LangChain is a popular tool for building applications with LLMs. It’s great for learning how components fit together, like how to connect to models, pull data, and chain steps to build complex workflows.
It also comes with many tools and integrations, including its own language for building chains (LCEL), plus features for debugging and parsing outputs.
But LangChain isn’t always the best fit for every project:
* Its system of abstractions can get confusing fast, especially if you’re used to plain Python.
* Even simple tasks can drag in tons of dependencies.
* Its update cycle sometimes lags behind those dependencies.
* And while LangSmith (LangChain’s companion versioning and observability tool) logs prompt changes, **it skips other key things**, like which functions or parameters were used, missing part of the context for changes.
This article covers 12 options, including Lilypad, our open-source framework built for versioning, tracing, and optimizing LLM calls, which makes prompt engineering less of a guessing game and more of a science.
We’ll also show you Mirascope, our lightweight toolkit that makes building AI applications simpler and faster.
## 1. Lilypad: Refine LLM Outputs Through Structured Experimentation
[Lilypad](https://github.com/mirascope/lilypad) is an open source prompt engineering framework made for software developers. It captures every LLM call as a snapshot of your code in action, **committed and versioned automatically so you always know what changed, when, and why**.
While LangChain focuses on chaining components together, Lilypad is more comparable to LangSmith: it's about making LLM development reproducible, observable, and iterative.
Lilypad’s lightweight, works with tools like OpenAI, Anthropic, or LangChain, and treats prompt engineering as an optimization problem, tracking every input, prompt, and change.
### Holistic Versioning for Effective Prompt Experimentation
Most prompt engineering tools focus on tracking just one thing: the prompt. But if you’ve worked with LLMs for even a little while, you know the [LLM prompt](/blog/llm-prompt/) is only part of the story.
Truth is, every language model response depends on a mix of things like temperature settings, tools, response models, and even the bits of code wrapped around the call. If your tool isn’t tracking those too, you’re only seeing part of the picture.
