Most people treat prompting like a conversation. They type something in, hope the AI gets it, and move on. But prompting isn’t just dialog: it’s design that shapes the way the generative AI model responds. The words you use, the structure you follow, the context you provide, these might not lock in an exact output, but they point the model in the right direction.
And once you start thinking that way, everything changes. Prompting stops being a guessing game and becomes a process you can test, tune, and trust. You’re not aiming for one lucky output, you’re aiming for consistency, even across edge cases, over time, and at scale.
In this article, we’ll share 11 prompt engineering best practices that modern developers can apply right away. We’ll begin with the essentials: seven practical techniques for writing clearer, more effective prompts that deliver better results with less trial and error.
Then we’ll shift from prompt writing to *actual* prompt engineering. Because while most advice on “prompt engineering” ends at tips for phrasing, **real engineering means treating AI behavior like a system**, something you can version, trace, and optimize like any other part of your stack.
That’s where our platform [Lilypad](/docs/lilypad) comes in. It’s a prompt engineering framework built for developers, designed to help them capture everything that influences an LLM’s output, from the prompt to the code that wraps it, and trace snippets back to its source. With Lilypad, teams can iterate faster, evaluate reliably, and ship AI features that actually hold up under real-world use cases.
## 7 Fundamental Prompt Engineering Best Practices
### 1. Specify Exactly What You Want
Large language models are great at picking up on hints, but that’s not always a good thing. In zero-shot prompts, where no guidance is given beyond the task description, vague instructions are especially risky.
If your prompt is vague, the model will still try to guess what you meant, often filling in the blanks with assumptions that don’t match your intent.
That’s why clarity matters. You need to be direct about what you're asking, how it should be structured, and what to avoid. Don’t just say “make it better” or “keep it simple”: define what “better” means. Does it mean shorter sentences or a specific tone?
Assume nothing. If your output needs to follow a certain format, stay within a word count, or match a particular style, say so. The more specific your prompt, the more likely the model is to give you what you actually want.
Don’t do this:
```
Summarize this article.
```
Instead, do this:
```
Summarize the following article in three concise bullet points that highlight its key arguments. Avoid including any opinion or unnecessary detail.
```
### 2. Show What Good Looks Like
LLMs are fast learners, at least when it comes to patterns. That means you don’t just have to tell the model what you want. You can show it.
By providing examples of the kind of output you expect (for a certain input), you’re helping the model pick up on the task, the tone, the format, everything. This approach is called few-shot prompting, and it’s especially useful when your output needs to follow a certain structure or carry a bit of nuance.
Think of examples as anchors. The model uses them to get its bearings, then generalizes from there. So pick examples that match the tone, format, and level of detail you want in return. Garbage in, garbage out, but good examples in? Much better output back.
Don’t do this:
```
Generate a product description for this item: a stainless steel water bottle.
```
Instead, do this:
```
Here’s how I want the product description to be written:
Example:
Product: Wireless Ergonomic Mouse
Description: A sleek, Bluetooth-enabled mouse with a contoured design for all-day comfort and precision.
Now generate one for:
Product: Stainless Steel Water Bottle
```
### 3. Use Clear, Action-Oriented Instructions
Start your AI prompts with strong action verbs. Words like Generate, Summarize, or Translate give the model a clear directive, and help cut through the noise.
Avoid soft openings like “Can you…” or “I need…”. These weaken the prompt’s intent and make it feel more like a suggestion than a command. Instead, treat your prompt like an instruction to a function: be direct, specific, and purposeful.
This kind of action-oriented language doesn’t just sound better, it actually works better. Many of the model’s training examples came from commands and task-based inputs, so prompts written that way tend to map more cleanly to what the model already understands.
Don’t do this:
```
I need help understanding this paragraph.
```
Instead, do this:
```
Summarize this paragraph in natural language to explain it to a high school student.
```
### 4. Guide the Model to Think Step-by-Step
When your prompt involves a complex or multi-part task, don’t ask the model to jump straight to the answer. Instead, use [prompt chaining](/blog/prompt-chaining/) or step by step guidance to help it think through the problem in stages.
This technique is known as Chain-of-Thought prompting. You’re asking the model to reason out loud before giving its final answer. It’s a simple tweak that can make a big difference, reducing hallucinated answers and encouraging deeper, more accurate responses.
It’s especially useful for complex tasks like logic-heavy prompts, coding challenges, analytical work, and decision-making tasks. Even if you just want a final answer, guiding the process often leads to higher-quality (and more explainable) results.
Don’t do this:
```
What’s the best marketing strategy for our new product?
```
Instead, do this:
```
Let's think through this step-by-step:
1. List the top 3 features or benefits of our new productivity app.
2. Identify the primary target audience based on those features.
3. Describe one or two marketing channels that would best reach that audience.
4. Based on all of the above, recommend a simple marketing strategy tailored to this audience.
```
### 5. Specify the Desired Output Format
LLMs don’t just need to know what to answer: they need to know how to answer. When you define the format you expect, the results get a whole lot better.
