A LangChain prompt template is a reusable way to build prompts for language models. It gives you a clear structure to follow, while making it easy to customize prompts and save time.
LangChain’s templates help keep your prompts consistent, and make the model’s answers more predictable and reliable. Over time, **they also improve results by reducing randomness in how prompts are written**.
A prompt template usually consists of two things:
1. A text prompt, which is just a chunk of natural language. It can be plain text, or it can have placeholders like `{variable}` that get filled in with real values when you use it.
2. Optional formatting rules, so you can control how the final prompt looks, like whether text should be bold, in all caps, or styled a certain way.
Once you fill in the variables, the template turns into a finished prompt that gets sent to the LLM to generate a response.
In our experience, LangChain’s prompt templates work well for getting started and handling most tasks, but when your app scales up and starts making 100+ LLM calls, **its built-in system starts to feel clunky and hard to scale**: managing all the different components (using LangChain and LangSmith), like chains and iterations, becomes messy fast.
That’s why we designed Mirascope and Lilypad to make LLM app development easier.
[Mirascope](https://github.com/mirascope/mirascope) is a user-friendly LLM toolkit that offers just the right abstractions to build smarter apps, without the clutter, confusion, or guesswork ([jump down](#how-mirascope-makes-prompt-templates-easier-to-build) to read more). [Lilypad](https://github.com/mirascope/lilypad) is a prompt management and observability tool that makes use cases for tracing and versioning prompts easier, to test what’s working ([skip to here](#how-lilypad-makes-structuring-calls-and-prompts-easier) to read more about Lilypad).
We dive into how LangChain prompt templates work and show you ways of iterating and versioning prompts using Mirascope and Lilypad.
## 3 Types of LangChain Prompt Templates
LangChain offers different template classes:
* String `PromptTemplate` for creating basic prompts.
* `ChatPromptTemplate` for chat-based prompts with multiple messages.
* `MessagesPlaceholder` for injecting a dynamic list of messages (such as a conversation history).
### `PromptTemplate`: Simple String-Based Prompts
This generates prompts by filling in blanks in a string, and is perfect for completion-style models that expect a single text input (`text-davinci-003` or similar).
You define a prompt with placeholders using standard Python format syntax. At runtime, these get resolved to generate the final prompt string:
```python
from langchain_core.prompts import PromptTemplate
example_prompt = PromptTemplate.from_template("Share an interesting fact about {animal}.") # infers 'animal' as input variable
# Format the template with a specific animal
filled_prompt = prompt.format(animal="octopus")
print(filled_prompt)
#> Share an interesting fact about octopus.
```
You can have multiple placeholders like `{animal}` and `{topic}` as needed, or none at all if the prompt is always the same.
### `ChatPromptTemplate`: Chat-Style Prompt with Roles
Chat-based models (like GPT\-4, Claude, or Gemini) don’t just take in a plain string. They expect a sequence of messages where each message has a role (like "system", "user", or "assistant") and some content.
LangChain's `ChatPromptTemplate` helps you build these kinds of prompts cleanly and dynamically. Think of it as a way to define a chat scenario with placeholders, then fill in the values when needed.
```python
from langchain_core.prompts import ChatPromptTemplate
chat_prompt = ChatPromptTemplate.from_messages([
("system", "You are a patient tutor who explains things clearly."),
("human", "Can you explain {concept} like I'm five?")
])
# Fill in the template with a specific concept
formatted_messages = chat_prompt.format_messages(concept="gravity")
print(formatted_messages)
```
After formatting, this will give you something like:
```
[
SystemMessage(content="You are a patient tutor who explains things clearly.", role="system"),
HumanMessage(content="Can you explain gravity like I'm five?", role="user")
]
```
Each item in that list is a structured message that includes both the role and the content, exactly how chat-based LLMs expect it. This is handy because you don’t need to manually construct message objects — the template handles it for you.
### `MessagesPlaceholder`: Inserting Dynamic Chat History into a Prompt
When you’re working with chat-based models, you often want to include conversation history (or some sequence of messages). `MessagesPlaceholder` acts as a stand-in for a dynamic list of messages you’ll provide at runtime.
Imagine we’re building a career coach bot that remembers previous questions and answers:
```python
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.messages import HumanMessage, AIMessage
chat_prompt = ChatPromptTemplate.from_messages([
("system", "You are a helpful career coach."),
MessagesPlaceholder("conversation"), # Dynamic history insertion
("human", "{current_question}")
])
# Define history using proper message objects
conversation_history = [
HumanMessage(content="How do I prepare for a job interview?"),
AIMessage(content="Start by researching the company and practicing common questions.")
