Prompt versioning means giving each iteration of a prompt its own identifier, so you can tweak and test different versions without losing track. It lets you compare results, roll back to earlier versions, and see what actually works over time.
In regular coding, versioning is standard, but with prompts for language models, it's even more important. That’s because LLMs are non-deterministic, and **don’t always behave the same way, even if you feed them the exact same input**.
The results also change based on things like model settings, system messages, or temperature. So if you want consistent, high-quality outputs, you need to track every piece of the puzzle.
That’s where prompt versioning comes in. It helps you treat prompting like a real optimization problem, not just trial and error. You can start isolating variables, testing what matters, and getting repeatable results.
One way we do this is by wrapping prompts inside Python functions and decorating them with `@lilypad.trace`. This lets us cleanly separate prompt logic from the rest of the code and track every change. It’s an effective way to measure what’s really influencing the model’s output.
Ultimately, when your code isn’t well structured, **you end up having to think through the optimization process rather than just improving it**. That’s why we built Lilypad, an open-source framework that views prompt engineering as an optimization problem that should be addressed using best practices in software development.
In the rest of this article, we’ll walk you through five top frameworks (including Lilypad) for managing prompt versioning and optimization.
* [Lilypad](#1-lilypad-structuring-ai-development-for-continuous-improvement) — software developer-inspired prompt engineering, versioning, and management.
* [LangSmith](#2-langsmith-prompt-versioning-from-a-central-hub) — prompt versioning from a central hub.
* [Langfuse](#3-langfuse-direct-integration-with-llms-without-a-proxy-layer) — direct integration with LLMs without a proxy layer.
* [Weave](#4-weave-suite-of-ai-tools-and-custom-models) — suite of AI tools and custom models.
* [PromptHub](#5-prompthub-user-friendly-collaborations-for-team-members) — user-friendly collaborations for team members.
## 1. Lilypad — Structuring AI Development for Continuous Improvement
[Lilypad](/docs/lilypad) addresses the challenges of working with non-deterministic LLM outputs by providing open source tools for automatic versioning and tracing of LLM calls, allowing you to manage and evaluate prompts.
Lilypad supports prompt engineering as an optimization process by:
* Automatically versioning code every time it runs so you can properly track and measure every LLM interaction.
* Annotation tooling purpose built for kickstarting your data flywheel.
* Making it as simple as possible for (non-technical) domain experts to collaborate in prompt development, including labeling and evaluating prompts.
* Integrating into existing workflows through its compatibility with various LLM providers and frameworks (e.g., LangChain, Mirascope, etc.), making it provider and tool agnostic.
* Flexible enough to handle any aspect of prompt engineering, even retrieval for RAG applications.
* First-class type-safety.
We dive into how Lilypad implements these key features.
