Langfuse turns prompt experimentation into a structured, collaborative workflow, helping you build faster and see what’s changing.
It lets you:
* Update prompts without redeploying your entire app, making it easy for non-technical team members to make changes.
* Test, compare, and roll back with a built-in playground for safer experimentation.
* Monitor key metrics like latency, cost, and quality across prompt versions.
* Integrate with frameworks like LangChain, Vercel AI SDK, LiteLLM, and OpenAI through the UI, SDK, or API.
Still, the experience isn’t without its tradeoffs. For example, self-hosting can be difficult to set up and maintain, with multiple infrastructure dependencies and a UI that some devs find unintuitive. Even after setup, debugging missing traces often means digging through logs and storage layers.
We built [Lilypad](/docs/lilypad) to version not only the prompt text but the entire context in which the prompt is called. This includes the logic, model settings, parameters, and structured return types, so you can iterate and debug with less guesswork when your outputs vary.
It also includes a fully type-safe, no-code playground that mirrors production behavior, so what functions in testing work exactly the same in production.
In this article, we’ll show how prompt management works in Langfuse, then contrast it with how Lilypad achieves the same goals in a simpler, more complete way.
## How Prompt Management Works in Langfuse
Below, we explain the main ways you can work with prompts in Langfuse:
### Managing Prompts via the Langfuse Console (Web UI)
Langfuse’s web console is a centralized interface for managing prompts across your LLM workflows. It’s where teams (both technical and otherwise) create, organize, and iterate on prompts without digging into the codebase.
The prompt management dashboard lists all your prompts by name and version. From there you can create, edit, label, and version-control prompts directly through the web console.
For instance, you might log into the Langfuse app and use the “Create Prompt” button to define a new template, fill in variables (e.g. `{{name}}`), and assign labels like production or staging.
An example of this is a prompt called qa-answer-with-context-chat, currently on version \#53. It’s tagged as a production-ready system prompt and contains example input/output flows for iterating in the Langfuse playground:
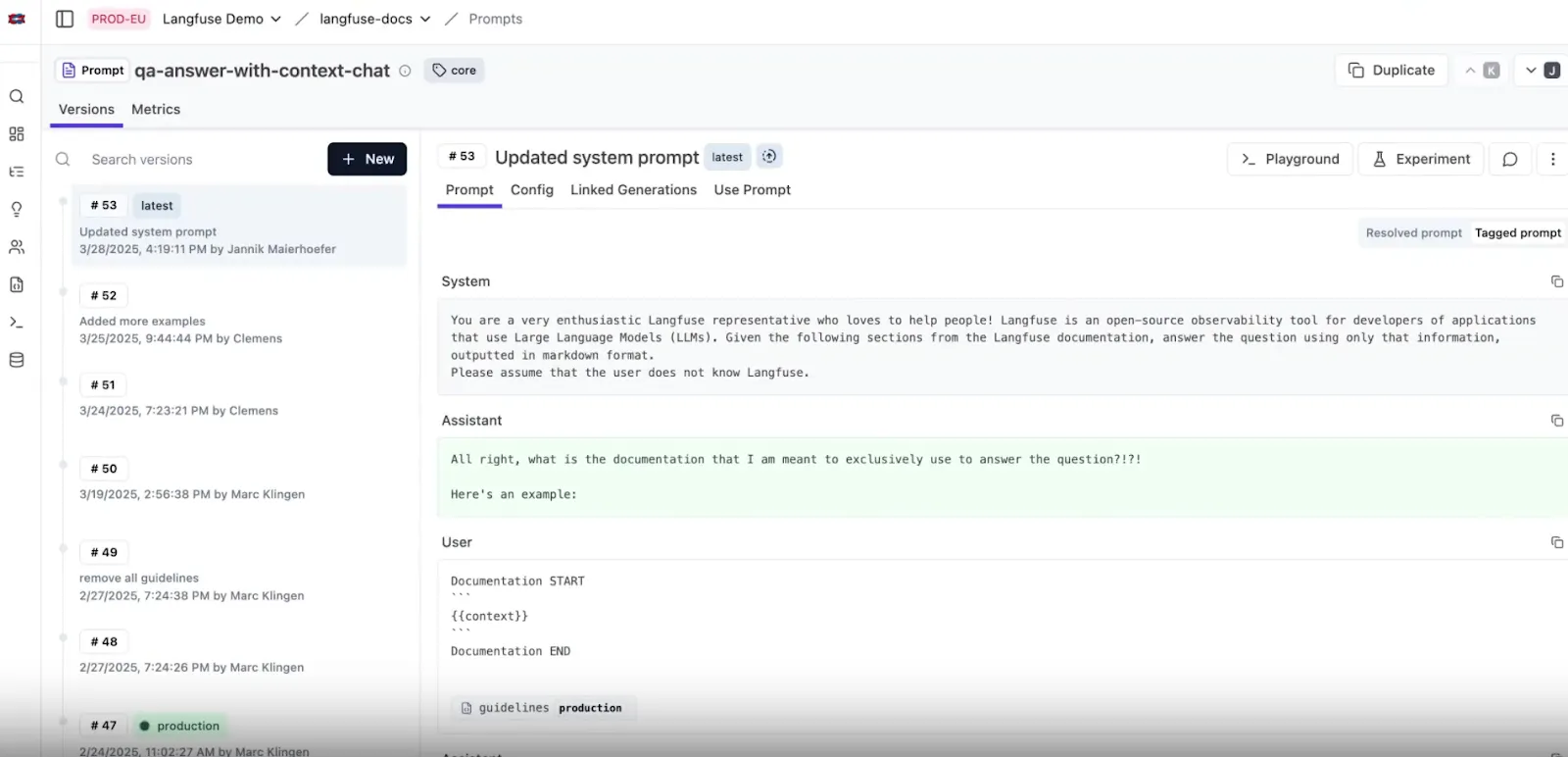
Once a prompt like qa-answer-with-context-chat is created, any edits (whether its text or configuration) are tracked automatically. Each time you change the prompt text or configuration in the console, Langfuse creates a new version each time, allowing you to compare changes side-by-side.
This is especially useful for non-technical team members, who can manage prompts and push updates without touching application code. Once a version is ready, assigning it the production label routes all runtime calls to that version. You can also define custom tags like latest, staging, or environment-specific labels.
