LangSmith is a popular observability and evaluation platform for LLM applications. It helps you debug, test, and monitor performance with features like tracing, prompt versioning, and a playground for experimenting with prompts and chains.
It’s especially useful for tracking changes and helping you understand how your app behaves across different runs.
But LangSmith has some limitations:
* It typically versions only the prompt templates, but not the surrounding code, logic, or the callable function that makes the LLM call. This can make tracing the root cause of issues difficult when things go wrong.
* Linking an output back to the exact prompt version requires you to manually save changes as new commits.
* LangSmith is tightly integrated with LangChain, and its tracing and versioning features work best within that ecosystem. If you’re building with tools outside LangChain, you’ll need to manually instrument your code using their SDK or API to capture traces and versions.
* Some users find the UI to be complex to navigate, and evals are also intricate, sometimes requiring large datasets.
In this article, we cover nine alternatives to LangSmith, starting with [Lilypad](/docs/lilypad), our open-source framework for tracking, debugging, and optimizing LLM applications.
- [Lilypad](#1-lillypad-full-code-snapshot-versioning-for-reproducible-llm-development)
- [PromptLayer](#2-promptlayer-closed-source-simplicity-with-drag-and-drop-prompt-tools)
- [Langfuse](#3-langfuse-open-source-monitoring-pay-to-power-up-evaluation)
- [Helicone](#4-helicone-real-time-dashboards-and-workflow-tracing-no-lock-in)
- [Orq.ai](#5-orq-ai-closed-source-control-for-high-stakes-llm-deployments)
- [Phoenix](#6-phoenix-open-source-observability-with-ml-roots)
- [OpenLLMetry](#7-openllmetry-opentelemetry-for-llms-plugged-into-your-stack)
- [HoneyHive](#8-honeyhive-built-in-prompt-studio-with-versioning-and-guardrails)
- [Portkey](#9-portkey-centralize-prompt-development-across-models-and-teams)
## 1. Lillypad: Full-Code Snapshot Versioning for Reproducible LLM Development
[Lilypad](/docs/lilypad) is built for software developers and lets them run their LLM workflows with the same structure and reliability as real code. It approaches prompt engineering as an optimization problem, recognizing that LLM calls are inherently non-deterministic and that even small adjustments can have unpredictable effects on the output.
To manage this unpredictability, Lilypad doesn't just track prompts, but captures the entire function closure. This means it versions everything that could influence the LLM call's outcome, including the function being called, all relevant model settings, parameters, helper functions, and any logic within scope.
This creates a full snapshot of the code context behind each output, making it easier to trace what changed, reproduce results, and experiment methodically when building [LLM applications](/blog/llm-applications).
Lilypad is also lightweight, works with other [LLM frameworks](/blog/llm-frameworks), and can be used with any prompt engineering library or provider SDK. If you prefer to self-host, you can run Lilypad with just Python 3.10+, PostgreSQL, Docker, and a GitHub or Google account for login. No complex setup or vendor lock-in.
Below are some of Lilypad’s core features that help make prompt development easier, less error-prone, and more efficient for developers.
### Make Your LLM Code Easy to Track
Lilypad helps you keep your LLM code clean and organized by wrapping each LLM call in a regular Python function. That function holds everything you need: inputs, prompt, model settings, logic, and even any pre- or post-processing steps.
By keeping it all in one place, you can trace exactly what happened, spot what changed, and keep the LLM stuff separate from the rest of your app. It’s easier to debug, test, and improve.
To enable tracing, simply add the @lilypad.trace decorator and set `versioning=”automatic"`. This tells Lilypad that the function contains an LLM call (or other non-deterministic code, e.g., retrieval from vector databases or embeddings), and that they should be automatically versioned and traced every time the code is run:
```python
from google.genai import Client
import lilypad
lilypad.configure(auto_llm=True)
client = Client()
@lilypad.trace(versioning="automatic") # [!code highlight]
def answer_question(question: str) -> str | None:
response = client.models.generate_content(
model="gemini-2.0-flash-001",
contents=f"Answer this question: {question}",
)
return response.text
response = answer_question("What is the capital of France?") # automatically versioned
print(response)
