LangChain might’ve been one of the first tools on the scene for building with LLMs for the first time (and rode an early wave of hype), but for many developers, it’s become more of a headache than a help.
Here’s why:
* You have to learn a bunch of custom classes and abstractions, even for things that could be done with plain Python or JavaScript. That means more complexity, less clarity, and harder debugging.
* Its design doesn’t generally follow software developer best practices. Users point out that code gets messy fast, things aren’t modular, and it’s tough to scale or maintain as your project grows.
Because of this, a lot of devs see LangChain as fine for prototyping, **but not something you'd want to take to production**.
To be fair, it’s not all bad. LangChain helped popularize LLM app development and has tons of third-party integrations. Its retrieval augmented generation (RAG) features are solid for working with large datasets, and its closed-source observability tool, LangSmith, helps track what your app is doing.
But LangSmith has its own issues too. For example, it doesn’t:
* Automatically version both your prompt and the code around it, which makes reproducibility harder.
* Evaluate multiple prompts together as a unit, so devs have to manually track and assess the behavior of interconnected prompts.
In this article, we’ll walk through the biggest pain points in LangChain, and show how [Mirascope](https://github.com/mirascope/mirascope), our Python LLM toolkit, fixes them with a cleaner, more developer-friendly approach.
We’ll also show how [Lilypad](/docs/lilypad), our open source prompt engineering framework, adds structure and traceability when working with unpredictable LLM outputs.
Let’s dive in.
### LangChain: One Size Fits All
LangChain tries to be *everything* at once: a full ecosystem that wants you to use its way of doing things, even when it adds extra layers you don’t really need. Instead of giving you more control, it wraps simple functions in fancy abstractions and nudges you into playing by its rules.
Take prompt templates. LangChain gives you multiple, dedicated classes like `ChatPromptTemplate`, not because they’re essential, but to nudge you into its system.
The result? A steeper learning curve, more complexity, and a growing list of dependencies (some of which, like Pydantic V2, took months to be fully supported). That makes it harder to maintain, scale, or adapt your code, something developers often struggle with across overly complex [LLM frameworks](/blog/llm-frameworks/).
That said, LangChain can be a solid learning tool for people exploring how LLM apps are built. But when it comes to real production use, that’s where things start to break down.
**Mirascope takes a different approach**. We built it with modular, native Python blocks you can plug in when you need them: no extra fluff, no unnecessary wrappers. Just clean, flexible code that grows with your [LLM applications](/blog/llm-applications/).
First, let’s look at an example using LangChain for a text summarization example:
```python
from langchain.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI
def summarize(content: str):
model = ChatOpenAI()
template = """
Please provide a summary for the following text:
{content}
"""
prompt = PromptTemplate.from_template(template)
retrieval_chain = ( # [!code highlight]
{"content": RunnablePassthrough()} | prompt | model | StrOutputParser() # [!code highlight]
) # [!code highlight]
return retrieval_chain.invoke(content)
content = """Climate change is one of the most pressing global challenges of our time. Rising temperatures, melting ice caps, and extreme weather events are becoming increasingly common. Scientists agree that human activities, particularly the burning of fossil fuels, are a major contributor to these changes. Addressing climate change requires coordinated international efforts, innovative policy solutions, and a shift toward sustainable energy sources."""
print(summarize(content))
```
Here, we see several concepts:
* First, you pass in [`PromptTemplate`](https://python.langchain.com/v0.1/docs/modules/model_io/prompts/quick_start/), `StrOutputParser`, [`RunnablePassthrough`](https://python.langchain.com/v0.1/docs/expression_language/primitives/passthrough/), and `ChatOpenAI()`. That’s three extra abstractions to learn — or four if you’re unfamiliar with OpenAI — just to set up a basic text summarization pipeline.
* The `retrieval_chain` construction isn’t immediately intuitive, and you may have to read LangChain’s documentation to understand what’s going on.
* It’s unclear how to invoke `RunnablePassthrough`, if you have multiple parameters, or whether additional instances of runnables would need to be defined. Again, something you’d likely have to check their docs for.
* It’s also unclear whether `RunnablePassthrough` only accepts a string, and their lack of editor docs provide zero type hints on what to do.
