Prompt optimization is the process of improving the questions or instructions you give to an LLM until the output hits the mark. It’s not the same as prompt engineering, which is the larger task of designing how prompts work across a full AI project. Instead, prompt optimization is just a part of that, and is about making your prompts better, one iteration at a time.
You usually start by writing a new prompt, seeing what the model gives you, and then making changes to improve the result. This trial-and-error loop is driven by feedback from the model, and although libraries like DSPy use an algorithm to help with the process, in real life most prompt optimization is still done manually.
Because AI responses can vary, even with the same input, it’s important to write prompts that consistently lead the model in the right direction. That’s why prompt optimization isn’t just helpful but is necessary.
Sometimes, you can improve prompts by making simple changes, like introducing small linguistic changes (wording, tone, personas). Other times, more advanced techniques are necessary, like prompting the model to reason step-by-step (chain of thought).
In this guide, we’ll walk you through 10 basic and advanced ways for optimizing prompts, and illustrate some of these using examples from our own framework for managing and improving LLM prompts, Lilypad.
## 5 Basic Ways of Improving Prompts, That Everyone Should Use
This section covers five techniques to get more accurate, relevant, and helpful results from a language model.
If you're looking for more advanced methods, feel free to [skip ahead](#5-advanced-prompting-techniques-that-work-in-production).
### 1. Write Clear, Direct Prompts for Better Results
If your wording is vague or too broad, the model may return something that feels generic or just not useful. Open-ended phrases like “tell me about” or “give me some tips” don’t give the model enough direction to generate a focused answer.
LLMs lean heavily on the structure and detail of your prompt to figure out what you actually want, as they won’t fill in the blanks or guess your intent.
Use concrete nouns and action verbs to describe what you’re doing. Adding numbers, categories, or output formats can help. So instead of saying, “Give me some productivity tips,” try something like:
```plaintext
List five productivity tips for remote workers, with one sentence explaining how each tip helps manage distractions.
```
This tells the model how many tips to provide, who the tips are for, what the goal is, and how the tips should be formatted. You’ve given it a structure, an audience, and a purpose, making it more likely you’ll get a better response.
### 2. Add Context to Get More Relevant Answers
Language models don’t know your situation unless you tell them, so without context, they’ll often give generalized advice.
For instance, if you ask, “Give me some productivity tips,” the model might respond with a long list of ideas, many of which may not apply to your lifestyle or work setup. But if you add a bit of detail, the output becomes more useful:
```plaintext
I’m a remote worker who struggles with afternoon focus and works mostly in a noisy home environment. What are some productivity tips for me?
```
Now the model knows who you are, what challenge you're facing, and what environment you’re in. With that context, it’s more likely to suggest relevant strategies, like using noise-canceling headphones, scheduling focus blocks during quiet times, or matching complex tasks to your energy levels.
### 3. Guide the AI with Examples (Few-Shot Prompting)
Sometimes, the best way to get the answer you want is to show the AI what you're looking for. This is called few-shot prompting, and it involves giving the model one or two examples to set the tone, structure, and level of detail you expect.
Unlike simple instructions, examples show the model what a “good” answer looks like, helping it follow your lead. LLMs are good at spotting patterns, so even a couple of short, few-shot examples can have a big impact on the output.
Let’s say you want the AI to suggest lifestyle habits. Instead of just asking for tips, you might include:
```plaintext
Example 1: “Start your day with a 10-minute walk to boost energy and mood; it’s a small change with a big payoff.”
Example 2: “Keep your phone out of the bedroom. Better sleep means everything’s better.”
Prompt: “Now give me more tips to improve focus in everyday life.”
```
Such few-shot examples tell the model that you want short, realistic, and positive advice, not just a bland or overly long list. They also set the tone for the rest of the response.
### 4. Have the AI Take on a Role
One effective way to get more accurate and relevant answers is to ask the model to take on a specific role. This technique, often called role prompting, helps the model respond with the voice and expertise of a particular kind of professional like a doctor, teacher, historian, or coach.
For example:
```plaintext
Act as a professional sleep coach and give me three daily habits I can adopt to improve sleep quality naturally.