# > The capital of France is Paris.
```
This creates a nested trace and logs that function execution as version 1 in the Lilypad playground:
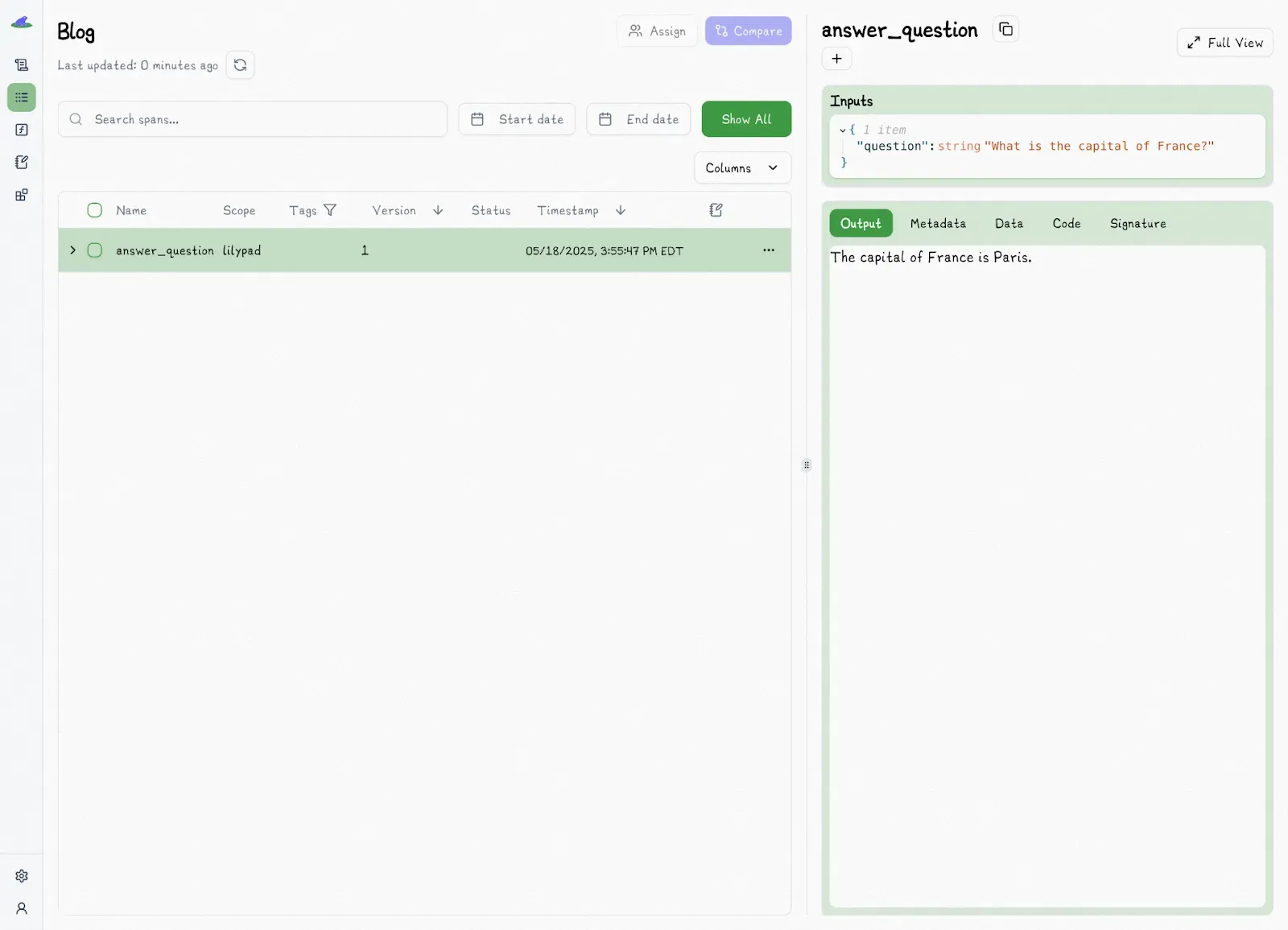
If you update the function (even slightly), Lilypad automatically creates version 2 and logs it.