The console also allows you to reference existing prompts within others (prompt composability) with the “Add prompt reference” button. This inserts a tag like: @@@langfusePrompt:name=OtherPrompt|label=production@@@, which pulls in the content of another prompt version:
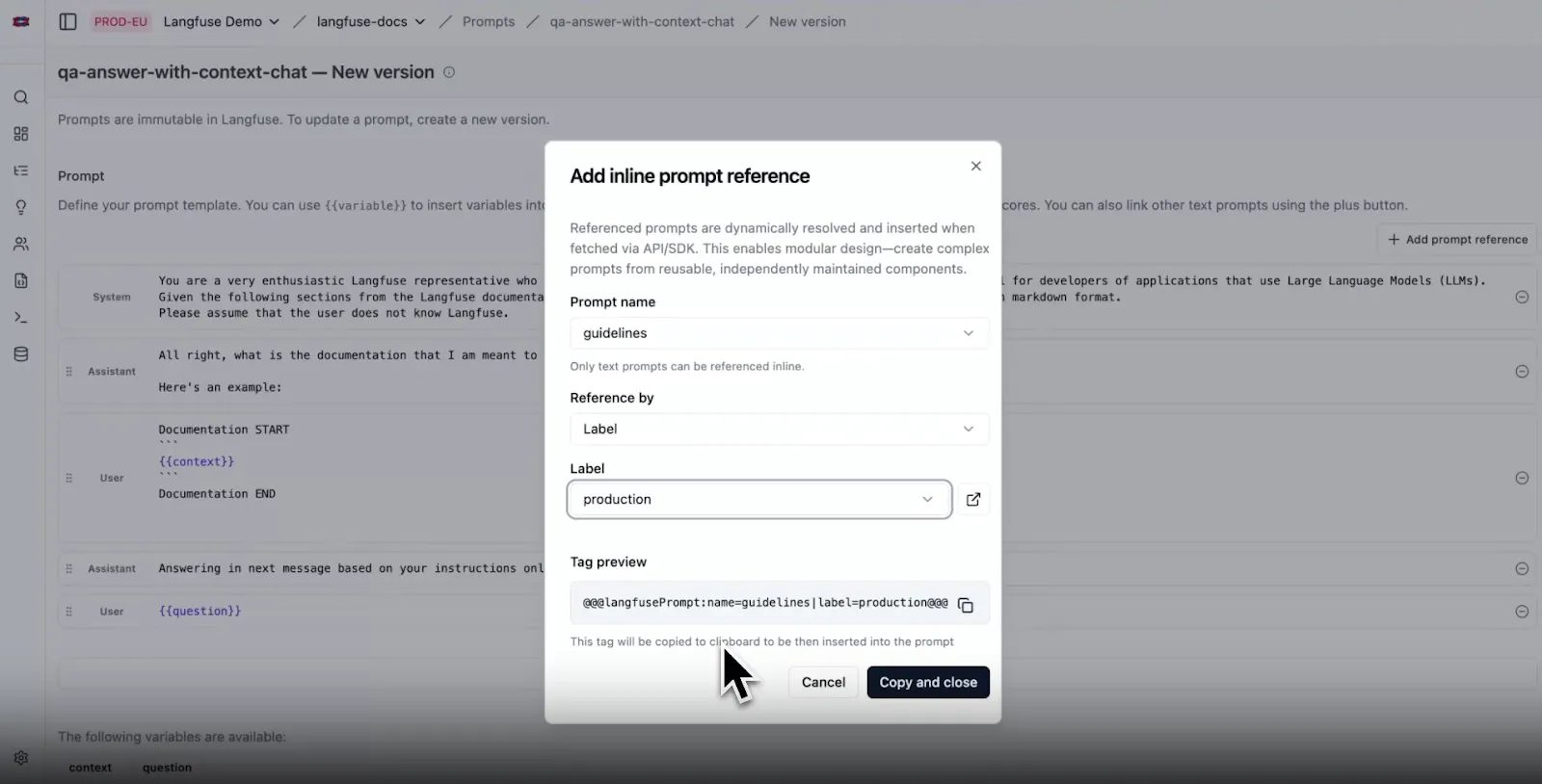
At runtime, these tags are automatically resolved, pulling in the referenced prompt’s content. This lets you build modular, reusable prompt templates right from the UI.
### Testing and Iterating in the Prompt Playground
Beyond managing prompt versions, Langfuse provides a prompt playground for hands-on experimentation. Here, you can edit prompt text and model parameters (like temperature, etc.) on the fly and immediately see how various models respond.
You either start from scratch by creating a new prompt template or load an existing version from the prompt management console to tweak and test. For example, you might pull in a production prompt, tweak some wording or variables in the playground, and compare the LLM outputs. This feedback loop helps you fine-tune prompts before pushing them to production.
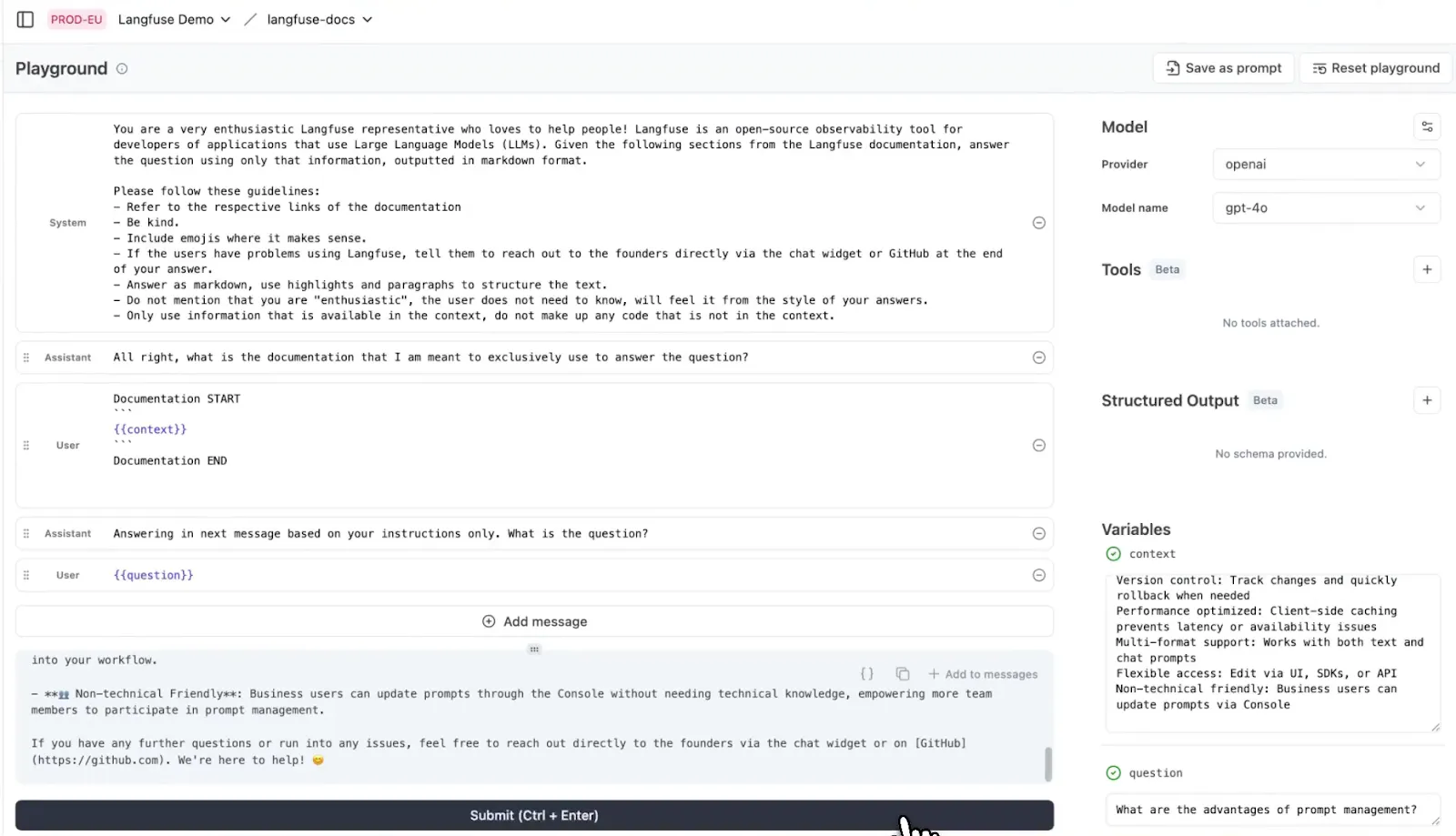
One key thing to note is that the playground is designed for iteration, not for saving or versioning prompts. Once you're satisfied with your changes, you save the updated prompt back into the prompt management section.