```
By framing the prompt this way, you’re telling the AI not just what to answer for complex tasks, but how to think, with the knowledge and perspective of someone who specializes in the topic.
### 5. Ask the AI to Explain Its Thinking (Chain-of-Thought)
Chain-of-thought prompting guides the model to break down its thinking step by step, rather than jumping straight to an answer.
This invites it to think aloud and often leads to more accurate, transparent responses, especially for questions that involve multiple steps, cause-and-effect reasoning, or uncertainty.
To do this, adjust your initial prompt to explicitly ask for reasoning. You might say something like, “Explain step by step…” or “What are the steps you would take to decide…”
For example:
```plaintext
I’m considering a move to Barcelona. Can you reason through the decision step by step, considering climate, cost of living, social life, work opportunities, and quality of life?
```
Now you’re giving the model a clear framework for thinking. It might start with climate, compare it to where you live now, then move on to housing prices, your job market, and so on, ending with a summary based on all the factors.
You can also refine chain-of-thought prompts by requesting pros and cons for each factor, or adding personal constraints like “Assume I work remotely” or “Assume I value cultural activities highly.” In more complex workflows, this can be extended using [prompt chaining](/blog/prompt-chaining), where each step builds on the last to guide the model toward a multi-part goal.
That said, newer reasoning-optimized models are getting better at handling deeper, multi-step reasoning within a single prompt, reducing the need for manual chaining in some cases.
## 5 Advanced Prompting Techniques That Work in Production
In production, it’s not enough to write a better prompt. It needs to be testable, traceable, and maintainable over time. The following techniques focus on structure, collaboration, and observability, so you can ship tested prompts that are easy to improve.
### 1. Treat Prompts Like Code
Prompts aren’t just text; they’re the interface layer between humans and large language models. If you want your LLM-powered app to behave consistently and be easy to debug and improve, prompts should be treated with the same care and structure as any other piece of production code.
Rather than leaving prompts as raw strings floating in the codebase or in some external folder, we recommend embedding them directly in your source code. This makes them easier to trace, validate, and maintain alongside the rest of your logic. It also prevents the drift that happens when initial prompt design and application behavior are managed separately.
Prompts include call parameters like temperature, model choice, and even surrounding logic, making them deeply integrated with the [LLM tools](/blog/llm-tools) that shape their behavior. **That’s why Lilypad advocates wrapping each prompt in a Python function, complete with typed arguments and structured return values**, since such functions are modular, clear, and easy to reason about.
By adding the `@lilypad.trace(versioning="automatic")` decorator to a function, you mark it as a versioned, non-deterministic unit:
```python
import os
import lilypad
from openai import OpenAI
lilypad.configure(
project_id=os.environ["LILYPAD_PROJECT_ID"],
api_key=os.environ["LILYPAD_API_KEY"],
auto_llm=True,
)
client = OpenAI()
@lilypad.trace(versioning="automatic") # [!code highlight]
def answer_question(question: str) -> str | None:
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": f"Answer this question: {question}"}],
)
return response.choices[0].message.content
response = answer_question("Who painted the Mona Lisa?")
print(response)
# > Leongardo da Vinci painted the Mona Lisa.
```
Every key component, whether it’s prompt text, parameters, and surrounding logic, is captured together as a single versioned closure. This allows you to use familiar developer tools like autocomplete, linting, and type-checking, making prompt development a structured, testable part of your codebase rather than leaving it as a raw string tacked on at the end.
### 2. Log Every Interaction for Full Visibility and Debugging
Logging data such as inputs, outputs, settings, hyperparameters, token usage, and others, creates a complete audit trail of your system’s behavior, showing you how prompts perform and how AI models respond over time.
This kind of traceability isn’t just nice to have; it’s essential for debugging, performance monitoring, and compliance. When something breaks or behaves unexpectedly, you need to be able to pinpoint what went wrong, when, and why. Logging allows teams to confidently answer questions like “What changed between version 11 and 12?” or “Why did this response cost twice as much?”
For instance, in Lilypad every function decorated with `@lilypad.trace()` is automatically traced and logged. This includes not only the prompt and inputs, but also the outputs, execution time, token counts, and other metadata.