In contrast, here’s how we’d implement it in Mirascope:
```python
from mirascope.core import openai, prompt_template
@llm.call(model="gpt-4o")
@prompt_template(
"""
Please provide a summary for the following text:
{content}
"""
)
def summarize(content: str): ...
content = """Climate change is one of the most pressing global challenges of our time.
Rising temperatures, melting ice caps, and extreme weather events are becoming increasingly common.
Scientists agree that human activities, particularly the burning of fossil fuels, are a major contributor to these changes.
Addressing climate change requires coordinated international efforts, innovative policy solutions, and a shift toward sustainable energy sources.
"""
print(summarize(content))
```
We’d use a simple decorator for the call and a function with a docstring to define the prompt, keeping the implementation straightforward.
## Chaining LLM Calls in LangChain
LangChain lets you chain LLM calls together using [runnables](/blog/langchain-runnables/) and their LCEL (LangChain expression language), which require explicit definitions of chains and flows. It offers a clean structure for simple prompt chains, but once these become more complex, it turns into a black box that’s hard to debug or tweak.
LangChain also gives you constructors like `load_qa_chain` to handle common tasks, like answering questions based on several documents. These are easy to plug in, but they have downsides and don’t give you much flexibility. If your needs grow or change, you’re stuck wrestling with pre-built chains.
Mirascope takes a different path. It uses plain Python to explicitly define functions and computed fields for [prompt chaining](/blog/prompt-chaining/) in a way that’s clean, flexible, and transparent. You see exactly what’s going on, and you can reuse outputs, save time, and cut down on unnecessary calls.
For most cases, computed fields are the way to go. They let you cache results and pass them into later steps without rerunning the same LLM call over and over.
Here’s a quick example where `explain_scientist` first calls `recommend_scientist` once and injects the result into the prompt template as a computed field:
```python
from mirascope.core import openai, prompt_template
@llm.call("gpt-4o")
@prompt_template(
"""
Recommend a renowned scientist in the field of {field}.
Give me just the name.
"""
)
def recommend_scientist(field: str): ... # [!code highlight]
@llm.call("gpt-4o")
@prompt_template(
"""
SYSTEM:
You are an expert historian of science.
Your task is to explain why the scientist "{scientist_name}" is highly regarded in the field of {field}.
USER:
Explain why "{scientist_name}" is renowned in {field}.
"""
)
def explain_scientist(field: str) -> openai.OpenAIDynamicConfig: # [!code highlight]
return {"computed_fields": {"scientist_name": recommend_scientist(field)}} # [!code highlight]
explanation = explain_scientist("Physics")
print(explanation)
# > "Albert Einstein is renowned in physics for developing the theory of relativity, which revolutionized our understanding of space, time, and gravity."
```
Since we used `computed_fields`, we can see the output at every step of the chain in the final dump:
```python
print(explanation.model_dump())
# {
# "metadata": {},
# "response": {
# "id": "chatcmpl-9r9jDaalZnT0A5BXbAuylxHe0Jl8G",
# "choices": [
# {
# "finish_reason": "stop",
# "index": 0,
# "logprobs": None,
# "message": {
# "content": "Albert Einstein is renowned in physics for developing the theory of relativity, which revolutionized our understanding of space, time, and gravity.",
# "role": "assistant",
# "function_call": None,
# "tool_calls": None,
# },
# }
# ],
# "created": 1722455807,
# "model": "gpt-4o-2024-05-13",
# "object": "chat.completion",
# "service_tier": None,
# "system_fingerprint": "fp_4e2b2da518",
# "usage": {"completion_tokens": 550, "prompt_tokens": 50, "total_tokens": 600},
# ...
# }
```
As mentioned earlier, you can also use functions for [LLM chaining](/blog/llm-chaining/), and even when they don’t offer caching benefits, they provide more explicit control over execution flow and allow for better reuse across classes and methods.
