LangSmith’s prompt management system helps teams version, test, and evaluate LLM prompts, especially within LangChain\-based ecosystems.
You can:
* Save prompt edits with automatic commits and tag them for different stages like `dev` or `prod`
* Test prompts live in their playground UI by tweaking inputs and model parameters
* Push, pull, and integrate prompts into your app via the SDK
* Evaluate prompts using datasets, with support for automated checks or human reviews
It’s a solid system for teams deep into LangChain and LangGraph.
But some devs find it limiting. Prompts are versioned as plain text, disconnected from the logic that uses them. That makes downstream usage brittle, introduces drift, and makes debugging hard in a non-deterministic world. The UI can feel heavyweight, and structured outputs need to be recreated by hand.
We built Lilypad to solve these problems. It versions the entire function, not just the prompt, including logic, models, parameters, and structured return types. The browser-based playground is lightweight but fully type-safe, and what you test there is exactly what runs in production.
In this article, we’ll break down how prompt management works in LangSmith and how Lilypad improves on its limitations.
## How to Manage Prompts in LangSmith
LangSmith gives you two ways to manage prompts for building [LLM applications](/blog/llm-applications): through a visual playground or via an SDK. Both approaches let you version, test, and evaluate your prompts.
### Managing Prompts in the Playground
The LangSmith playground lets you create, edit, and test prompts interactively, which is ideal for quick experiments or working with teammates.
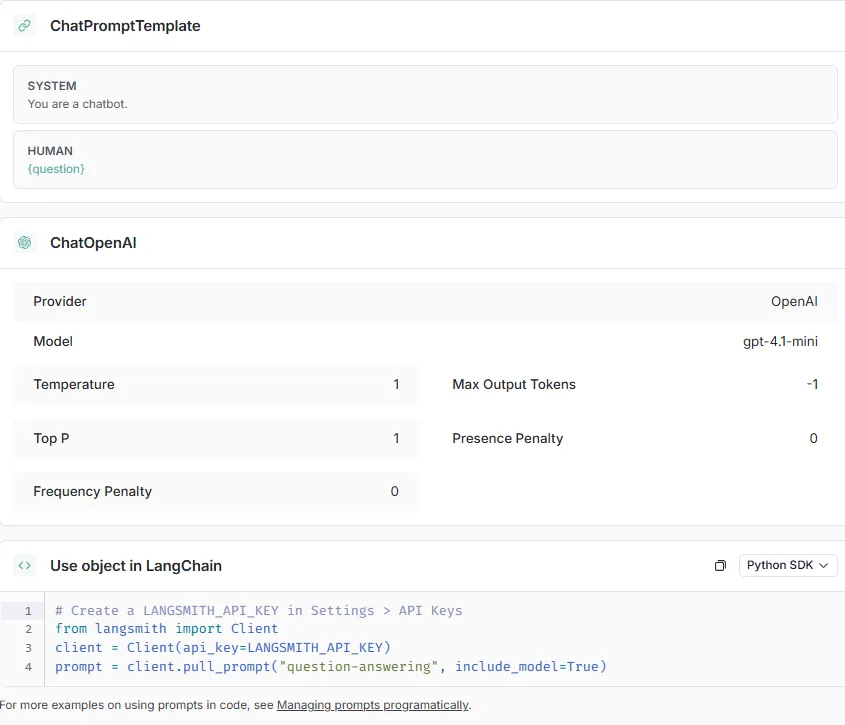
By default, it uses [`ChatPromptTemplate`](https://python.langchain.com/api_reference/core/prompts/langchain_core.prompts.chat.ChatPromptTemplate.html), a LangChain prompt class that separates messages by role, like System and Human. You can plug in variables (like `Question`) to make prompts dynamic and reusable.
Since LangSmith is built on LangChain, the prompts you work with are actually [LangChain runnables](/blog/langchain-runnables). That means you're managing LangChain entities underneath the nice UI on top.
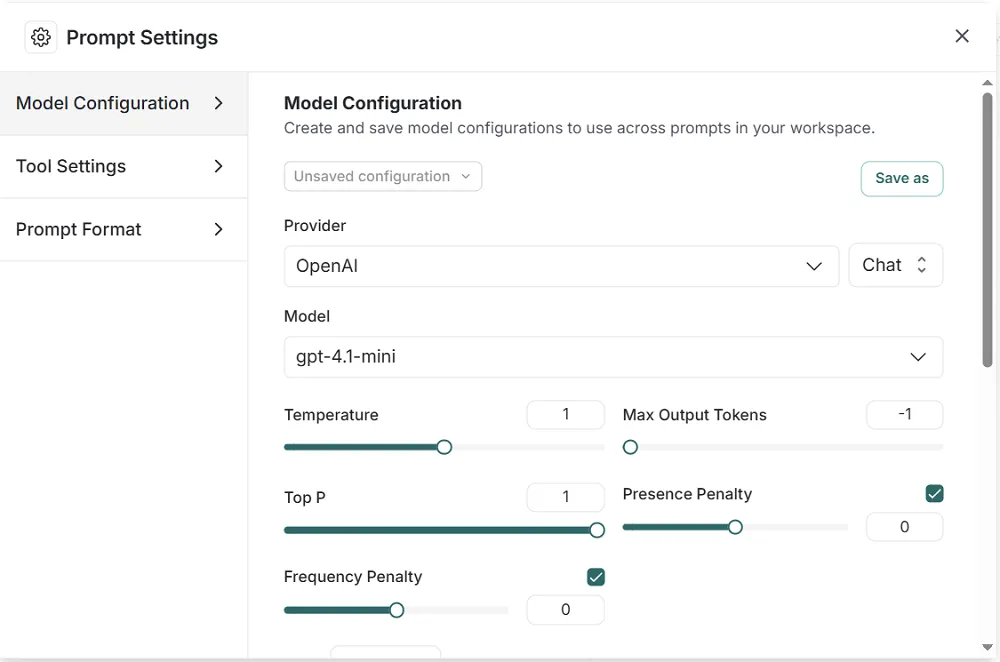
You can customize the settings for each prompt, like Provider, Model, Temperature, Top P, and more. It’s easy to add messages, tools, and even define the shape of the output with a schema:
For more complex workflows, there’s the “Prompt Canvas.” It’s a visual editor that helps you lay out bigger prompt templates and even includes an LLM\-based assistant to help you write them:
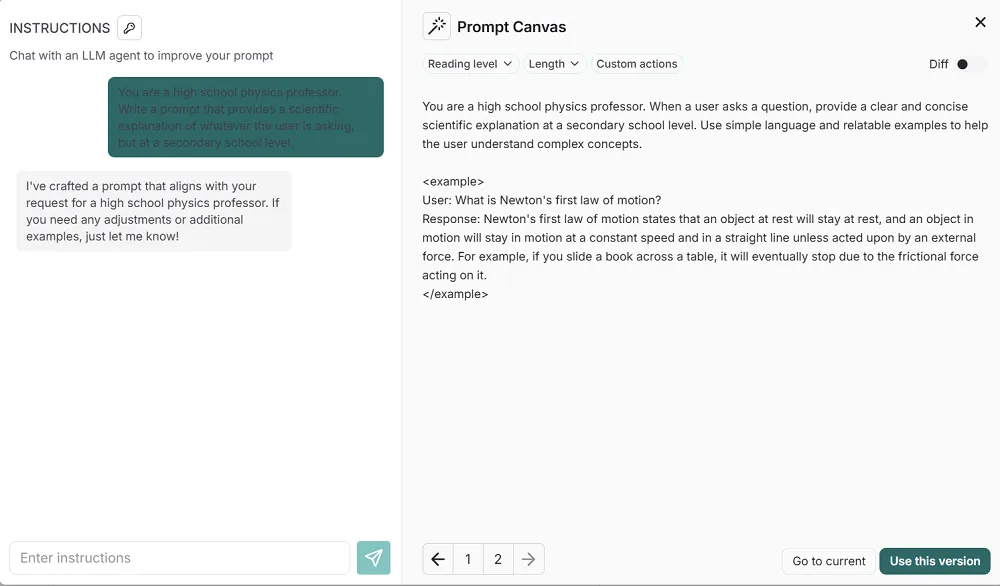
Every time you save a prompt by clicking “Use this version,” LangSmith commits your changes and versions them using a unique, Git-like identifier. You can tag these versions (like “QA over documents” or “Chatbots”) to keep things organized.