Want a list? Say so. Need bullet points, a table, JSON, or a block of code? Spell it out. Clear formatting instructions help the model stay focused, avoid hallucinations, and produce outputs that are easier to read, and easier to use.
This matters even more when your output is going into a downstream tool or system. Consistency counts. You can even prime the model by showing the format before the content, setting the structure before it generates the response.
Don’t do this:
```
List benefits of remote work.
```
Instead, do this:
```
List 3 key benefits of remote work in bullet points, with each point no longer than one sentence.
```
### 6. Stay with Simple, Accessible Language
LLMs work best when your prompts are clear, direct, and easy to understand, just like any good API. If your wording is vague or overloaded with jargon, the model is more likely to misfire.
Skip the slang, idioms, and fuzzy phrases unless they’re truly necessary, and if they are, define them clearly. Words like better, intuitive, or robust might mean something to you, but to the model, they’re open to interpretation.
Write your prompt like you’re explaining specific tasks to someone smart but unfamiliar with your field. The simpler the language, the easier it is for the model to build a clear mental map, and that leads to more consistent, reliable results.
Don’t do this:
```
Write a robust, intuitive onboarding flow with all the bells and whistles.
```
Instead, do this:
```
Write a clear, step-by-step onboarding flow that explains the product’s core features in under 5 screens.
```
### 7. Assign the Model a Role When Context Matters
LLMs tend to respond more accurately, and in the right tone, when you tell them who they’re supposed to be. Giving the model a role helps it adopt the right voice, vocabulary, and level of formality for the task.
Need a professional explanation for a client? Ask the model to act as a consultant. Writing a friendly support reply? Frame it as coming from a helpful rep. Roles help guide tone, audience awareness, and framing, all of which make the output more relevant and useful.
Some argue that assigning a role doesn’t truly change the model, it just forces you to clarify what you actually want, which might be a valid reason it works so well.
Don’t do this:
```
Explain how to use Git to someone new.
```
Instead, do this:
```
You are a programming instructor teaching a beginner. Explain how to use Git for version control in simple, friendly language.
```
## 4 Best Practices to Make Your Prompts Repeatably Good
At small scale, writing better prompts can get you far. But once you’re shipping [LLM applications](/blog/llm-applications/) to real users, with unpredictable inputs and evolving models, prompt quality alone won’t cut it.
LLMs are inherently non-deterministic since the same prompt can yield different outputs. So the question becomes not “how do I write the perfect prompt?” but “how do I engineer this system, including [LLM integration](/blog/llm-integration/), to deliver reliable results?”
That makes prompt engineering a process of continuous improvement, what machine learning developers would call an optimization problem.
Solving it means tracking *everything* that changes, measuring what works, and testing new ideas against old ones in your artificial intelligence systems. It’s no longer just about the prompt, but the entire system: inputs, outputs, and the code connecting them. In other words, effective [LLM orchestration](/blog/llm-orchestration/).
The four best practices below approach prompt engineering as a system-level discipline that you version, trace, and improve over time.
**We built Lilypad with this in mind**. While other platforms focus on narrow slices, like playgrounds or prompt versioning, they often fall short when it comes to implementing prompt engineering techniques that make LLM behavior repeatable at scale.
For example, such tools version the prompt but ignore things like parameters or helper logic. Others silo tracing and evaluation, forcing constant context-switching just to label or compare outputs.
Lilypad brings it all together. In the best practices for prompt engineering that follow, we’ll show how it helps teams apply real engineering principles to prompt development and make outputs reliably good.
### 8. Version Everything that Influences the Output
If it affects the LLM’s behavior, it should be versioned. Not just the prompt, but the model, temperature, helper functions, preprocessing steps, and surrounding logic.
Without versioning, you can’t reproduce outputs or track what changed. That’s why prompt engineering should follow the same rules as production code: every change to logic or inputs should create a new version.
Versioning gives you visibility. It lets you roll back, track progress, and understand exactly what changed when results shift.
Lilypad makes this easy by versioning the full context; not just the prompt, but the code that shapes the call. In fact, we recommend wrapping every LLM call in a Python function to capture the model, parameters, prompt, and any pre/post-processing in one place, even when working with multi-step patterns like [LLM chaining](/blog/llm-chaining/).
Add the `@lilypad.trace` decorator and set `versioning=automatic` to have Lilypad version every change made within the function closure.
