tool or framework (e.g., Mirascope, LangChain, etc.), ensuring you're not locked into any particular framework and that you retain full control over your AI stack.
It also means that you can use the same decorator to handle any non-deterministic code. For example, the retrieval portion of your pipeline may use embeddings, which should also be versioned, traced, and optimized systematically.
### Collaboration with Non-Technical Experts
Prompt iteration is often tied to code deployment: when non-technical domain experts (e.g., marketers, legal teams, etc.) want to refine a prompt, they rely on developers to implement changes, test, and redeploy even minor updates.
Lilypad offers managed prompts through its versioned functions and an intuitive GUI (**Lilypad playground**) that allows non-technical users to interact with and modify prompts without needing to alter the underlying code. This separates concerns and allows software engineers to focus only on the underlying system architecture.
Domain experts can define prompt templates with input variables, and the system automatically generates type-safe function signatures to keep everything structured, as shown below:
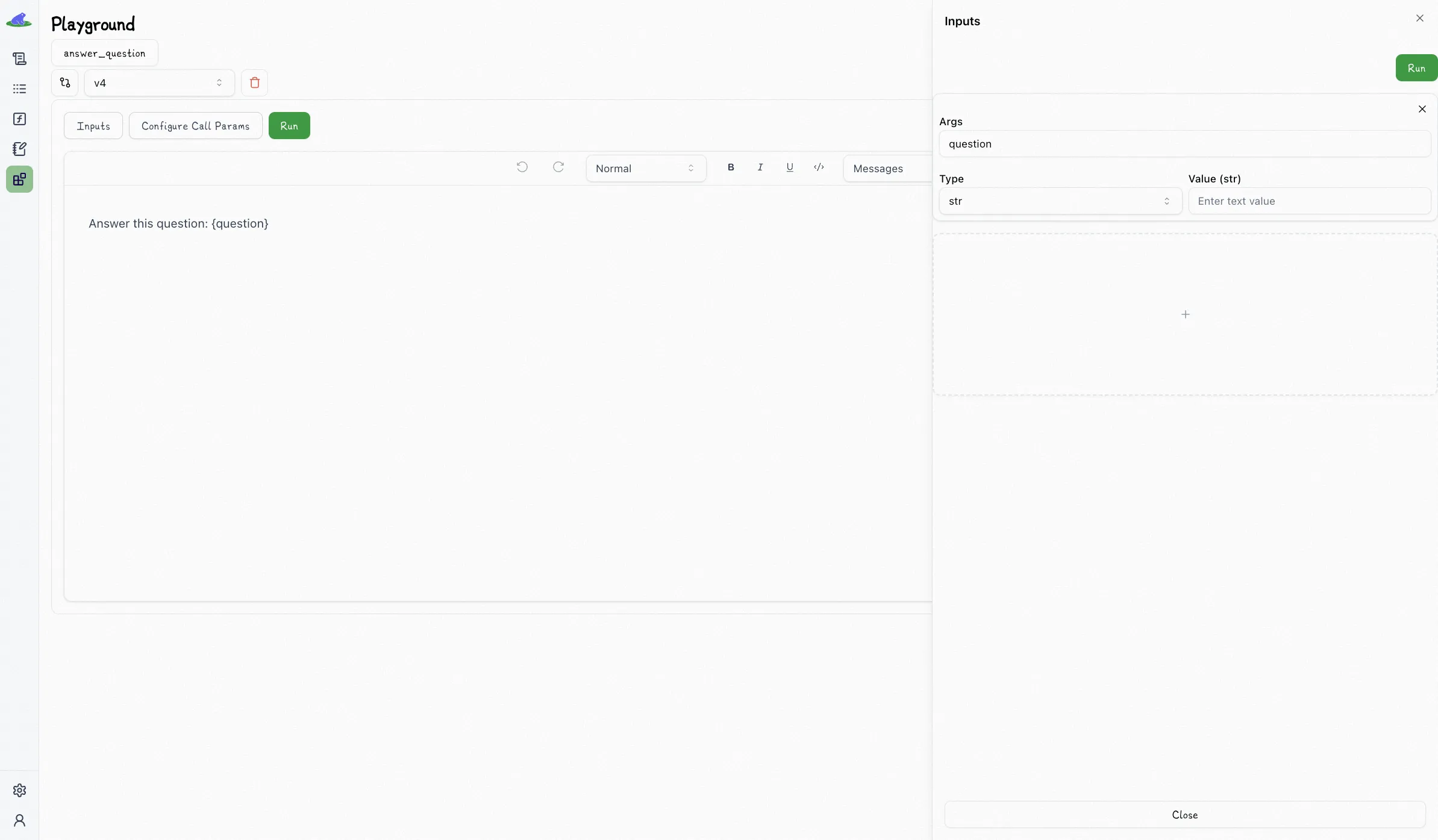
The playground’s no-code dashboards provide full visibility on the prompt engineering process and offer:
* Markdown-supported prompt templates, along with their associated Python functions
* LLM outputs, along with associated traces
* Call settings, like provider, model, and temperature
* Call metadata, like costs, token usage, and more
The playground supports multiple providers like OpenAI, Anthropic, Gemini, Mistral, OpenRouter, and more, including setting a default provider for an individual prompt.