Some core features include variables in prompts, tool calling, structured outputs, major model providers like OpenAI, Anthropic, Bedrock, and Google.
The playground is available to all Langfuse cloud users once your LLM API keys are configured.
### Managing Prompts with the Langfuse SDK
In addition to the web console, Langfuse lets you manage prompts programmatically using its SDKs for Python and JavaScript/TypeScript, or directly through its API. This is especially useful if you want to embed prompt workflows into your CI/CD pipeline or other automated systems.
For instance, using the Python SDK, you can create a new prompt or add a version:
```python
from langfuse import Langfuse
langfuse = Langfuse()
langfuse.create_prompt(
name="movie-critic",
type="text",
prompt="As a {{criticlevel}} movie critic, do you like {{movie}}?",
labels=["production"], # immediately tag this version as “production”
config={
"model": "gpt-4o",
"temperature": 0.7,
"supported_languages": ["en", "fr"],
}
)
```
This call creates a prompt named movie-critic. If a prompt with that name already exists, Langfuse automatically logs a new version. You can also attach one or more labels like \["production"\] to route runtime calls to this version by default. Labels in Langfuse work as version pointers.
At runtime or elsewhere in code, you can retrieve a prompt and fill in its variables. For example:
```python
prompt_obj = langfuse.get_prompt("movie-critic")
final_text = prompt_obj.compile(criticlevel="expert", movie="Dune 2")
print(final_text)
# -> "As an expert movie critic, do you like Dune 2?"
```
Here, `get_prompt("movie-critic")` fetches the latest version tagged with the `“production”` label. The prompt_obj contains a template with placeholders like `{{criticlevel}}` and `{{movie}}`. When you call `prompt_obj.compile(...)`, those placeholders get populated with your variables.
By default, the SDK caches prompts after the first fetch to minimize latency on future requests. You can also fetch a prompt by specific label or version, depending on your needs. For example:
```python
# Get version 1 explicitly
old_prompt = langfuse.get_prompt("movie-critic", version=1)
# Or fetch the prompt currently labeled “staging”
staging_prompt = langfuse.get_prompt("movie-critic", label="staging")
```
**Note**: Langfuse’s prompt retrievals aren’t type-safe (unlike Lilypad’s) and so there’s no automatic check to make sure the `get_prompt` method receives the correct template arguments.
Using labels like "latest" (which always point to the most recent version), you can build workflows to promote versions, like creating a new prompt version in code, tagging it as staging, testing it, then updating the production label to promote it.
### Evaluating Prompts in Langfuse
Langfuse offers several methods to evaluate prompts. Below are some main ones:
#### 1. Prompt Experiments
Langfuse's prompt experiments let you test prompts against a fixed dataset of examples. In this setup, you create a dataset of input cases and reference outputs (ground truths), then run a specific prompt version on all of them:
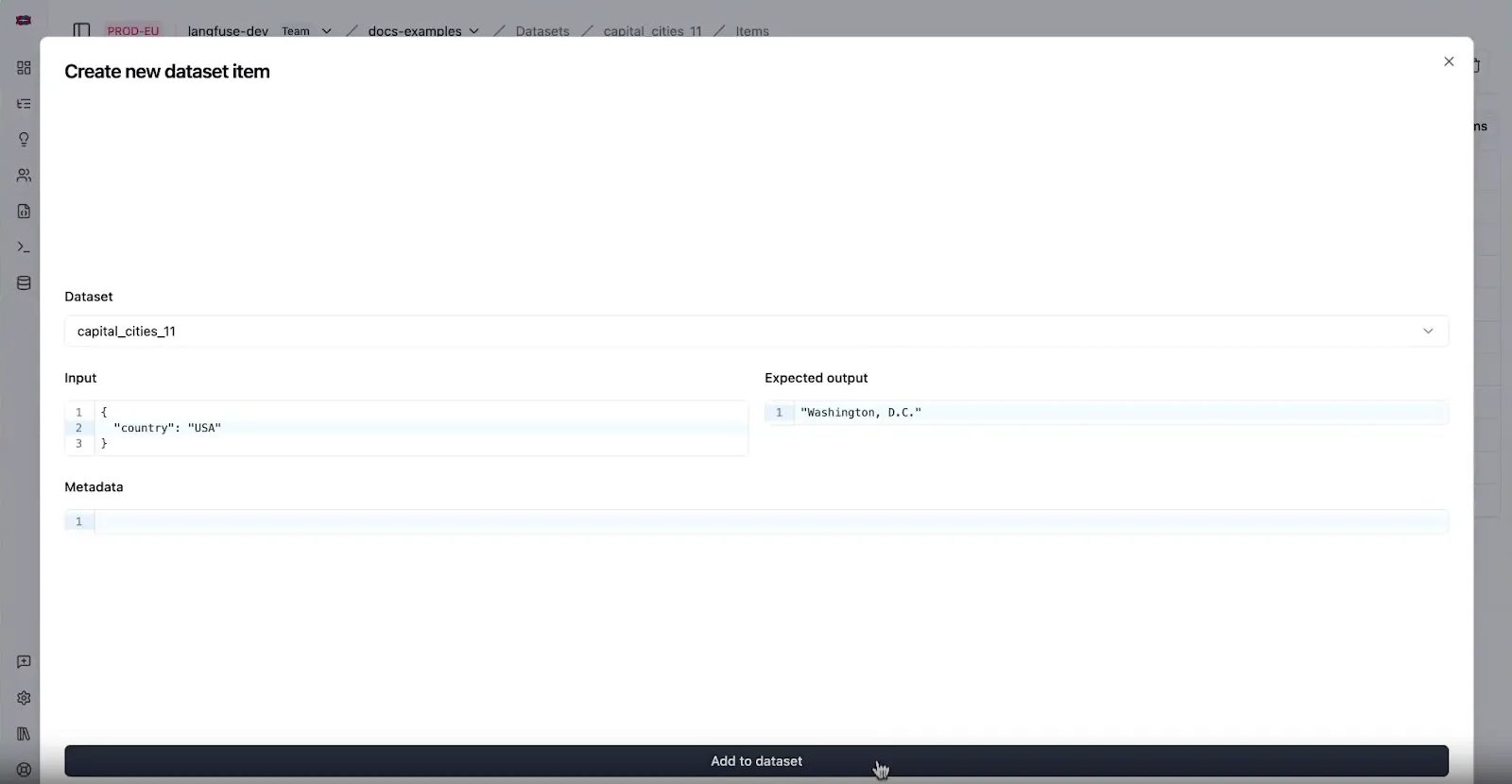
This is all handled in a no‑code UI. You pick a prompt and a dataset, map the dataset fields to the prompt variables, and click “Run.” Langfuse will generate outputs for each case and let you compare versions side by side.