]
formatted_messages = chat_prompt.format_messages(
conversation=conversation_history,
current_question="Should I send a thank-you email afterward?"
)
print(formatted_messages)
```
The output will be a list of message objects like:
```
[
SystemMessage(content="You are a helpful career coach.", role="system"),
HumanMessage(content="How do I prepare for a job interview?", role="user"),
AIMessage(content="Start by researching the company and practicing common questions.", role="assistant"),
HumanMessage(content="Should I send a thank-you email afterward?", role="user")
]
```
This setup allows you to manage dynamic dialogue context without manual overhead. When we used `MessagesPlaceholder("conversation")`, it was replaced with the full history of back-and-forth messages between the user and assistant.
The messages were injected exactly in order, so you didn’t have to manually merge or format them, since LangChain took care of that behind the scenes.
## How Mirascope Makes Prompt Templates Easier to Build
LangChain lets you build prompt templates, but the process can feel a bit clunky. You often have to instantiate a `PromptTemplate` class, pass in template strings, list all your input variables, and manually manage roles if you're working with chat models.
If you’ve ever thought, “Why can’t I use a function for this?”, you’re not alone. That’s why third parties built tools like [`langchain-decorators`](https://pypi.org/project/langchain-decorators/), which layer a decorator-based syntax on top of LangChain. These offer a more pythonic way to write prompt templates, **but they’re still third-party, and come with some limitations**.
Mirascope, on the other hand, takes the decorator approach seriously, and builds prompt templates around decorators from the ground up, allowing you to write clean, composable, and structured prompts as plain functions. But what really sets it apart is not just the decorator syntax. It’s the flexibility you get with constructs like `BaseMessageParam`, the return value of Mirascope’s prompt template decorator.
Unlike `langchain-decorators`, which ultimately flatten your messages into strings, Mirascope treats prompts as structured data. Each message maintains its role (user, system, assistant), supports multi-modal content (text, images, audio, documents), and integrates with downstream LLM workflows.
This approach ensures compatibility across providers and unlocks tool use, [prompt chaining](/blog/prompt-chaining/), and dynamic configuration for [LLM integration](/blog/llm-integration/).
At its simplest, you can add a Mirascope `@prompt_template` decorator to any Python function to turn it into a structured prompt that returns a list of role-tagged messages ready for an LLM:
```python
from mirascope import prompt_template
@prompt_template("Recommend a {genre} movie") # [!code highlight]
def recommend_movie_prompt(genre: str) -> ... # [!code highlight]
print(recommend_movie_prompt("comedy"))
# Output: [BaseMessageParam(role='user', content='Recommend a comedy movie')]
```
Note that the `recommend_movie_prompt` method’s signature defines the prompt’s template variables. `BaseMessageParam` turns those variables into role-aware messages that Mirascope can pass to any provider.
`@prompt_template` works in tandem with our `@llm.call` decorator, which turns Python functions into structured API calls with minimal boilerplate.
hl\_lines \= "3-5"
```python
from mirascope import llm, prompt_template
@llm.call(provider="openai", model="gpt-4o-mini") # [!code highlight]
@prompt_template("Recommend a {genre} movie")
def recommend_movie_prompt(genre: str) -> ...
response = recommend_movie_prompt("comedy")
print(response.content)
#> You should watch The Grand Budapest Hotel, a witty and visually stunning comedy.
```
First, the `prompt_template` decorator wraps the function with a prompt string (“Recommend a `{genre}` movie”). When `genre=”comedy”`is passed, Mirascope transforms the template into a structured message:
```
BaseMessageParam(role='user', content='Recommend a comedy movie')
```
The model-agnostic [`llm.call` decorator](/docs/v1/learn/calls/) sends this structured message to the model and the return value is a `CallResponse` object that includes generated content, a full list of input messages, model parameters, usage metrics, and any tool or modality-specific metadata.
[`CallResponse`](/docs/v1/api/core/base/call_response/) is useful because whether you're calling OpenAI, Anthropic, Google, or another provider, the shape of the response remains the same. That means you can build [LLM tools](/blog/llm-tools/), logging, analytics, or debugging features once and reuse them everywhere.
It also includes fields like `.messages` for the exact prompt, `.usage` for token tracking, and `.model` to confirm which backend handled the call (among others).