```python
import lilypad
import os
from openai import OpenAI
lilypad.configure(auto_llm=True) # [!code highlight]
client = OpenAI()
@lilypad.trace(versioning="automatic") # [!code highlight]
def answer_question(question: str) -> str:
completion = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": question}],
)
return str(completion.choices[0].message.content)
response = answer_question("What makes popcorn pop?")
print(response)
```
This shifts your workflow from ad hoc prompt tweaking to a structured, iterative process. The function now becomes a unit of optimization, something you can version, evaluate, and refine over time, much like a machine learning model.
You’re no longer asking, “Did this prompt change help?” You’re comparing, “Did version 4 outperform version 3 on our eval set?” Each time that function runs, whether in dev, staging, or production, Lilypad captures the full generation: it can break down the inputs, model responses, parameters, and the exact version of the code that produced it. That data flows straight into the Lilypad playground.
The playground is a collaborative prompt engineering environment where you evaluate and compare results. You can:
* View outputs across different versions
* Inspect inputs and parameters for every call
* Swap between model or prompt versions to see how behavior changes
* Annotate outputs with pass/fail labels or notes
* Replay generations to test reproducibility or debug edge cases
Instead of guessing what changed (or why) you get a full trace, backed by version history and real inputs.
For example, we see below that V6 of our code calls `gpt-4o`:
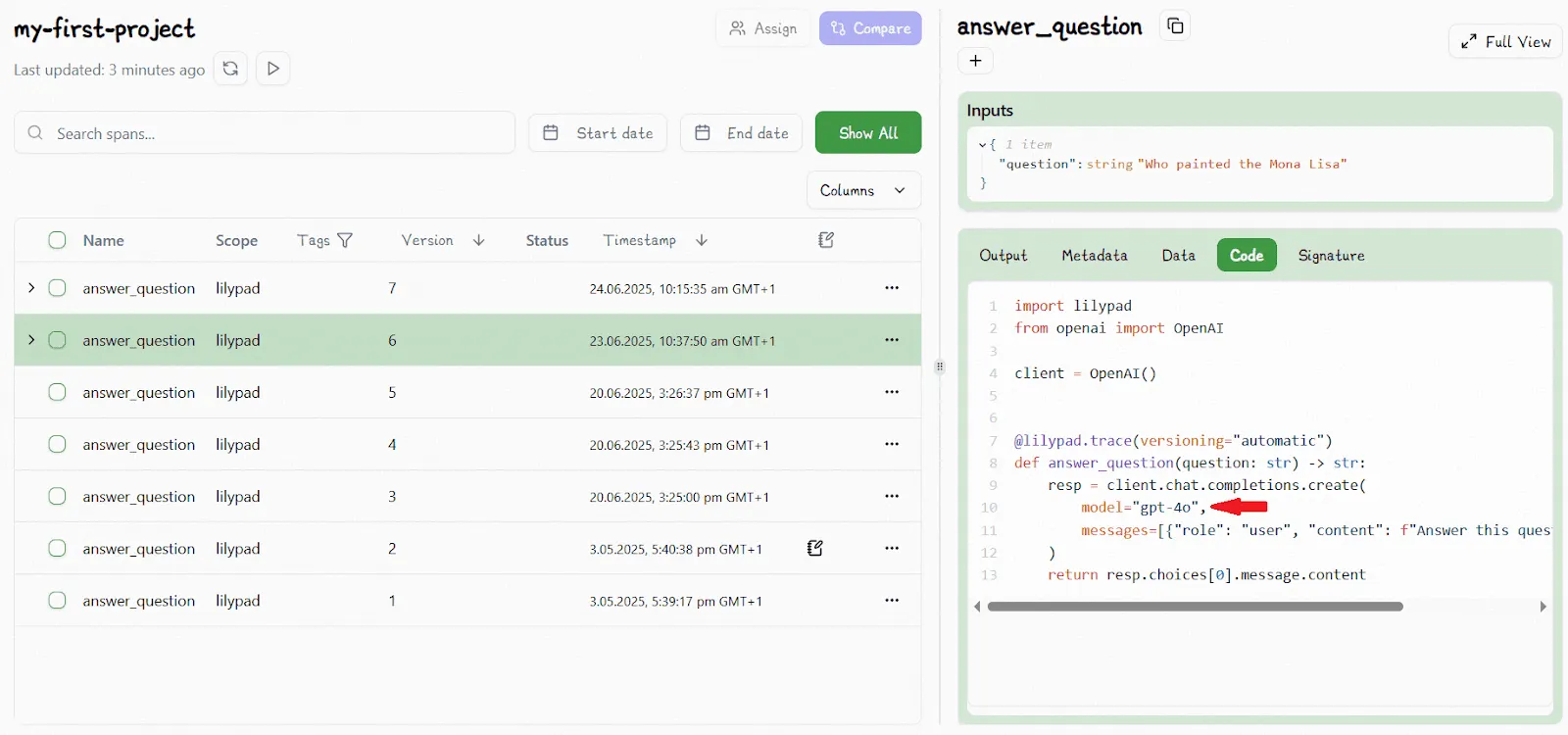
Changing the model type automatically increments the version number:
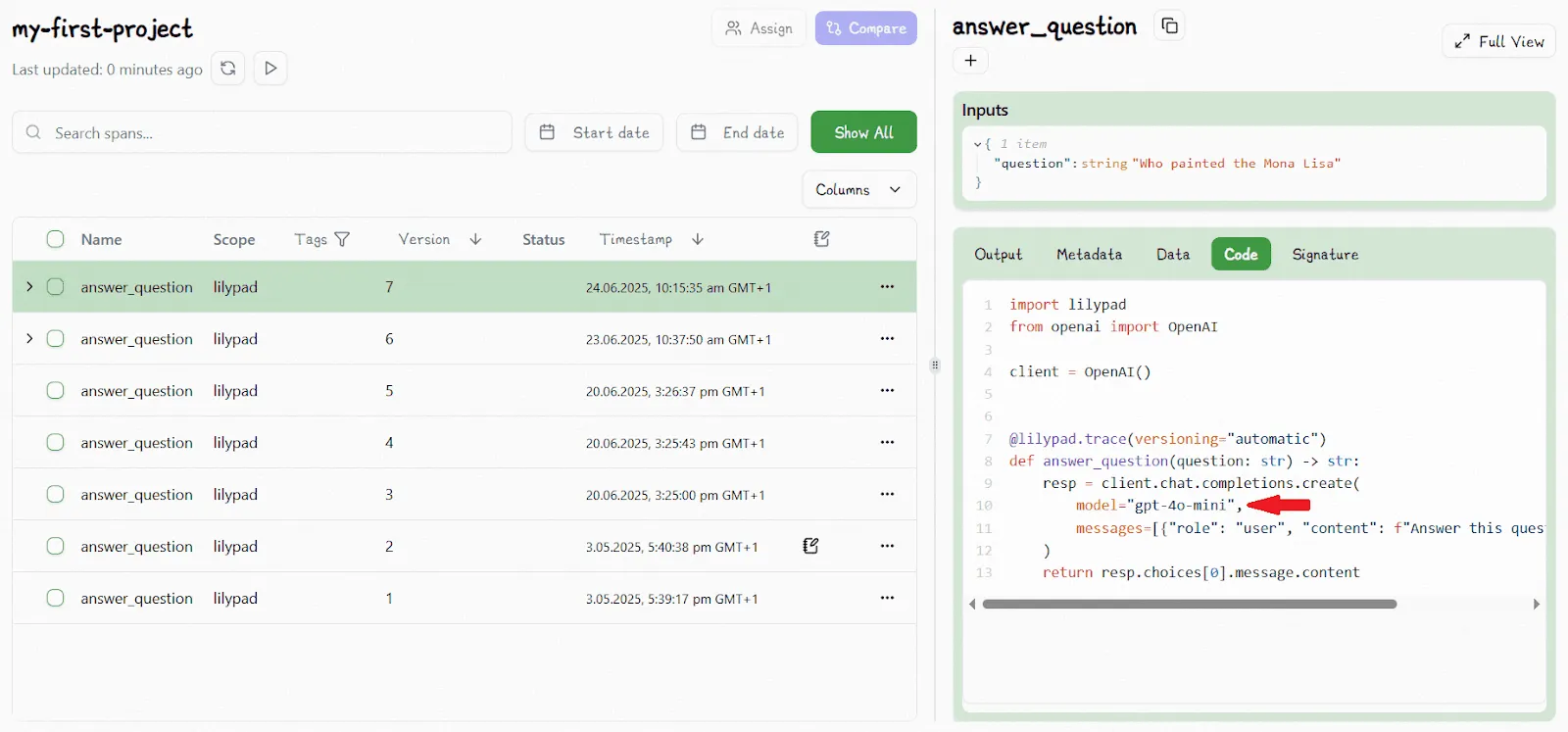
### 9. Trace Every Output You Generate
Tracing is how you observe what the model actually did, given a specific input, set of parameters, and version of your code.
A good trace captures everything that matters: inputs, outputs, model settings, token usage, latency, cost, and more. When something breaks or performance drops, traces let you debug the issue instead of guessing. Observability isn’t optional. It’s foundational to building reliable LLM\-powered apps, especially in production.
That’s why we recommend to trace not just raw API calls, but also the structured execution of your LLM\-powered functions. You want to know not only *what* happened, but where it happened, and why.
That’s where Lilypad’s tracing system comes in. Just call `lilypad.configure()` to enable automatic tracing. This captures raw LLM API calls and logs critical metadata like inputs, outputs, token usage, and costs, giving you an API\-level footprint of your versioned calls.