And when it’s time to see how your prompt performs, you can run evaluations right in the playground by testing it against a dataset or viewing scores given by an [LLM\-as-judge](/blog/llm-as-judge) or a human. All this we describe further below.
### Managing Prompts Using the SDK
For those who prefer working in code, the LangSmith SDK (available in Python or TypeScript) lets you manage prompts programmatically, giving you tighter control, direct CI/CD integration, and the ability to stay right in your editor.
You can write a new prompt locally and push them to LangSmith using `client.push_prompt()`. This uploads your prompt template along with optional tags or descriptions. Every push creates a new version, so your prompt history stays clear.
```python
from langsmith import Client
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate([
("system", "You are a career advisor."),
("user", "What are some good job options for someone with a background in {background}?"),
])
client.push_prompt("career-advice-prompt", object=prompt)
```
Once a prompt is in LangSmith, you can pull it down anytime with `client.pull_prompt()`. You can fetch the latest version, a specific commit hash, or a tagged version like `my-prompt:prod`.
You can list all your prompts with `client.list_prompts()`, or clean up old ones with `client.delete_prompt()` to audit or clean up versions. Such methods also let you integrate prompts directly into LangChain apps.
LangSmith also lets you publish prompts to [LangChain Hub](https://smith.langchain.com/hub): the public sharing space within the ecosystem. Just set your prompts to “public” so they’re reusable across teams and projects.
### Evaluating Prompts in the LangSmith UI
LangSmith supports a structured, [evaluation-driven development workflow](https://docs.smith.langchain.com/evaluation/concepts) that emphasizes predefined testing and metric\-based comparisons.
It’s built around datasets that act as the backbone of LangSmith’s evals. First, you need a dataset made of input prompts and either expected outputs or rules that describe what success looks like. You upload these datasets into LangSmith, where they’re used to run repeatable evaluations across different prompt versions.
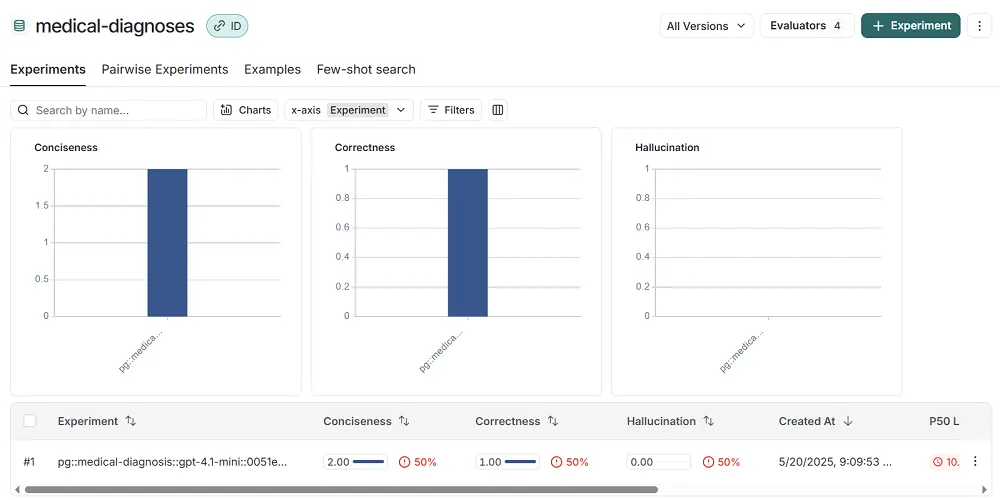
Evaluators can be automated AI judges, custom Python functions, or just human reviewers. This gives you flexibility in how you judge output quality, whether it's strict accuracy or subjective usefulness.
But LangSmith relies on having those datasets available up front. That’s fine for structured benchmarks, but it slows down early iteration and is less flexible for exploring outputs organically, because you have to stop and define your tests before you can really start learning.