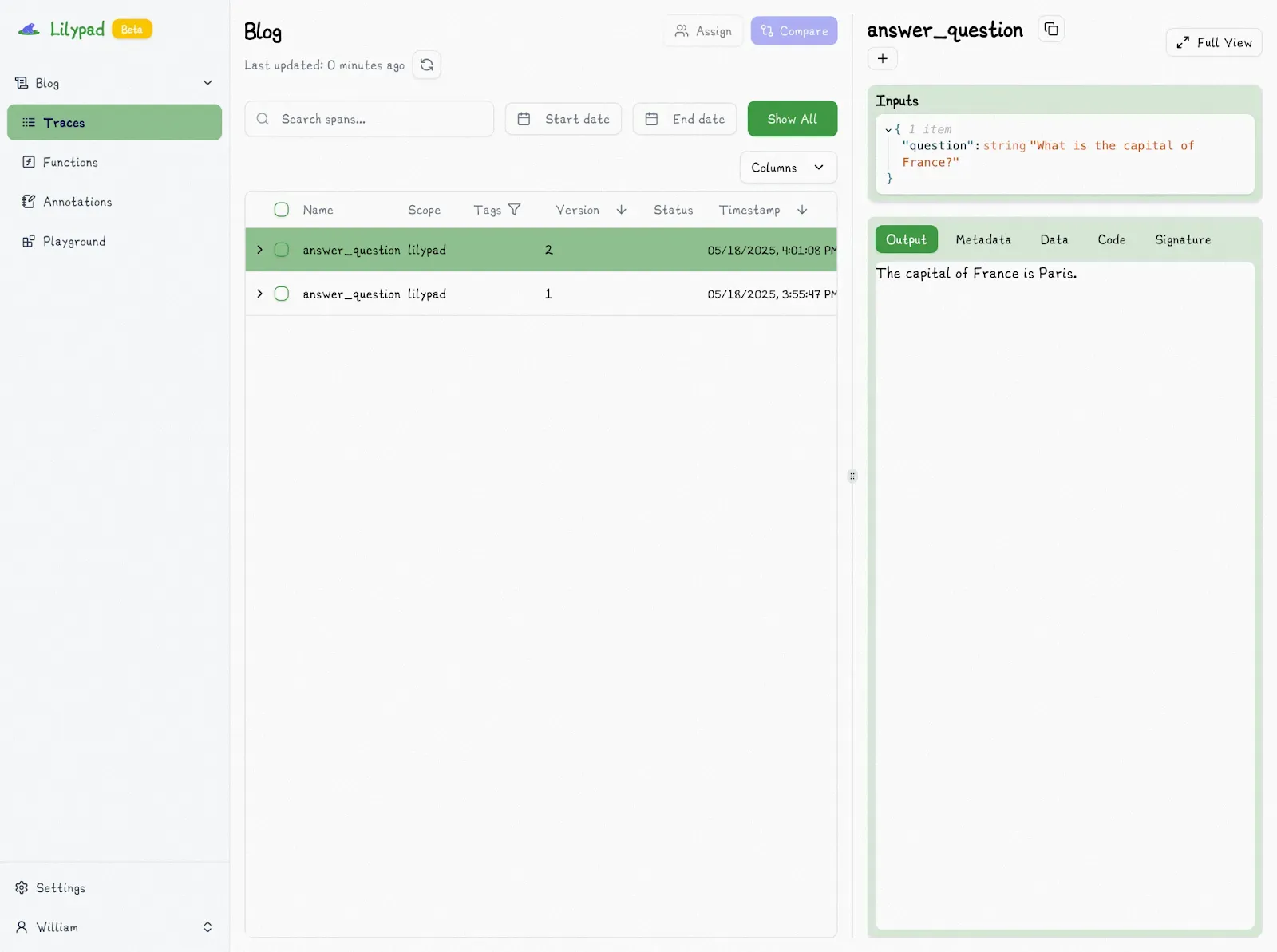
You can also compare function versions by clicking the “Compare” button:
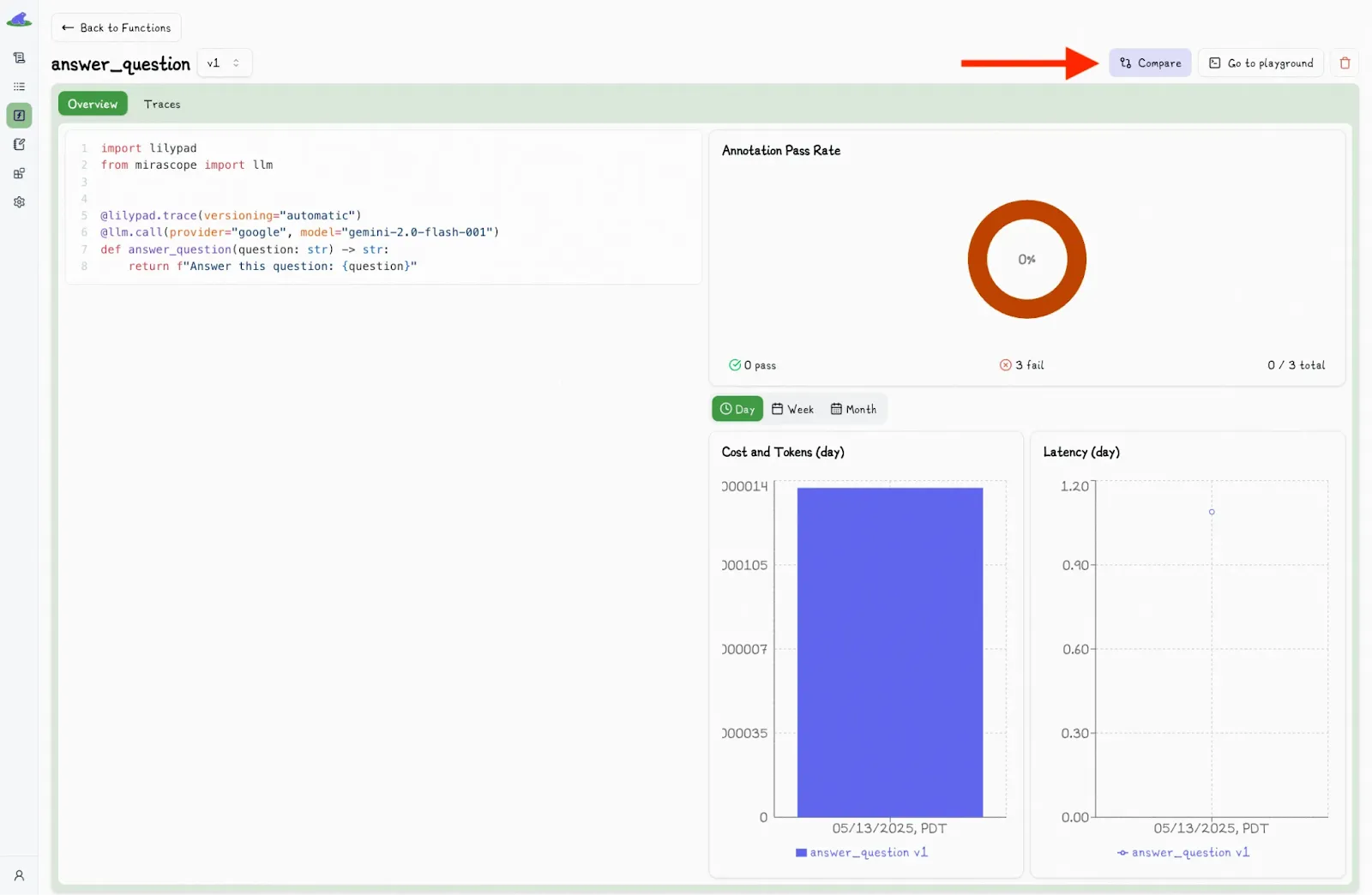
This toggles a second dropdown menu, where you can select another version and view the differences side-by-side.