These traces are built on the [OpenTelemetry Gen AI spec](https://opentelemetry.io/) and can include nested spans, meaning you can see how each part of your code, from helper functions to internal LLM calls, was triggered, and how it performed.
The code below shows how Lilypad traces nested function calls, where both the `parent()` and `child()` functions are decorated with `@lilypad.trace()`, allowing their inputs, outputs, and execution metadata to be automatically captured and visualized as linked spans in the trace view:
```python
import lilypad
lilypad.configure()
@lilypad.trace()
def child(text: str) -> str:
return "Child Finished!"
@lilypad.trace()
def parent(text: str) -> str:
output = child("I'm the child!")
print(output)
return "Parent Finished!"
output = parent("I'm' the parent!")
print(output)
# > Child Finished!
# > Parent Finished!
```
The Lilypad playground displays the results of the traced execution, capturing both the `parent()` and nested `child()` calls as structured spans, giving you full visibility into their inputs, outputs, and execution metadata, so you can inspect how and when each function ran:
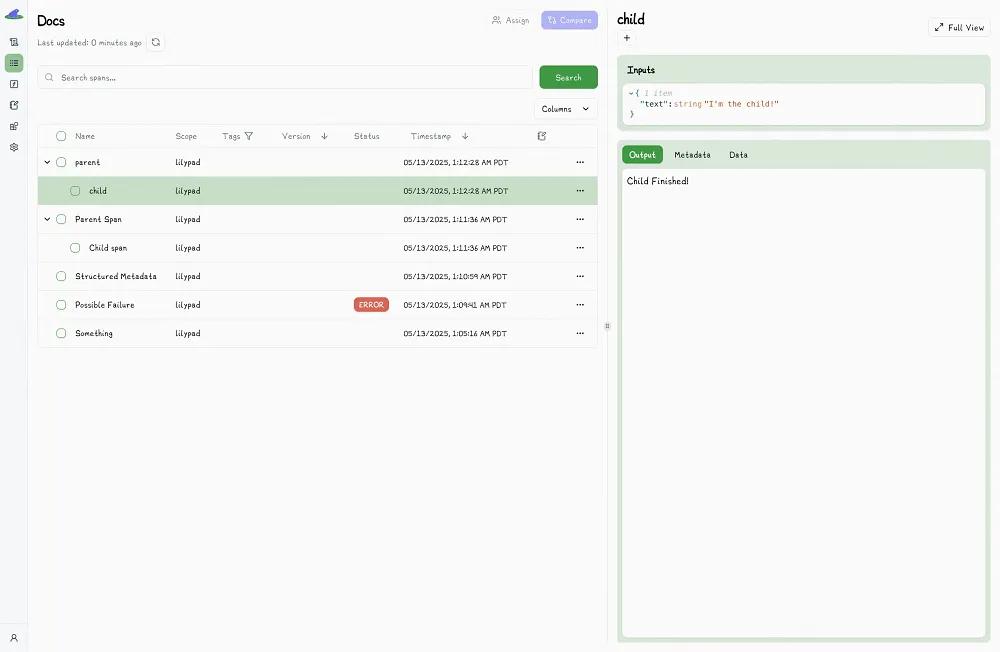
### 3. Use Versioning to Track, Compare, and Improve Prompts
Like any serious development task, prompt optimization works best when it’s experimental and data-driven. By capturing changes to an initial prompt and its configuration as a unique version, you get a complete history of what changed, when, and why.
Versioning also allows you to compare different outputs and supports rigorous, effective [LLM prompt](/blog/llm-prompt) refinement through A/B testing and regression analysis, so you can tie variations in output quality back to specific inputs, edits, or parameter shifts. It lets you evaluate how efficient your prompts are, using token and latency metrics to balance quality with performance and cost.