This allows you to spot problems when you change a prompt (also when [prompt chaining](/blog/prompt-chaining)), since you can see if things got better or worse.
Prompt experiments also work with LLM-as-a-judge evaluators (described below) to automatically score experiment results. Just select the evaluator(s) in the UI, and Langfuse runs them across your dataset automatically.
#### 2. LLM-as-a-Judge Evaluations
Langfuse offers two main ways to use LLMs as judges:
1. **Managed, or pre-built evaluators** for targeting common quality metrics like hallucination, relevance, toxicity, and helpfulness. These come with optimized system prompts and configurations, so you can deploy them quickly with minimal setup.
2. Your own **custom evaluators** that let you specify both the LLM to be used and parameters like temperature and token limits.
#### 3. Manual Annotation and User Feedback
You can also manually score outputs and collect direct user feedback in Langfuse to capture more nuanced judgments, which are especially useful in early-stage development or subjective tasks.
For example, in the Annotate tab you might select a set of traces and label each answer as “Correct” or “Incorrect,” or rate it on a 1–5 scale. These annotations are saved as evaluation scores attached to the trace, just like any other performance metric in Langfuse.
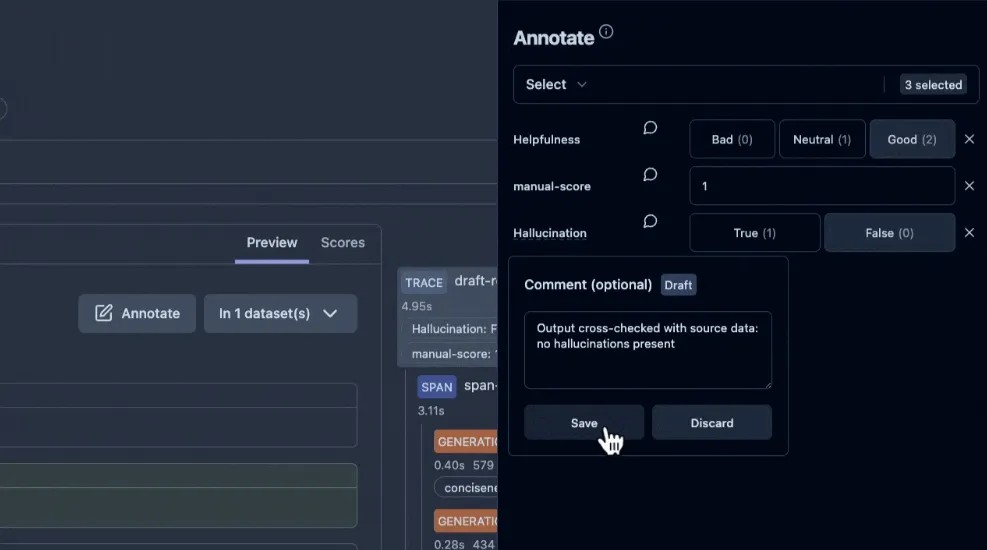
Langfuse also provides an “Annotation queue” feature for distributing tasks to team members and ensuring consistency.
You can also capture live feedback from your app’s users. For instance, in a chat interface, you might have a thumbs-up and down, or a star rating for each bot response. Langfuse can ingest this feedback via its SDKs or APIs and attach it to the corresponding execution trace.
Feedback can be explicit (ratings, votes) or implicit (did the user accept the suggestion, time spent reading, etc.). Internally, Langfuse simply treats user feedback as another score dimension.
Later, you can filter traces by feedback score or plot average feedback per prompt version.
## How Prompt Management Works in Lilypad
Lilypad is an open-source prompt engineering framework that treats prompts not just as text to be managed separately, but as an integral part of your codebase.
It encourages embedding prompts directly within plain Python functions in order to keep the prompt and the logic it uses all in one place, making your code easier to manage, version, and debug as you iterate.
Then, with a simple `@lilypad.trace(versioning="automatic")` decorator, that function (and everything that influences its output) is versioned automatically.
This keeps prompts close to the code that uses them, while Lilypad takes care of versioning and tracing behind the scenes. It also works with tools like Pydantic to help catch errors and keep things consistent.
### Why Reproducibility Needs More Than Prompt Text
In real-world LLM applications, the prompt text is only part of the picture. The result also depends on things like the function's code, the inputs, model settings, and how the response is handled afterward.
Versioning only the [LLM prompt](/blog/llm-prompt) (as we’ve seen other tools do) makes debugging fragile, because outputs can still vary even when the prompt stays the same. To reliably repeat or improve a result, you need the full context.
Lilypad captures the full context by treating the entire function call as a traceable unit. It takes a complete snapshot, including the prompt, code, inputs, and outputs, so you can replay it exactly as it ran, or change a part to see another result.