## Editor Support for LangChain and Mirascope
**LangChain’s prompt templates don’t offer built-in editor support**. For example, `topic` below isn’t supported since the user input to `invoke` is a dict with string keys:
```py
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
prompt = ChatPromptTemplate.from_template("tell me a fun fact about {topic}") # [!code highlight]
model = ChatOpenAI(model="gpt-4")
output_parser = StrOutputParser()
chain = prompt | model | output_parser
chain.invoke({"topic": "pandas"}) # [!code highlight]
```
So you could enter `topics` (plural) in the invocation dictionary and the editor would give you no warning or error message.
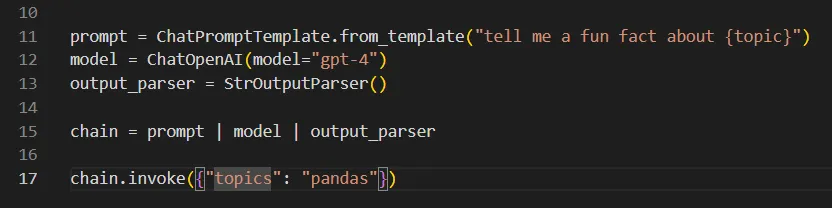
The error would only be shown at runtime:

In contrast, the example with Mirascope below shows how `storyline` is defined as a fixed word and string attribute, and so passing in, say, a plural form of the word would automatically generate an error, thanks to Python:
```python
from mirascope.core import prompt_template
@prompt_template(
"""
SYSTEM: You are a top class manga editor
USER: What do you think of this new storyline I'm working on? {storyline}
"""
)
def editor_prompt(storyline: str): ...
storyline = "Two friends go off on an adventure, and ..."
messages = editor_prompt(storyline) # [!code highlight]
print(messages)
# > [
# BaseMessageParam(role='system', content='You are a top class manga editor'),
# BaseMessageParam(role='user', content='What do you think of this storyline I'm working on? Two friends go off on an adventure, and ...')
# ]
```
In our IDE, trying to pass in a non-string generates an error:
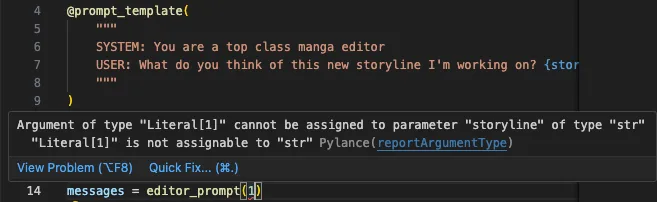
Autocomplete is also provided for the attribute:

The catch here is that in the case of LangChain, if you haven’t defined your own error handling logic, **it might take you a while to figure out from where bugs originate**. Mirascope warns you immediately of such errors.
## Prompt Versioning in Langchain Hub (And How Lilypad Makes It Better)
Anyone working with prompt templates is going to need to version prompts, since changes and tweaks you make will affect the output and arguably need to be tracked so you know what worked, what didn’t, and can roll back or improve without guessing.
LangChain's product for doing this is LangSmith. It offers a Git-style version history for prompts, complete with commits, pulls, and downloads.
However, it suffers from a few weaknesses:
* You’re working with a prompt template but not other influential factors in your versioning, like model settings, logic, or how the prompt is actually called in the code.
* You have to version and download prompts manually.