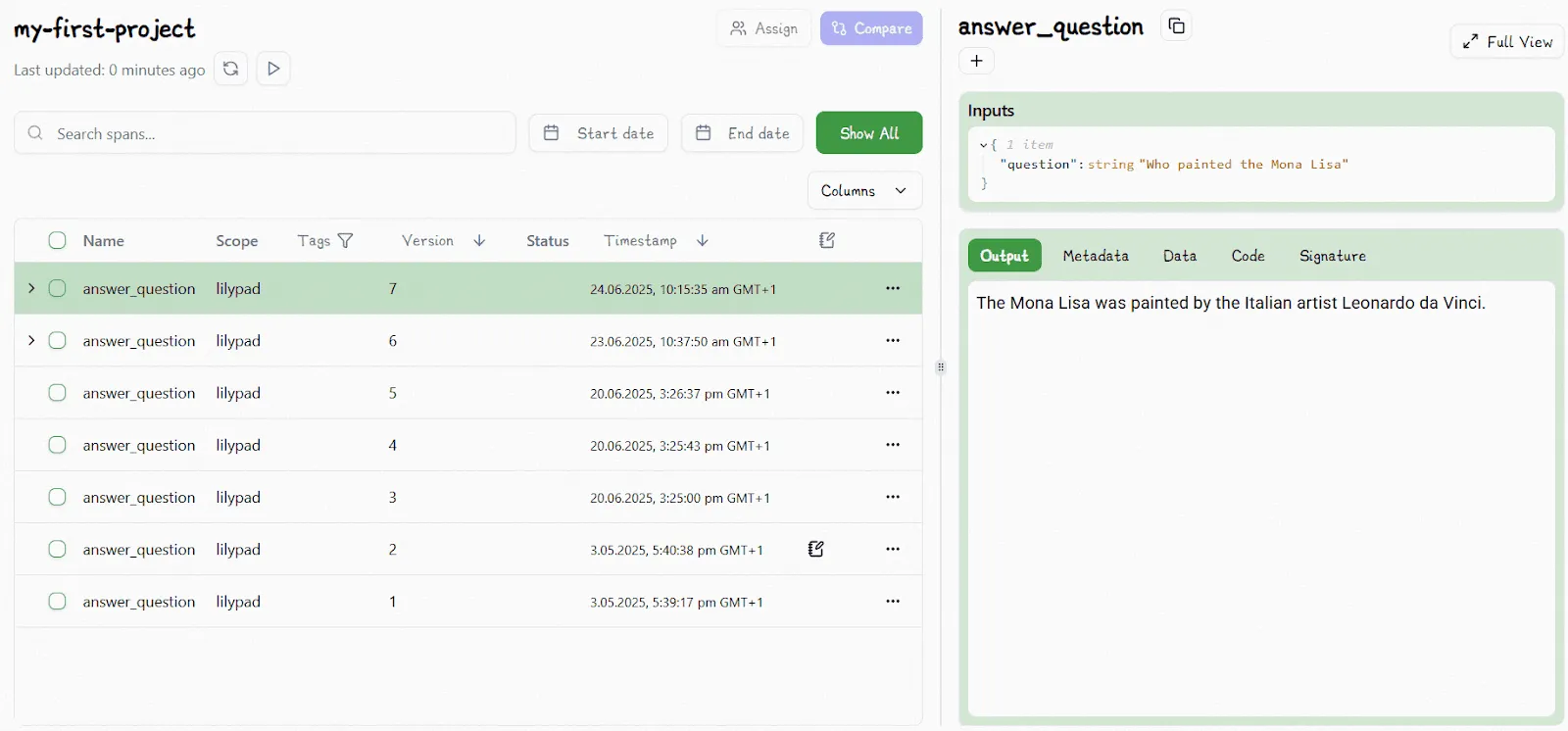
In Lilypad, for example, every time a `@trace`-decorated function is executed, it’s tied to the exact version of the function that ran. You can rerun any past version using `.version(n)`:
```python
response = answer_question.version(7)("Who painted the Mona Lisa?")