**It’s like reading just the headline of an article** and assuming you understand the whole story. You’re missing the context, and with LLMs, context is everything.
Instead of versioning just the prompt, Lilypad starts with the code. Every LLM call is wrapped in a Python function to encapsulate the prompt, the model, call parameters, and any pre- or post-processing logic, as well as any inputs and return values.
Once you add a simple `@lilypad.trace` decorator to make your function a managed prompt, Lilypad takes it from there, automatically versioning and tracing the entire setup. That way, you’re not guessing which change made things better (or worse).
```python
import lilypad
import os
from openai import OpenAI
lilypad.configure()
client = OpenAI()
@lilypad.trace(versioning="automatic") # [!code highlight]
def answer_question(question: str) -> str:
completion = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": question}],
)
return str(completion.choices[0].message.content)
response = answer_question("Which is Saturn's biggest moon?")
print(response)
# > Saturn's biggest moon is Titan.
```
(Note that setting `versioning=”automatic”` in the trace decorator will automatically track changes.)
This turns your prompt experiments into something closer to software engineering or machine learning, with visibility, traceability, and the ability to improve over time.
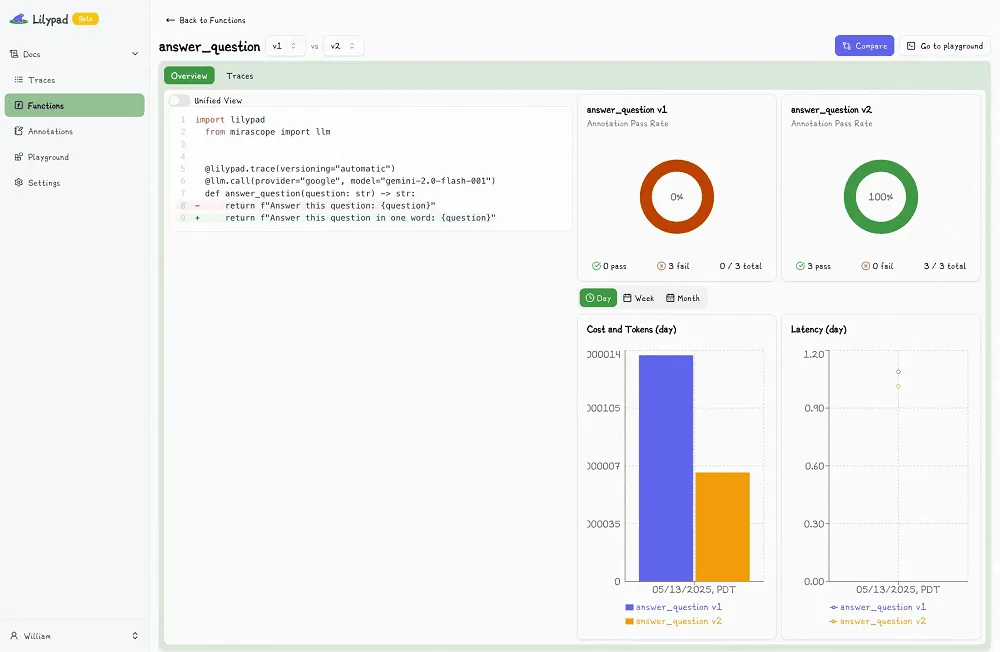
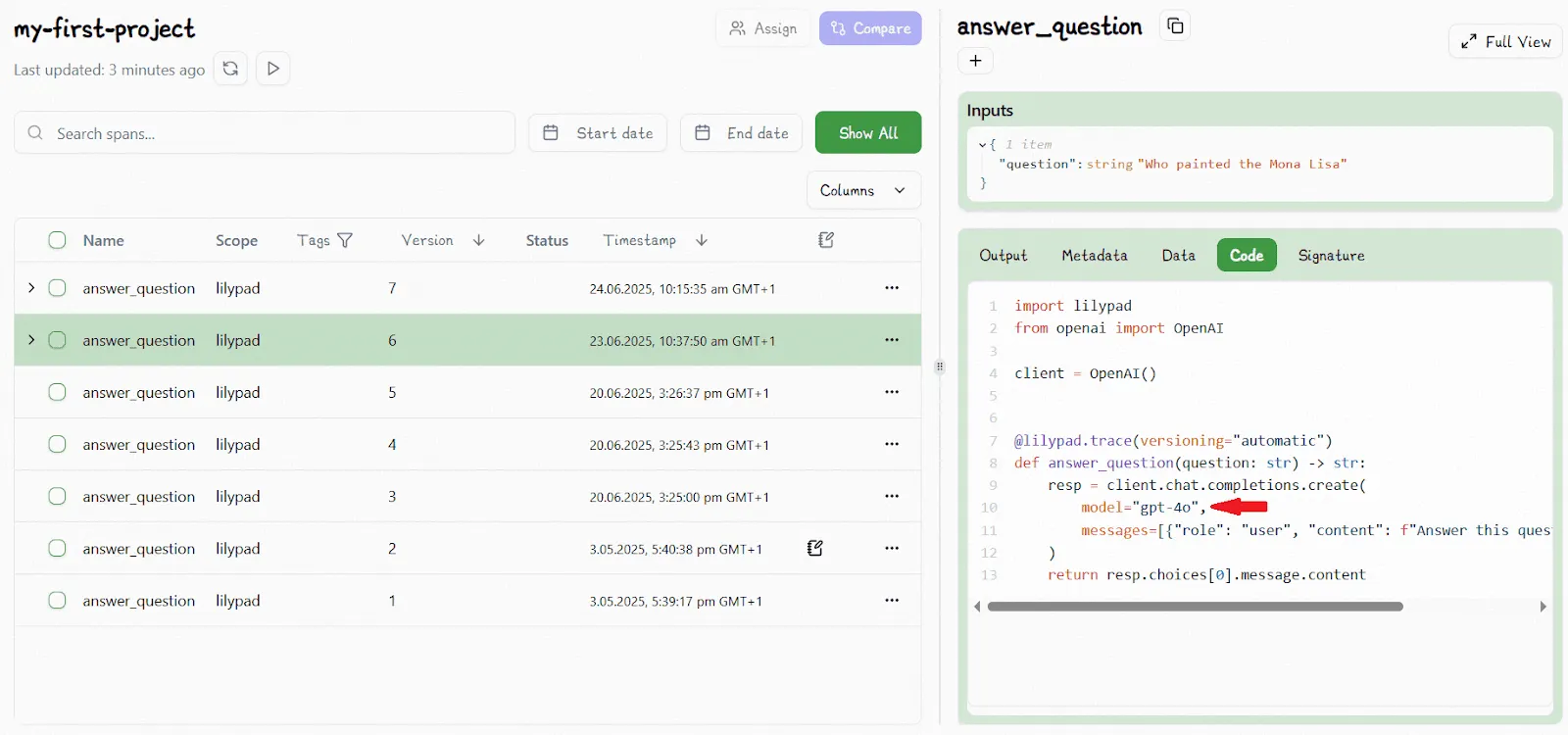
As an example of this, below we show a code sample that’s similarly wrapped in `lilypad.trace` after it first appears in Lilypad playground as V6:
As soon as we change any part of the function, e.g., edit the model type to be `gpt-4o-mini`, and Lilypad automatically increments the version to V7:
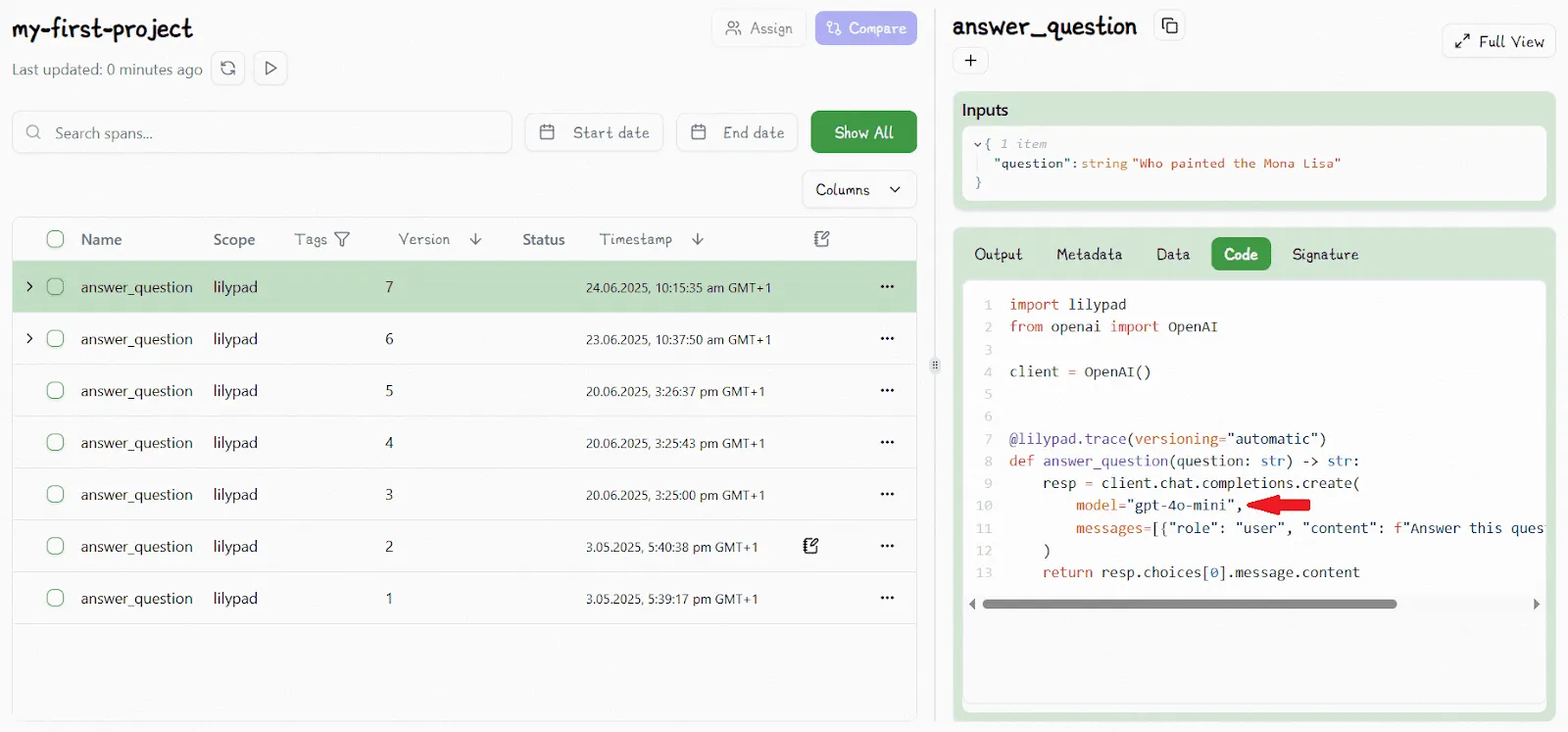
If Lilypad detects that nothing has changed when you run the code, or a change is identical to a previous version, the version won't be updated.
Lilypad versions functions using their function closure, which means any user-defined functions or classes it interacts with (that are within scope) are also logged and tracked automatically.
Lilypad uses the [OpenTelemetry Gen AI spec](https://opentelemetry.io/) to trace every call made by a generation.

Each generation’s output can be annotated with pass/fail labels and reasoning, enabling systematic evaluation of whether prompt changes improve output quality (as described later).
### Collaborating with Non-Technical Domain Experts
When developers and domain experts have to work in the same codebase without proper separation of concerns, prompts aren’t decoupled from the code that uses them.