This setup feels more at home in traditional ML pipelines. But real-world prompt tuning often doesn’t follow a straight line. Teams want to try something, see what it does, tweak, repeat. That’s where LangSmith can feel rigid; it’s great for clean benchmarks, but less ideal for the messy, creative work of prompt iteration.
## No Commits, No Drift: Lilypad’s Versioning Model
Lilypad is an open source prompt engineering framework that supports [LLM integration](/blog/llm-integration) and treats prompts as code (specifically, as typed, versioned Python functions) rather than as files in a content management system.
This isn’t just a style choice. It’s because Lilypad was built for software engineers who expect their prompts to behave like the rest of their application: composable, testable, and traceable. Rather than managing prompts as disconnected assets in a UI, Lilypad keeps them tightly woven into your codebase.
In other words, you’re not committing prompts manually or tagging them in a hub. Lilypad automatically snapshots the exact code: prompt logic, inputs, parameters, and even return types, every time a function runs. It’s just like versioning any other function in your app.
That’s the key difference: LangSmith treats prompts like content. Lilypad treats them like software. And if your prompts are influencing how your app behaves, they deserve to be versioned, tested, and debugged with the same rigor as everything else.
### Why Versioning Just the Prompt Isn’t Enough
LLM behavior depends on more than just the prompt string. The final output can be influenced by the model you choose (like switching from `gpt-4o` to `claude-3-opus`), the parameters you pass in (e.g., temperature, `max_tokens`, `top_p`), and all the little bits of code that wrap around the prompt itself, like input formatting before the call and result parsing or validation after it.