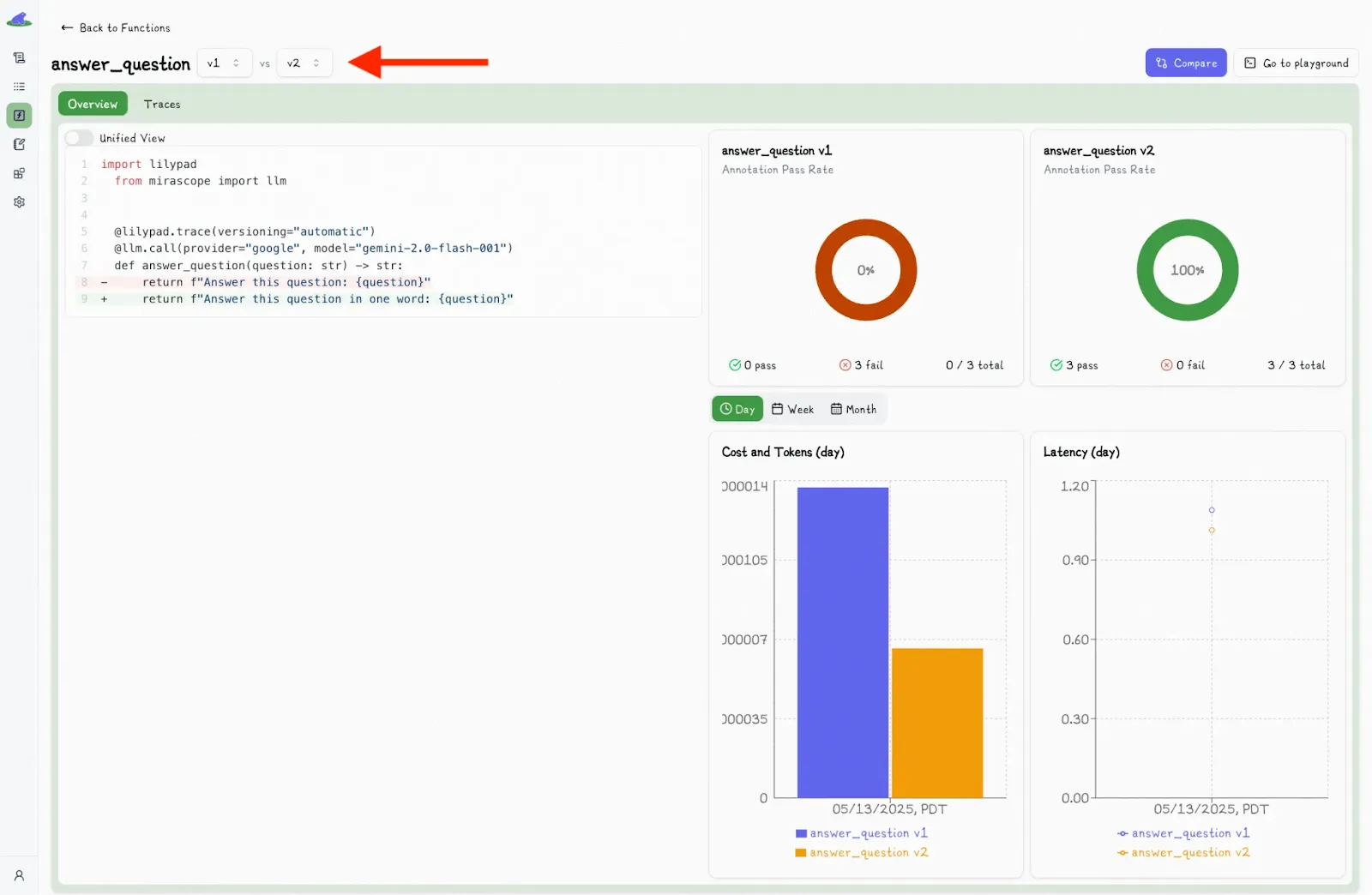
For better observability, Lilypad instruments everything using the [OpenTelemetry Gen AI spec](https://opentelemetry.io/).
Each trace breaks down the full story: what was asked, how it was asked, and what came back. It’s perfect for debugging and improving tricky workflows. You also get all the key details: inputs, outputs, model and provider info, token usage, latency, and cost.
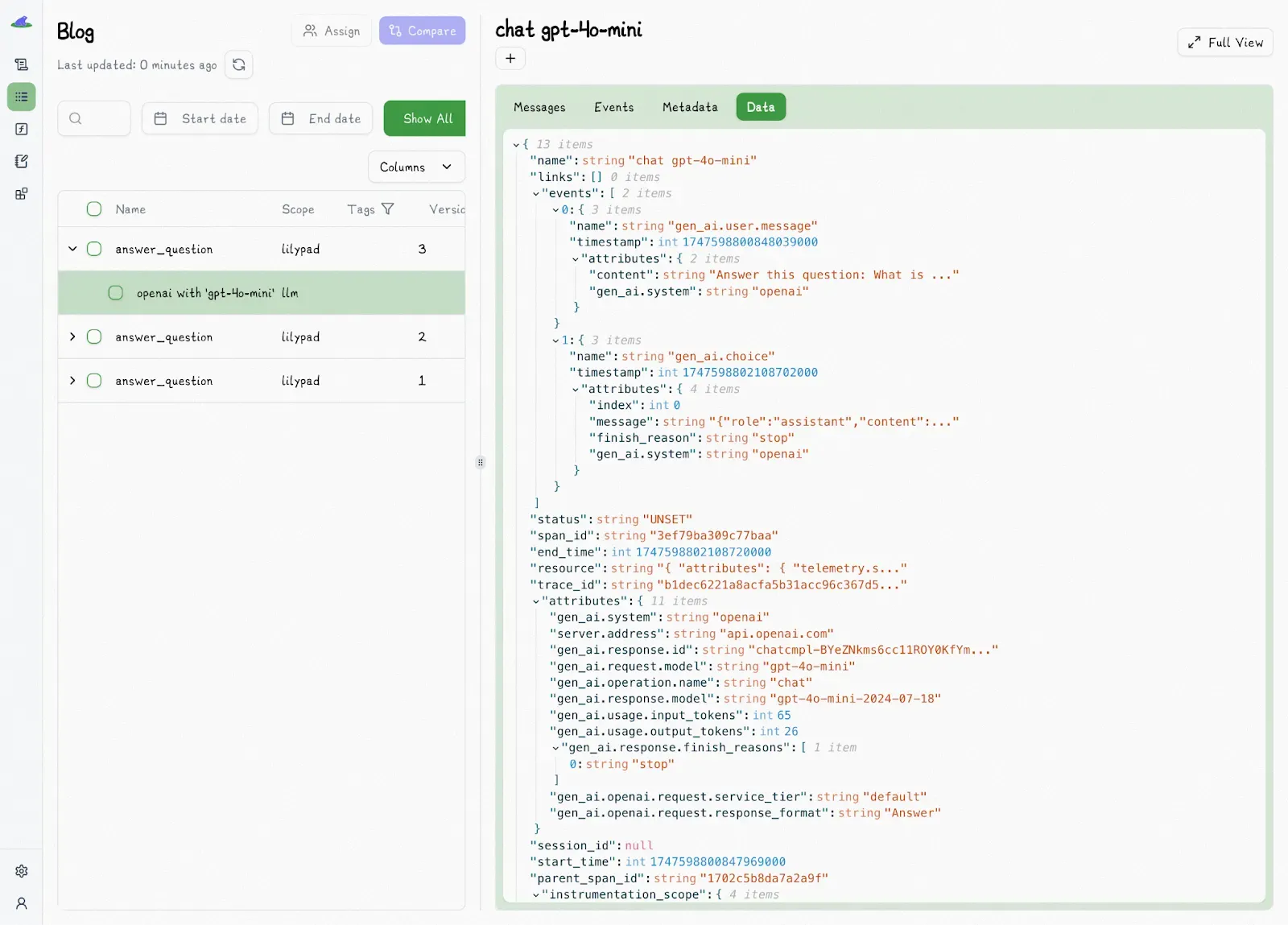
This kind of automatic tracing and version control lets you easily measure improvements and iterate without guessing what was different between runs.