This makes even small changes risky and time-consuming. Non-technical team members, who often know how to best craft and edit prompts, can’t easily make updates without involving an engineer.
And for engineers, even a one-line prompt edit can mean a full redeploy, risking bugs in unrelated parts of the system due to dependency changes, config drift, and more.
Thanks to Lilypad’s playground environment, domain experts don’t need access to the codebase at all. They can create, edit, and test prompts in a dedicated web UI, complete with type-safe variables, real-time feedback, and metadata like token usage, cost, provider, model, and temperature settings. It’s all versioned, traceable, and easy to test.
Engineers still control what runs in production, **but prompts can be hot swapped**, as playground users iterate on prompts, without touching the code or triggering a redeploy. The result? Faster iteration, less friction, and safer collaboration.
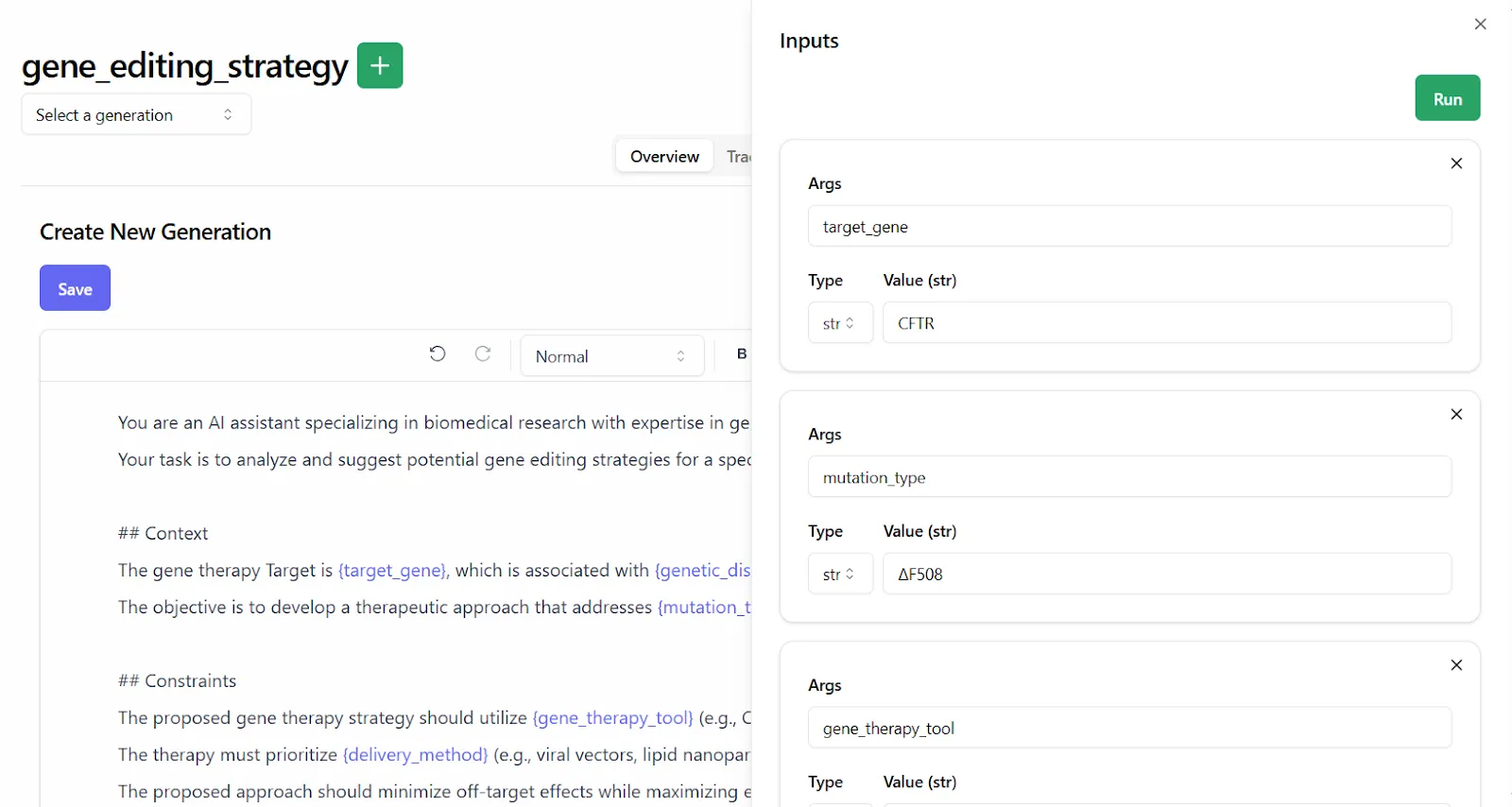
Lilypad’s markdown prompt templates support variables backed by type-safe function signatures, which hold prompt arguments and values:
### Evaluating LLM Outputs with Easy Annotations
The fact that LLM outputs are inherently non-deterministic makes traditional unit tests ineffective. Instead, [LLM evaluation](/blog/llm-evaluation/) is a continuous process — you're always uncovering new edge cases, and "correctness" often depends on context and human judgment.
Since LLM responses often don’t have clear-cut right or wrong answers, we rely on fuzzy metrics, with pass/fail labels being the most practical. They simplify subjective [prompt evaluation](/blog/prompt-evaluation/) into a clear question: Is this good enough to use?
In high-stakes scenarios, like medical recommendations, expert human annotators are essential to make that call. Overcomplicating this with granular scoring (like 1–5 stars) often adds confusion without improving reliability.
The goal is to ultimately ship useful, reliable features, not perfect ones. Pass/fail evaluations provide a clear, repeatable way to measure progress and guide prompt iteration, which you tweak until it consistently passes.