For example, you create a prompt template and save each change as a new commit by clicking “Save as.” This creates a version history where each commit is assigned a unique hash number (e.g., `3b929440`):
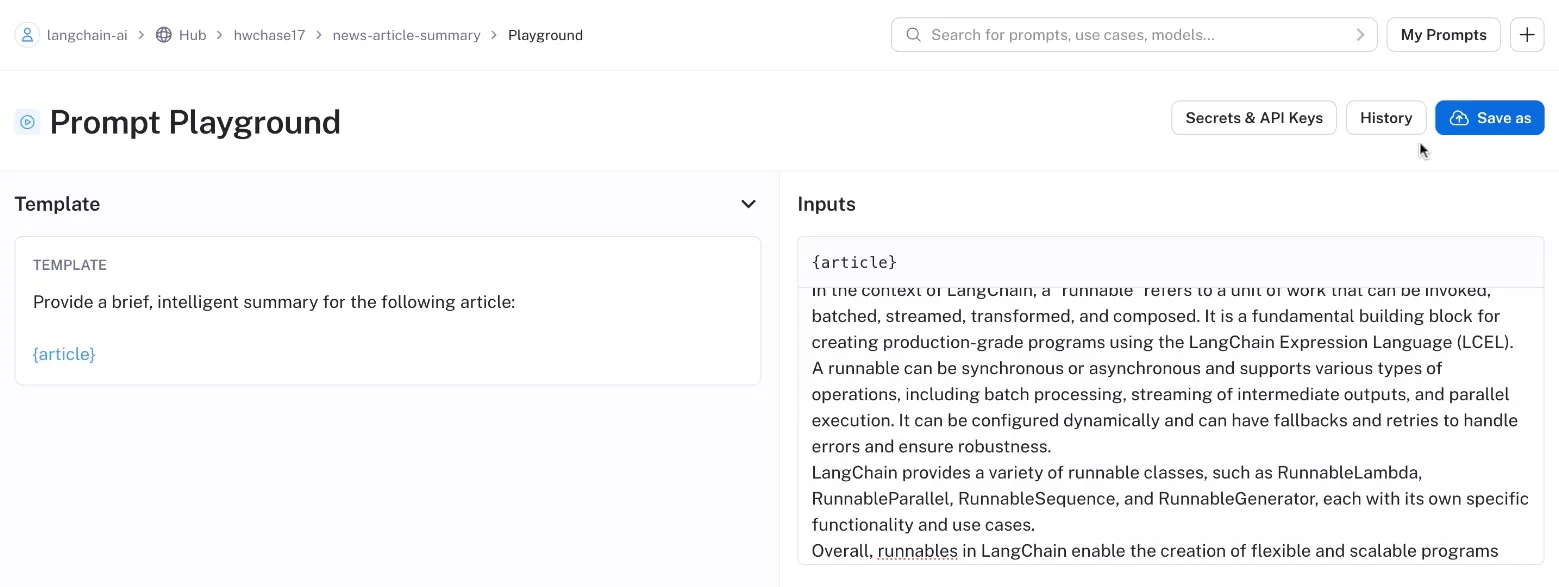
You then download and use the prompt by referencing the specific commit hash in your own code:
```python
from LangChain import hub
obj = hub.pull("langchain-ai/summarization of articles:3b929440")
```
To improve this, we created Lilypad, an [advanced prompt engineering](/blog/advanced-prompt-engineering/) framework that automatically versions not just the prompt but the entire code calling the LLM, including model settings and logic, and handles all versioning behind the scenes, so you never have to do it manually.
### How Lilypad Makes Structuring Calls and Prompts Easier
Lilypad treats the entire context around an LLM call (not just the prompt itself) as a fully defined system, **capturing not just the prompt** but also the code, model, inputs, and parameters, effectively isolating each factor that could affect the model’s behavior.
This structured approach makes it possible to methodically test what impacts the outcome, compare results across variations, and understand what actually improved performance.
We encourage developers to wrap calls inside Python functions and decorate them with `@lilypad.trace` to automatically version and trace each execution:
```python
import lilypad
import os
from openai import OpenAI
lilypad.configure()
client = OpenAI()
@lilypad.trace(versioning="automatic") # [!code highlight]
def answer_question(question: str) -> str:
completion = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": question}],
)
return str(completion.choices[0].message.content)
response = answer_question("What is the deepest point in the Pacific ocean?")
print(response)
```
(Note that setting `versioning=”automatic”` in the trace decorator will automatically track changes.)
Structuring calls in such a way encourages developers to treat LLM logic as first-class software components: versioned, traceable, and ready to be optimized.
Lilypad tracks changes based on the function closure, so any user-defined functions or classes it relies on (that are within scope) are also **automatically** captured as part of the version, with no need to manually save changes.
### One Playground, Full Control: Manage, Test, and Trace in One Place
Such code lines wire your LLM applications into Lilypad’s playground environment, letting you observe, test, and iterate on your functions in a structured, UI-driven way.