On top of that, how your code is structured also matters. Are you using helper methods? Conditional branches? Type coercion? These aren’t just cosmetic. They directly impact what the LLM sees and how it behaves.
For starters, Lilypad encourages developers to wrap every prompt call inside a Python function to transform it into a fully managed prompt artifact that’s trackable, comparable, and safe to iterate on.
And with one line of code — `@lilypad.trace(versioning="automatic")` — you unlock full-stack version control:
```python
import lilypad
from openai import OpenAI
client = OpenAI()
@lilypad.trace(versioning="automatic") # [!code highlight]
def answer_question(question: str) -> str:
completion = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": f"Answer this question: {question}"}]
)
return str(completion.choices[0].message.content)
response = answer_question("What is the capital of France?")
print(response)
# > Paris
```
Now every time the function changes, Lilypad creates a new version. That includes changes to the prompt, model, parameters, logic, and return schema. It logs the inputs, outputs, and metadata, captures a full trace, and stores the entire function closure to ensure reproducibility. That means even helper functions and in-scope classes get tracked automatically.
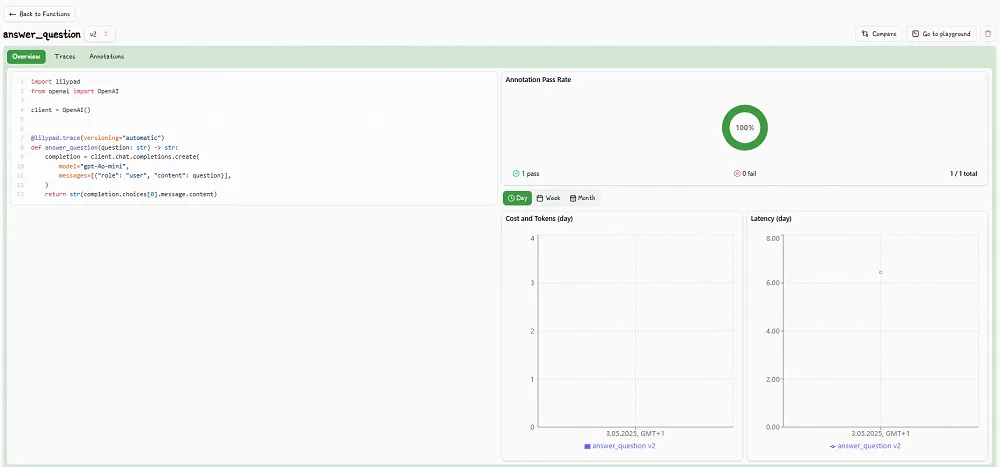
The output of the code is shown in the Lilypad traces tab:
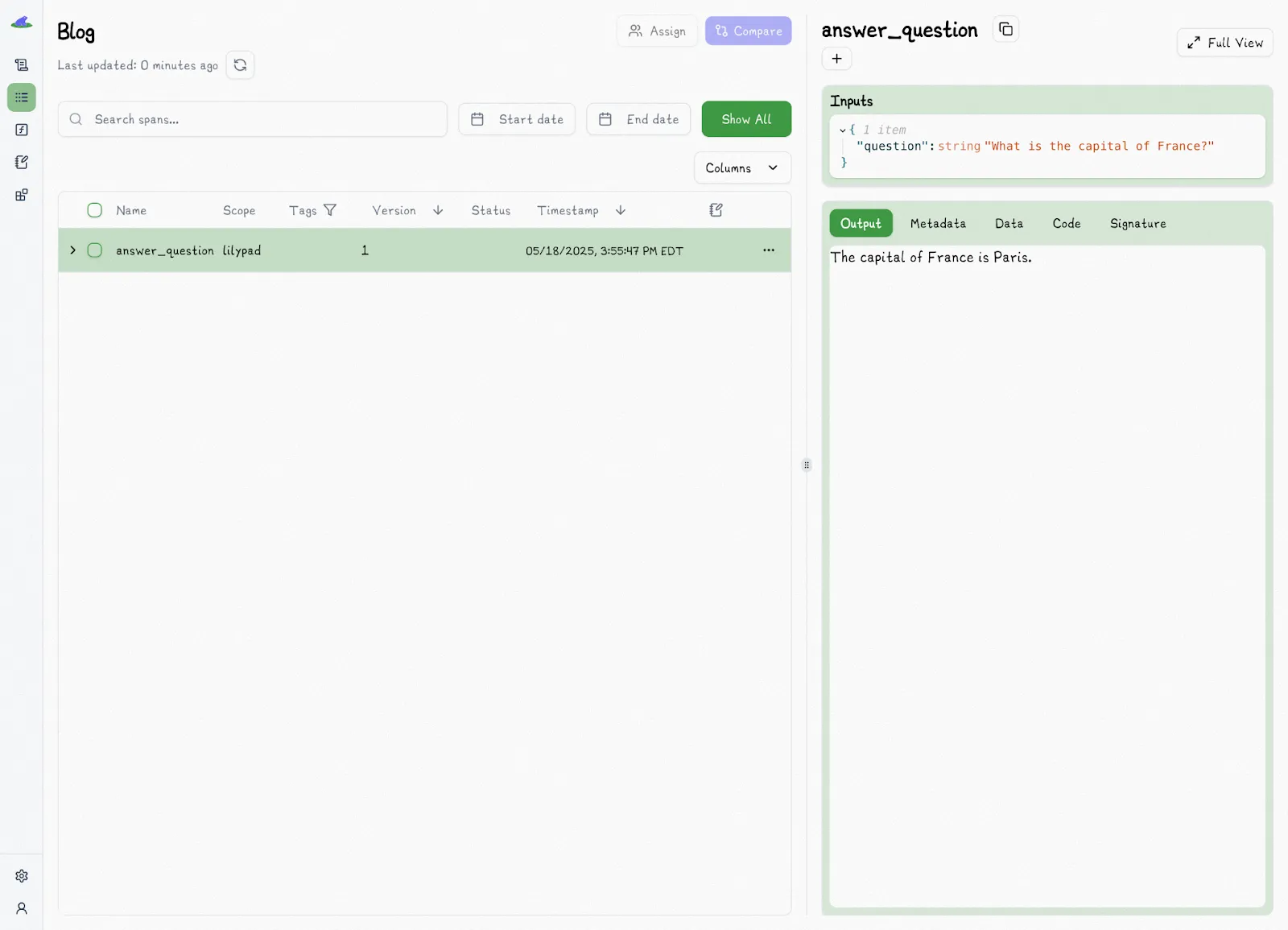
Our platform also shows the version you’re running (V1, V2, V3) alongside detailed trace data like latency, cost, and output.
Changing the model used in our function from `gpt-4o-mini` to `gpt-4o`, for instance, increments the version:
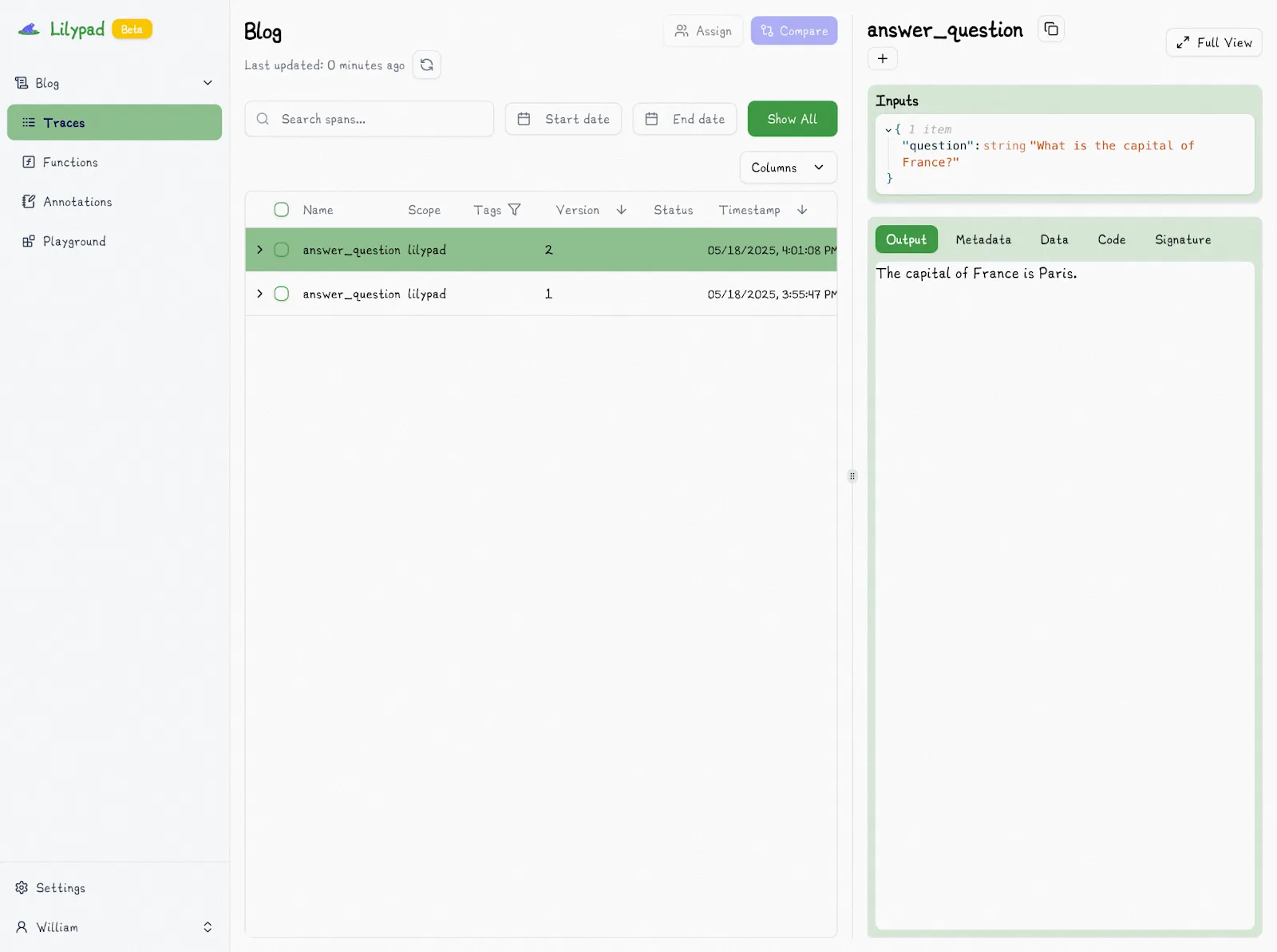
(It also doesn’t duplicate versions if nothing meaningful has changed.)