```python
import lilypad
from openai import OpenAI
client = OpenAI()
@lilypad.trace(versioning="automatic") # [!code highlight]
def answer_question(question: str) -> str:
completion = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": f"Answer this question: {question}"}]
)
return str(completion.choices[0].message.content)
response = answer_question("What is the capital of France?")
print(response)
# > Paris
```
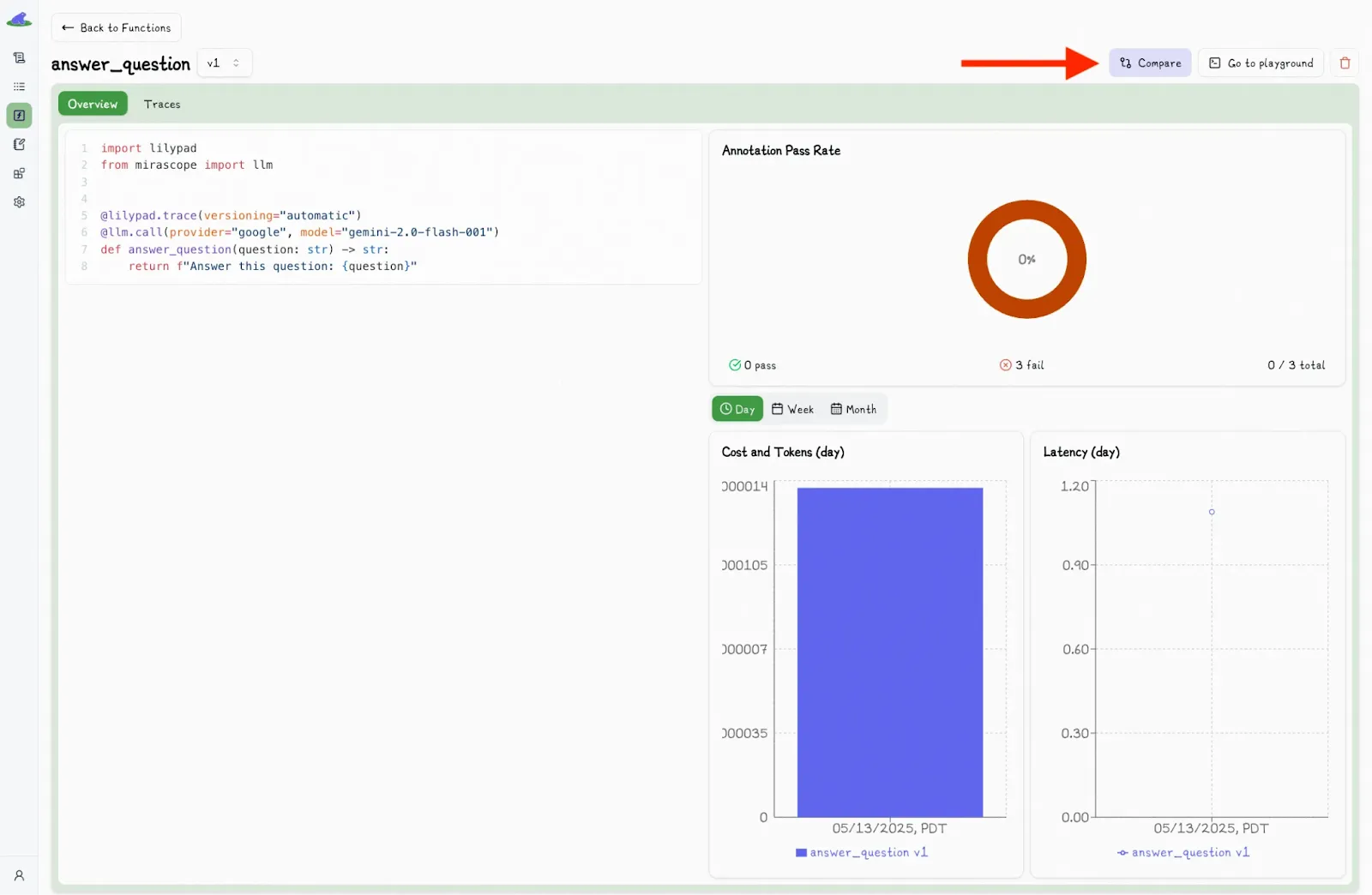
Each time we run the function using the decorator with `versioning=”automatic”` enabled, Lilypad creates a new version (except if the function hasn’t changed between runs).
Clicking the “Compare” button allows you to see and compare changes between versions:
You then select different versions to view the differences side-by-side.
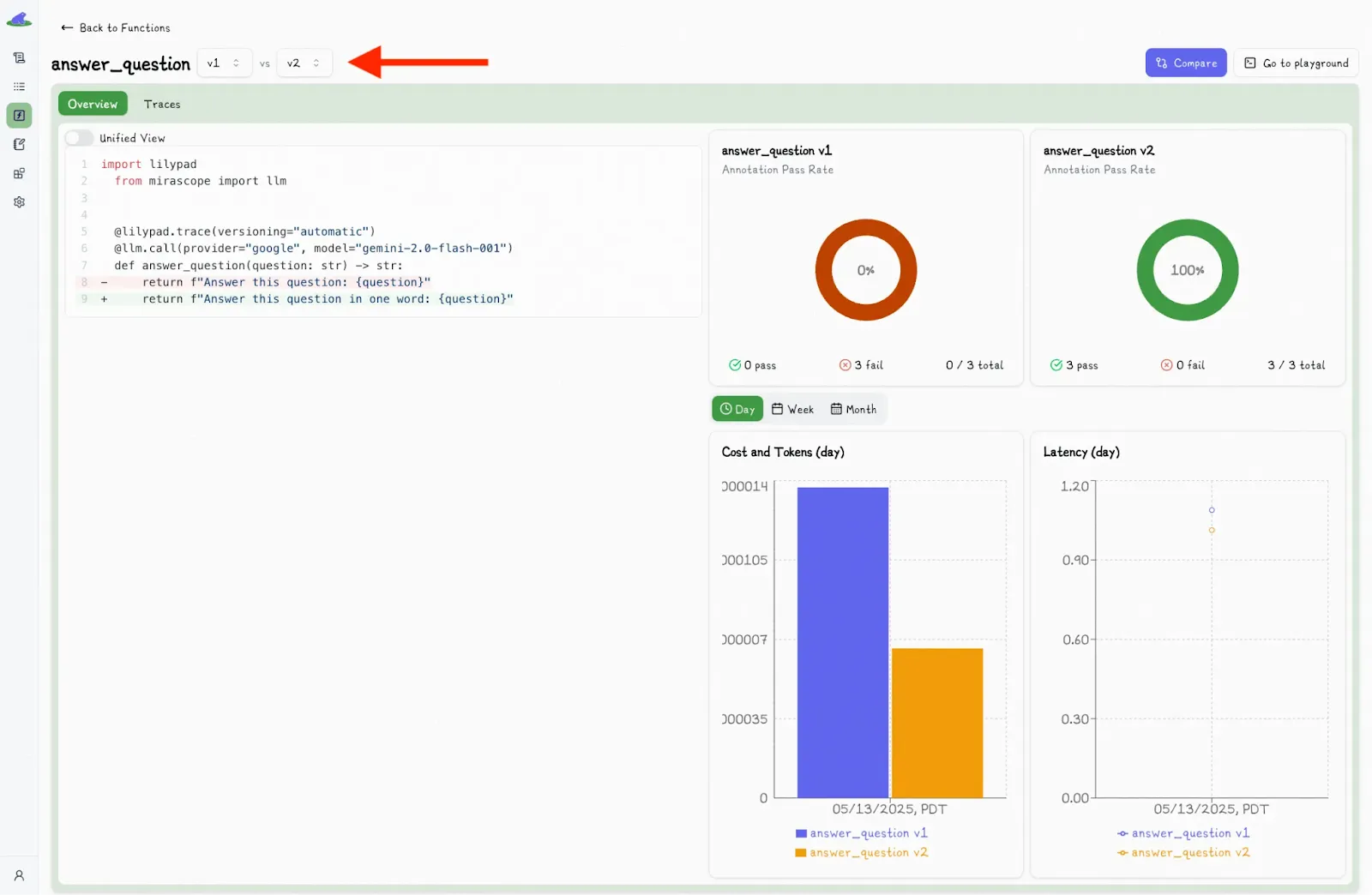
Lilypad instruments everything using the [OpenTelemetry GenAI spec](https://opentelemetry.io/) for deep observability.