```
Lilypad keeps track of versions as well:
You can also compare different versions side by side, showing all relevant metrics:
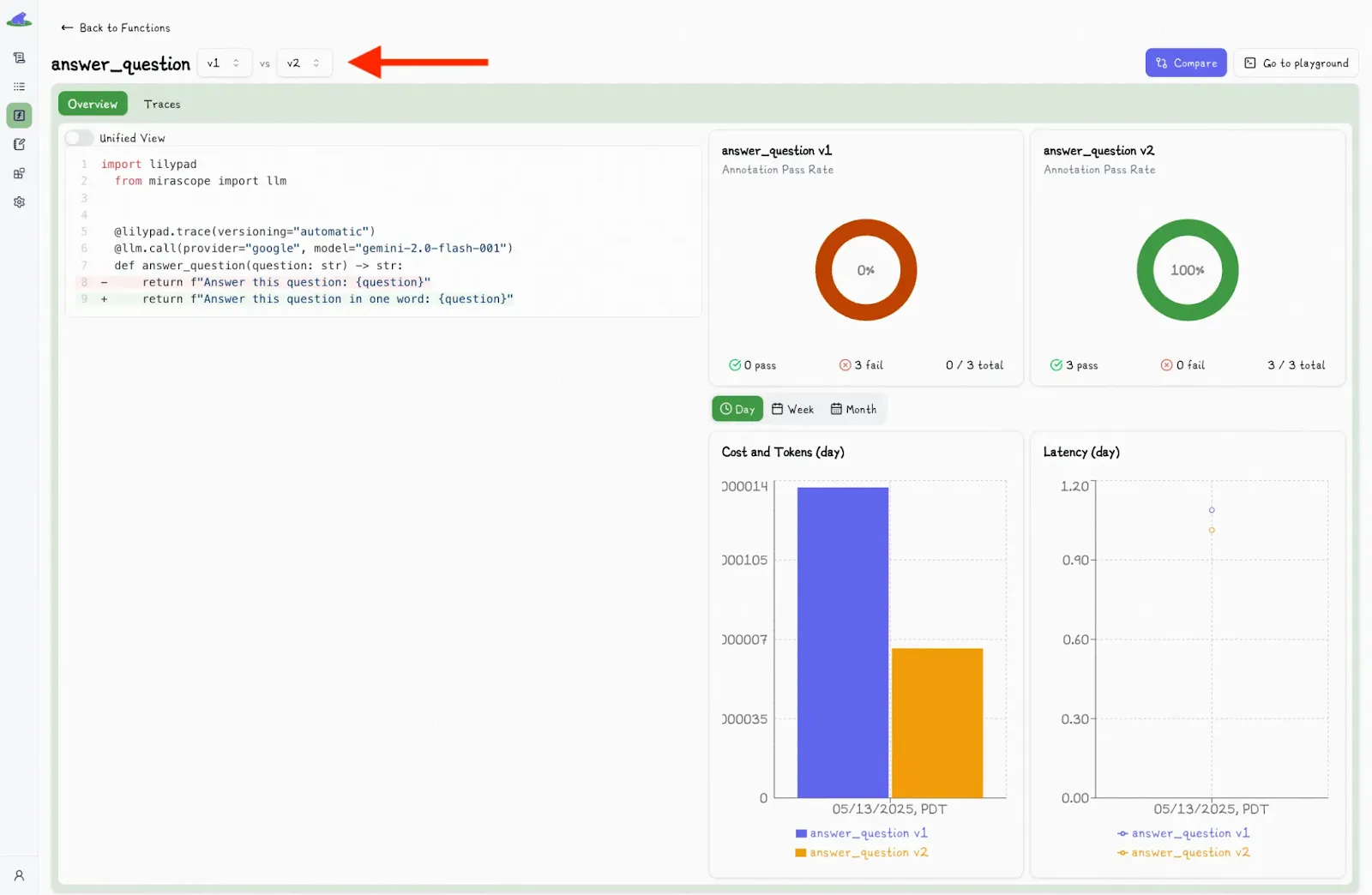
This makes it easy to isolate variables like AI prompt wording, model changes, or other slight tweaks, and see what actually led to better results.
Under the hood, Lilypad automatically versions the entire function closure with every change, including any user-defined functions or classes outside the main prompt function (as long as they’re within scope). Also, identical runs aren’t duplicated and only meaningful changes are tracked.
### 4. Build a Workflow That Enables Non-Technical Collaboration
Prompt optimization shouldn’t be limited to developers. In a real-world setting, domain experts and business users often have important insights into what an AI prompt should do, though their involvement should be made as efficient as possible without triggering the need to redeploy just for a small prompt optimization.
That’s why an effective workflow for LLM development must support collaboration between technical and non-technical users.