### Evaluation of LLM Outputs by (Non-Technical) Domain Experts
Lilypad provides a framework for continuously evaluating non-deterministic outputs by logging everything about calls (including inputs, outputs, cost, time, etc.) so domain experts can annotate these.
Evaluating versioned traces in this way allows users to:
* See exactly what version of the code and prompt produced an output
* Identify what went wrong and where
* Spot patterns in good and bad outputs
* Test if a new version is actually better than the old one on the same inputs
This provides the data needed to treat prompt engineering like a real optimization problem, not just trial and error.
Although some types of tasks have “correct” and “incorrect” outputs, others are more nuanced and require fuzzier evaluation criteria.
For example, summarizing a customer support ticket has no single “correct” summary, as multiple outputs might all be valid as long as they capture the key points.
You can’t evaluate it with a strict exact-match metric; instead, you might annotate it as “good enough,” “too vague,” or “missing key details.” This is where fuzzy evaluation (e.g., pass/fail with reasoning) is more appropriate than binary correctness.
And for many tasks, pass/fail labels with reasoning are simple enough to scale, but rich enough to guide meaningful iteration as they define a "good enough" fuzzy metric for calls.
The playground allows you to easily choose any output to annotate:
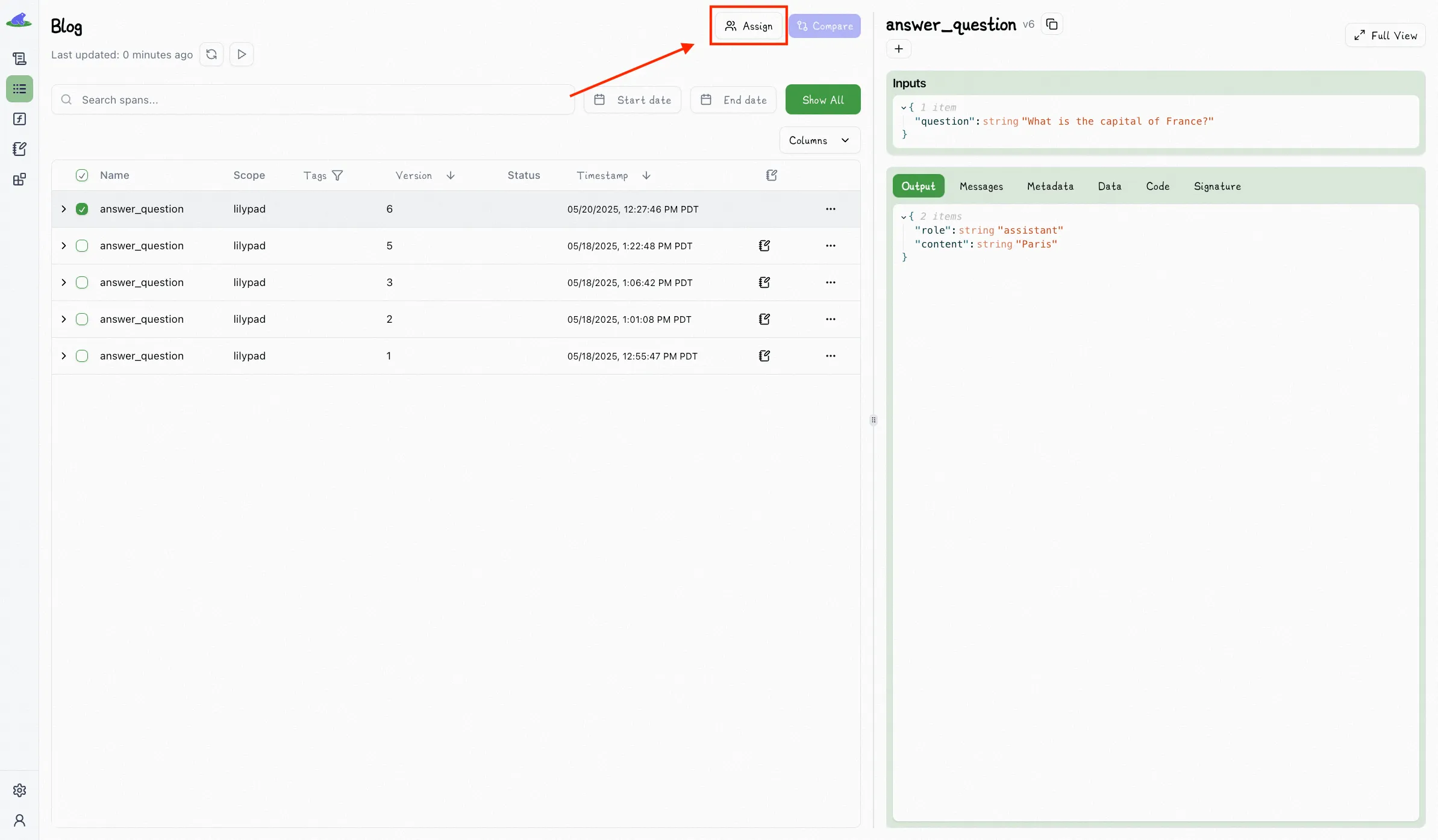
Here we simply mark an output as “Pass” or “Fail”:
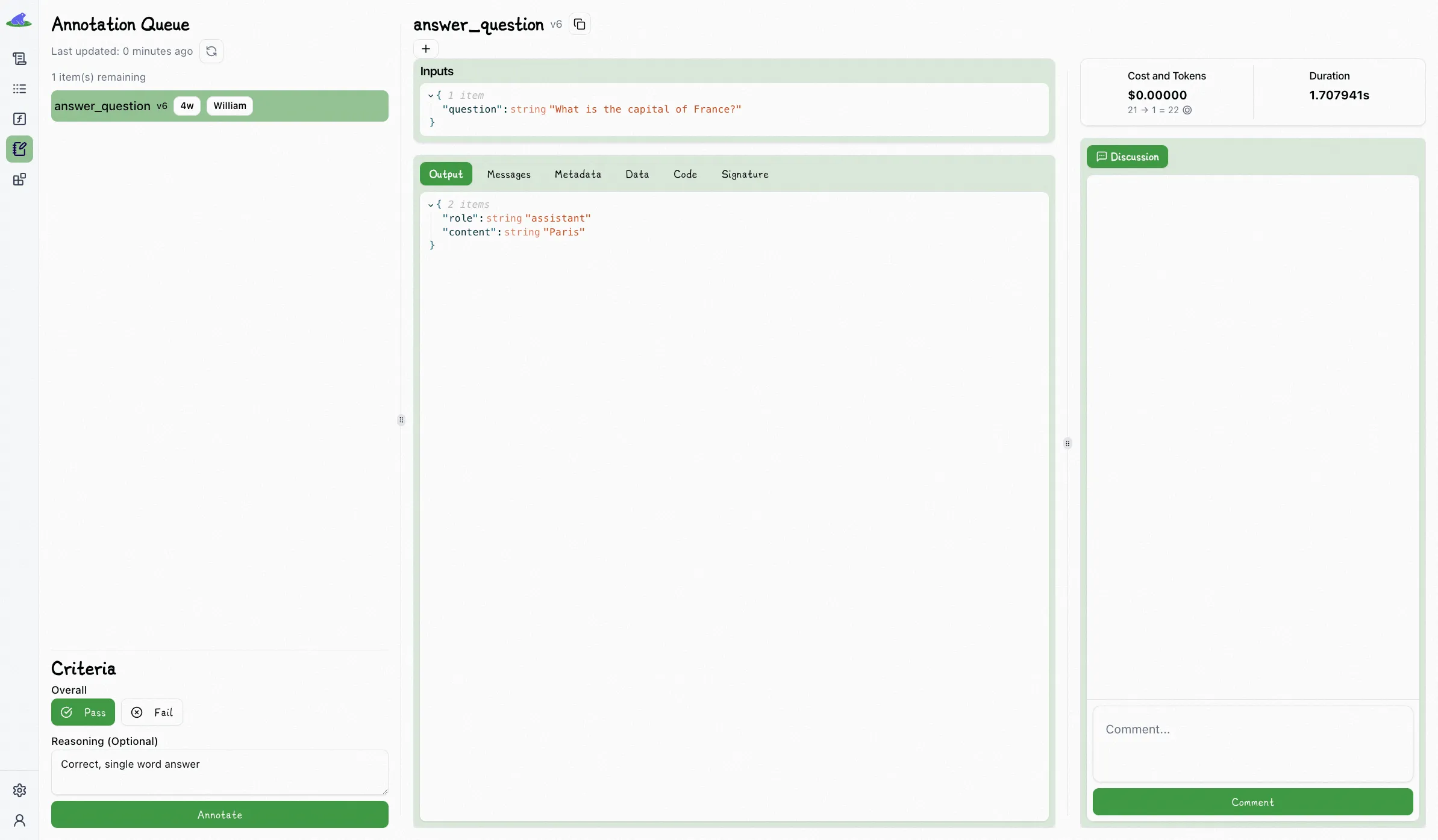