Each trace captures the full context: what was asked, how it was asked, and what the model returned. You also get detailed metadata like inputs, outputs, model and provider info, token usage, latency, and cost.
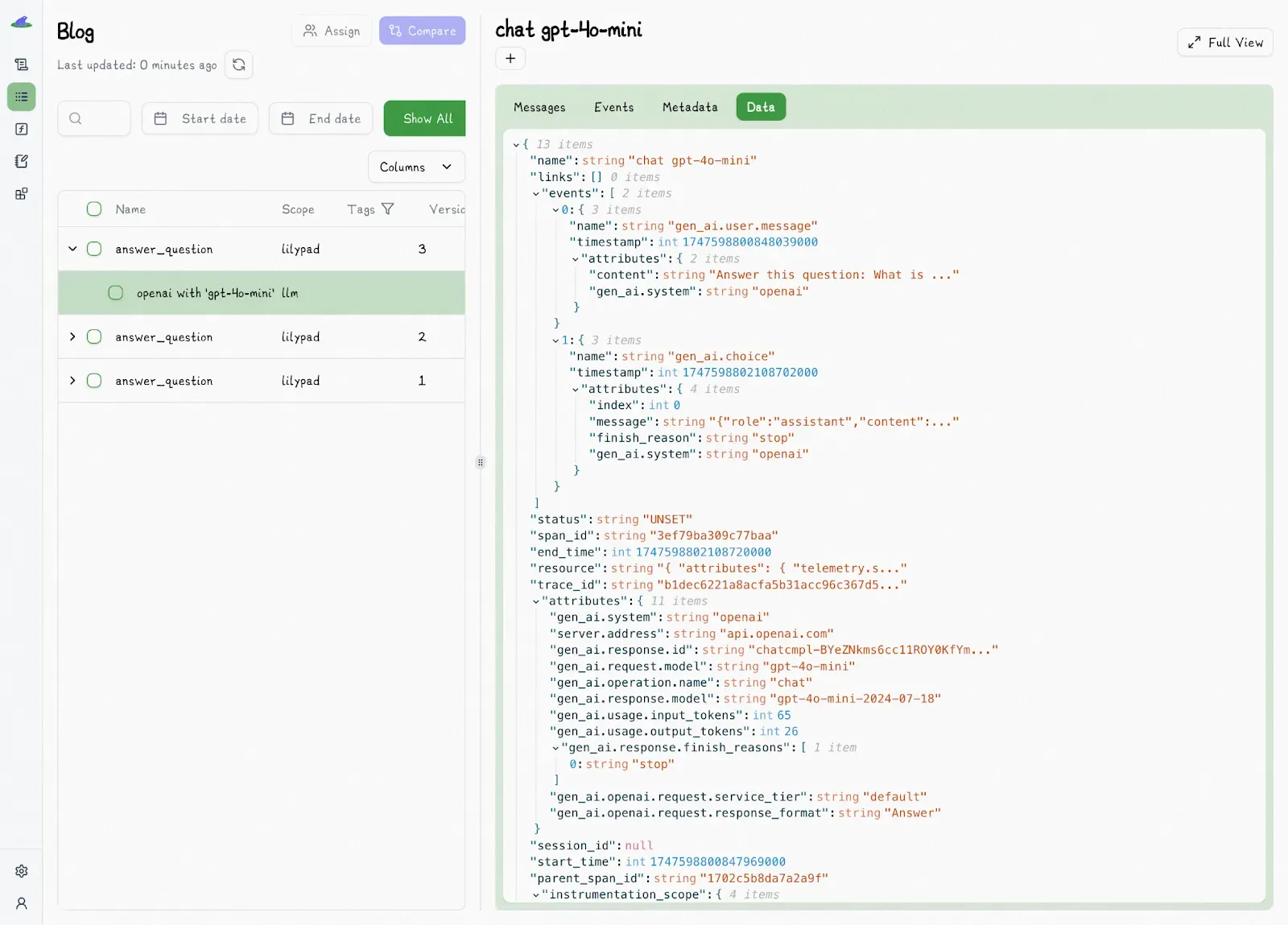
This level of visibility lets you easily measure improvements and iterate without guessing what was different between runs.
### How Non-Technical Users Can Safely Edit and Ship Prompts
Lilypad provides a no-code, browser-based playground that makes prompt management accessible to non-technical team members.
SMEs can edit, test, and ship prompt updates without requiring direct developer intervention for every iteration. This separation of concerns lets devs focus on system architecture, while SMEs handle prompt logic and evaluation.