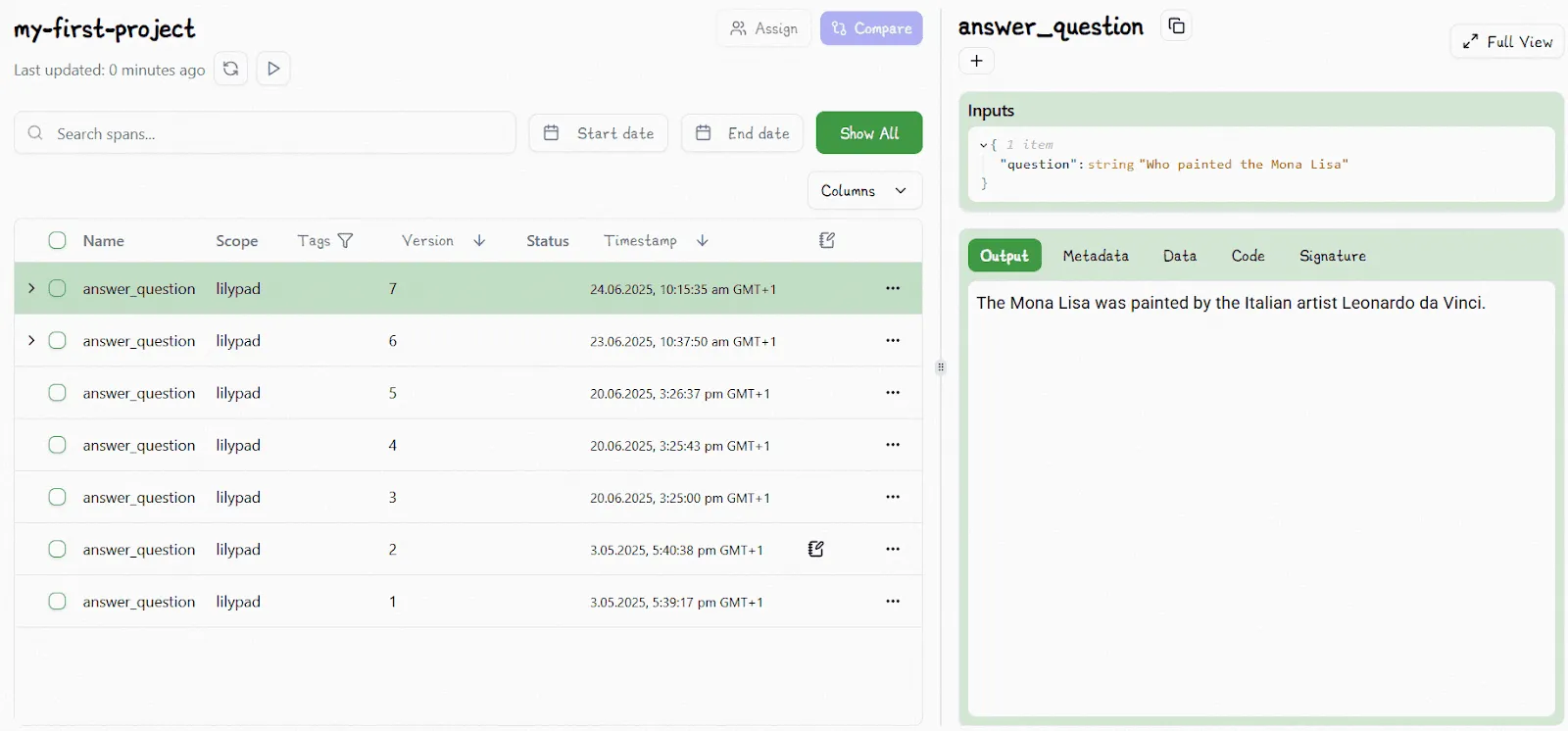
But to make those traces truly actionable, the `@lilypad.trace` decorator promotes each trace from a loose log to a structured unit of execution, linking it directly to the function that made the call, like `answer_question()` in our earlier example. That lets you filter, group, and analyze traces by logical units, not just endpoints or paths.