Below, we show an example of how versioning works. A function wrapped in `lilypad.trace` is displayed in the playground as V6:
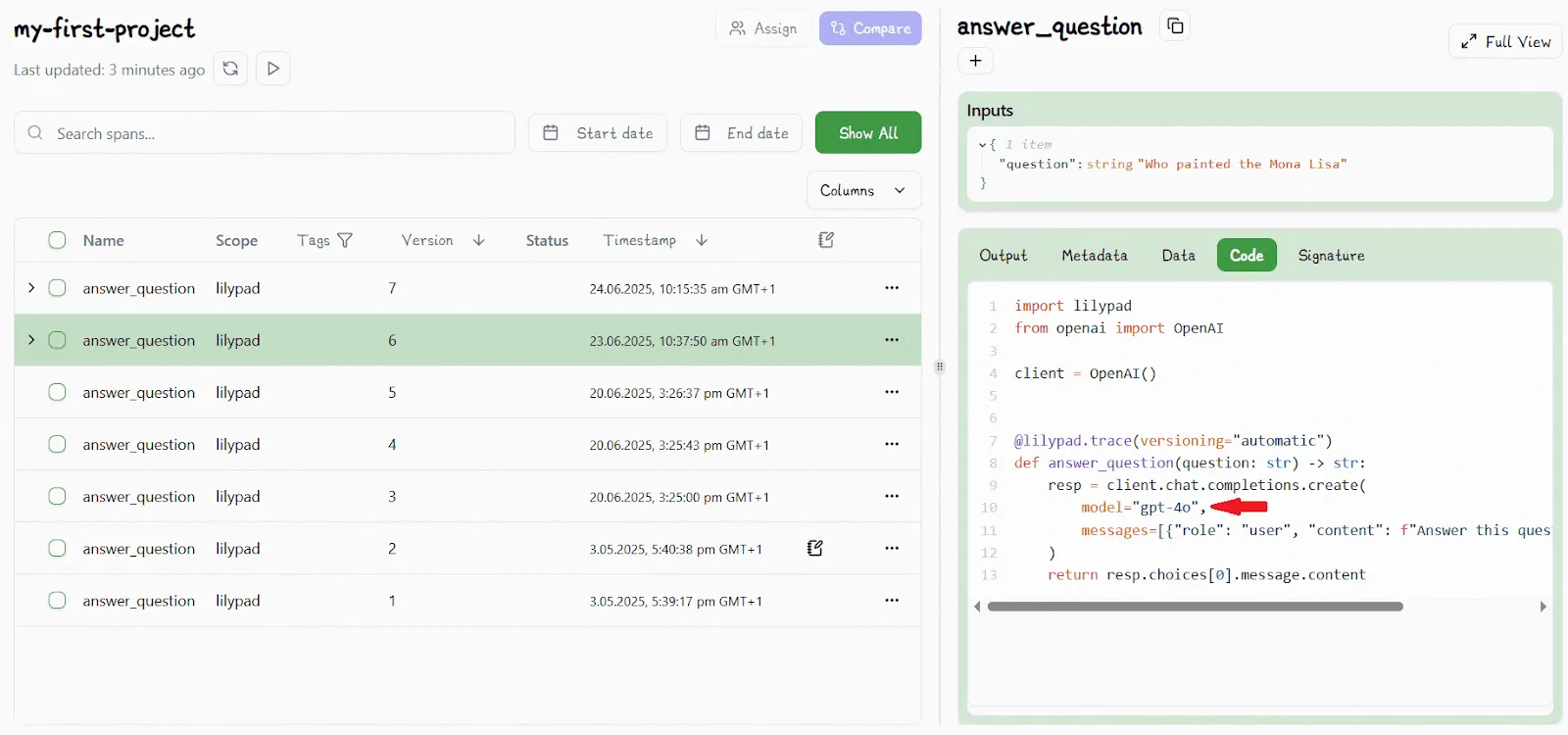
We then edit the function to change the model type in the call to `gpt-4o-mini` and Lilypad automatically increments it to V7:
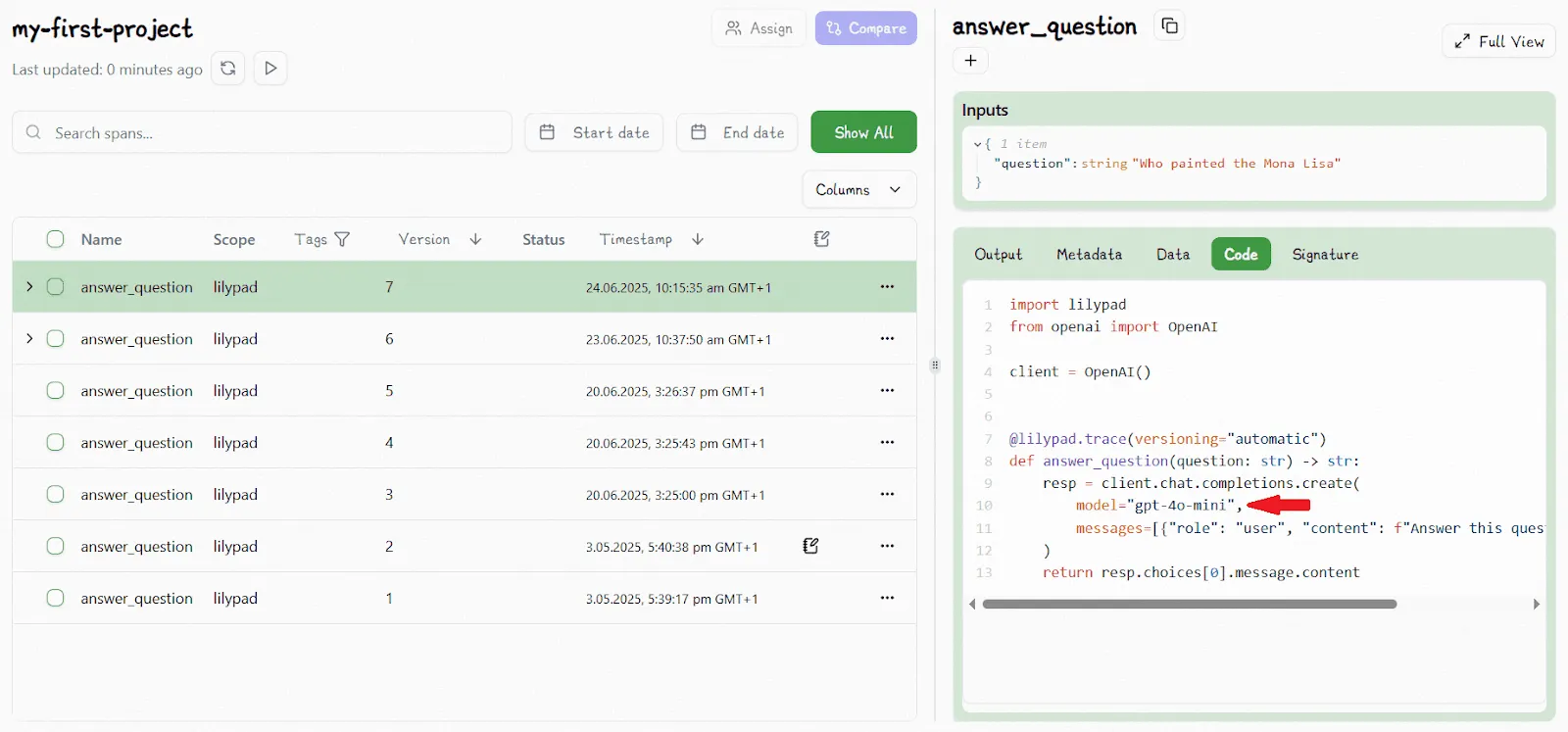
The fact such changes are done automatically is especially useful when running large numbers of prompts and calls.
If the system detects that a change is identical to that in a previous version, the version number isn’t incremented. You can revert to any saved version simply by selecting it in the playground.
This managed prompt environment allows non-technical domain experts to independently work with prompt templates without involvement from developers, meaning they can run prompts and evaluate and annotate outputs of large language models without developers needing to redeploy code.