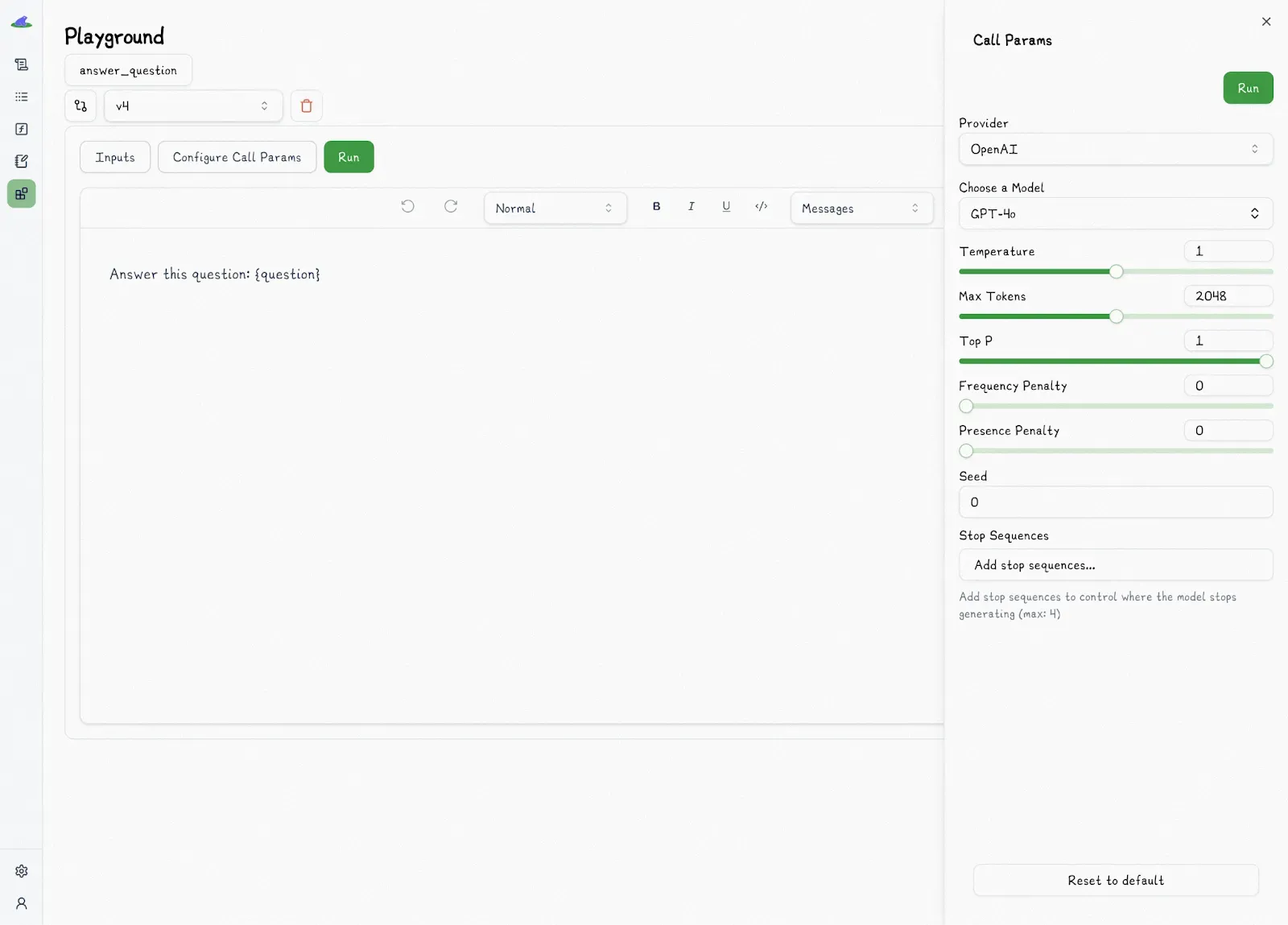
In the playground, non-technical users can:
* Edit markdown-style prompt templates using `{variable}` placeholders.
* Fill in values via auto-generated forms, based on the function’s type-safe Python signature.
* Get real-time validation on inputs, with immediate feedback on any issues.
**All edits are sandboxed by default**, so changes stay isolated until a developer explicitly integrates the approved version. Nothing goes live without review.
The code you test in the playground is the exact same versioned code that runs in your live app. There's nothing hidden or separate. **That’s different from other tools that treat prompts like files stored somewhere else**, separate from the code that uses them. This can lead to problems: it’s easier to break things, harder to fix bugs, and more confusing when something changes.
Once a prompt version has been tested and validated, engineers can reference it directly in code using methods like `.version()` or `.remote()`.
## Evaluating Prompt Performance
In traditional software, tests can check for exact results because the code always works the same way. But LLM apps don’t work like that: the same input can give different (but still okay) answers each time. For tasks like summarizing or giving recommendations, there usually isn’t just one “right” answer. What counts as good depends on the situation and how you look at it.
This makes [prompt evaluation](/blog/prompt-evaluation) an ongoing process, not a one-time test you automate and forget. You need to continuously observe outputs, especially as new edge cases evolve.
This also doesn't work well for traditional methods or tools (like LangSmith) that rely solely on predefined datasets and fixed expected outputs, because LLM systems aren’t static. Prompts get tweaked, logic evolves, and outputs can vary.
Lilypad tackles these challenges with a trace-first approach to evaluation. Instead of requiring predefined datasets and fixed expected outputs, it automatically logs every prompt execution as a full, versioned trace.
These traces act as real-world evaluation data, giving you a complete snapshot of what happened (input and outputs, call settings, logic, etc.), and you don’t have to manually curate anything upfront.
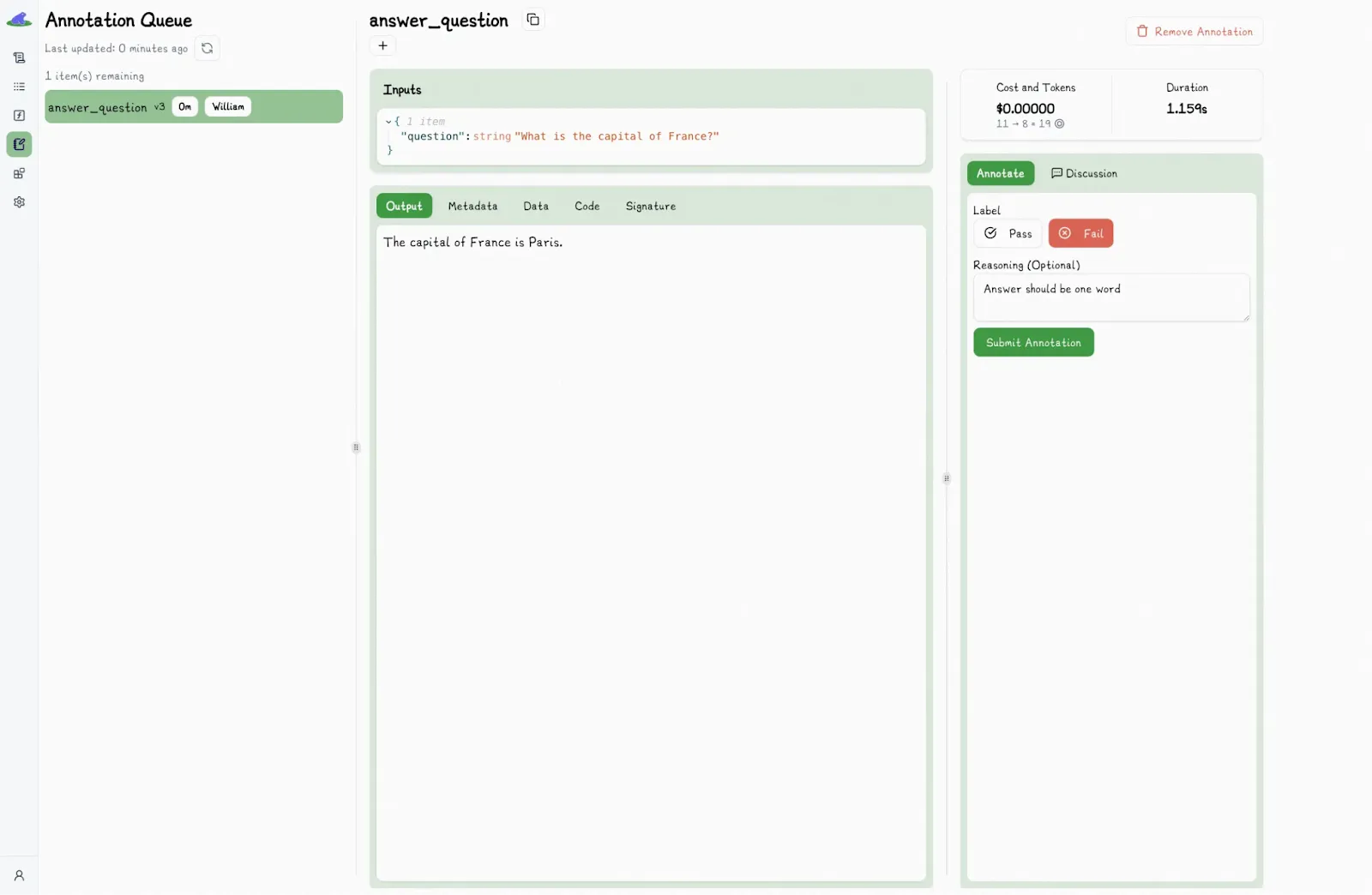
In the playground, both developers and non-technical users can review captured traces using pass/fail labels. This binary scoring approach is more useful and practical when deciding if an output is "good enough" for use, especially for subjective or context-dependent criteria. This stands in contrast to numeric ratings (e.g, 1-5), where you’re not exactly sure what 2 or 3 means.