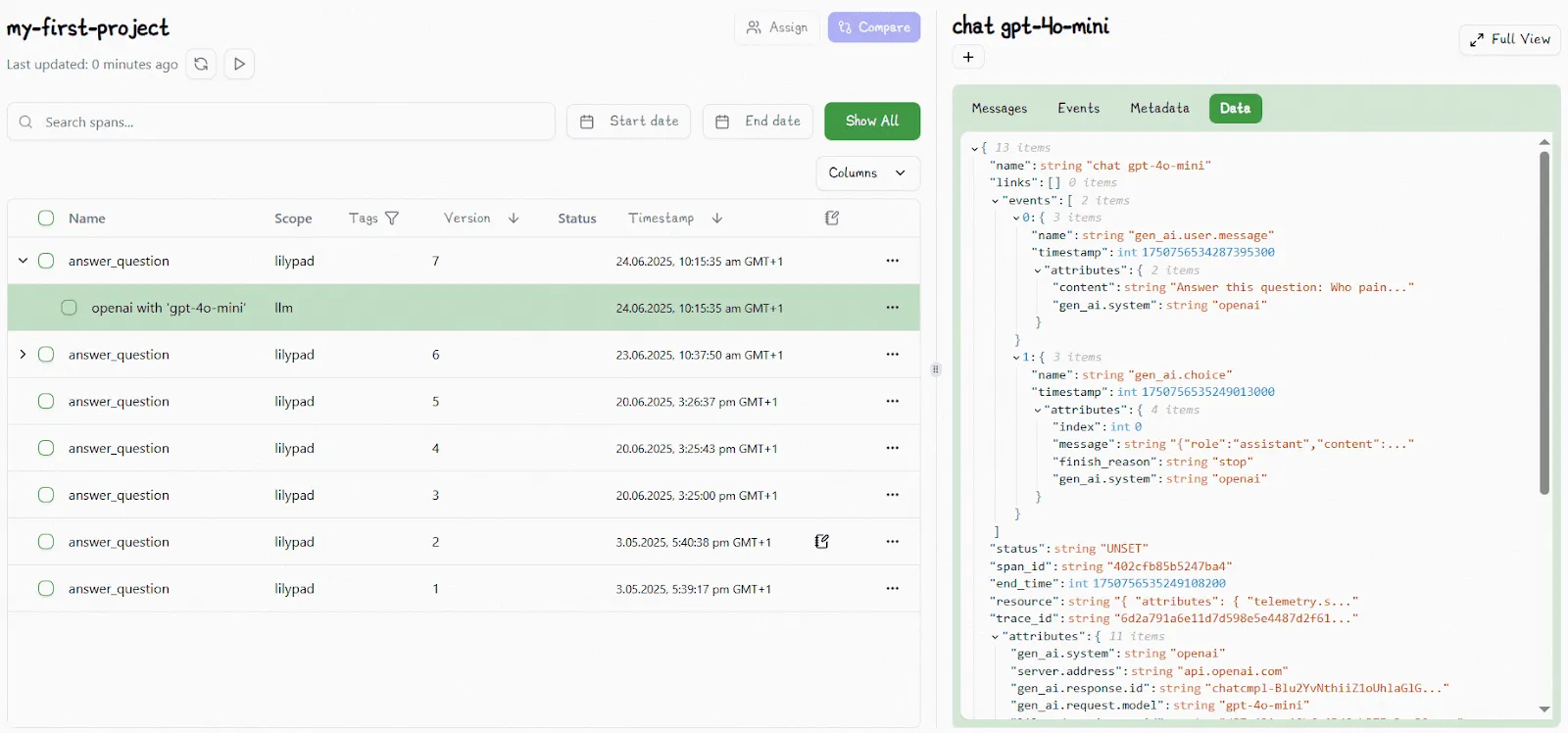
### 10. Offer Safe and Controlled Prompt Collaboration
Prompt tuning shouldn't be limited to engineers. Product managers, writers, and domain experts often bring the kind of insight that makes or breaks how you write prompts, especially when tone, clarity, or context really matter.
That means you need a way to let non-developers contribute without touching production code.
With Lilypad, you can do exactly that. It supports managed prompts, which are versioned prompt templates that live in the playground. This lets contributors edit, test, and iterate on prompts directly in the browser, while developers reference those prompts safely in code, without ever needing to redeploy the app just to apply a wording tweak.