Lilypad allows non-technical teams to easily annotate prompts with pass/fail labels by simply selecting an output in the playground:
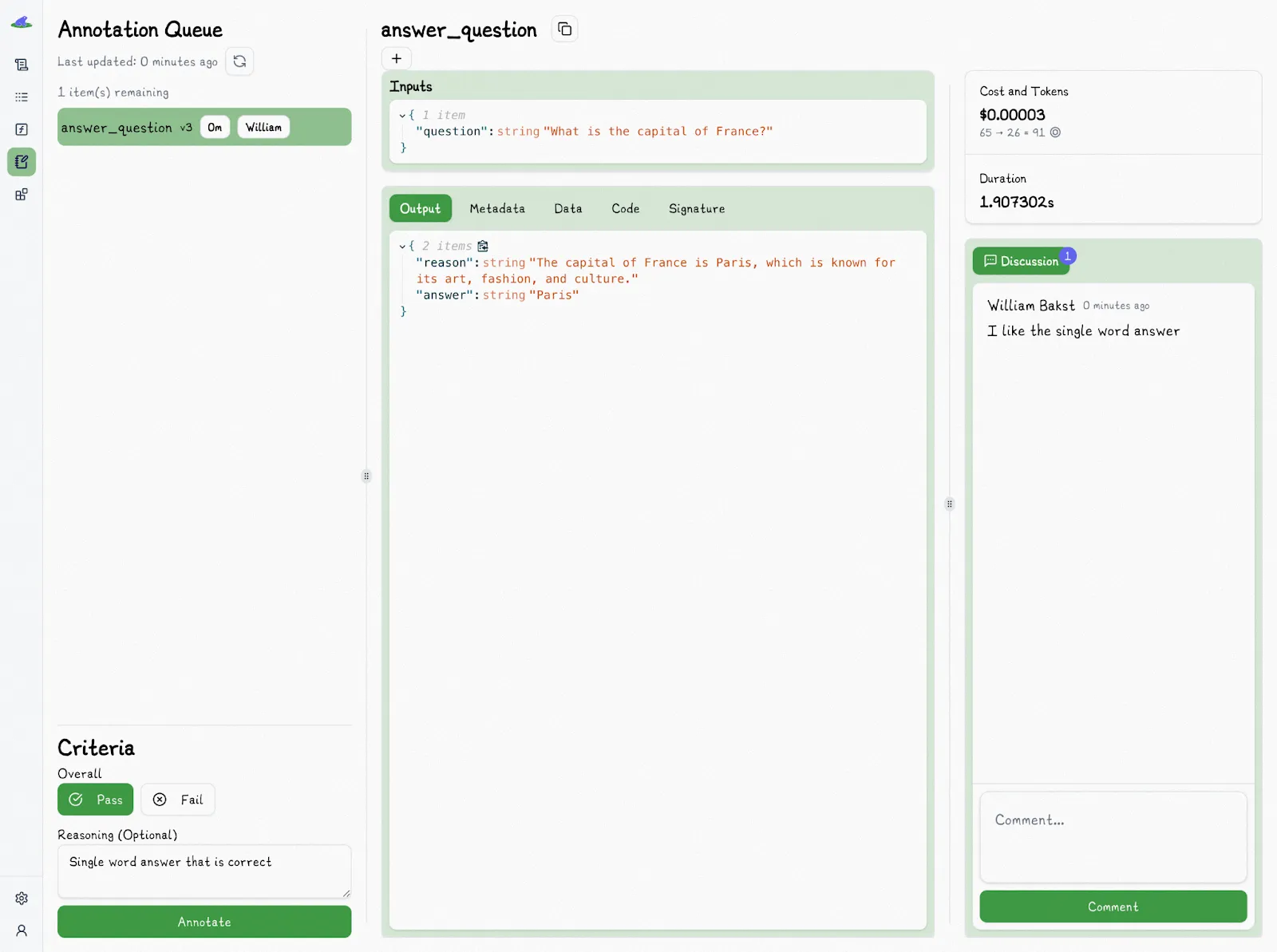
A simple pass/fail label, backed by a short explanation, is one of the best ways to start automating your evaluations. By consistently tagging outputs as pass/fail and explaining why, you can train an LLM judge to take over that job. Instead of spending all your time labeling, you shift the work to verifying, which is faster and more efficient.
Lilypad plans to roll out an [LLM\-as-a-judge](/blog/llm-as-judge/) feature soon to help with exactly this. But even once it’s live, human verification will still matter. Spot-checking results is the best way to catch issues, build trust in your evals, and improve your dataset over time.
Get started with [Lilypad](https://lilypad.mirascope.com/) to structure your prompt experiments and track what’s working, and why.
## 2. Mirascope: User-Friendly Library that Simplifies LLM Application Development
[Mirascope](https://github.com/mirascope/mirascope) is a lightweight Python toolkit that prioritizes simplicity, reliability, and developer experience. It’s designed to be simple, modular, enjoyable to use, and to work with Lilypad.
We believe prompt engineering deserves the same level of tooling and consideration as any other aspect of software engineering, and Mirascope gives you building blocks for [LLM integration](/blog/llm-integration/) instead of boxing you into some clunky structure. You get control over what you use, how you use it, and nothing gets in your way.
Mirascope allows you to:
* Write LLM calls in the same clean Python you already know.
* Use one consistent interface, no matter which model provider you're using.
* Get structured, validated responses from your LLMs using Pydantic models.
Below we’ve got examples for each of these:
### A Pythonic Approach to LLM Development
A lot of frameworks try to make your life easier by creating abstractions for tasks you could already do with plain Python. **It might sound helpful** to make complex patterns easier to manage, but often such libraries aren't written with software developer best practices in mind and obscure what’s happening under the hood.
Take LangChain runnables, for example. They’re great when you want to chain a couple of steps together. But as soon as your workflow gets more complex, they start to feel like a black box: confusing and hard to control.
These frameworks also tend to pile on different abstractions for every little thing, like one-shot, zero-shot, and few-shot prompt templates. That means more dependencies to import, and more time spent waiting for updates to those dependencies. Sometimes, it’s just simpler, and smarter, to stick with Python.
Mirascope was built with real software engineering in mind. We lean into native Python wherever possible, so you’re working in a language you already know, not fighting through some new framework.
We also use the powerful Pydantic library to handle data validation and structure. It keeps your code clean and your outputs predictable.
Our goal? Make your coding experience smooth, clear, and easy to follow. We don’t hide the magic, **we show you how it works**. Instead of reinventing the wheel, we use Python features like computed fields and function chaining, which let you directly manage execution of [prompt chaining](/blog/prompt-chaining/) without needing the intermediate constructs like runnables.
That means you get more control, better visibility into what’s going on, and way less to learn before you’re up and running.
### Convenient LLM Calling
Some prompt engineering libraries don’t centralize important elements for calls, like how prompts are formatted or what model settings you're using. Instead, they spread things over your codebase, so making changes gets messy.
Even switching model providers involves writing extra boilerplate just to make it work, which slows down how fast you can test and improve your prompts.
Mirascope makes calls clean and easy to manage so they’re more readable, no matter which model provider you're using.
At the heart of it is the `@llm.call` decorator, which accepts provider and model arguments and returns a `CallResponse` that behaves the same across OpenAI, Anthropic, Mistral, and more. Want to switch providers? Change a single line. That's it.
To keep things organized, Mirascope also gives you the `@prompt_template` decorator. You can pair it with `@llm.call` to write reusable prompts that stay right next to the logic that uses them. That means easier updates, better version control, and fewer headaches.
You can stack both decorators onto any regular Python function to instantly turn it into a traceable, provider-aware LLM call:
```python
from mirascope import llm, prompt_template
from pydantic import BaseModel
class Movie(BaseModel):
title: str
director: str
@llm.call(provider="openai", model="gpt-4o-mini", response_model=Movie) # [!code highlight]
@prompt_template("Extract {text}") # [!code highlight]
def extract_movie(text: str): ... # [!code highlight]
movie = extract_movie("Inception by Christopher Nolan")
print(movie)
# Output: title='Inception' director='Christopher Nolan'
```
If you’re using Lilypad, even better. Mirascope’s `@llm.call` plays nicely with `@lilypad.trace`, letting you trace every call and version every change to give you a full audit trail with zero extra effort.