We encourage users to manually label outputs in this way as much as possible at the beginning of a project with the end goal of eventually automating the process using [LLM\-as-a-judge](/blog/llm-as-judge/), which we’re intending to launch in the near future.
Nonetheless, we advise to always keep a human in the loop to provide final verification as judges can sometimes lack confidence in particular tasks.
To get started with Lilypad, you can use your GitHub credentials to sign up for the [playground](https://lilypad.mirascope.com/) and instantly begin tracing and versioning your LLM functions with just a few lines of code.
## Mirascope — Lightweight and User-friendly LLM Toolkit for Software Developers
[Mirascope](https://github.com/mirascope/mirascope) is a Python toolkit that makes building with LLMs simple and flexible. It’s designed to fit right into your existing workflow without weighing you down; just use what you need, when you need it.
Built with [prompt engineering best practices](/blog/prompt-engineering-best-practices/) in mind, Mirascope lets you turn regular Python functions into LLM API calls using its convenient `llm.call` decorator. That means less boilerplate, more control, easier [LLM integration](/blog/llm-integration/), and consistent behavior across different providers, all while keeping your code safe and easy to manage.
Need to switch models or providers on the fly? No problem. Mirascope makes it easy to tweak settings as you go.
```py
from mirascope import llm
@llm.call(provider="openai", model="gpt-4o-mini") # [!code highlight]
def recommend_book(genre: str) -> str:
return f"Recommend a {genre} movie"
response: llm.CallResponse = recommend_book("science fiction")