### Structure Your Code for Complete Traceability
Lilypad promotes traceability and software developer best practices starting with the way it encapsulates LLM calls, including all inputs and parameters needed for that call, within functions.
This colocates everything required for tracking prompts, model configurations, and function logic, like the prompt template, any pre- or postprocessing steps, etc.
It also prevents mixing of elements together with business logic, which would make it harder to isolate variables and track changes.
Below is an example of an LLM call, along with all relevant parameters, wrapped in a function:
```python{7-14}
import lilypad
from openai import OpenAI
lilypad.configure(auto_llm=True)
client = OpenAI()
@lilypad.trace(versioning="automatic")
def recommend_book(genre: str) -> str:
completion = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": f"Recommend a {genre} book"}],
)
return str(completion.choices[0].message.content)
if __name__ == "__main__":
response = recommend_book("science fiction")
print(response)
```
Note the function is decorated by `@lilypad.trace(versioning="automatic")`. This structures the LLM API call as a non-deterministic function that takes a set of inputs (i.e., the function's arguments) and returns a final, generated output (i.e., the function's return value). The `@lilypad.trace` decorator tells Lilypad that this function should be traced every time it executes so we can capture things like the input arguments and output (as well as latency, cost, etc.).
By specifying `versioning="automatic"` , **we're telling Lilypad that this function should be automatically versioned every time it executes**. This makes it easy to compare different versions of your prompts by comparing the two different function versions and their outputs.