Lilypad also detects when a function (and its prompts) haven’t changed, so it won't create duplicate versions unnecessarily.
### Collaborating with Non-Technical Experts
Lilypad’s no-code playground supports collaboration across technical and non-technical teams.
This lets non-developers interact with and tweak prompts directly, without touching code or depending on engineers for minor changes.
It also separates concerns, allowing software engineers to focus on system architecture while SMEs handle prompt logic and evaluation.
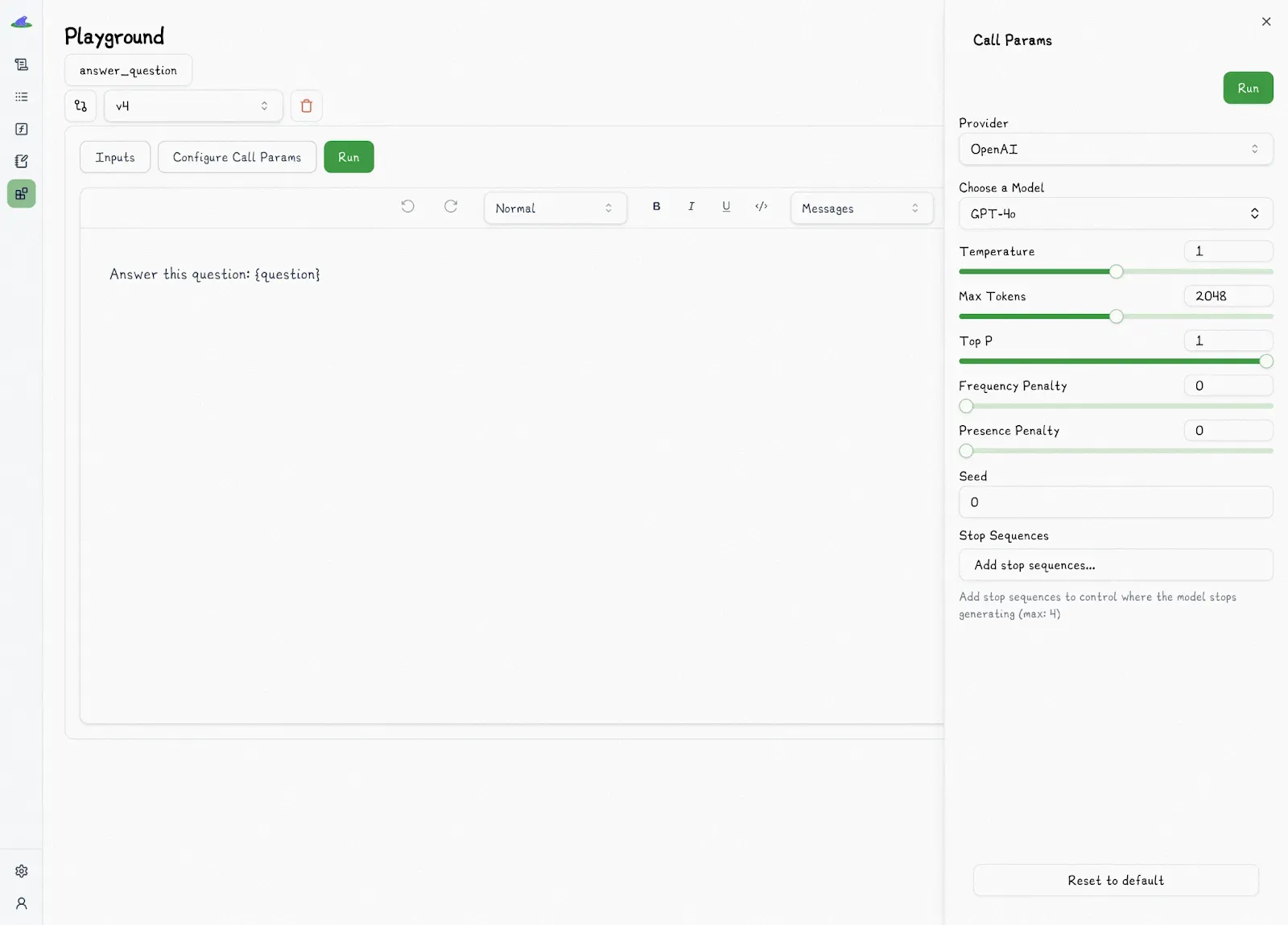
The dashboard provides Markdown-supported prompt templates with type-safe variables, along with their associated Python functions, so you can see both the prompt and the exact code it ties into.
It also shows:
* LLM outputs and traces.
* Call settings, such as provider, model, temperature, and other configuration details.
* Metadata, including cost, token usage, and latency, to help monitor efficiency and performance.

### Evaluating LLM Outputs
Since LLMs are non-deterministic, evaluating their outputs is challenging: you can run the same prompt twice and get slightly different (yet valid) outputs. That makes traditional testing methods like unit tests less reliable since you can’t always count on exact matches. Plus, what qualifies as “correct” often depends on context.
Lilypad tackles this challenge in two ways. First, it logs every detail of a call, including inputs, outputs, costs, and timing, to give you a complete, traceable picture of how an LLM behaves over time. This persistent context makes it easier to rate outputs consistently, spot regressions, and understand how changes in prompts or code affect the results.