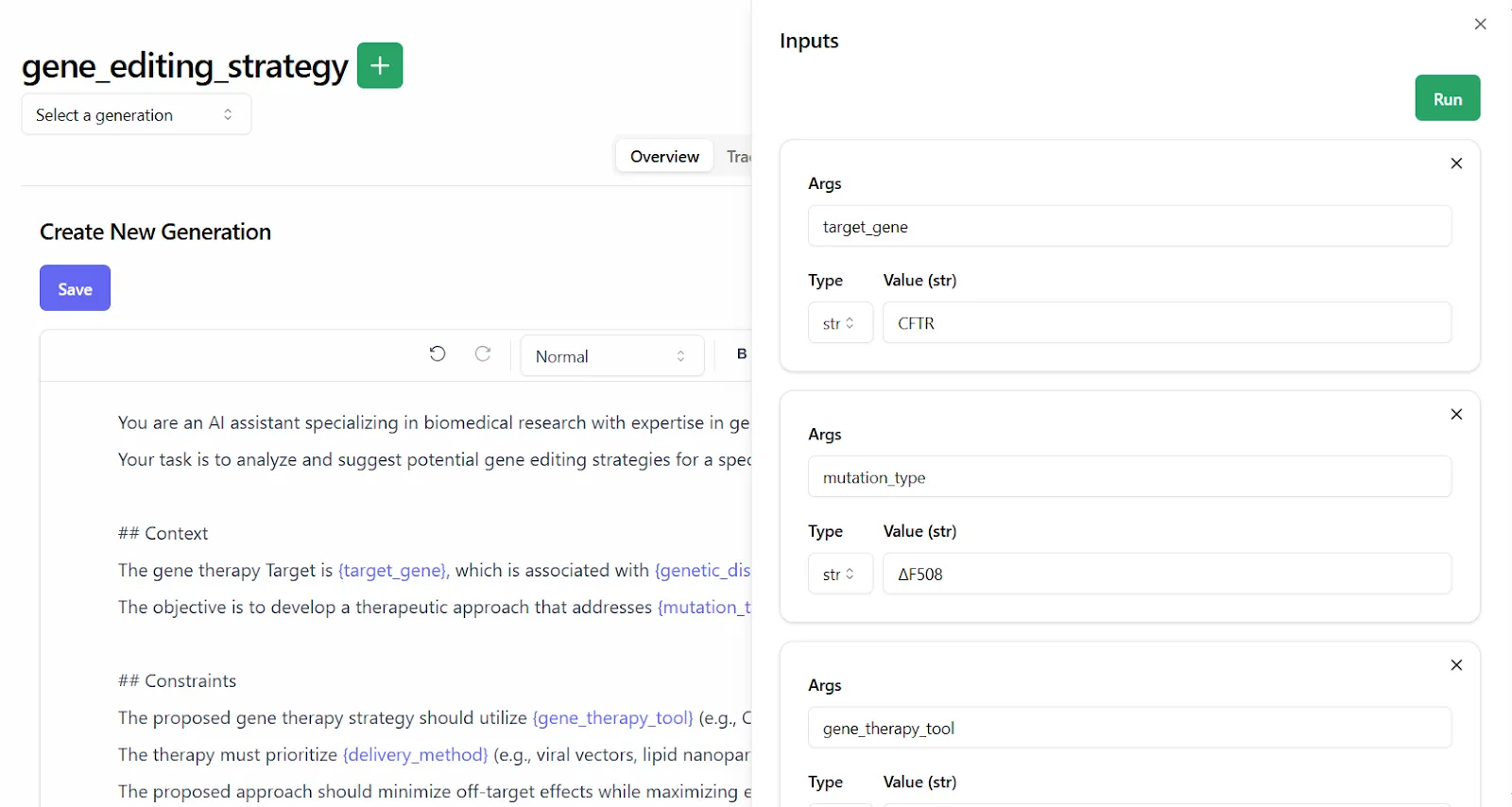
This creates a clean separation of concerns: developers handle infrastructure and application logic, while subject matter experts own the prompt wording. This division is especially valuable when collaborating on more advanced use cases, such as [LLM agents](/blog/llm-agents/), where prompt components and control logic need to evolve independently.
Each team can move quickly without blocking or breaking the other, improving the user experience. And because the playground features prompts that are markdown-enabled and fully versioned, collaborators can experiment freely, revert changes, and keep improving without risk.
But make no mistake: an [LLM prompt](/blog/llm-prompt/) isn’t a floating artifact detached from your codebase. Under the hood, Lilypad treats them just like any other function. The playground generates type-safe code that matches the prompt version you’re referencing in production.
If Lilypad ever goes offline, your code keeps running as-is, with no hidden dependencies, no broken links.
This contrasts with many other systems, which treat prompts as separate from code entirely. That kind of separation might seem flexible, but it makes your system brittle. When the logic that drives model behavior lives outside your source of truth, it’s harder to test, debug, or trust what’s actually going into production.
### 11. Make Evals a First-Class Citizen
Without evaluation, you’re running without feedback. You can’t know whether a prompt change improved performance, introduced regressions, or simply altered behavior in unpredictable ways.
[LLM evaluation](/blog/llm-evaluation/) shouldn’t be an afterthought, but should be a core part of your development workflow. A practical place to start is with binary labels: pass/fail, accompanied by a brief explanation. This approach is faster to apply, easier to interpret, and more consistent than numeric scoring systems.
By contrast, ratings like 1–5 often suffer from ambiguity. What distinguishes a “4” from a “5”? Without clear criteria, such scores quickly become subjective and inconsistent, even across reviews from the same person.
Pass/fail evaluations avoid that ambiguity and better reflect real-world needs. They align with the core question most teams care about: is this output good enough to deploy?
This structure also lends itself to automation. Once you’ve built a solid evaluation dataset, some [LLM tools](/blog/llm-tools/) allow you to prompt an LLM to act as a judge, replicating the behavior of human evaluators. That said, [LLM-as-a-judge](/blog/llm-as-judge/) outputs should still be verified by humans, especially when dealing with edge cases where outputs may be difficult to assess.