This also allows us to easily compare different versions:
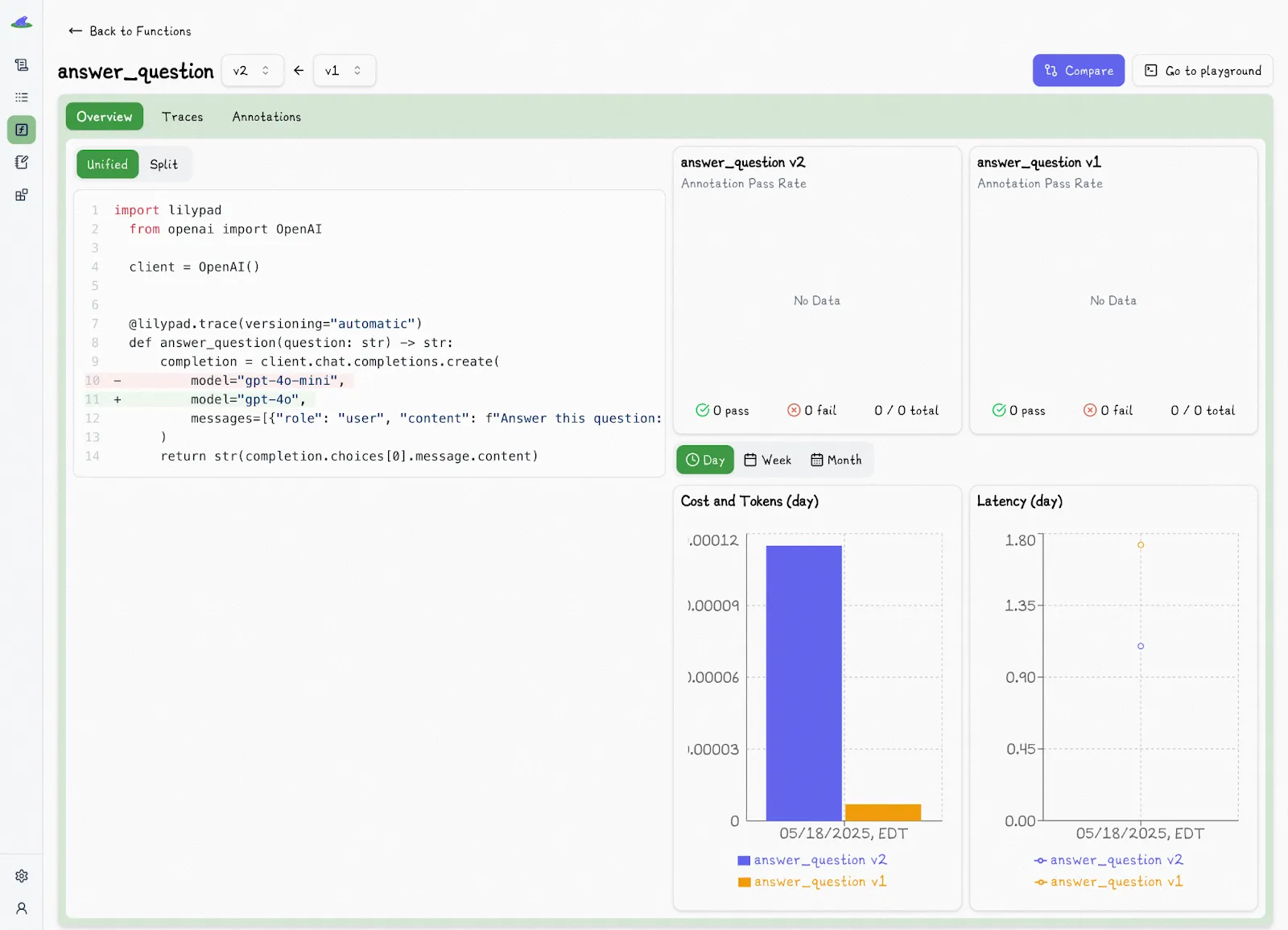
Even changes to user-defined functions or classes outside the main prompt function are logged and tracked automatically (as long as they’re within scope).
For example, structuring your outputs will affect the return type of your function:
```python
import lilypad
from openai import OpenAI
from pydantic import BaseModel
lilypad.configure(auto_llm=True)
client = OpenAI()
class Answer(BaseModel): # [!code highlight]
reason: str # [!code highlight]
answer: str # [!code highlight]
@lilypad.trace(versioning="automatic")
def answer_question(question: str) -> Answer | None: # [!code highlight]
completion = client.beta.chat.completions.parse(
model="gpt-4o-mini",
messages=[{"role": "user", "content": f"Answer this question: {question}"}],
response_format=Answer,
)
return completion.choices[0].message.parsed
response = answer_question("What is the capital of France?")