You can optionally provide reasoning for your pass/fail decision to help others understand the criteria applied.
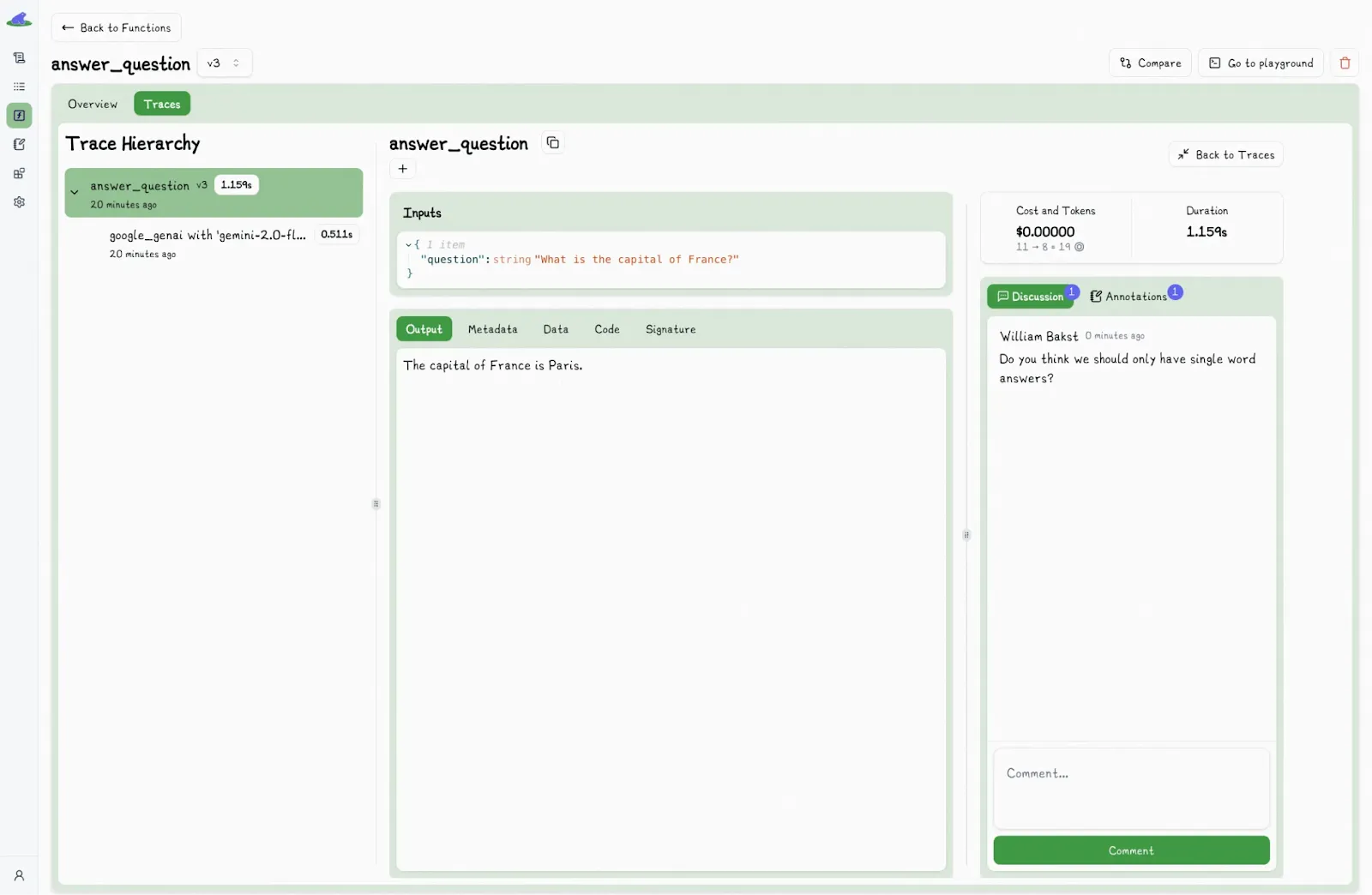
A discussion section is also available for adding comments or context to traces:
We encourage users to start by manually labeling outputs, especially in the early stages of a project. Each label is tied to a specific, versioned trace, which gradually forms a high-quality, human-annotated dataset that becomes the foundation for training automated evaluation systems, such as [LLM-as-a-judge](/blog/llm-as-judge), for which we’re actively building support.
The long-term goal with [advanced prompt engineering](/blog/advanced-prompt-engineering) is to shift toward a semi-automated workflow, where an LLM proposes a label and a human simply verifies it. In practice, this is often much faster than labeling from scratch, while still benefiting from human oversight.
That said, we still recommend keeping a human in the loop to ensure the LLM judge’s evaluations remain aligned with those of human annotators..
## Manage Your Prompts with Lilypad
For full reproducibility and control, Lilypad versions your entire [LLM integration](/blog/llm-integration), including the prompt text, the code that calls the model, the input parameters, and any logic around it, so you can see exactly what was run, every time.
You can start for free using your [GitHub](https://github.com/mirascope/lilypad) credentials (no credit card required), with paid plans for growing teams. Lilypad also supports [Mirascope](/docs/mirascope), our lightweight toolkit for building [LLM agents](/blog/llm-agents).
Langfuse Prompt Management: How It Works (+ A Flexible Alternative to Consider)
2025-07-23 · 12 min read · By William Bakst