## No Built-In Type Safety for Return Values of Functions
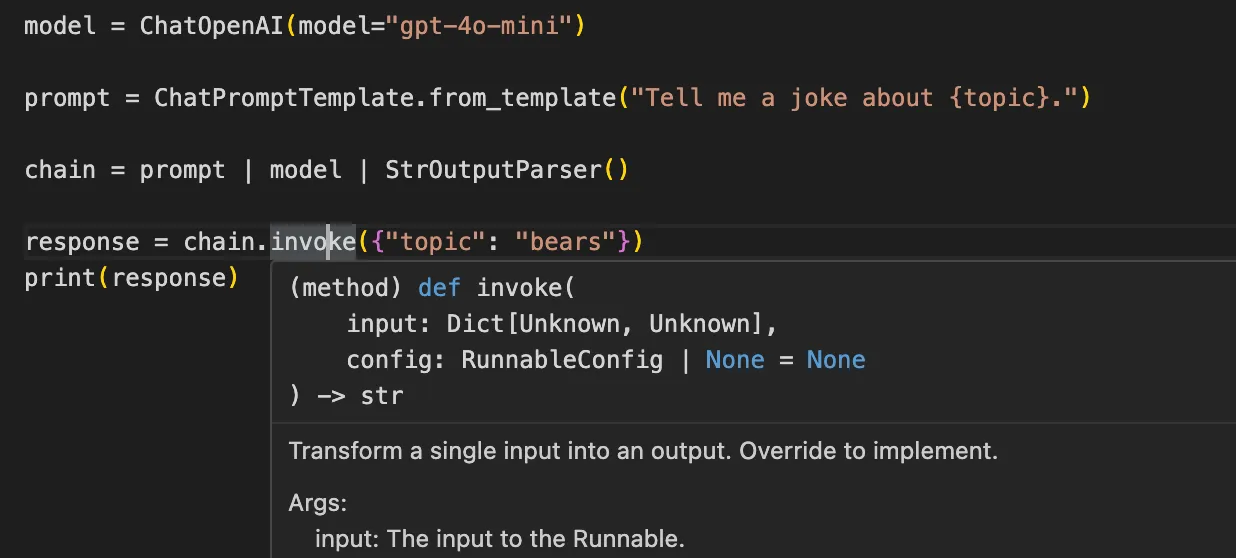
LangChain doesn’t inherently enforce built-in type safety for the return values of functions. For example, when using methods like `invoke()`, inputs are often dictionaries, but there's no explicit type hinting for the expected output or the return type of the function interacting with the LLM.
As a result, **errors related to data structure or type mismatches might only surface at runtime**, when the application tries to process the returned data.
For instance, the method signature for `invoke` below indicates it expects `”topic”` but if we were to pass `”subject”` at runtime, LangChain wouldn’t catch it since there’s no type-checked contract between the prompt and the `invoke()` method:
In contrast, Mirascope implements type safety via its Pydantic-based [response model](/docs/v1/learn/response_models/), enforcing what values functions return, and how LLM calls interact with those functions.
We provide full linting and editor support, offering warnings, errors, and autocomplete as you code. This helps catch potential issues early and ensures code consistency.
For instance, `Book` below is defined as a Pydantic `BaseModel` against which we validate the LLM’s output:
```py
from mirascope import llm, prompt_template
from pydantic import BaseModel
class Book(BaseModel):
"""An extracted book."""
title: str
author: str
@llm.call(provider="openai", model="gpt-4o-mini", response_model=Book)
@prompt_template("Extract the book title and author from this text: {text}")
def extract_book_details(text: str): ...
response = extract_book_details("The book 'Foundation was written by Isaac Asimov.")