And it does this using only a few lines of code. So by adding the `trace` decorator to a function, you're ensuring that any and all changes get automatically versioned and traced every time you run the code. And the output will show up in Lilypad:
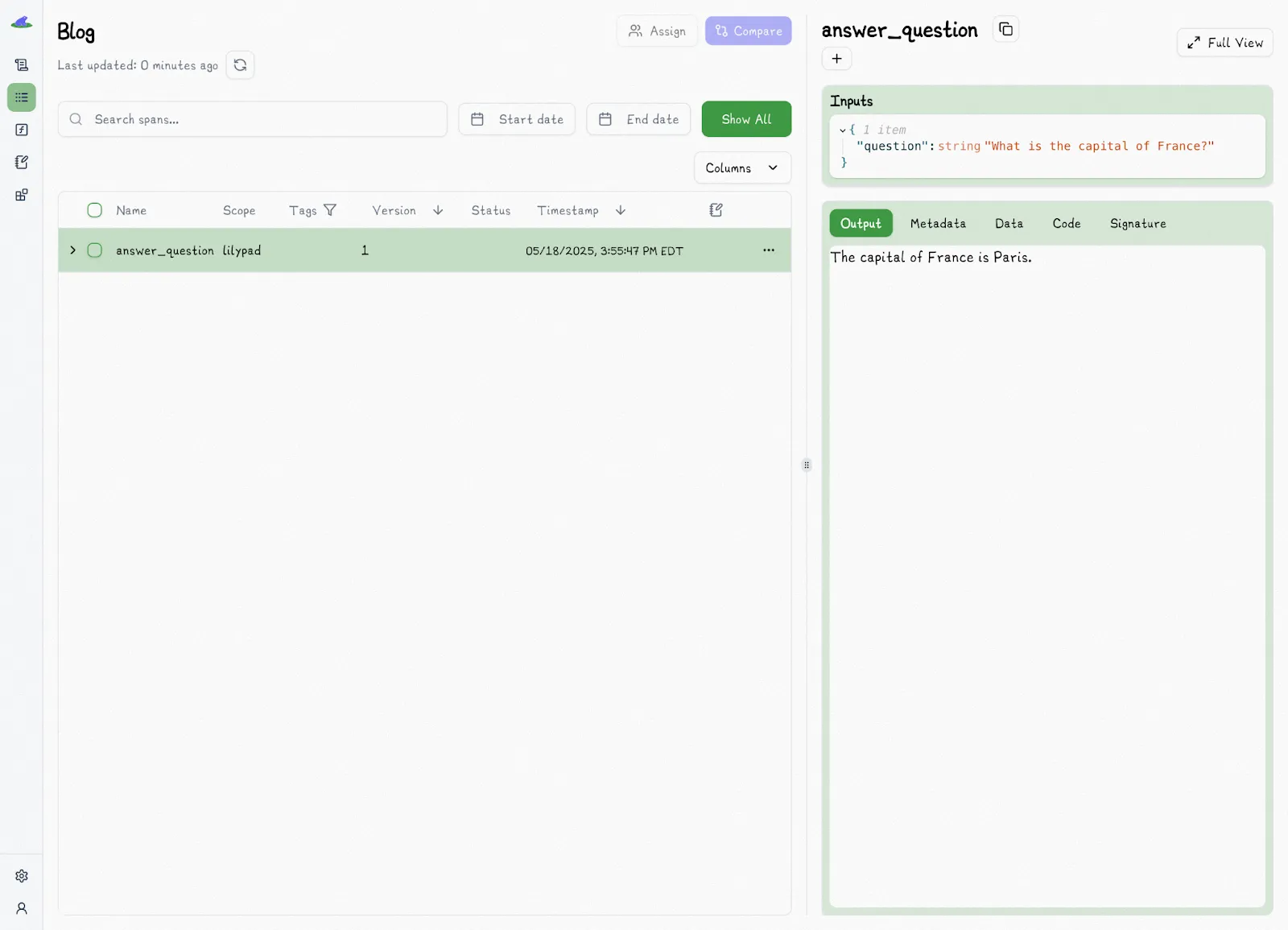
Note the version numbers: Lilypad assigns this initial version as V1. To the right you see a panel with all of the trace information, such as the output. Running the same function again will capture that execution's trace against the same version.
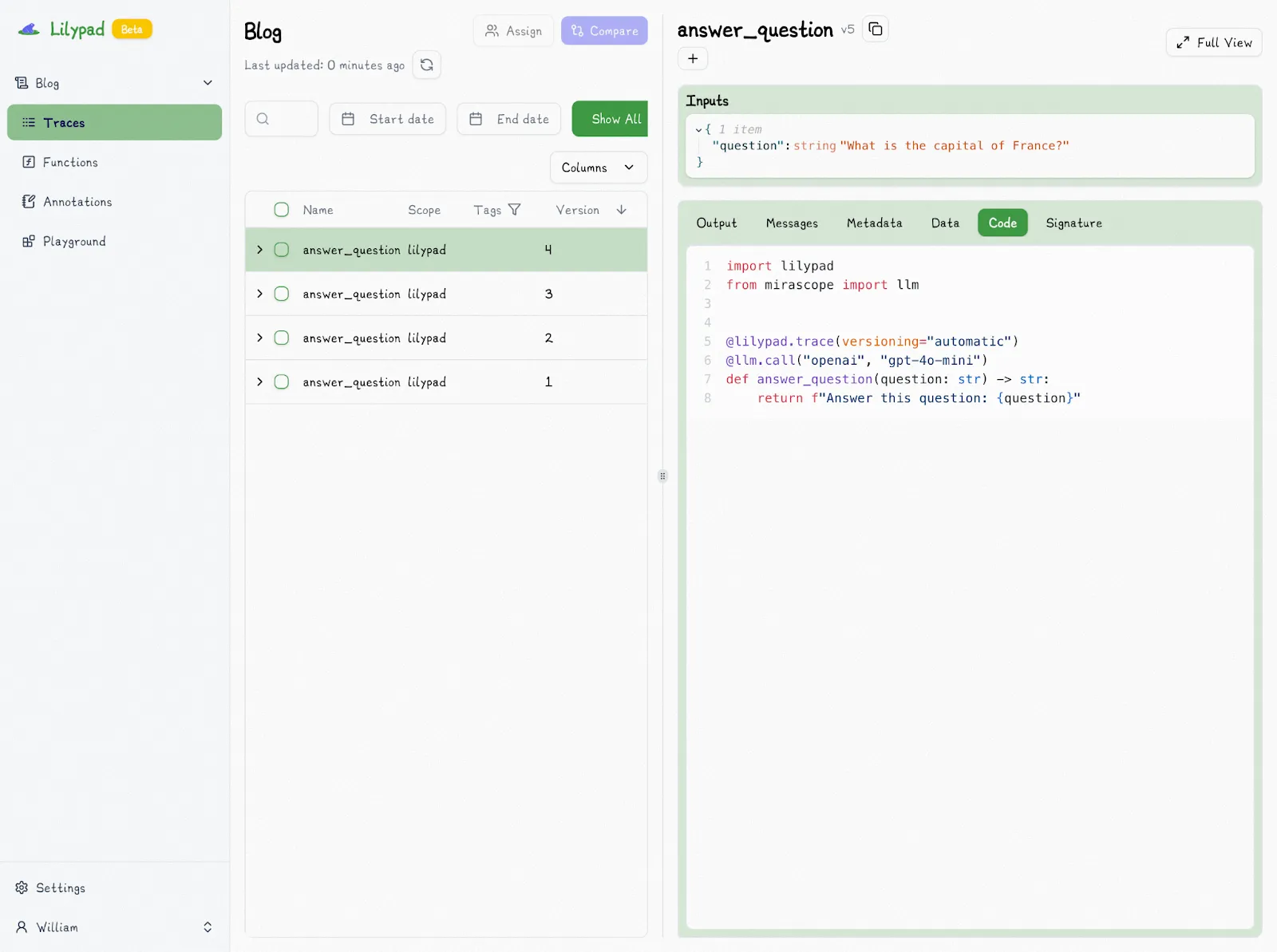
When we change the model type in the call to `gpt-4o`, Lilypad automatically increments it to V2:
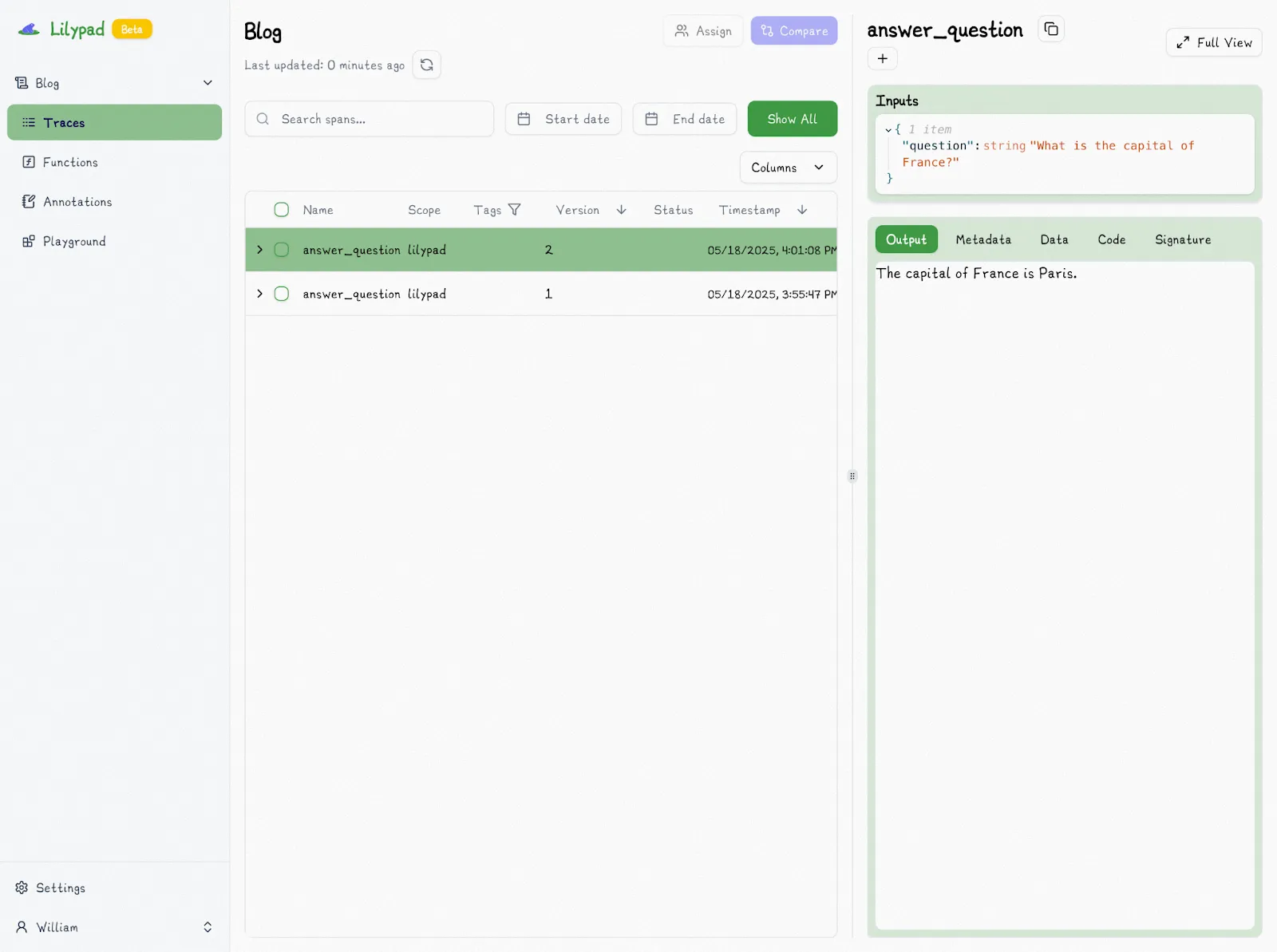
Changing any aspect of the function automatically increments the version number. In fact, Lilypad will automatically detect the correct version so you can simply revert and not worry about properly tracing everything. And if a change is identical to a previous version, Lilypad won’t create a new version because it will detect the existing version automatically.
This makes comparing versions extremely easy:
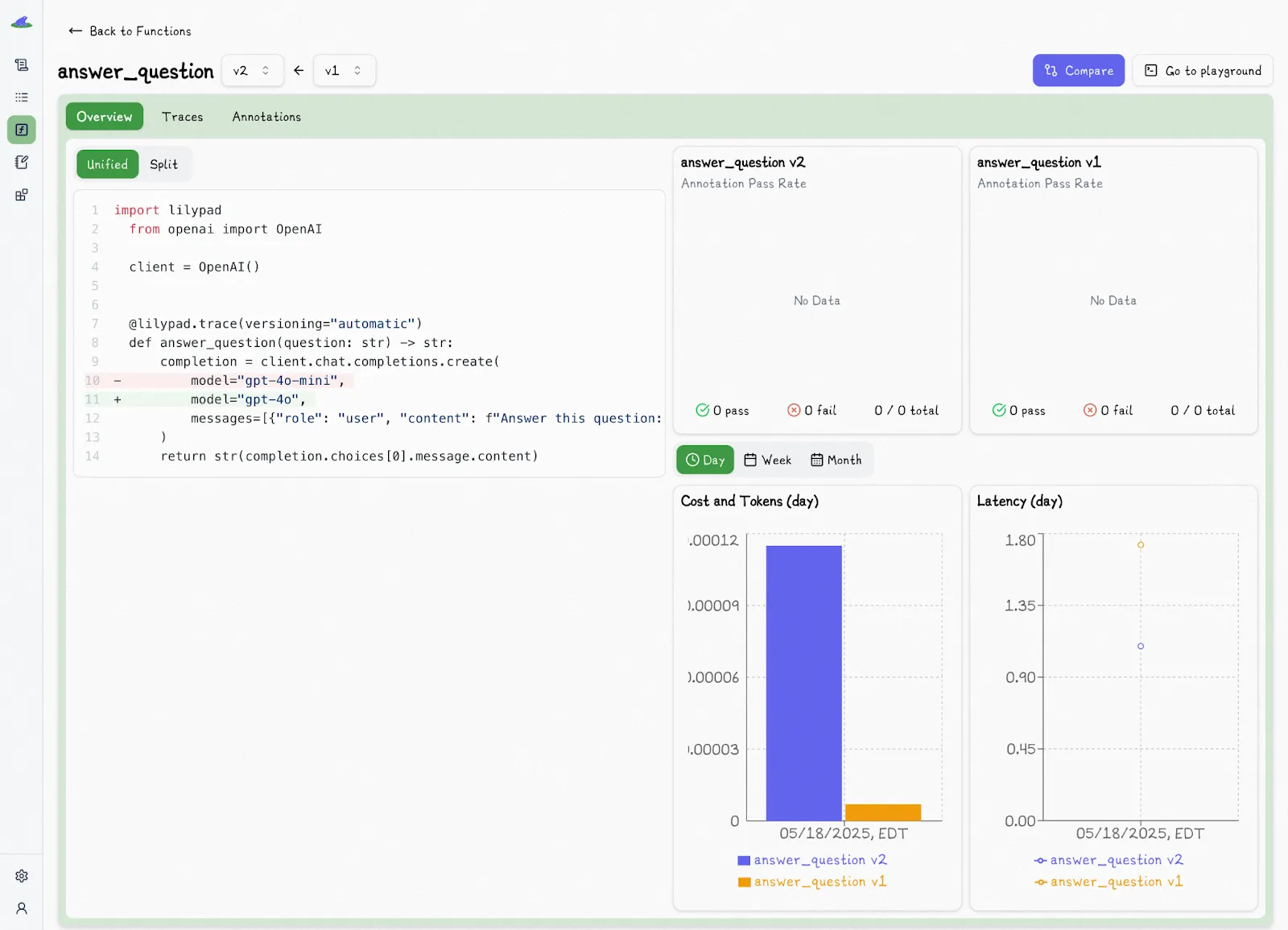
Lilypad versions LLM calls using their function closure, which means any user-defined functions or classes it interacts with (that are within scope) **are also logged and tracked automatically**.
For example, we may decide that we want to structure our outputs, which will affect the return type of our function:
```python{8-10,14}
import lilypad
from openai import OpenAI