```python
from mirascope import llm, prompt_template
@lilypad.trace(versioning="automatic") # [!code highlight]
@llm.call(provider="openai", model="gpt-4o-mini", call_params={"max_tokens": 512})
@prompt_template("Recommend a {genre} movie")
def recommend_movie(genre: str): ...
response: llm.CallResponse = recommend_movie("comedy")
print(response.content)
# "You should watch *Superbad*. It's a hilarious coming-of-age comedy packed with awkward teenage moments and great one-liners."
```
### Built-In Response Validation
Most prompt engineering frameworks leave it to you to check LLM outputs. They hand off the call, then it’s your job to write boilerplate just to make sure the response is actually what you expected.
That’s a problem, **because LLMs can be unpredictable**. If your application’s expecting one structure and gets something else, you get runtime errors. Or worse, silent bugs that sneak through your system and are a nightmare to track down.
That’s why response validation matters. You need to lock in the shape of the output and verify it before anything else runs.
With Mirascope’s built-in response validation powered by Pydantic, you can catch errors before your code ever runs.
You define a response model ahead of time using a Pydantic `BaseModel`, which specifies what the LLM’s output should look like. Then Mirascope automatically validates the LLM’s output according to your defined response model by parsing it into a clean, type-safe Python object.
That object becomes the function’s return value: ready to use, fully structured, and totally predictable.
```py
from mirascope import llm, prompt_template
from pydantic import BaseModel
class Book(BaseModel):
"""An extracted book."""
title: str
author: str
@llm.call(provider="openai", model="gpt-4o-mini", response_model=Book)
@prompt_template("Extract the book title and author from this text: {text}")
def extract_book_details(text: str): ...
response = extract_book_details("The book 'Foundation was written by Isaac Asimov.")
print(response.title) # Output: Foundation
print(response.author) # Output: Isaac Asimov
```
Your IDE immediately shows whether the return type matches the structure you expect when you hover the cursor over `response`, which is inferred as an instance of the `Book` model.
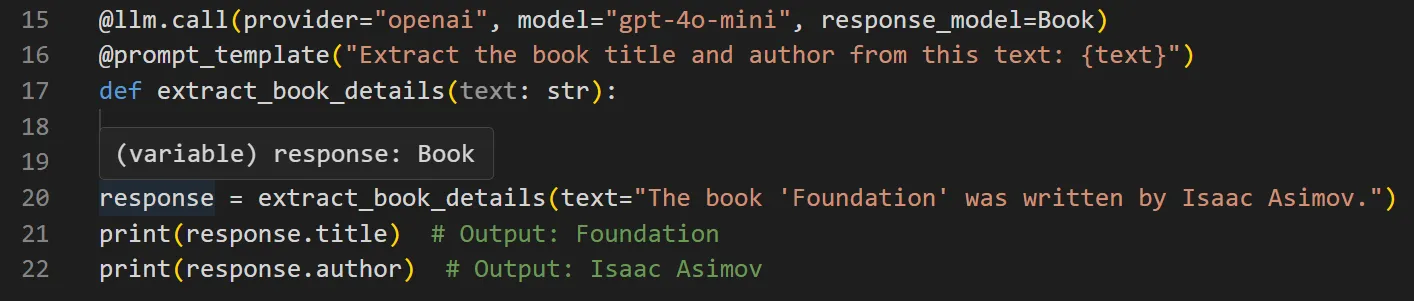
Response models also feature auto-complete for expected values:
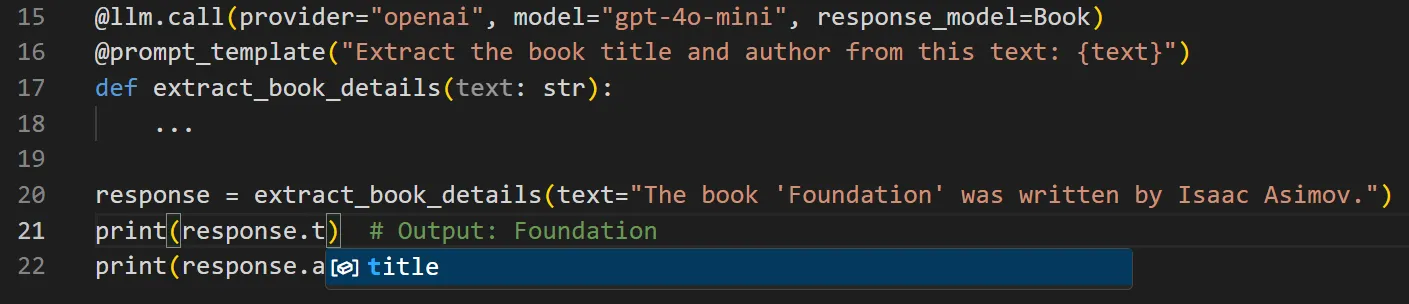
If the LLM strays from the format Mirascope will throw a clear `ValidationError` at runtime, so issues never go unnoticed. It’s response handling with guardrails and built for real-world dev work.
Start building intelligent [LLM agents](/blog/llm-agents/) faster with Mirascope’s [developer-friendly toolkit](https://github.com/mirascope/mirascope). You can also find code samples and more information in our [documentation](/docs/v1/learn/).
## 3. LlamaIndex: Empowers Developers to Build Data-Driven Apps
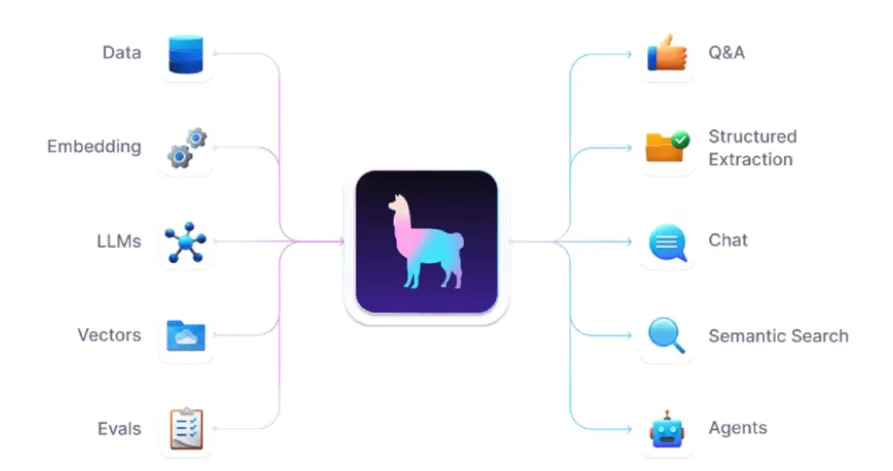
[Llamaindex](https://www.llamaindex.ai/), formerly GPT Index, is a data framework for building LLM applications that benefit from “context augmentation,” meaning that user queries also retrieve relevant information from external data sources (e.g., documents and knowledge bases).