print(response)
```
This means changes to the return type will now be logged and traced as a new version:
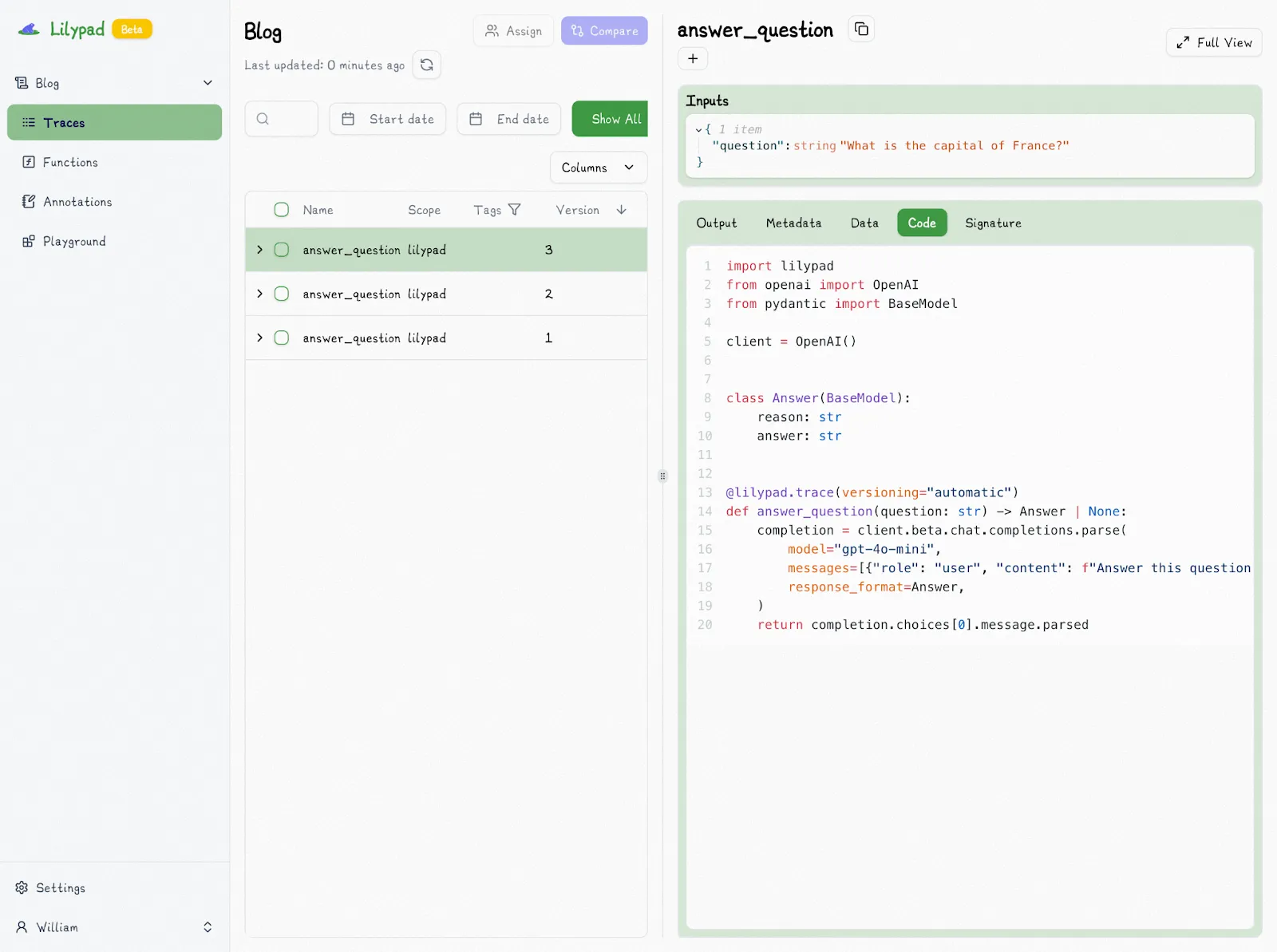
Setting `auto_llm=True` ensures every LLM call is traced using the [OpenTelemetry Gen AI spec](https://opentelemetry.io/), which gives you a precise snapshot of each call:
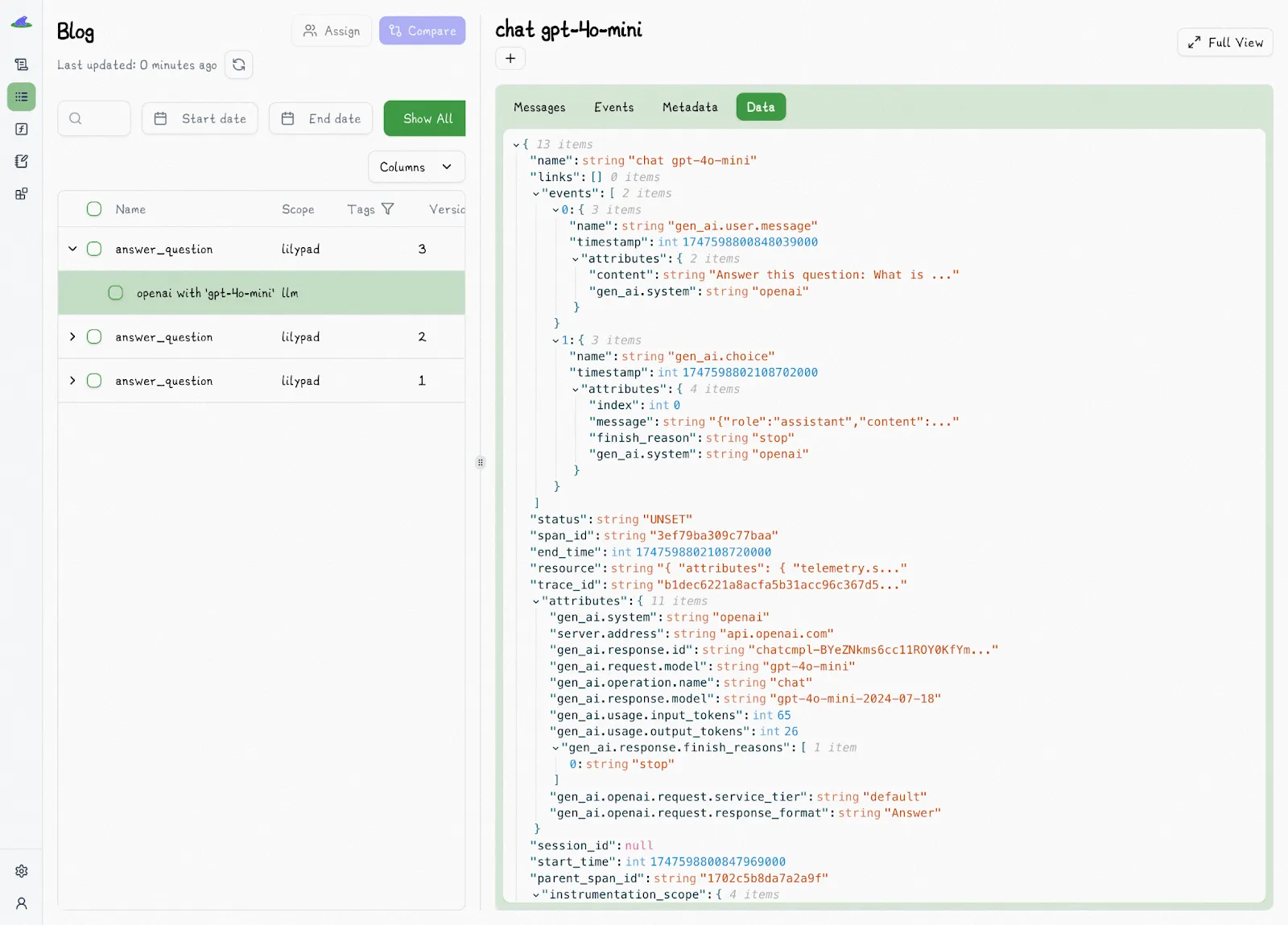
Large language model calls become a nested span within the overall trace, so you always know where and how it was triggered.