print(response.content)
```
Mirascope is also compatible with Lilypad, as you can easily track calls by adding the `lilypad.trace` decorator to a function making an LLM call.
Below are some of Mirascope’s core features and capabilities.
### Leveraging Native Python for Scalable AI Application Development
By using native Python constructs, Mirascope reduces the learning curve for developers already familiar with the language and avoids unnecessary abstractions.
Below we use Mirascope’s `@prompt_template` decorator to define prompt templates as a standard Python function:
```py
from mirascope import llm, prompt_template
@prompt_template("What is the capital of {country}?") # [!code highlight]
def capital_prompt(country: str) -> str: # [!code highlight]
return {"country": country} # [!code highlight]
@llm.call(provider="openai", provider="openai", model="gpt-4o-mini")
def get_capital(prompt: str) -> str:
return prompt
def get_and_print_capital(country_name: str):
prompt = capital_prompt(country=country_name)
response = get_capital(prompt=prompt)
print(f"The model thinks the capital of {country_name} is: {response}")
get_and_print_capital("France")
```
Mirascope provides its `prompt_template` decorator so you can write prompt templates as standard Python functions. This avoids the need to create a separate prompt template for different use cases, as seen with [LangChain](/blog/langchain-prompt-template/).
This lets you focus on the core logic of your application without having to deal with complex, homegrown abstractions.
(See our latest article on [how to make a chatbot](/blog/how-to-make-a-chatbot/).)