This is done to enrich answers by injecting the retrieved information into the machine learning LLM before it generates its response, providing it with a better understanding of context and allowing it to produce more accurate and coherent real-time outputs.
A typical example of context augmentation is a retrieval augmented generation (RAG) system that uses a vector database like Chroma, for which Llamaindex specializes in orchestrating tasks.
Llamaindex has a [documentation site](https://docs.llamaindex.ai/en/stable/) and a [GitHub repo](https://github.com/run-llama/llama_index) where you can download the source code.
## 4. Griptape: Minimal Prompt Engineering with Python

[Griptape](https://www.griptape.ai/) is a Python framework for developing AI-powered applications that enforces structures like sequential pipelines, DAG-based workflows, and long-term memory. It follows these design tenets:
* All framework primitives are useful and usable on their own in addition to being easy to plug into each other
* It’s compatible with any capable LLM, data store, and backend through the abstraction of drivers
* When working with data through loaders and tools, it aims to efficiently manage large datasets and keep the data off prompt by default, making it easy to work with big data securely and with low latency
* It’s much easier to reason about code written in a programming language like Python, not natural languages. Griptape aims to default to Python in most cases unless absolutely necessary
Griptape features both a [documentation site](https://docs.griptape.ai/stable/) and a repo on [GitHub](https://github.com/griptape-ai/griptape).
## 5. Semantic Kernel: Streamlined Integration with the Microsoft Ecosystem
[source](https://learn.microsoft.com/en-us/semantic-kernel/concepts/semantic-kernel-components?pivots=programming-language-csharp)
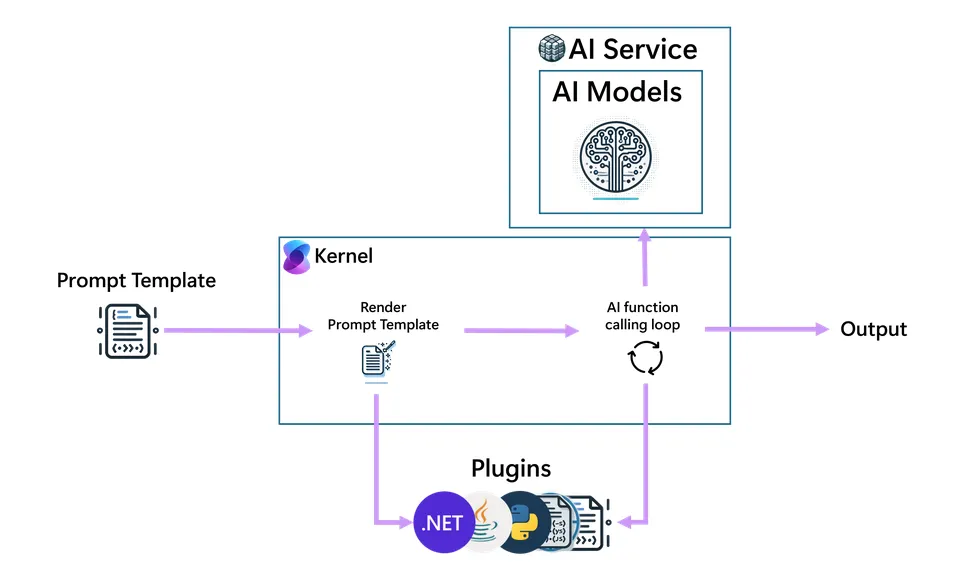
[Microsoft Semantic Kernel](https://learn.microsoft.com/en-us/semantic-kernel/overview/) is an open-source development kit that lets you integrate AI models into applications through a flexible plugin system.
It consists of a central component that acts as a dependency injection container, managing services and plugins necessary for AI applications, and offers pre-built or custom functionalities (plugins) that encapsulate specific tasks, allowing developers to extend AI capabilities.
This allows it to easily integrate with various AI models and services, including text generation, chat completion, and experimental features like text-to-image and audio processing.
Semantic kernel also integrates with the .Net ecosystem and supports programming languages like C\#, Java, and Python, with C\# having the most comprehensive feature set.
Microsoft Kernel has a [GitHub repo](https://github.com/microsoft/semantic-kernel) (along with a separate site for [documentation](https://learn.microsoft.com/en-us/semantic-kernel/)) where you can access the source code.
## 6. Braintrust: Automates Evaluation Processes for Faster Iteration
[source](https://www.braintrust.dev/docs/start)
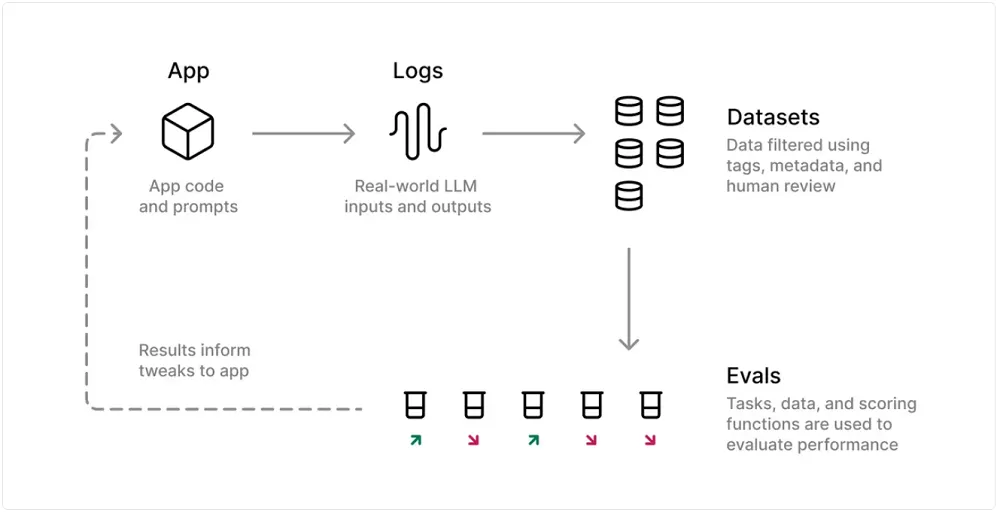
[Braintrust](https://www.braintrust.dev/) is an end-to-end platform for building AI applications that allows you to create, test, deploy, and continuously improve them.
It provides a framework that allows developers to build and assemble AI applications using reusable components and include a suite of tools that simplify the creation and management of agents.
It also offers a playground for iteratively and rapidly prototyping and testing different prompts with various models, allowing for experimentation with real dataset inputs and comparing responses across various models like OpenAI, Anthropic, Mistral, Google, and Meta.