### How Non-Technical Teams Ship Prompt Changes (Safely)
Lilypad’s playground allows SMEs to fine-tune prompts without touching the codebase, and because it’s tied directly to the underlying function, what runs in the playground is exactly what runs in production, with no proxies and no drift.
This means domain experts can test ideas, make updates, and preview outcomes, all without needing to file a ticket or wait for a dev. Meanwhile, engineers can use Lilypad’s `.version()` or `.remote()` methods in their code to reference the exact version that’s been approved, tested, and traced.
```python
response = answer_question.version(1)("What is the capital of France?")
```
If Lilypad ever goes offline, your app doesn’t break since the full logic lives in your code, not in a fragile, separate system.
This is in contrast to traditional prompt and [LLM tools](/blog/llm-tools), which store prompt strings in a central UI and sync them into the app, often leading to mismatches and brittle deployments.
In Lilypad, prompts are real functions. And in the playground, non-technical users can:
* Edit markdown-style templates with `{{variable}}` placeholders
* Fill in inputs using forms auto-generated from the function’s type-safe signature
* See prompt arguments validated live at runtime, just like in production
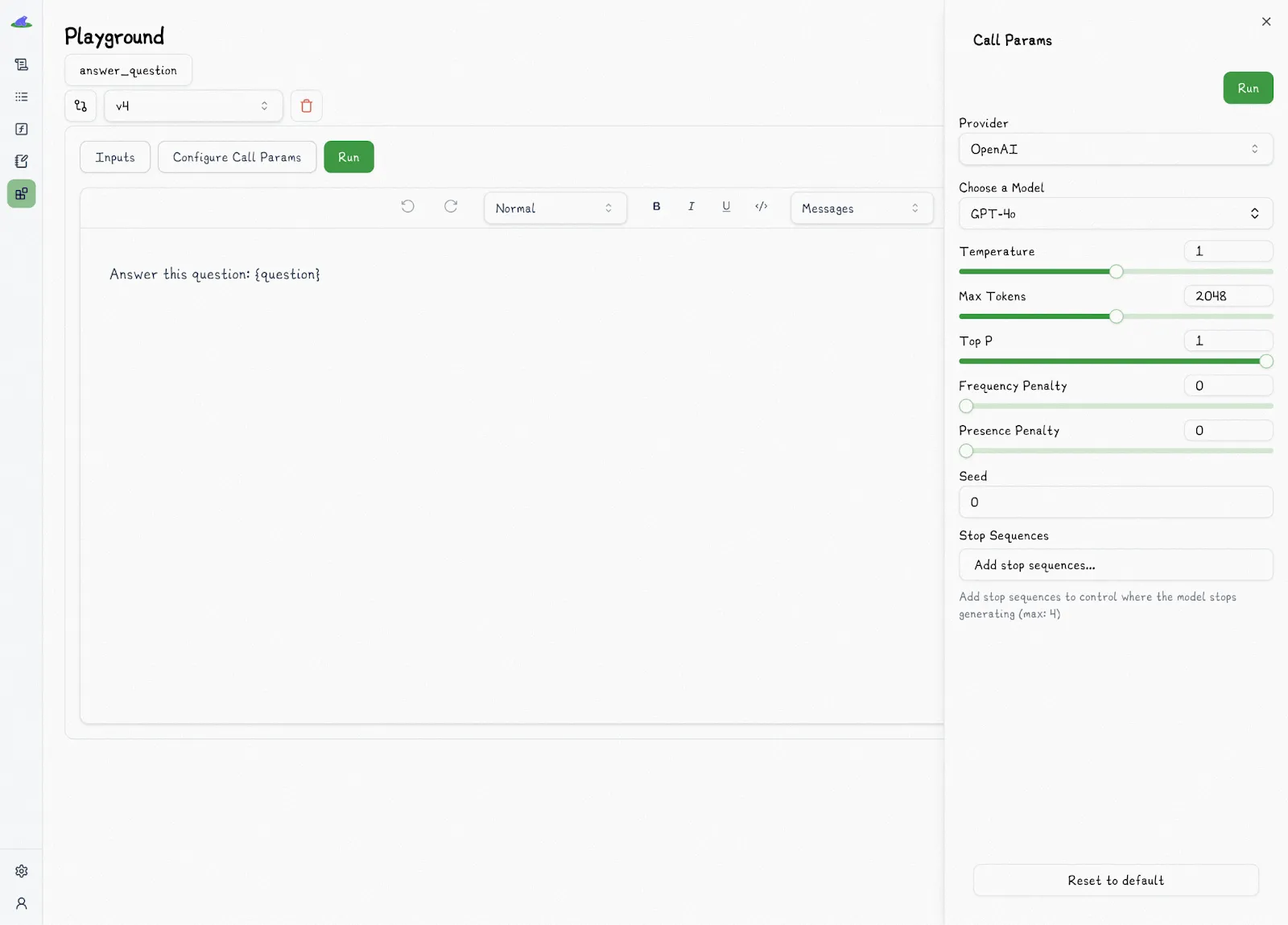
All prompt edits in the playground are sandboxed by default, so nothing touches production until it’s explicitly published. The playground itself offers a minimal interface showing the essentials: prompt logic, call settings, temperature, inputs, outputs, traces, and usage stats.
### Evaluate the Prompts You Ran, Not Just the Ones You Planned
In LangSmith, you define your inputs and expected outputs ahead of time, then run your existing prompts or chains against that dataset to generate metrics and scores. This is great when there’s a clear ground truth, like checking if a math problem has the correct answer.