The playground provides:
* Prompt templates in markdown, and displays any Python function associated with a template
* Call settings, like provider, model, and temperature
* Type-safe prompt arguments and values
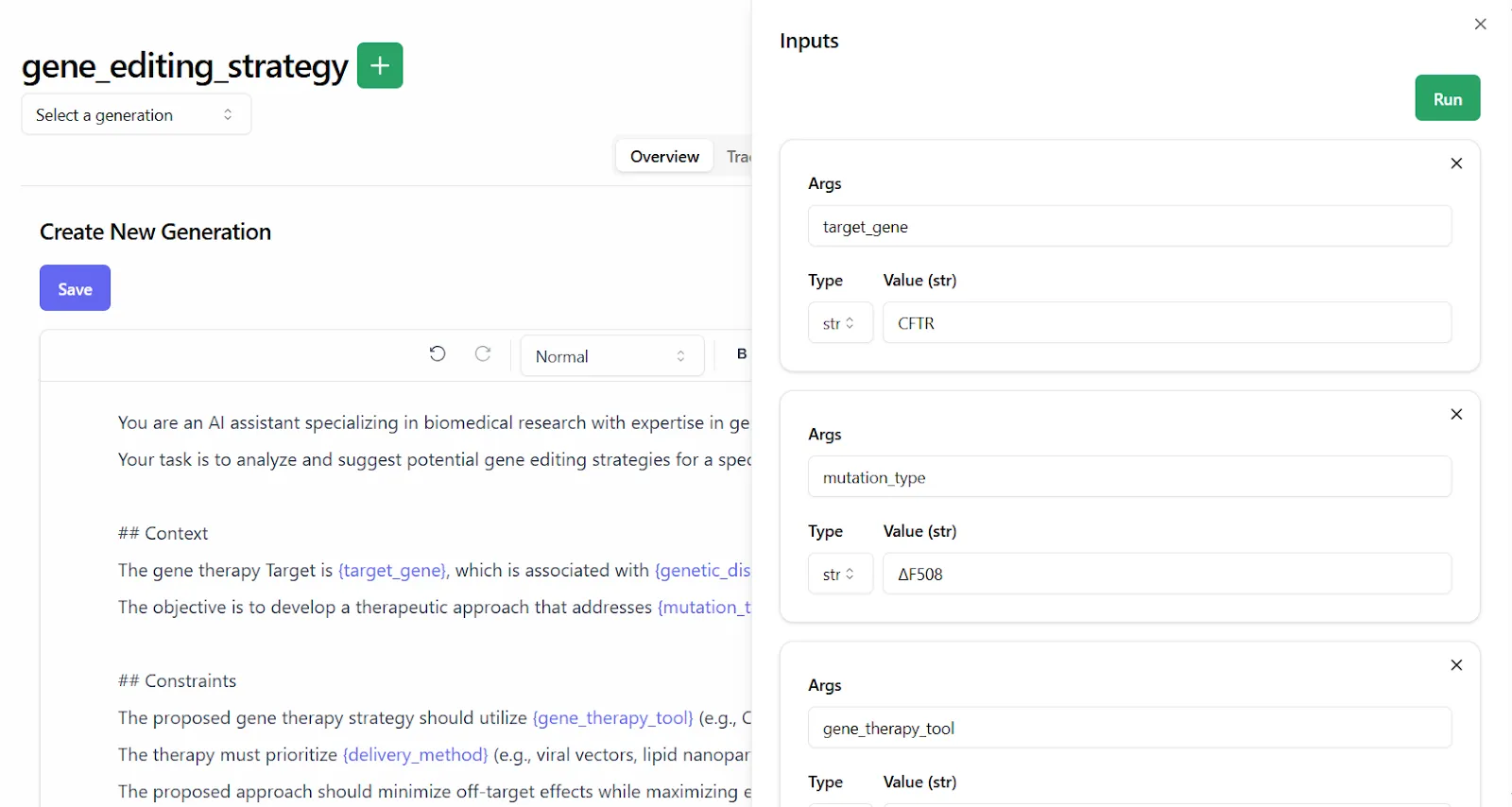
Lilypad also captures outputs and traces using the [OpenTelemetry Gen AI](https://opentelemetry.io/) spec to make observability easier, giving users an exact snapshot of every output:

Domain experts can evaluate outputs using a simple and effective pass/fail labeling system, based on whether the output meets the bar for being "good enough" in context.
We recommend using such [LLM evaluation](/blog/llm-evaluation/) criteria since relying on scoring rubrics or arbitrary rating scales like 1–5 add unnecessary complexity, slow down the evaluation process, and can lead to inconsistent judgments.
By contrast, a binary pass/fail system keeps evaluations focused, fast, and aligned with real-world goals of determining whether an output is acceptable for production use.