And unlike LangSmith, which depends on pre-built datasets for [prompt evaluation](/blog/prompt-evaluation), Lilypad takes a trace-first approach, turning every prompt run into a versioned trace with full metadata and building a real-world dataset automatically as you go. This means when outputs vary (as they often do), you have the full context to understand what changed.
This is shown in the playground, where you see which version of the code and [LLM prompt](/blog/llm-prompt) produced each output and find patterns in what works (and what doesn’t), and test if a new version actually performs better on the same input. It’s not just trial and error anymore; prompt engineering becomes a real optimization process for [LLM integration](/blog/llm-integration).
Secondly, because “correctness” often involves subjective judgment or fuzzy criteria, especially in tasks like summarization or reasoning where there’s no single "correct" output, Lilypad simplifies the evaluation process into a pass/fail labeling system. Instead of agonizing over granular scoring (like 1-5 ratings) or trying to match exact strings, you just ask: Is this output acceptable? This keeps evaluations focused, fast, and practical, even across thousands of traces.
The playground also lets you easily select any output for annotation:
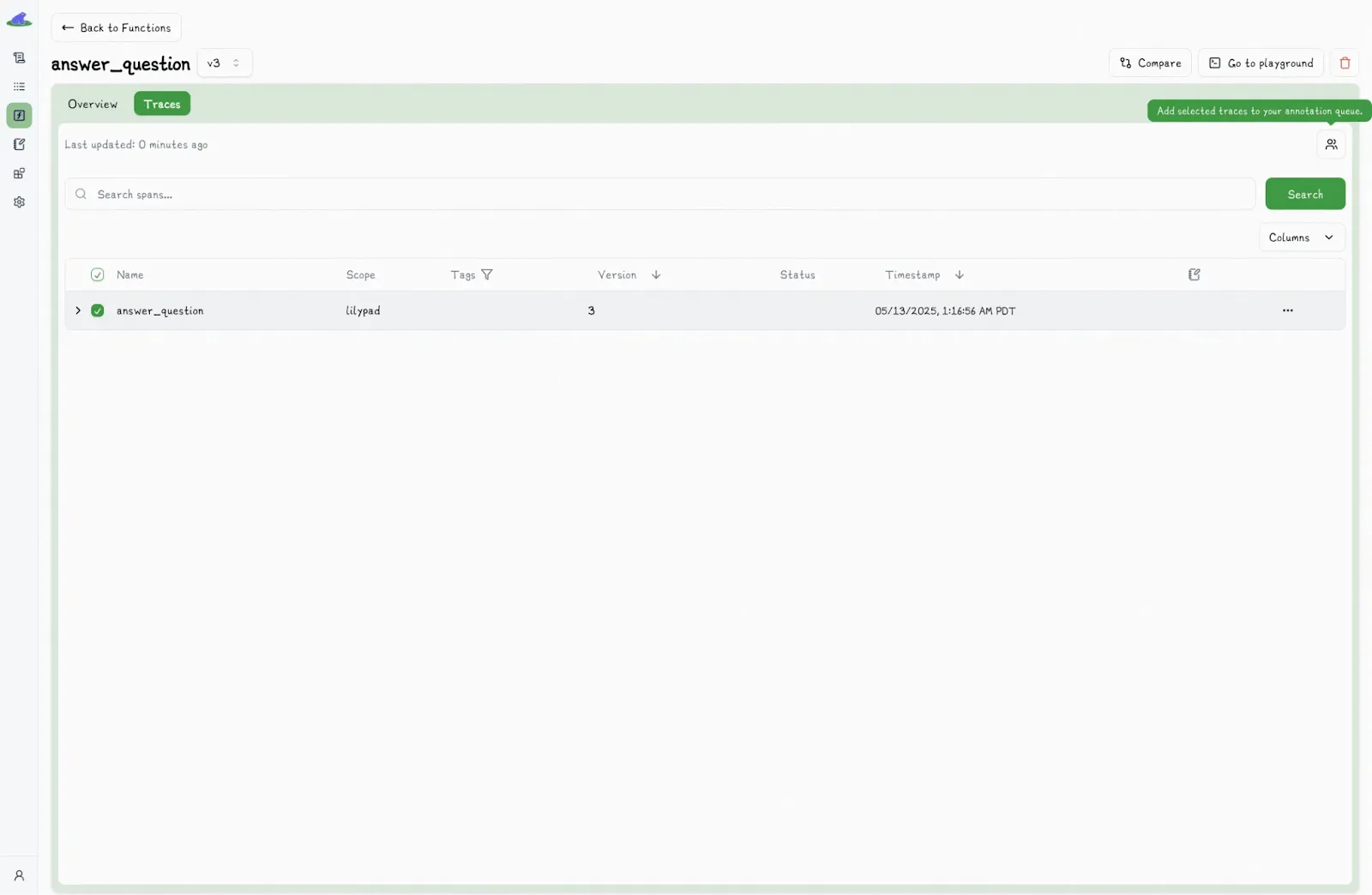
From there, just click the “Pass” or “Fail” label, add any context or reasoning if you want, and click “submit annotation.”