For example, Lilypad’s playground provides a shared, no-code space where subject matter experts can safely test and iterate on prompts. The playground supports markdown-style prompt editing, along with structured, type-safe input forms for things like settings of AI models (e.g., provider, temperature), prompt arguments, and configuration values.
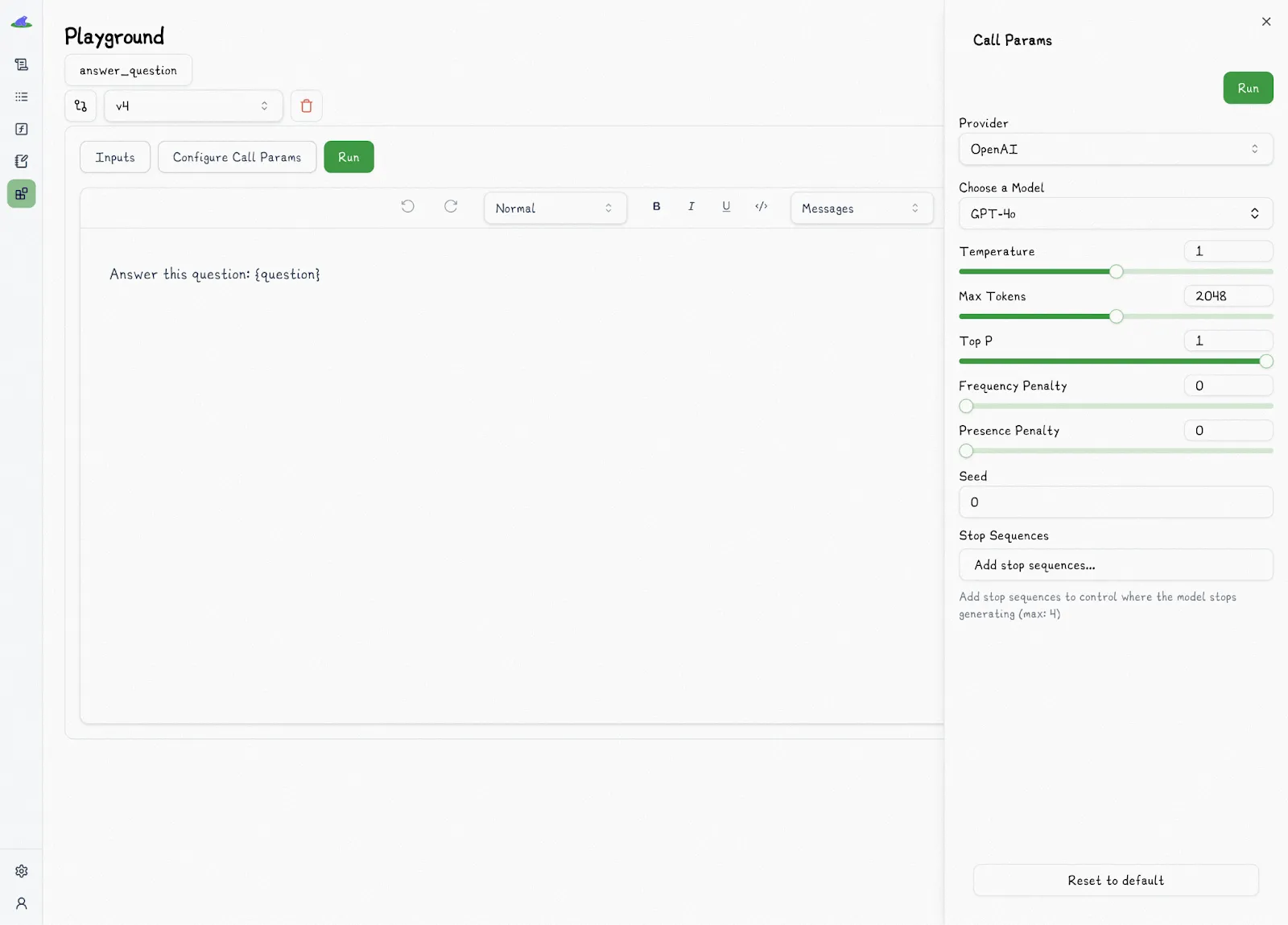
It also displays the full output, including responses of AI models, logs, token usage, latency, and cost, all versioned automatically, without the need to redeploy.