Lilypad makes evaluation easy to adopt. Non-technical contributors can annotate outputs from AI tools directly in the playground UI: selecting pass or fail and providing reasoning with just a few clicks.
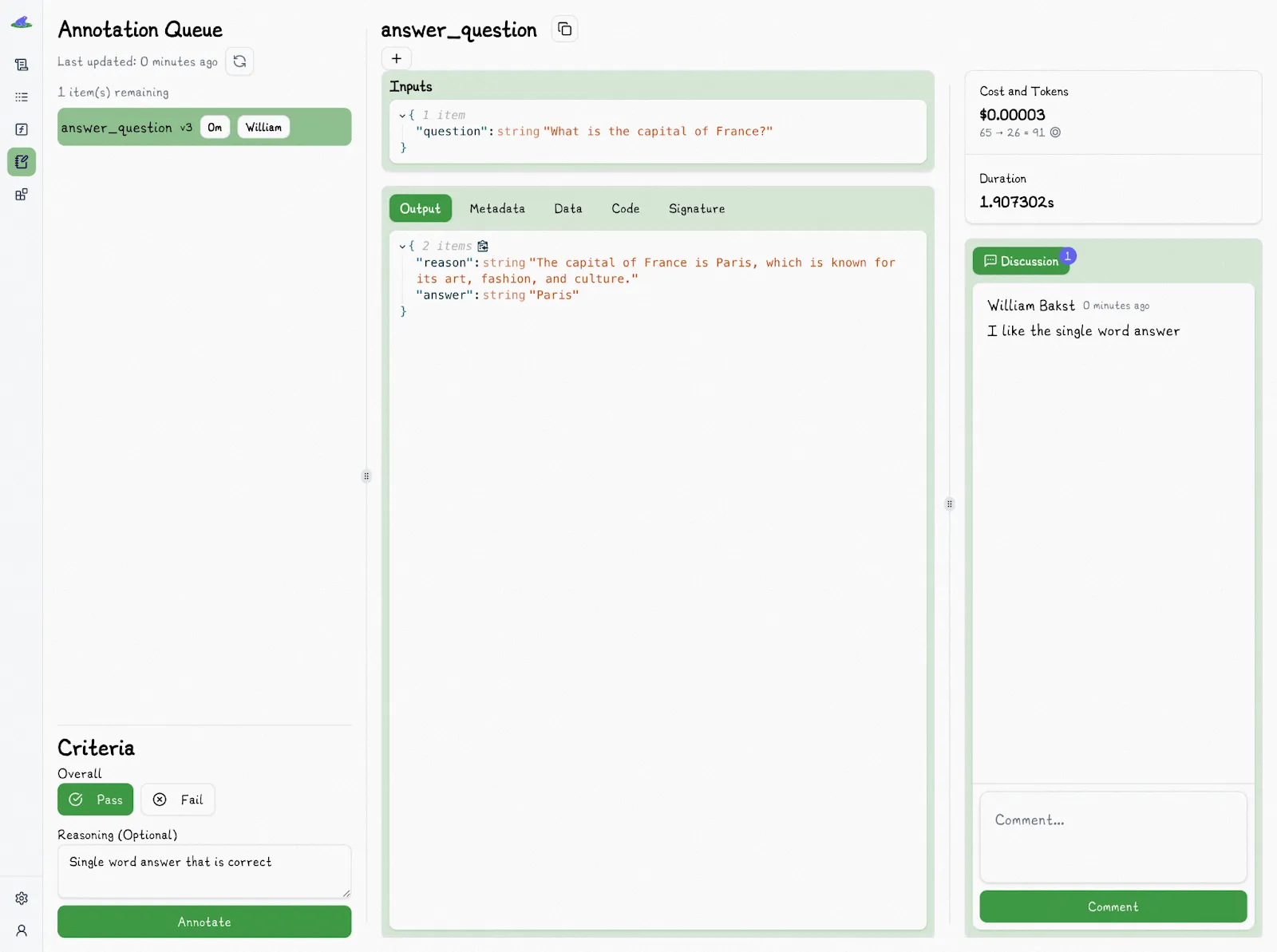
Each evaluation is tied to a specific version of the function that generated the model outputs. That means when quality shifts, whether for better or worse, you can immediately trace back to what changed: the prompt, model, code, parameters, or any combination of the above.
## Go Beyond Prompt Writing, Start Prompt Engineering
Build with the same rigor you apply to the rest of your stack: Lilypad brings versioning, observability, and [prompt evaluation](/blog/prompt-evaluation/) to every call made to AI models to help ensure desired outcomes.
[To get started with Lilypad](https://lilypad.mirascope.com/), you can use your GitHub credentials to sign up and begin tracing and versioning your LLM functions with just a few lines of code.
11 Prompt Engineering Best Practices Every Modern Dev Needs
2025-07-01 · 13 min read · By William Bakst