print(response.title) # Output: Foundation
print(response.author) # Output: Isaac Asimov
```
Hovering over `response` below shows it expects a `Book` return type:
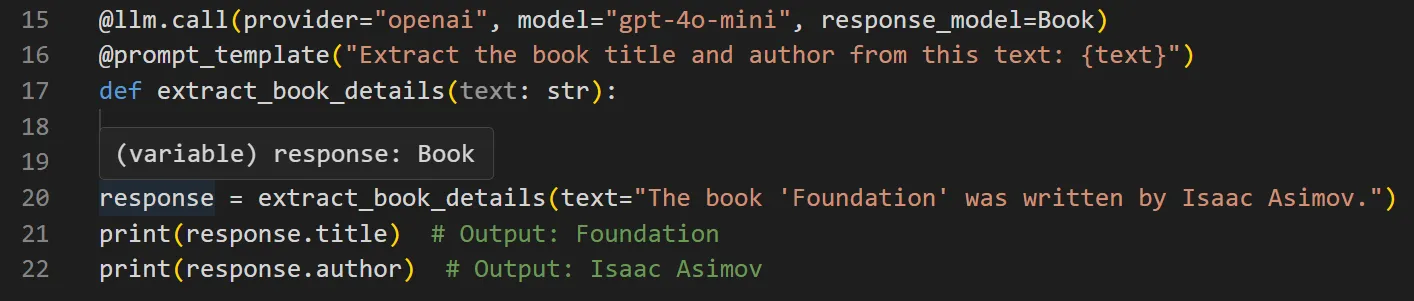
Since the `@call` decorator wraps a regular Python function, you can still use type hints on its inputs, like `text: str`, which helps your IDE provide better autocomplete, inline docs, and error checking as you write code.
## Better Prompt Versioning and Evaluation
We’ve talked about LangSmith, LangChain’s tool for tracing and observability. Now let’s break down where it falls short and how Lilypad does it better.
### LangSmith Only Versions Prompts, Not the Code
LangSmith versions your prompt templates, which gives you Git-style tracking (with SHA hashes) so teams can search, manage, and organize prompts more easily.
**But LangSmith (or LangChain Hub) don’t version the callable or its parameters**. That includes the logic in your chains, [LLM agents](/blog/llm-agents/), and how prompts are used. You’re on your own for that, using Git or adding labels by hand.
That disconnect makes it hard to know which version of your code ran with which version of your prompt. And when things break? Good luck tracing the root cause.
Lilypad auto-versions everything: not just the prompt, but also the Python function that calls the LLM. That includes the model config (like temperature or model name), any helper functions, and all the logic inside.
Why does this matter? Because language models are non-deterministic. The same input can give different outputs. If you don’t version both the code and the [LLM prompt](/blog/llm-prompt/), reproducing bugs or tracking changes becomes almost impossible.
With Lilypad’s `@trace` decorator, you can wrap your LLM function and capture a full snapshot of everything that influenced that call. This also makes it easier to version and monitor API\-based LLM calls, especially when integrating third-party APIs, internal tools, or other cloud services.
Any change to the function: prompt tweak, parameter change, helper edit, etc., creates a new version automatically when you set `versioning=”automatic”`in the trace decorator.
```python
import lilypad
import os
from openai import OpenAI
lilypad.configure(auto_llm=True) # [!code highlight]
client = OpenAI()
@lilypad.trace(versioning="automatic") # [!code highlight]
def answer_question(question: str) -> str:
completion = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": question}],
)
return str(completion.choices[0].message.content)
response = answer_question("Why is the sky blue?")
print(response)
```
You see all this in Lilypad’s playground, an easy-to-use interface that lets both devs and non-devs tweak prompts without touching the code or needing to get someone to redeploy every time they want to test a change.
The playground shows you everything you need to understand your LLM calls, like:
* Prompt templates (with Markdown support) and the exact code behind them.
* LLM responses, plus key details like which model was used, how many tokens it took, and how long it took to run.