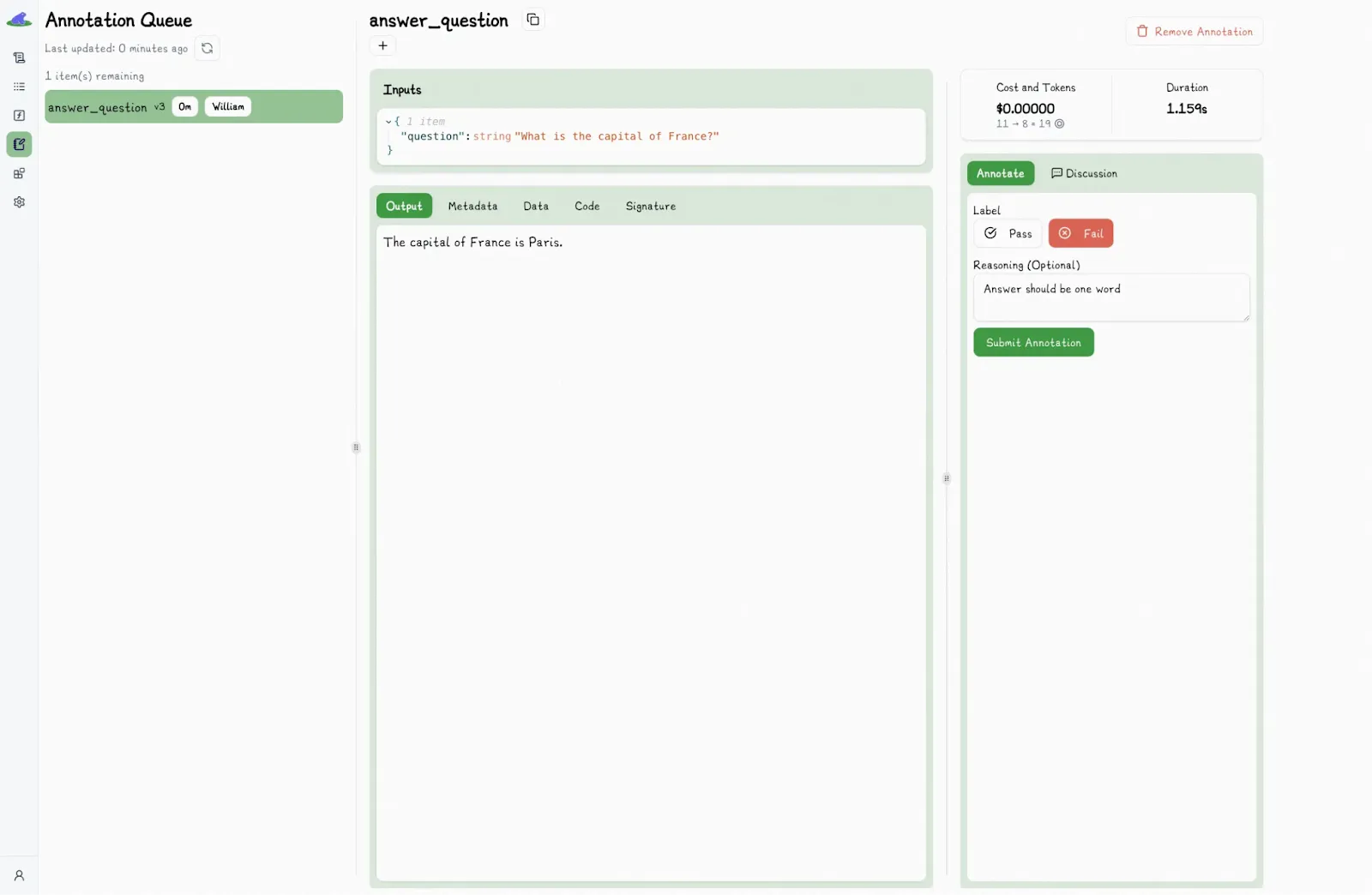
We encourage users to manually label outputs, especially early in a project. Because each label is tied to a specific versioned output, it helps build high-quality, human-annotated datasets that can later be used to train automated evaluation systems, such as LLM judges, which we plan to launch soon.
The goal is to move from manual labeling to semi-automated evaluation where an [LLM-as-judge](/blog/llm-as-judge) proposes labels, and a human evaluator verifies or rejects them. This works well since verifying is usually faster than creating from scratch.
Nonetheless, even with automated methods, keeping a human in the loop for final verification is advised, as automated systems (no matter how good) can still miss things that only a human can properly judge.
### Manage Your Prompt Workflow with Lilypad
[Lilypad](/docs/lilypad) is free to get started with, no credit card required, and offers paid plans for growing teams.
You can open a free account using your [GitHub](https://github.com/mirascope/lilypad) credentials. Lilypad also supports [Mirascope](/docs/mirascope), our lightweight toolkit for building [LLM agents](/blog/llm-agents).
## 2. PromptLayer: Closed-Source Simplicity With Drag-and-Drop Prompt Tools

[PromptLayer](https://www.promptlayer.com/) is a developer tool that helps you monitor and manage prompts by acting as a lightweight wrapper around OpenAI’s Python SDK.
It logs each API call along with its metadata, so you can trace how your prompts behave and search through them later via a visual dashboard. It integrates easily without major rewrites or architectural changes, and your API keys stay local.
PromptLayer is closed-source, supports no-code prompt editing, a drag-and-drop agent builder, and a visual prompt registry to help teams collaborate on LLM workflows. It works with LangChain and LiteLLM, supports Hugging Face models, and offers a self-hosted option for enterprise users.
Pricing starts at $50 per user/month for Pro, but there’s a free tier for small-scale use, which includes 5,000 requests per month and 7 days of log retention.
## 3. Langfuse: Open Source Monitoring, Pay to Power Up Evaluation

[Langfuse](https://langfuse.com/) is an open-source platform for LLM observability and evaluation, designed to give users full visibility into how AI agents and applications behave in production. It offers end-to-end tracing, prompt management, monitoring, dataset testing, and a full evaluation suite.
Unlike LangSmith, which is closed source and built tightly around the LangChain ecosystem, Langfuse is framework-agnostic and integrates broadly across the LLM stack. While it still supports LangChain integrations, it’s a fit for teams that aren’t exclusively tied to those tools.
Langfuse provides a self-hosted version for free (observability only), while advanced features like the Playground and LLM-as-judge evaluators require a paid license.
Cloud pricing starts at $29/month, with a Pro tier at $60/user/month (or $100/user/month for self-hosted users needing full functionality). Startups get 50% off cloud plans.