Braintrust provides advanced evaluation capabilities, including trials, hill climbing, and detailed test case management. Its `Eval()` feature allows users to score, log, and visualize outputs to evaluate [LLM applications](/blog/llm-applications/) without guesswork.
You can learn more about Braintrust by going to its [documentation site](https://www.braintrust.dev/docs/start) or its [GitHub repo](https://github.com/braintrustdata).
## 7. Haystack: Utilizes a Modular Pipeline System
[source](https://docs.haystack.deepset.ai/v2.4/docs/tracing)
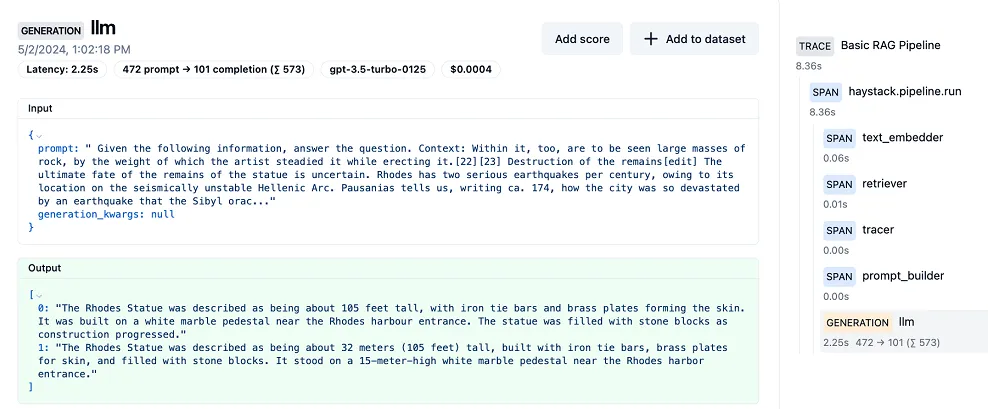
[Haystack](https://haystack.deepset.ai/) is an end-to-end framework for building applications using LLMs, transformer models, vector search, and more. Examples of such applications include RAG, question answering, and semantic document search.
Haystack is based on the notion of pipelines, which allow you to connect various Haystack components together as workflows that are implemented as directed multigraphs. These can run in parallel, allowing information to flow through different branches, while loops can be implemented for iterative processes.
Haystack features extensive resources including a dedicated [documentation site](https://docs.haystack.deepset.ai/docs) and a [GitHub repository](https://github.com/deepset-ai).
## 8. Flowise AI: Low Code LLM Application Builder
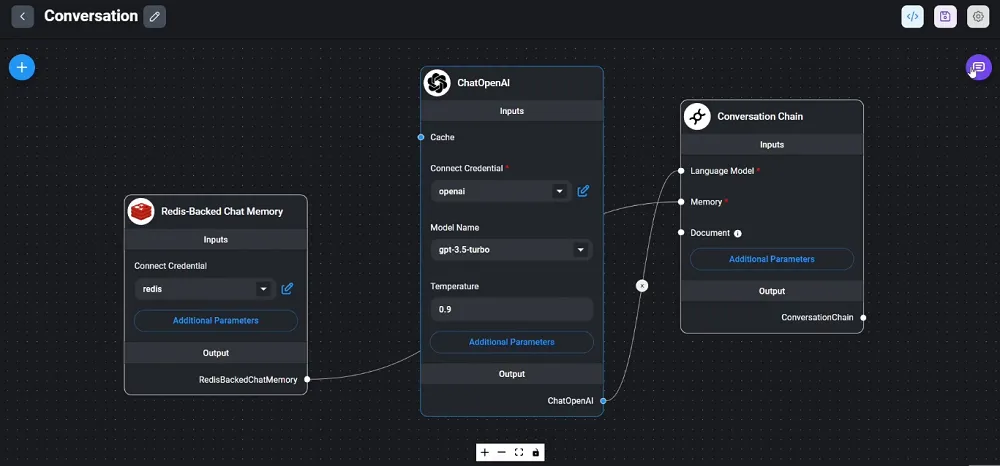
[Flowise](https://flowiseai.com/) lets you build LLM\-based applications (e.g., chatbots, agents, etc.) using a cutting-edge low-code or no-code approach via a graphical user interface, eliminating the need for extensive programming knowledge.
Through its drag and drop approach, Flowise enables you to develop many of the same applications based on large language models that you normally would with standard coding libraries. Flowise’s approach is great for those who want to develop LLM and generative AI applications — this could include beginners, those not proficient at coding, or those just wanting to rapidly develop prototypes. It also works with other low-code or no-code applications like Bubble and Zapier (the latter offering integrations with numerous other [LLM tools](/blog/llm-tools/)).
Flowise has a website that features extensive [documentation](https://docs.flowiseai.com/), as well as a [GitHub repository](https://github.com/FlowiseAI/Flowise).
## 9. Orq: Unifies LLM Application Management
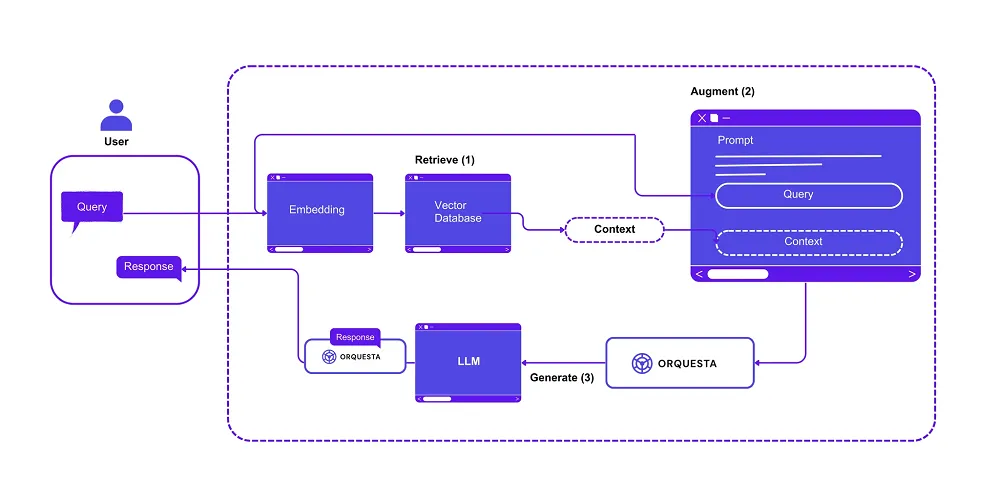
[Orq.ai](http://Orq.ai) is an end-to-end LLMOps platform for collaboratively developing, deploying, and managing LLM\-driven applications.
Its low-code/no-code approach simplifies application development and automation for teams by offering all the necessary and customizable tools in one place. It connects with many different models and providers, and allows developers to experiment and test AI ideas before fully building them.