Additionally, Mirascope colocates LLM calls with the prompt itself, treating the prompt and its configurations as a central organizing unit that promotes code cleanliness and supports better maintainability and scalability for [LLM applications](/blog/llm-applications/).
### Validation of Prompt Inputs and Outputs
Mirascope offers a built-in `response_model` that leverages Pydantic's BaseModel for easy validation of LLM outputs.
By setting the `response_model` in Mirascope's call decorator, it automatically parses and validates language model responses against your defined schema. This reduces debugging and the need to write your own validation boilerplate, as shown below:
```py
from pydantic import BaseModel
from mirascope import llm, prompt_template
class Book(BaseModel):
title: str
author: str
@llm.call(provider="openai", model="gpt-4o-mini", response_model=Book) # [!code highlight]
@prompt_template("Extract the book title and author from this text: {text}")
def extract_book_details(text: str):
...
response = extract_book_details(text="The book '1984' was written by George Orwell.")
print(response.title) # Output: 1984
print(response.author) # Output: George Orwell
```
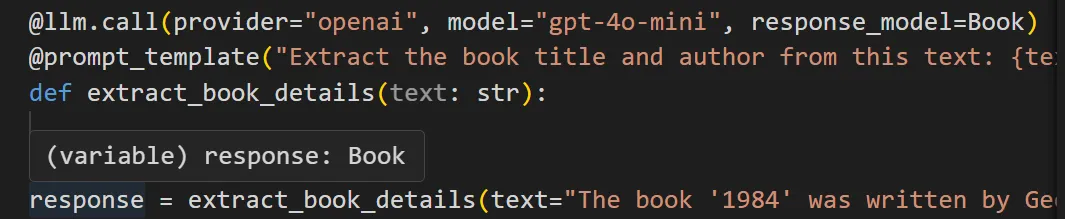
Here, the response model ensures the output conforms to the structure and types (fields) defined in `Book`. You see the correct type-hint in your IDE at lint time:
Additionally, it supports third-party libraries like Tenacity to automatically retry failed requests. This reinserts previous validation errors into subsequent prompts, allowing the LLM to learn from past validation failures and improve its accuracy through few-shot learning.
### Streamlined Function Calling (Tools)
Mirascope simplifies function calling by automatically extracting tool descriptions from docstrings, letting you use any function as a tool with little additional effort. This makes it easier to implement [LLM chaining](/blog/llm-chaining/), where the model can invoke multiple [LLM tools](/blog/llm-tools/) in sequence to complete complex tasks.
Below, we designate the function `check_book_availability` as a tool by declaring it as an argument in the `llm.call` decorator.
When the LLM is called, a tool description for `check_book_availability` is generated and sent with the prompt:
```py
from mirascope import llm, prompt_template
def check_book_availability(title: str) -> str: # [!code highlight]
"""Checks if a given book is available in the library.
Args:
title: The book title (e.g., "1984" by George Orwell).
"""
if title.lower() == "1984":
return f"The book '{title}' is available for checkout."
elif title.lower() == "the great gatsby":
return f"The book '{title}' is currently checked out."
else:
return f"I'm sorry, we don't have '{title}' in our library."
@llm.call(provider="openai", model="gpt-4o", tools=[check_book_availability]) # [!code highlight]
@prompt_template("Can you check if {book_title} is available?")
def get_book_status(book_title: str): ...
response = get_book_status("1984")
if tool := response.tool:
print(tool.call())
# > The book '1984' is available for checkout.
```
Mirascope supports varying docstring styles, including Google-, ReST-, Numpydoc-, and Epydoc-style.
To learn more about Mirascope, you can refer to its extensive [documentation](/docs/v1/learn).