So Lilypad encourages users to assess outputs through a practical lens: would this be an acceptable output? If yes, it’s a pass. If not, it’s a fail, and you can (optionally) explain why:
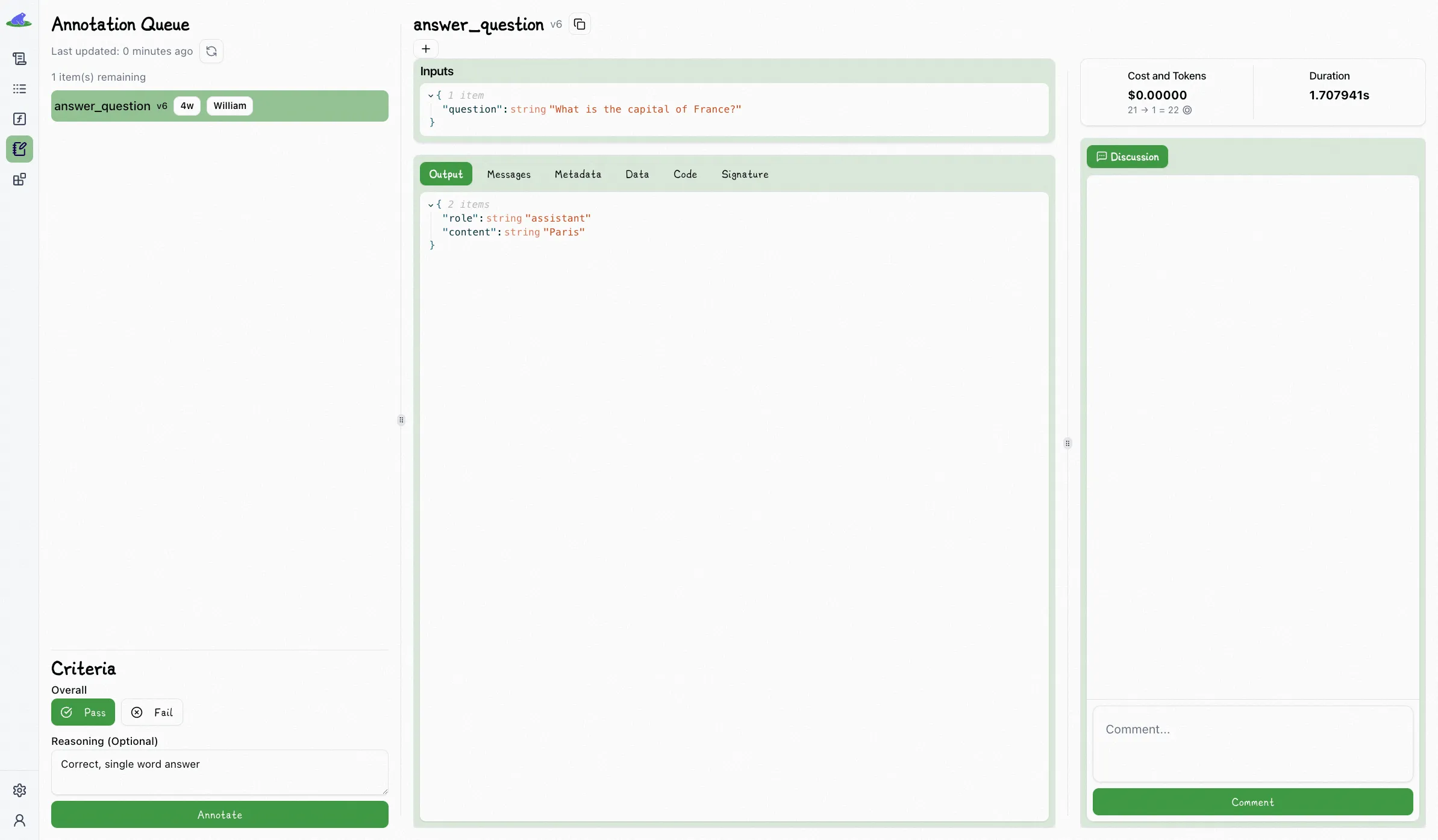
Having a domain expert who really knows the task go through the results and mark what's good and what's not gives you solid training examples for automating evaluations.
Automating evals instead of making every judgment from scratch allows your team to focus on spot-checking and confirming edge cases.
Even if the handoff to [LLM-as-a-judge](/blog/llm-as-judge/) is reliable though, we recommend that you still consistently verify results to catch breakdowns and stay confident in what you’re shipping. This process ensures the judge is continuously aligned with the human evaluator.
## Start Structuring Your Prompts Smarter
Lilypad brings engineering discipline to prompt development, giving you automatic versioning, easy [prompt evaluation](/blog/prompt-evaluation/), and traceable outputs for every LLM call. Mirascope’s user-friendly library provides multi-modal messaging and provider-agnostic calls, offering a cleaner alternative to LangChain’s prompt classes.
To get started quickly and securely, [you can sign up for Lilypad](https://lilypad.mirascope.com/) with your GitHub credentials. Lilypad also supports [Mirascope](https://github.com/mirascope/mirascope/), our lightweight toolkit for building AI agents.
A Guide to Prompt Templates in LangChain
2025-06-30 · 9 min read · By William Bakst