The intuitive dashboard facilitates collaboration between technical and non-technical team members, and provides built-in tools for performance tracking, anomaly detection, and model tuning to ensure LLM applications run efficiently.
It also offers playgrounds and experiments for testing AI models, prompt configurations, and RAG pipelines in a controlled environment before production.
You can find out more by consulting its [documentation](https://docs.orq.ai/reference/authentication) or its [GitHub repository](https://github.com/orq-ai).
## 10. Langroid: Minimizes Learning Curve with Intuitive Agent-Task Paradigm
[source](https://langroid.github.io/langroid/tutorials/langroid-tour/)
[Langroid](https://langroid.github.io/langroid/) is a lightweight Python framework designed for building LLM\-powered applications using a multi-agent programming paradigm.
It allows developers to fully configure agents with capabilities including utilization of LLMs, vector databases, natural language processing (NLP), and tools, and enables collaborative problem-solving through message exchanges between agents.
Key features include:
* Task delegation by agents, which can break down complex tasks and delegate subtasks to other agents
* Integration with vector databases for information retrieval
* Implementation of caching mechanisms and logging for improved performance and debugging
* Minimization of complexity with clean abstractions like “Agents” and “Tasks,” to allow developers to get started and achieve results quickly, reducing the learning curve compared to LangChain's more feature-rich but complex ecosystem
To get started with Langroid, you can refer to its [documentation](https://langroid.github.io/langroid/quick-start/) or [GitHub page](https://github.com/langroid/langroid).
## 11. Rivet: Visualizes Complex Logic Chains for Clarity
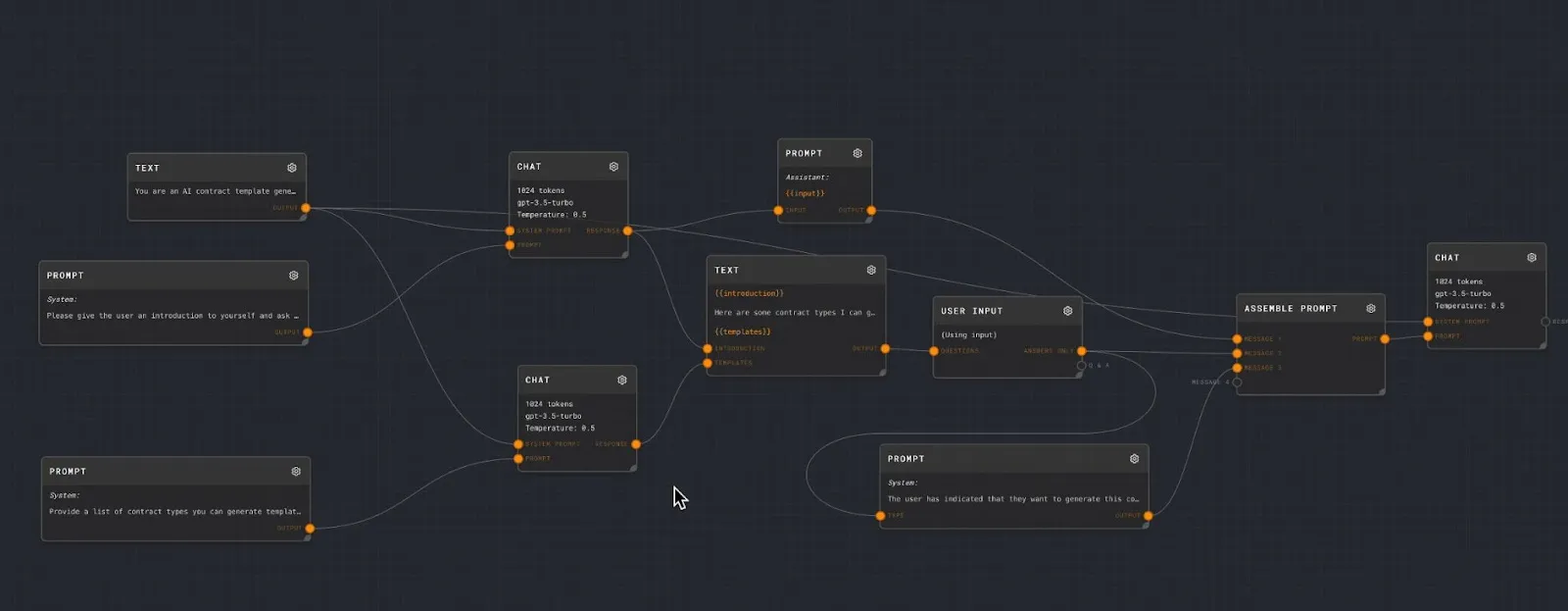
[Rivet](https://rivet.ironcladapp.com/) is a no-code, open-source visual programming environment designed for building applications with generative AI.
It offers a graphical interface where users can design, debug, and iterate on "prompt graphs" visually. These graphs represent workflows and interactions between LLMs and other components.
Rivet offers a drag-and-drop interface for creating workflows that simplifies debugging and iteration, and features easy collaboration as well. It allows for granular control in setting up data processing chains that don't necessarily involve LLMs, providing flexibility for various use cases.
It’s compatible with Windows, Linux, and Mac systems, and supports multiple LLM providers, including OpenAI, Anthropic, and AssemblyAI.
You can learn more about Rivet by having a look at its [documentation](https://rivet.ironcladapp.com/docs) and [GitHub page](https://github.com/ironclad/rivet).
## 12. Humanloop: Empowers Teams with Intuitive A/B Testing for AI Models
[source](https://humanloop.com/docs/v5/guides/prompts/call-prompt)
[Humanloop](https://humanloop.com/) is a low-code tool that helps developers and product teams create LLM apps using a variety of providers. It focuses on improving AI development workflows by helping you design effective prompts, do customization, and evaluate how well the AI performs these tasks.
Humanloop offers an interactive editor environment and playground allowing both technical and non-technical roles to work together to iterate on prompts. You use the editor for development workflows, including:
* Experimenting with new prompts and retrieval pipelines
* Fine tuning prompts
* Debugging issues and comparing different models
* Deploying to different environments
* Creating your own templates
Humanloop has a website offering complete [documentation](https://humanloop.com/docs/v5/getting-started/overview), as well as a [GitHub repo](https://github.com/humanloop) for its source code.
## Get Started with Prompt Engineering
Lilypad and Mirascope aim to remove the complexities around the engineering workflow so you can focus on the content of your prompts. Lilypad upholds the idea that [advanced prompt engineering](/blog/advanced-prompt-engineering/) requires structure, versioning, and continuous evaluation.
Mirascope allows you to code how you normally code, without getting bogged down in dense and confusing abstractions.
Want to learn more? Check out [Lilypad’s documentation](/docs/lilypad), or [Mirascope’s code samples](/docs/mirascope).
12 LangChain Alternatives in 2025
2025-06-27 · 9 min read · By William Bakst