By adding Lilypad’s `@lilypad.trace()` decorator to any function, you effectively add observability to LLM calls and expose their characteristics and outputs in the playground.
This means what runs in the playground is exactly the same function that runs in production. Each run is tied to a specific version and traced automatically, ensuring consistency between what non-technical users are testing and what developers are shipping.
And because prompts are versioned at the function level, developers retain full control over the structure and behavior of the system while domain experts can iterate freely on prompt content and inputs.
This separation of concerns, **with engineers owning the function scaffolding and SMEs owning the iterations**, lets teams move faster without stepping on each other’s toes. When ready, a versioned, effective prompt can be hot-swapped into production by referencing it directly (e.g., `.remote()` or `.version(n)`) all without breaking the build or risking untested changes.
### 5. Evaluate Prompt Performance Through Real-World Feedback, Not Just Tests
[LLM evaluation](/blog/llm-evaluation) isn’t as straightforward as doing unit tests, as outputs can be tricky and a little random due to non-determinism. Assertions won’t catch whether a new prompt is improving or degrading in real-world use; instead, you need a system that captures feedback across multiple runs and versions.
In Lilypad, for instance, tracing and logging over brittle test cases is emphasized, so instead of asking, “Did this return the exact expected answer?” you should be asking, “Is this version of the prompt more useful, more consistent, or more relevant over time?”
Lilypad supports evaluation metrics through annotations, which let you manually label specific runs with pass or fail judgments and freeform reasoning to improve prompt performance.
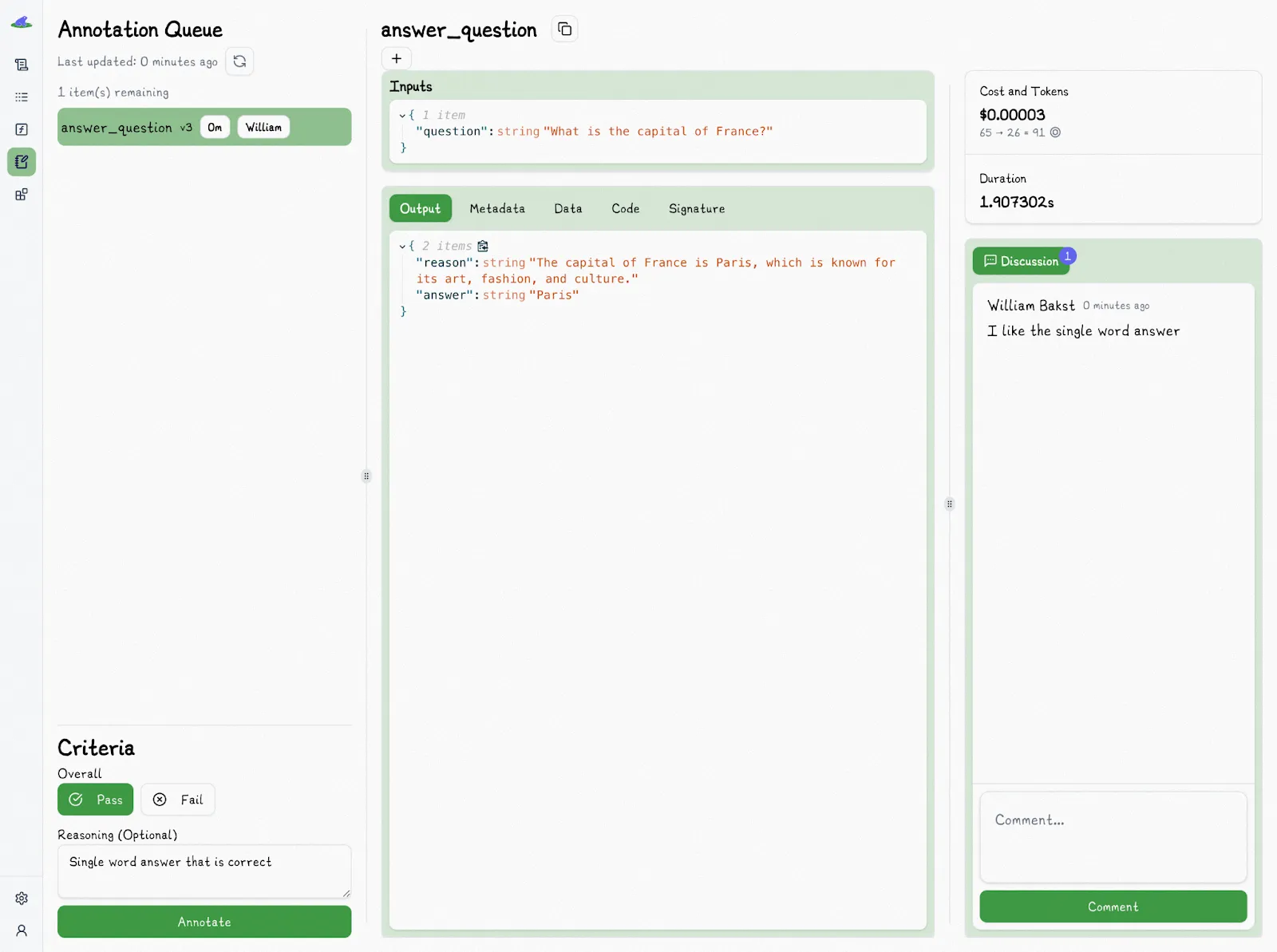
We find that labeling outputs as “pass” or “fail” offers a better baseline for judging their real-world usefulness, compared to rating them on a numerical scale like 1 to 5, where going from, say, a 3 to a 4 can be more subjective and harder to interpret than a clear yes-or-no assessment of whether the output meets expectations.
Each annotation is tied to a particular trace, meaning each [prompt evaluation](/blog/prompt-evaluation) is grounded in the full context of how and when an AI prompt was run. You can assign annotations to teammates, making it easy to review and discuss output quality collaboratively.