from pydantic import BaseModel
lilypad.configure(auto_llm=True)
client = OpenAI()
class Answer(BaseModel):
reason: str
answer: str
@lilypad.trace(versioning="automatic")
def answer_question(question: str) -> Answer | None:
completion = client.beta.chat.completions.parse(
model="gpt-4o-mini",
messages=[{"role": "user", "content": f"Answer this question: {question}"}],
response_format=Answer,
)
return completion.choices[0].message.parsed
if __name__ == "__main__":
response = answer_question("What is the capital of France?")
print(response)
```
Now even changes to the return type will be correctly captured as a new version:
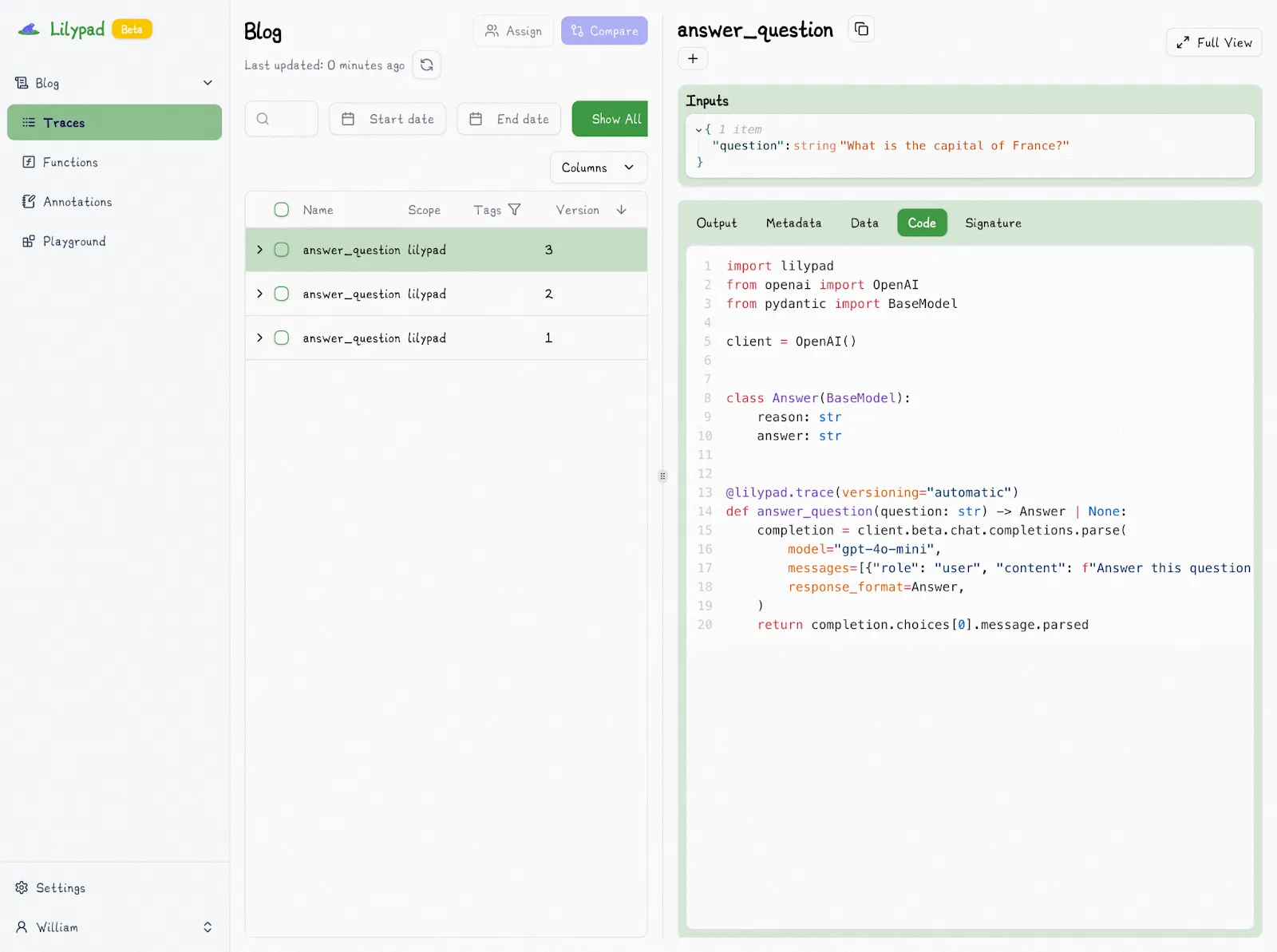
The `auto_llm=True` setting ensures Lilypad also traces and logs every LLM call made (using the [OpenTelemetry Gen AI spec](https://opentelemetry.io/) to make observability easier) to give you an exact snapshot of each LLM output to help you monitor the performance of prompts over time:
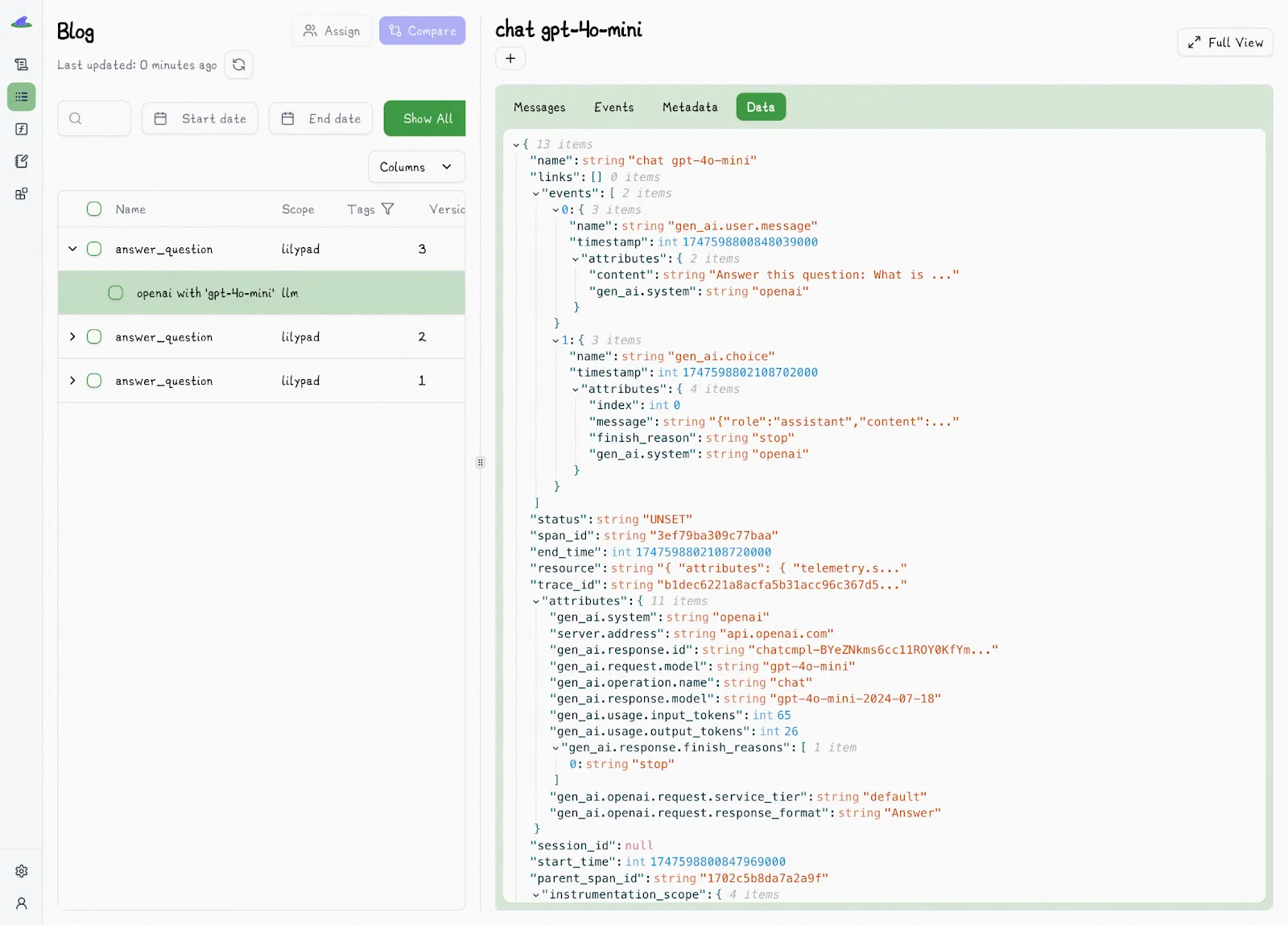
Any of these spans will properly appear nested inside of whichever other span or trace contains their execution.
### Collaboration with Non-Technical Experts
Managing and iterating on prompts in collaborative workflows presents several challenges:
* Prompt changes normally force developers to modify and redeploy the codebase, slowing down development.
* (Non-technical) domain experts often lack the technical skills to modify prompts directly in the codebase, making them reliant on developers for even minor changes.
* Without a dedicated environment, it's difficult for domain experts to test and evaluate prompts independently (again, without needing help from developers).