## LangSmith — Specialized in Logging and Experimenting With Prompts
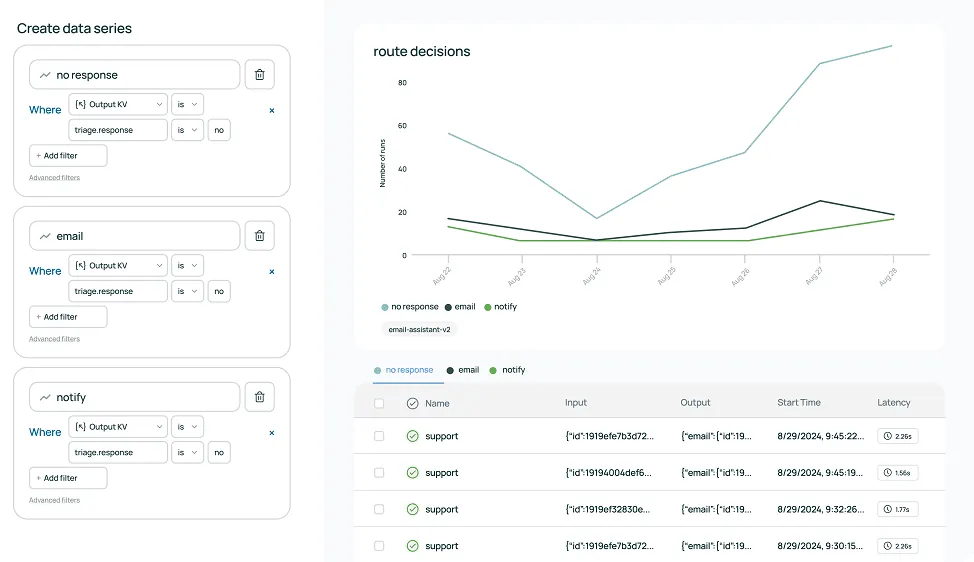
[LangSmith](https://www.langchain.com/langsmith), created by the team behind LangChain, is a closed-source developer platform that provides tools and infrastructure to build, monitor, debug, test, and optimize LLM\-powered applications.
The platform is also framework-agnostic, meaning you can use it with or without the LangChain library.
### Tracking and Tracing for Observability
LangSmith records all LLM calls, inputs, and outputs, and intermediate steps into a trace that developers can inspect. This rich tracking information gives you full visibility into the chain of calls (for example, in a LangChain pipeline) and helps you see exactly what the model was asked and how it responded at each step. By tracking the entire sequence of prompts, model responses, and tool invocations, you can easily pinpoint where things might be going wrong or behaving unexpectedly.
### Evaluation and Testing
LangSmith provides an integrated way to create datasets of test queries and expected answers, and then evaluate your model or chain’s performance against them. Using the LangSmith SDK or UI, you can easily build high-quality [LLM evaluation](/blog/llm-evaluation/) sets and run them in bulk.
LangSmith also comes with a suite of off-the-shelf evaluators (and allows custom ones) to automatically grade or score the LLM’s responses on various criteria.
### Prompt Management and Version Control
You create and store prompts with a full version history. Every time you refine or tweak a prompt, you can track it as a new version or commit by saving it, enabling you to roll back or compare changes if needed.
This built-in version control is similar to Git but for prompts. You can label versions with tags (e.g., “v1”, “staging”, “prod”) and easily switch your application to use a different prompt version without code changes.
Unlike with Lilypad, LangSmith versions and traces only the prompt itself rather than the entire lexical closure of the function making the LLM call, and operates without the specific and complete snapshot of the code that produced the output.
For more information, you can read about LangSmith on its website or consult its documentation site.
## Weave — Trace-based Debugging and Scoring for LLM Applications
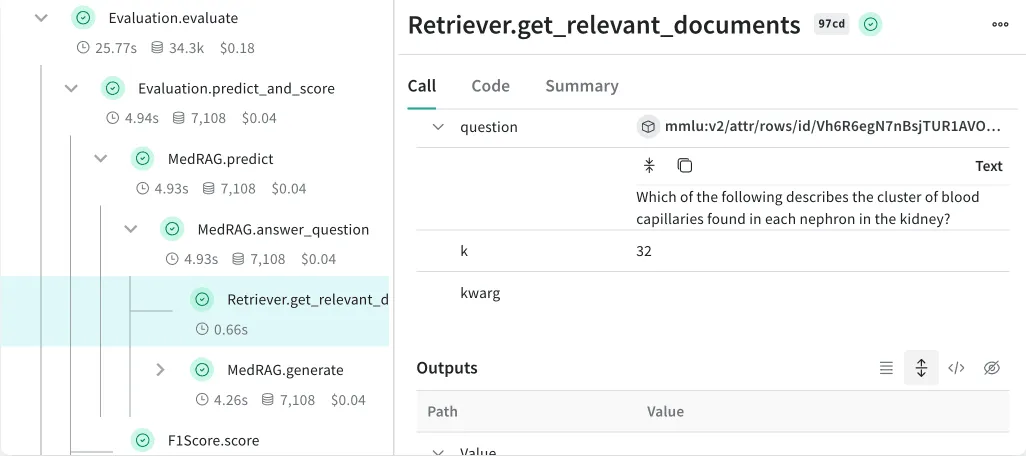
[W&B Weave](https://wandb.ai/site/weave/) is a toolkit developed by Weights & Biases that provides tools for tracking, evaluating, and iterating on LLM applications.