For in-code workflows, Lilypad provides a `trace.annotate()` method, which lets you tag and evaluate outputs directly from within [LLM applications](/blog/llm-applications), without modifying function signatures or return values. This makes it simple to fold prompt evaluation into CI pipelines, scripted tests, or automated reporting.
```python
from google.genai import Client
import lilypad
client = Client()
lilypad.configure()
@lilypad.trace(name="Answer Question", versioning="automatic", mode="wrap") # [!code highlight]
def answer_question(question: str) -> str | None:
response = client.models.generate_content(
model="gemini-2.0-flash-001",
contents=f"Answer this question: {question}",
)
return response.text
trace: lilypad.Trace[str | None] = answer_question("Who painted the Mona Lisa?")
print(trace.response) # original response
# > Leonardo da Vinci painted the Mona Lisa.
annotation = lilypad.Annotation( # [!code highlight]
label="pass", # [!code highlight]
reasoning="The answer was correct", # [!code highlight]
data=None, # [!code highlight]
type=None, # [!code highlight]
) # [!code highlight]
trace.annotate(annotation) # [!code highlight]
```
Over time, we recommend building a dataset of these annotated traces. This gives you a contextual record of what worked and why. Lilypad will soon support [LLM-as-a-judge](/blog/llm-as-judge) evaluations, allowing you to reuse these human-labeled examples to automate future assessments during the optimization process and shifting your team’s role from tagging outputs to simply verifying them.
That said, human review still matters. Even as tooling improves, we recommend keeping humans in the loop to catch edge cases and confirm that your LLM-powered application continues to meet quality expectations in real-world use.
## Make Every Prompt Count
Prompting doesn’t end at generation: it begins there. Lilypad traces every AI prompt, captures every version, and helps you evaluate responses over time. That means a better and more effective prompt, fewer regressions, and full transparency into your [LLM integration](/blog/llm-integration).
Want to see it in action? Explore our [docs](/docs/lilypad) or check out our [GitHub](https://github.com/mirascope/lilypad). Lilypad offers first-class support for [Mirascope](/docs/mirascope), our lightweight toolkit for building [LLM agents](/blog/llm-agents).
10 Proven Ways to Optimize Your Prompts
2025-07-22 · 8 min read · By William Bakst