For example, we see where the non-deterministic function (`answer_question`) is indicated as V6 in the playground:
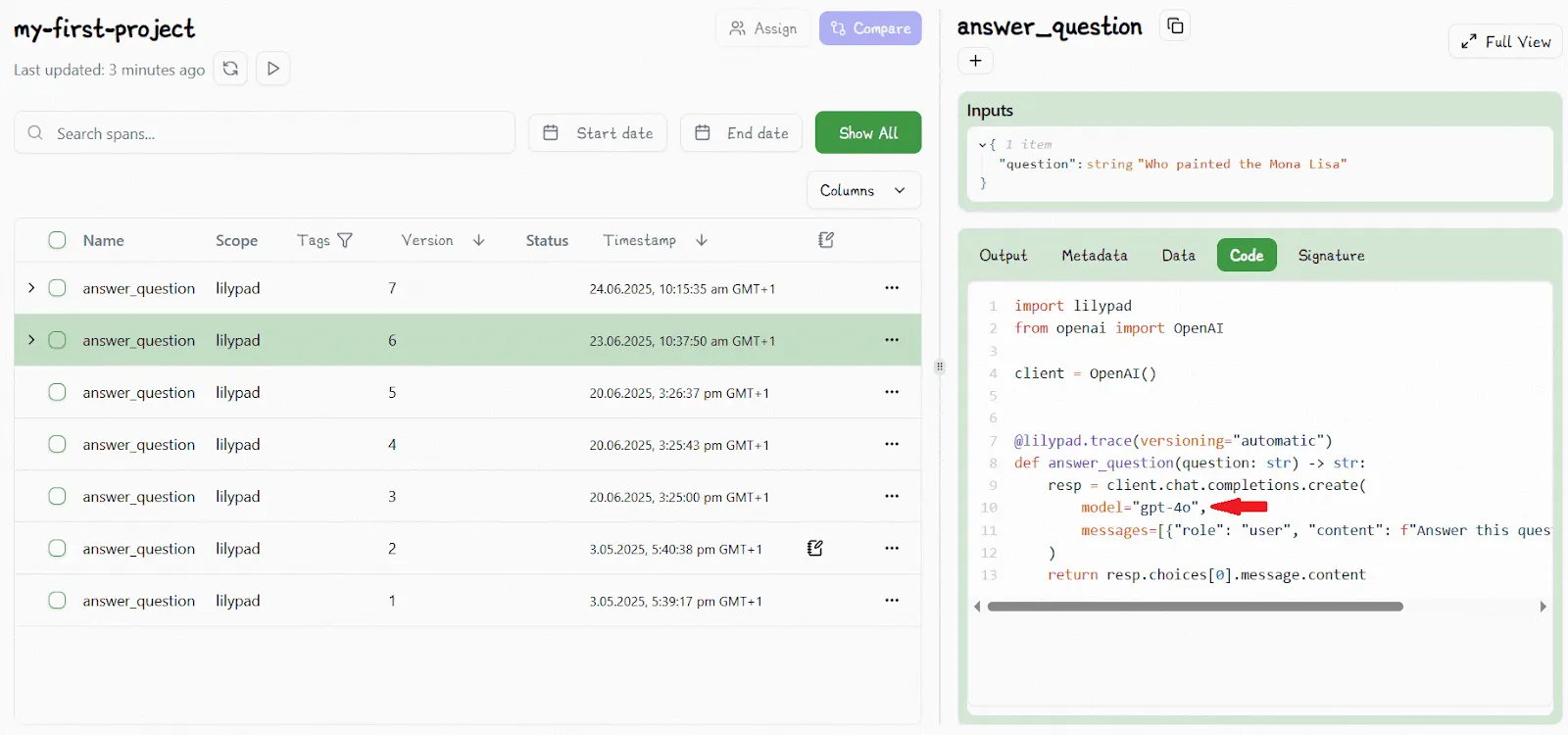
Any changes to the code would increment this to V7.