### Tracing and Monitoring
Weave automatically logs all inputs, outputs, code, and metadata in your application, organizing the data into a trace tree. This feature allows you to debug issues and monitor your application in production effectively.
### Evaluations and Scoring
The toolkit offers rigorous evaluations that enable you to experiment with different models, prompts, and configurations. It provides visualizations, automatic versioning, and leaderboards to help optimize performance across quality, latency, cost, and safety dimensions.
Weave includes pre-built LLM\-based scorers for common tasks such as hallucination detection, summarization, similarity assessment, and more. Plus, you can integrate custom or third-party scoring solutions to tailor evaluations to your specific needs.
### Human Feedback Integration
With Weave, you can collect human feedback with Weave's annotation template builder, which allows you to gather ratings, emojis, and detailed annotations. This feature aids in building high-quality evaluation datasets and refining application performance based on user insights.
To learn more, you can read about Weave on its website or consult its documentation site.
## Langfuse — Streamlined Prompt Management and Evaluation
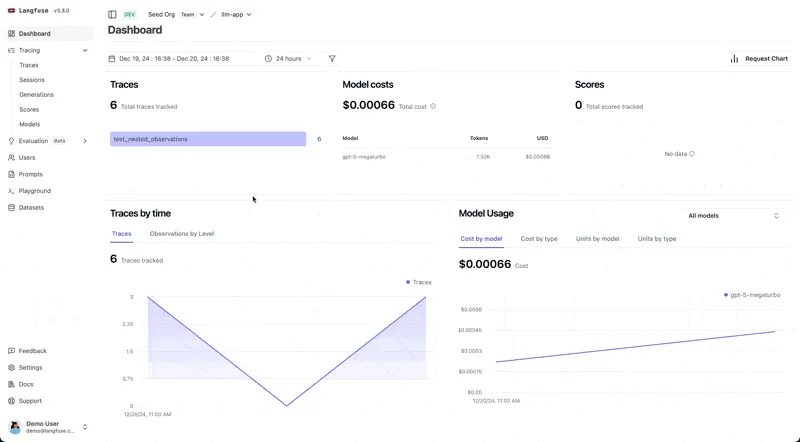
[Langfuse](https://langfuse.com/) is an open-source platform that supports every stage of developing, monitoring, evaluating, and debugging LLM\-powered applications. It integrates with popular frameworks like OpenAI SDKs, LangChain, and LlamaIndex, making it easy to work within the tools you want or already use.
### Prompt Management
Langfuse offers robust tools for prompt management, including prompt registries and playgrounds. These features allow developers to test and iterate on different prompts systematically, improving the quality and performance of their applications.
### Real-Time Monitoring and Evaluation
With Langfuse, developers can monitor LLM outputs in real time. The platform supports both user feedback collection and automated evaluation methods to assess the quality of responses and ensure they meet expectations.
### Structured Testing for AI Agents
Langfuse also provides structured testing capabilities for AI agents, particularly in chat-based interactions. The unit testing features help developers ensure the reliability and consistency of their artificial intelligence agents, making sure that everything works as expected.
Langfuse features a GitHub repository, a dedicated documentation site, and a website.
## Haystack — Effective for Structuring Prompt Pipelines
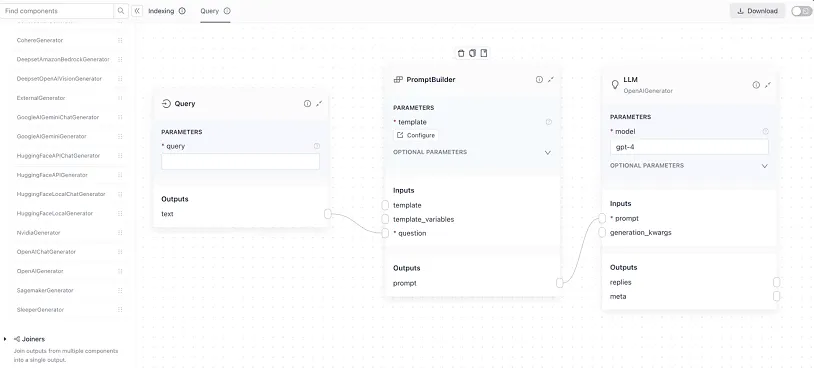
[Haystack](https://haystack.deepset.ai/) is an orchestration framework for building customizable, production-ready LLM applications. Its prompt engineering features allow you to construct effective prompts, tailor interactions with a variety of LLMs, and build a [RAG application](/blog/rag-application/) using context-enriched responses.