As described in the last section, Lilypad provides a playground that allows non-technical team members to iterate on prompts (and run them) through an intuitive GUI, reducing the need for direct engineering involvement:
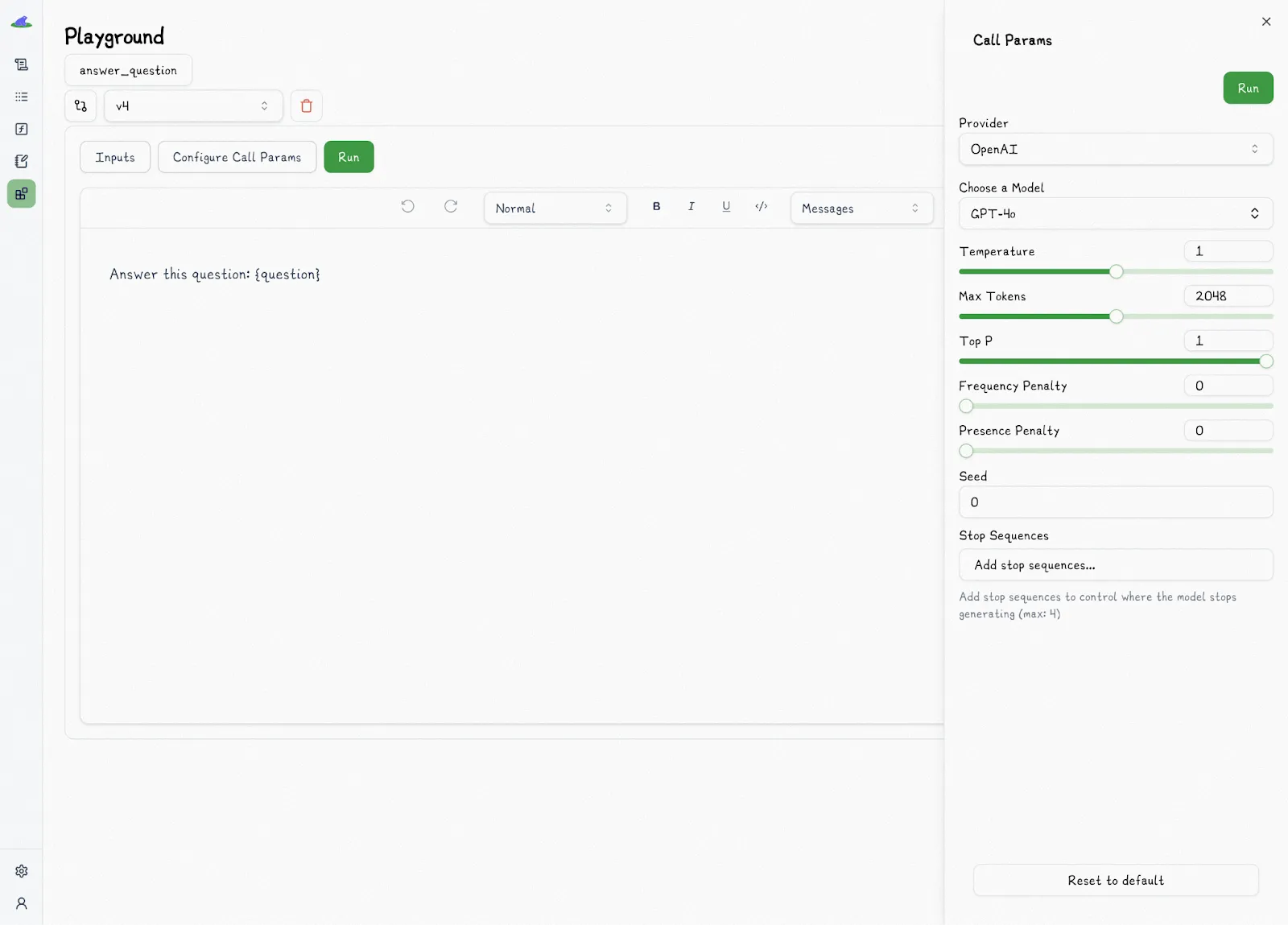
The playground attaches to a versioned function, and every time it runs it will be traced and versioned automatically against that function.
This means that domain experts can create, change, and iterate on prompts autonomously without requiring the usual back-and-forth with developers, who can separately use the matching code, the `.version` method, or the `.remote` method to use exactly that version of the function downstream to integrate it with their application.
```py
# runs the remotely deployed version
recommend_book.remote("fantasy")
```
The playground shows details of prompts and outputs, including:
* Markdown-supported prompt templates, and any Python function associated with it
* Call settings, like provider, model, and temperature
* Prompt arguments and values (Lilypad uses type-safe function signatures for the variables used in prompt templates — see the screenshot further down below)
* LLM outputs, including raw outputs and traces
* Metadata like token usage and cumulative costs, as shown below
In the prompt template below, we provide type-safe function signatures for the variable values:
This ensures that the code running in the playground can be used 1:1 exactly as run downstream in your application, and that running that code will trace it against the correct version automatically.
### Evaluate Non-Deterministic LLM Outputs
Prompt versioning and evaluation go hand-in-hand, as versioning lets you measure the effectiveness of iterations in a structured way to see which one yields the most desirable result.
The fact we’re versioning inputs that produce non-deterministic outputs makes this challenging as we can't just define a bunch of test cases and call it a day.
Instead, evaluating LLM outputs often involves subjective judgment. Determining whether an output is "good enough" depends on the specific use case, the desired quality bar, and the nuances of human language.
For example, if you're trying to extract user info, the metric you want to optimize for is often just correctness. So in this case, "was the extraction correct?" would be a good enough metric to measure progress and detect regressions, rather than using an overly complex scoring system.
Even a granular scoring for instance (e.g., a scale from one to five) can be tricky as it’s often unclear what a "3" vs. a "4" really means or where to draw the line on what’s considered good enough.
We therefore find pass/fail metrics to be mostly efficient in allowing you to track the reasons for failures and successes, and to use that information to improve your outputs.
When it comes to collaborative evaluation, Lilypad makes this easy by allowing non-technical teams to annotate LLM outputs using pass/fail criteria to indicate the most effective prompts.