But not every LLM task has a right answer.
When you’re summarizing a customer support ticket, writing a product description, or recommending a movie, the "correct" output is often subjective. Worse, when your prompts change frequently or your system is already live, the original dataset might not reflect what’s actually running anymore.
Also, LLMs are non-deterministic. Run the same prompt with the same input twice and you might get two different outputs.
Lilypad uses a trace-first approach that evaluates prompts as they actually run. This means every prompt you run is captured as a full versioned trace, complete with metadata: the prompt, parameters, model provider, and output. These traces become your real-world dataset, so no extra curation is needed.
When it comes to rating an output, we find that teams usually care less about whether it scored a 3 or a 4, and more about one simple question: is it good enough to use or not?
That's why we recommend skipping numeric scores and instead tagging outputs as Pass or Fail: it's faster, clearer, and better aligned with how most teams make real-world decisions
Lilypad supports this approach. Every trace can be opened, reviewed, and labeled with a simple Pass or Fail tag, along with an optional explanation to capture your reasoning:
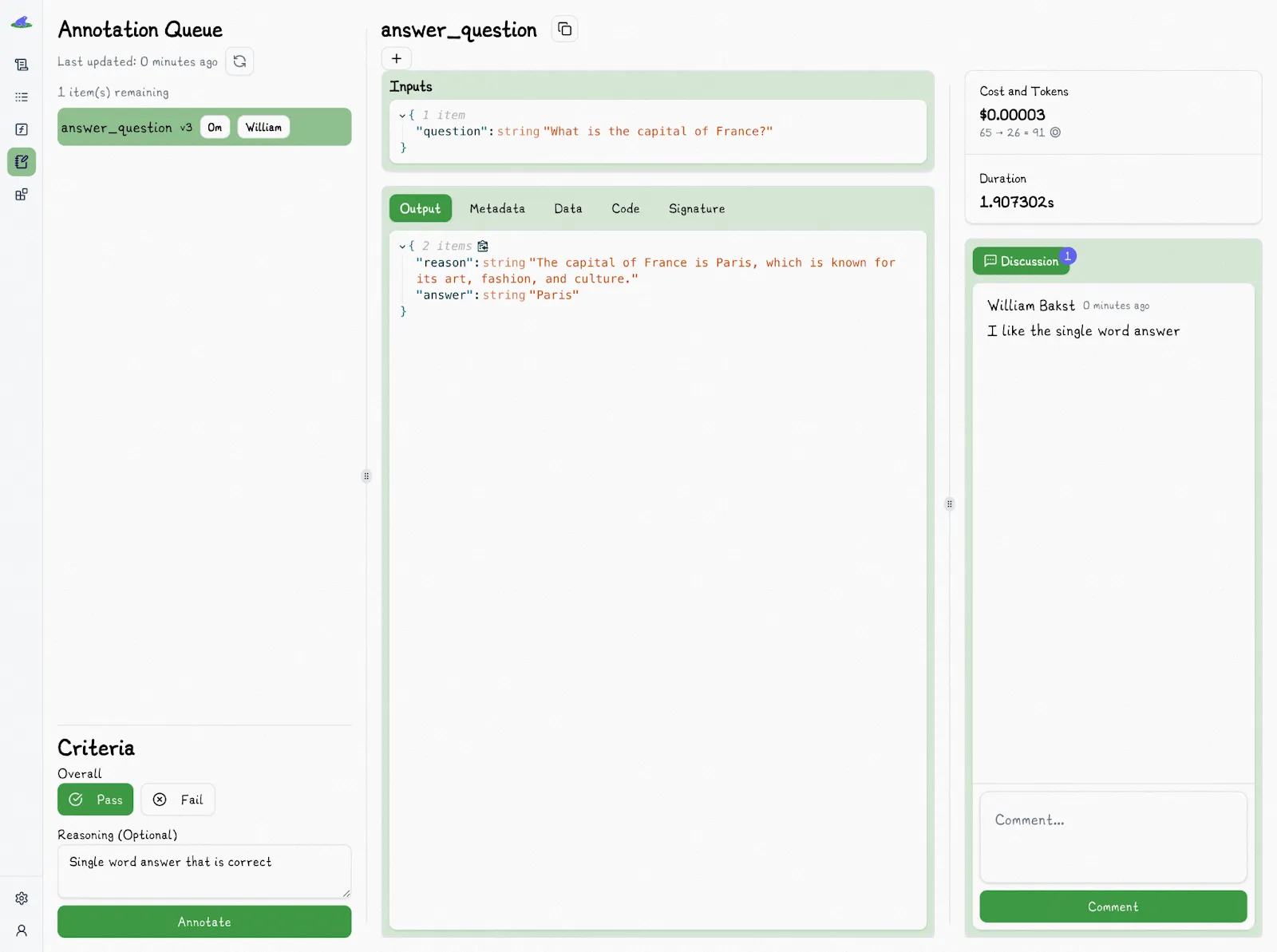
You can also leave comments in the discussion panel of each trace. Use it to share what you noticed, add context, or flag something for your team.
As you tag more outputs, Lilypad builds up a dataset of human-labeled feedback. And soon, you’ll be able to train a custom LLM\-as-judge to replicate your decisions, helping automate the scoring process based on your own past annotations.
That means you can move from hand-labeling to quick review, speeding up your workflow without giving up control. Of course, manual review still matters, which is why we recommend verifying all outputs nevertheless.
## Version Everything. Debug Anything.
Lilypad supports self-hosting and helps you optimize prompts like production code, not loose strings in a UI. With typed functions, automatic versioning, rich trace metadata, and human-in-the-loop [LLM evaluation](/blog/llm-evaluation), you can debug, improve, and deploy your prompts for all kinds of use cases with confidence.
Want to learn more? You can find more Lilypad code samples in both our [docs](/docs/lilypad) and on [GitHub](https://github.com/mirascope/lilypad). Lilypad offers first-class support for [Mirascope](/docs/mirascope), our lightweight toolkit for building [LLM agents](/blog/llm-agents).
LangSmith Prompt Management - How it Works
2025-06-26 · 7 min read · By William Bakst