It's [PromptHub](https://prompthub.deepset.ai/) offers an open source repository for prompt templates.
### Simplify Model Interactions
Haystack is technology agnostic and allows users to decide which vendor or technology they want to use, making it easy to switch out components. It supports models from OpenAI, Cohere, and Hugging Face, providing flexibility in model selection.
It’s also generally extensible and flexible, allowing for custom components like modules or classes.
### Extract Structured Data from Unstructured Outputs
The framework’s architecture, with its focus on pipelines and components, is geared towards processing and manipulating unstructured data (like documents) to perform tasks such as natural language question answering and semantic search.
### Extend Model Capabilities with Tools
Haystack’s design as an extensible framework supports the integration of custom components and formats, which could include tools for enhanced calculations or external API calls to AI systems.
The framework features a GitHub repository, a dedication documentation site, and a website.
## Agenta — Rapid and Collaborative LLM Application Development
[Agenta](https://agenta.ai/) is an open-source, end-to-end LLMOps platform that helps developers and product teams build generative AI applications powered by LLMs.
### Prompt Management and Experimentation
Agenta lets you experiment quickly with specific prompts across a variety of LLM workflows, such as chain-of-prompts, retrieval augmented generation, and [LLM agents](/blog/llm-agents/). It’s compatible with frameworks like Langchain and LlamaIndex and works seamlessly with models from providers like OpenAI, Cohere, or even local models.
### Observability and Evaluation
With Agenta, you can add a few lines of code to start tracking all inputs, outputs, and metadata of your application. This allows you to compare app versions, find edge cases, improve your development process, debug and more.
Agent allows you to create test sets and golden datasets to evaluate your applications, whether using pre-existing evaluators or custom ones. The platform provides the tools you need to assess and streamline performance, and you can even annotate results and run A/B tests using human feedback to fine-tune your models.
More information about Agenta is available on its website, its documentation site, and on GitHub.
## LangChain — Scalable and Customizable LLM Application Framework
[LangChain](https://www.langchain.com/) is an open-source framework that facilitates building applications powered by large language models.
### Dynamic Prompting and Advanced Customization
LangChain, through its LangChain Expression Language (LCEL) and modular design, allows for dynamic composition of chains. This includes possibilities for prompt construction that can incorporate customized logic and components, adapting to varying contexts and requirements.
Some users report that LCEL works fine for simple chained AI prompts but grows in complexity with more complicated chains, however. Although LCEL allows you to connect components using a pipe operator, it also obscures how the code is functioning under the hood, and is another abstraction for developers to learn.
### Supports Model Interactions with Wrappers and Integrations
LangChain introduces a variety of NLP wrappers that abstract away the complexities of dealing directly with large language models. These wrappers provide developers with high-level abstractions for model I/O, enabling straightforward interactions with AI models.
The library also offers libraries with integrations for components like large language models, agents, output parsers, and more, as well as off-the-shelf chains for common tasks.
### Extend Model Capabilities with Custom Tools
LangChain's extensible design allows developers to automate and integrate custom AI tools and components into their [prompt chaining](/blog/prompt-chaining/).
More information about LangChain is available on its website, GitHub page, and documentation site.
## Optimize Your Prompt Engineering Workflow With Lilypad
Lilypad focuses on making the development of artificial intelligence features more manageable for software engineers by providing tools for versioning, tracing, and optimization.
Our framework is designed to be as general a tool as possible and can be used with other libraries, giving you the flexibility to build what you want, your way.
Want to learn more? You can find Lilypad’s code samples on both our [documentation site](/docs/lilypad) and on [GitHub](https://github.com/mirascope/lilypad).
8 Best Prompt Engineering Tools in 2026
2025-06-20 · 20 min read · By William Bakst