You just choose a particular trace to evaluate:
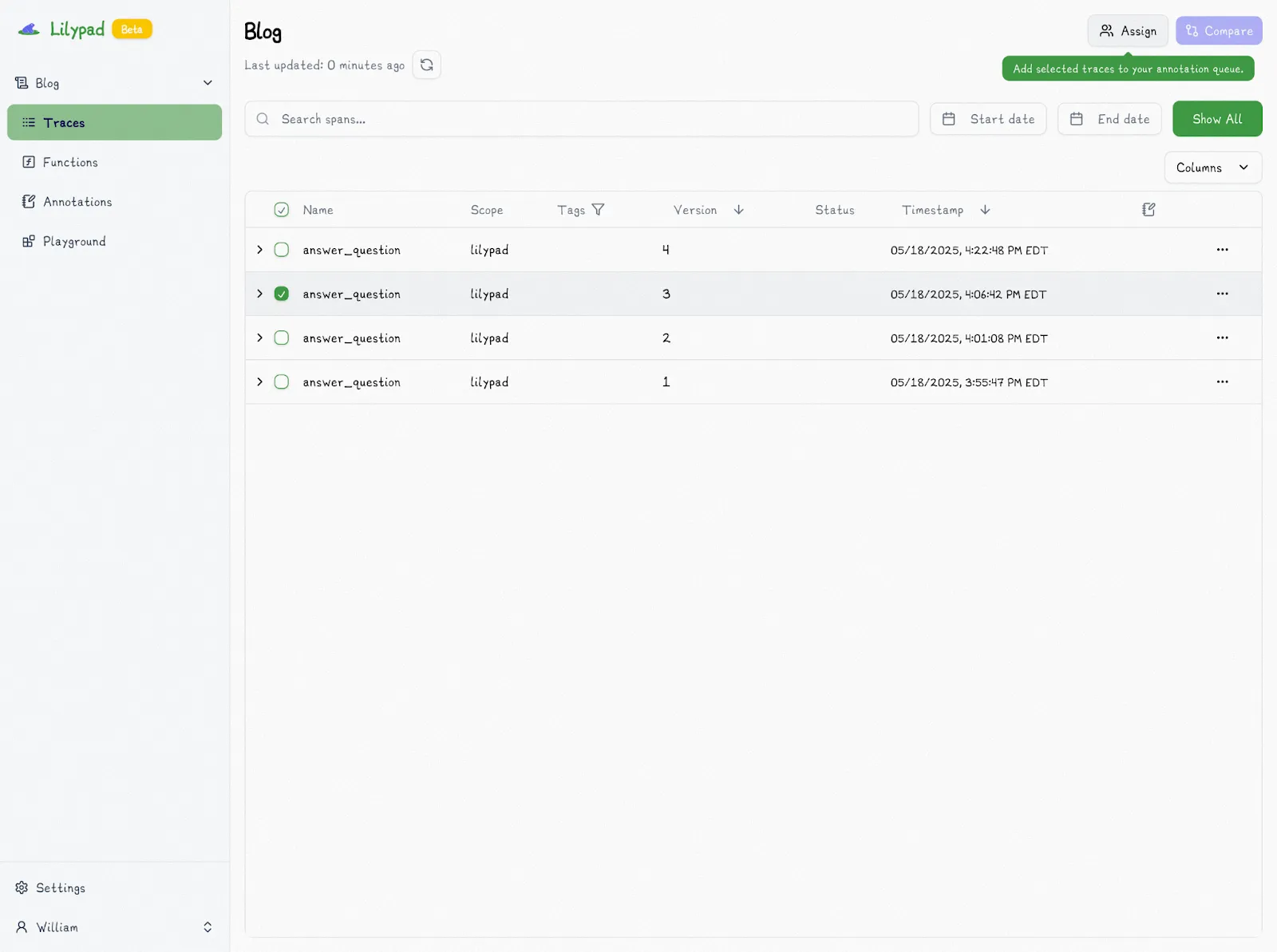
And then mark the trace as “Pass” or “Fail” with an optional reason:
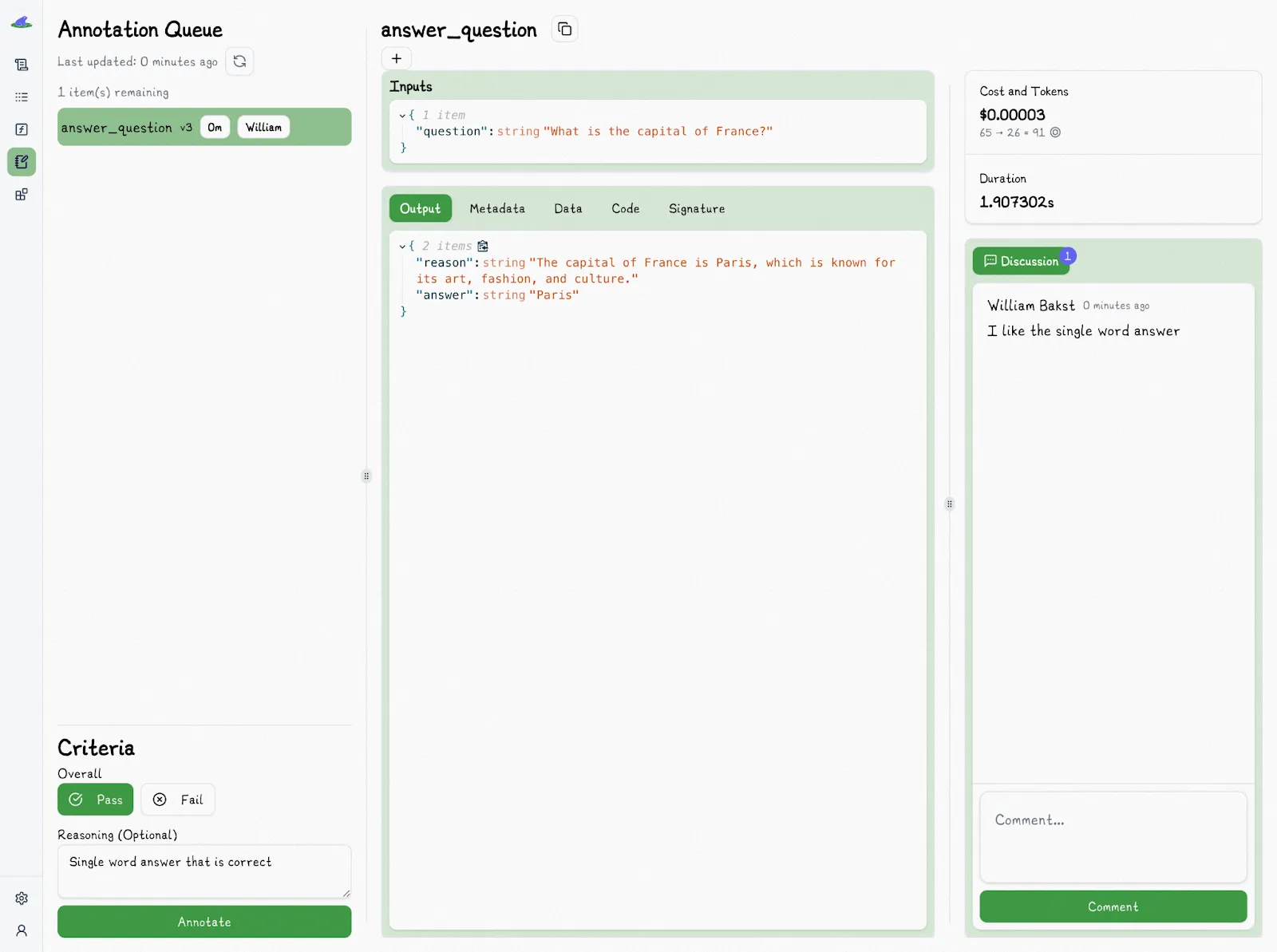
You'll notice that we also utilize the discussions to provide additional unstructured metadata for other team members.