## 4. Helicone: Real-Time Dashboards and Workflow Tracing, No Lock-In

[Helicone](https://www.helicone.ai/) allows you to monitor, debug, and optimize LLM applications in real time. It emphasizes ease of integration and flexibility, offering features like session tracking, prompt management, workflow tracing, and real-time dashboards.
Compared to LangSmith, Helicone is entirely open source and free to self-host with no license requirements. You can deploy it via Docker Compose, Kubernetes, or custom setups. It works well with providers like OpenAI, Anthropic, and Gemini by simply changing the base URL or using their SDK.
Helicone also includes extras like caching, threat detection, key vaults, and user-level segmentation features not natively built into LangSmith. Although LangSmith has more advanced evaluation tooling, Helicone is better suited for dev teams wanting a general-purpose observability layer across providers.
Helicone operates on a volumetric pricing model that gets cheaper with more requests. The paid tier starts at $20/seat/month, capping at $200/mo for unlimited seats for fast-growing teams.
## 5. Orq.ai: Closed-Source Control for High-Stakes LLM Deployments
[Orq.ai](http://Orq.ai) is a closed-source, end-to-end LLMOps platform launched in February 2024\. It supports over 130 LLMs and offers features for experimentation, deployment, and evaluation.
The platform comes with dedicated playgrounds for testing prompts and model behavior, tools for deploying applications with safety checks, and built-in observability that lets you trace every step of the pipeline. You also get performance insights like latency, cost, and output quality, plus automated and human-in-the-loop evaluations to improve results over time.
Orq.ai supports hybrid and self-hosted setups, making it flexible for enterprise environments. It offers a free tier for small teams, while paid plans (starting at $250/month) unlock more logs, users, and API call limits.
The platform is still relatively new, so community support and third-party integrations may be more limited than those of mature platforms.
## 6. Phoenix: Open-Source Observability With ML Roots
[Phoenix](https://phoenix.arize.com/) by Arize AI is an open-source observability tool that allows you to evaluate, debug, and monitor AI models (large language models included).
It supports OpenTelemetry-based tracing to give visibility into how LLM apps run, alongside built-in tools for prompt management, dataset versioning, and interactive experimentation.
You can benchmark different models and prompt variations, run structured experiments, and track key metrics like latency, error rate, and cost.
The platform also includes a playground for tuning prompts and replaying traces, though its interface leans more toward general ML workflows than LLM-specific use cases, so teams building chatbots or agentic systems might find its interface less intuitive.
It doesn’t offer prompt templating or full-stack orchestration, so it’s better suited as a complementary tool rather than an all-in-one platform. Pricing starts at $50/month, but usage is free to get started.
## 7. OpenLLMetry: OpenTelemetry for LLMs, Plugged Into Your Stack
[OpenLLMetry](https://www.traceloop.com/openllmetry) is an open-source observability layer for LLM apps that lets you monitor and debug complex workflows with minimal friction. It’s built on top of OpenTelemetry and offers a non-intrusive way to trace LLM executions and understand how your application behaves in real time.
You can export trace data to Traceloop or plug it into your existing observability stack, including tools like Datadog, Honeycomb, or Dynatrace. This makes it a great fit for teams that already rely on OpenTelemetry-compatible platforms and want to layer in LLM-specific insights without overhauling their infrastructure.
It also supports features like agent tracing for multi-step reasoning, prompt templating, and experimentation to help refine your workflows.
There are no direct fees for OpenLLMetry since it’s open source, but you may incur costs from the infrastructure or third-party platforms where you export and process the observability data.
## 8. HoneyHive: Built-In Prompt Studio With Versioning and Guardrails

[HoneyHive](https://www.honeyhive.ai/) provides end-to-end visualization into AI agent interactions using OpenTelemetry standards. It captures detailed distributed traces, logs, and metrics across multi-step AI pipelines, including retrieval, tool use, model inference, and guardrails, enabling fast debugging and root cause analysis.
HoneyHive has built-in support for automated and human evaluations, which can be embedded directly into your CI/CD workflows. This allows you to catch regressions early and continuously monitor quality in production.
It also includes a Prompt Studio with version control, [LLM tools](/blog/llm-tools), and dataset management features like filtering, annotation, and export, making it easier to curate data for fine-tuning and ongoing model improvement for AI applications.
The platform has a free plan and an enterprise tier with custom usage limits, self-hosting options, and support for SSO/SAML.
## 9. Portkey: Centralize Prompt Development Across Models and Teams
[Portkey](https://portkey.ai/) helps you build, monitor, and manage LLM applications and offers a unified API to connect with over 250 AI models like OpenAI, Anthropic, and Stability AI, while layering in performance optimization, observability, guardrails, and budget control features to streamline the entire development lifecycle.
It’s built on OpenTelemetry and captures 40+ metrics for every request, including cost, latency, accuracy, and more. Its distributed tracing provides end-to-end visibility for faster debugging and root cause analysis.
PortKey also includes a collaborative Prompt Playground and Library with version control, templating, and deployment support across all 250+ models, which is great for multi-model workflows and iterative prompt development.
Portkey offers a Free Developer Plan, a Production Plan at $49/month, and custom pricing for Enterprise users who need advanced support and scalability.
## Get Started With Lilypad
Lilypad automatically versions your prompt and traces every function call, so you can easily reproduce results, debug faster, and track changes across runs. Its interface keeps everyone in sync, improves collaboration, and supports ongoing testing, iteration, and growth.
With built-in support for OpenAI, Anthropic, and more, Lilypad gives you the structure you need to build reliable LLM apps faster.
Want to learn more? Check out Lilypad code samples on our [documentation site](/docs/lilypad) and [GitHub](https://github.com/mirascope/lilypad). Lilypad offers first-class support for [Mirascope](/docs/mirascope), our lightweight toolkit for building AI agents.
9 LangSmith Alternatives in 2025
2025-06-24 · 12 min read · By William Bakst