Bootstrapping the evaluation in this way with a human evaluator with enough domain expertise to properly annotate and kickstart the system allows you to later automate it using a system like LLM-as-a-judge, which we’re intending to launch in the future.
Using LLM-as-a-judge would then move the majority of the work from labeling to verification, which promises to make the process more manageable. You can then verify the accuracy of the judge with a human-in-the-loop, continuing to improve the judge until you need to intervene less thanks to a high level of confidence in the judge’s accuracy.
In the meantime, consistently annotating outputs lets you know whether they're improving or not and helps you build data sets against which you can test future versions of your application.
It’s nonetheless important to look at your data with your own eyes as that's the best way to identify where things are failing and how to improve them. **We recommend you always do this, even if using an LLM judge**, in order to identify outputs where the judge lacks confidence.
### Manage Your Prompts with Confidence
Lilypad simplifies prompt versioning so you can experiment with ease. With built-in tracking, collaboration tools, and seamless version control, you’ll always know what changed, why it changed, and how to improve your LLM outputs.
[Get started with Lilypad](/docs/lilypad) by opening a free account using your [GitHub](https://github.com/Mirascope/lilypad) credentials. Lilypad also supports [Mirascope](/#mirascope), our lightweight toolkit for building AI agents.
## 2. LangSmith — Prompt Versioning from a Central Hub

[LangSmith](https://www.langchain.com/langsmith) is a closed-source tool for managing and optimizing the performance of chains and intelligent agents in LLM applications. Its parent framework is LangChain, with which it integrates, although you can use LangSmith on its own or with other tools besides LangChain. Note however, that while LangSmith is able to trace calls made by third-party tools, it’s less likely to version them.
LangSmith offers a centralized prompt repository (LangChain Hub) with functionality for archiving and versioning prompts. To use prompts that are saved to LangSmith Hub, you typically use its `pull` command specifying the prompt to download, along with its commit hash (version).
While the hub is a prompt management environment to which you push prompts and their changes to it, it also lets you manage and run chains containing the prompts.
You can find more information about how to manage prompts in LangChain Hub in its documentation and on its website.
## 3. Langfuse — Direct Integration with LLMs Without a Proxy Layer
[Langfuse](https://langfuse.com/) is an open-source LLM platform that helps teams collaboratively debug, analyze, and iterate on their LLM applications.
It offers a prompt CMS (content management system) for managing and versioning your prompts, allowing non-technical users to work with prompts while not requiring you to redeploy your application.
Langfuse lets users link prompts with traces to understand performance in the context of LLM applications, and monitor which prompt versions were used in specific traces.
You can also generally track usage statistics and manage execution logs.
It supports integration with LangChain, Vercel AI SDK, and OpenAI functions and allows for quick rollbacks to previous prompt versions if needed.
For more information on how Langfuse’s prompt management works, you can consult its user documentation or see details on GitHub.
## 4. Weave — Suite of AI Tools and Custom Models
[Weights & Biases Weave](https://wandb.ai/site/weave/) is a framework for tracking, experimenting with, evaluating, deploying, and improving LLM\-based applications. It allows users to choose from a variety of AI models to work with, and to create, save, and iterate on different types of prompts, such as StringPrompt and MessagesPrompt, which can be easily formatted and parameterized.
Weave also allows users to compare different versions and revert to previous ones if needed, as well as to set up custom workflows for tasks like generating game content, creating chatbots, and implementing AI agents.
It provides a comprehensive API allowing developers to interact with its features using languages like JavaScript, Python, and Java, and you can create custom dashboards from these APIs and functions.
You can find more information on Weave’s prompt management in its documentation and on its website.
## 5. PromptHub — User-Friendly Collaborations for Team Members
[PromptHub](https://www.prompthub.us/) is a prompt management platform for teams. It lets you test, collaborate, and deploy prompts, and features built-in prompt versioning, comparison, and approval workflows.
The SaaS platform offers a Git-like prompt versioning system based on SHA hashes, allowing you to commit prompts and open merge requests to collaborate on prompt design, all within a central GUI. It also offers functionality for comparing prompt versions side by side, and approving or rejecting changes.
All changes are logged and team members are automatically notified. PromptHub also provides an API letting you access your prompts from any other application.
You can find more information on PromptHub in its documentation and on its website.
## Upgrade Your Prompt Engineering Process
Lilypad's prompt versioning and management functionality was built from the ground up with software engineering best practices in mind. It offers an accessible interface for you to easily track changes across different versions of prompts to improve collaboration, and to support ongoing prompt experimentation and iteration.
Want to learn more? You can find more Lilypad code samples on both our [documentation site](/docs/lilypad) and [GitHub](https://github.com/Mirascope/lilypad). Lilypad offers first-class support for [Mirascope](/#mirascope), our lightweight toolkit for building AI agents.
Five Tools to Help You Leverage Prompt Versioning in Your LLM Workflow
2025-05-18 · 18 min read · By William Bakst