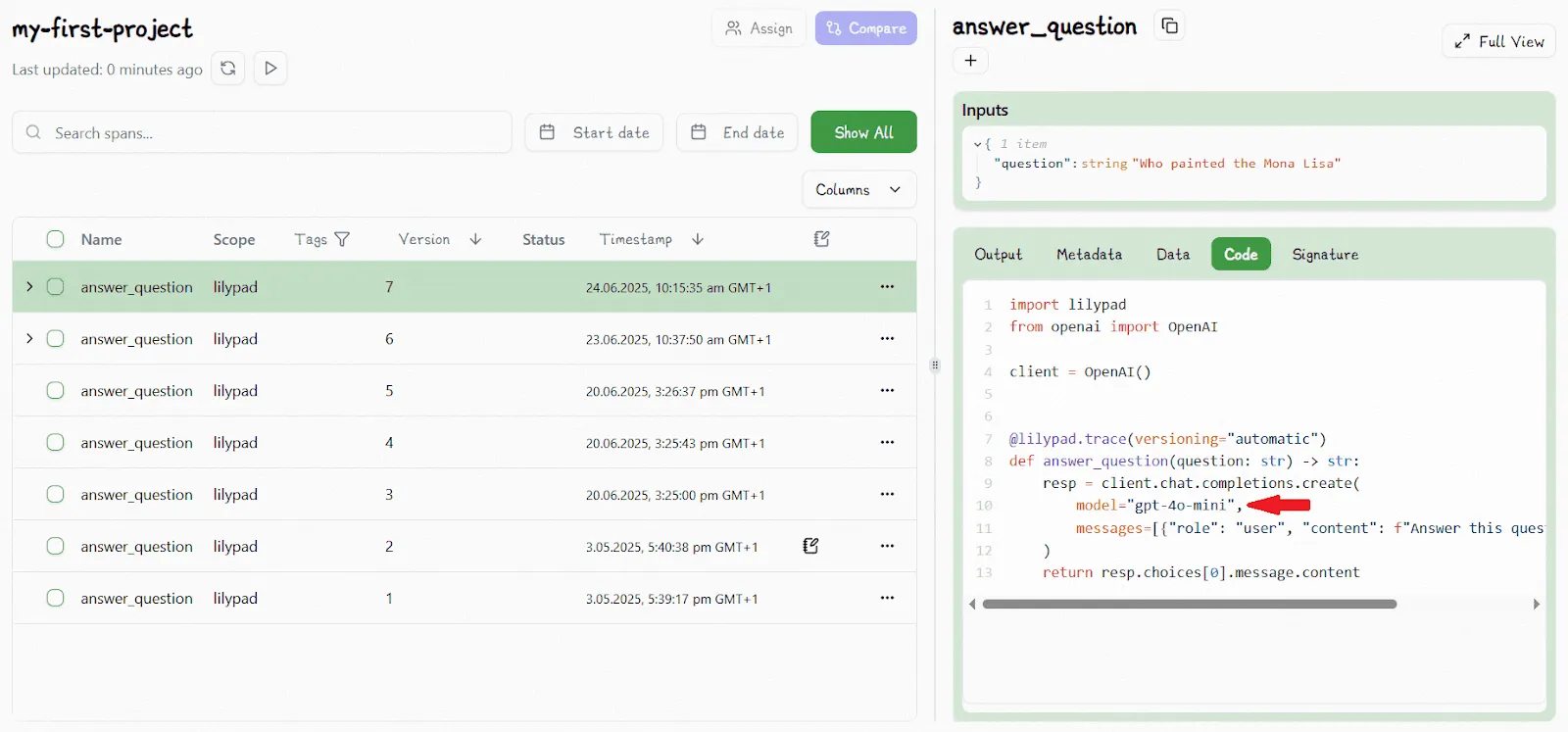
Lilypad automatically creates a nested trace whenever the function is executed:

This gives you a full snapshot of the function — code, config, and logic — so you can accurately compare how different versions affect LLM output on the exact same input.
### Lilypad’s Unified Evaluation Workflow
LangSmith lets you build test sets with expected inputs and outputs, then compare your actual runs against them. Sounds great, until you realize it doesn’t lock in the exact function or logic used to generate those outputs.
That means if something changes in your code, prompts, or model settings, it's tough to go back and understand exactly what happened in a past run. You can tag runs manually to track versions, but there’s no built-in way to connect a test result to the specific callable in your codebase that created it, unless you do the extra work yourself.
Lilypad’s open source framework solves this by fully capturing everything: your function code, prompts, parameters, and helper logic. So even if you're chaining together multiple functions, you get a complete trace of every step. That makes it way easier to evaluate how each part contributed to the final result.
Lilypad also keeps things simple with a binary scoring system: pass or fail, plus a reason why. No fuzzy 1-to-5 scale. This makes feedback for [prompt evaluation](/blog/prompt-evaluation/) use cases clearer and more consistent, by determining what’s “good enough,” especially when reviewing tricky steps in longer workflows.
In the Lilypad playground you evaluate outputs by picking any output:
Then you can assign a label, like “Pass” or “Fail,” and optionally add a comment to explain why you made that choice:
And subsequently marking that output as “Pass” or “Fail” (you can optionally provide reasoning):
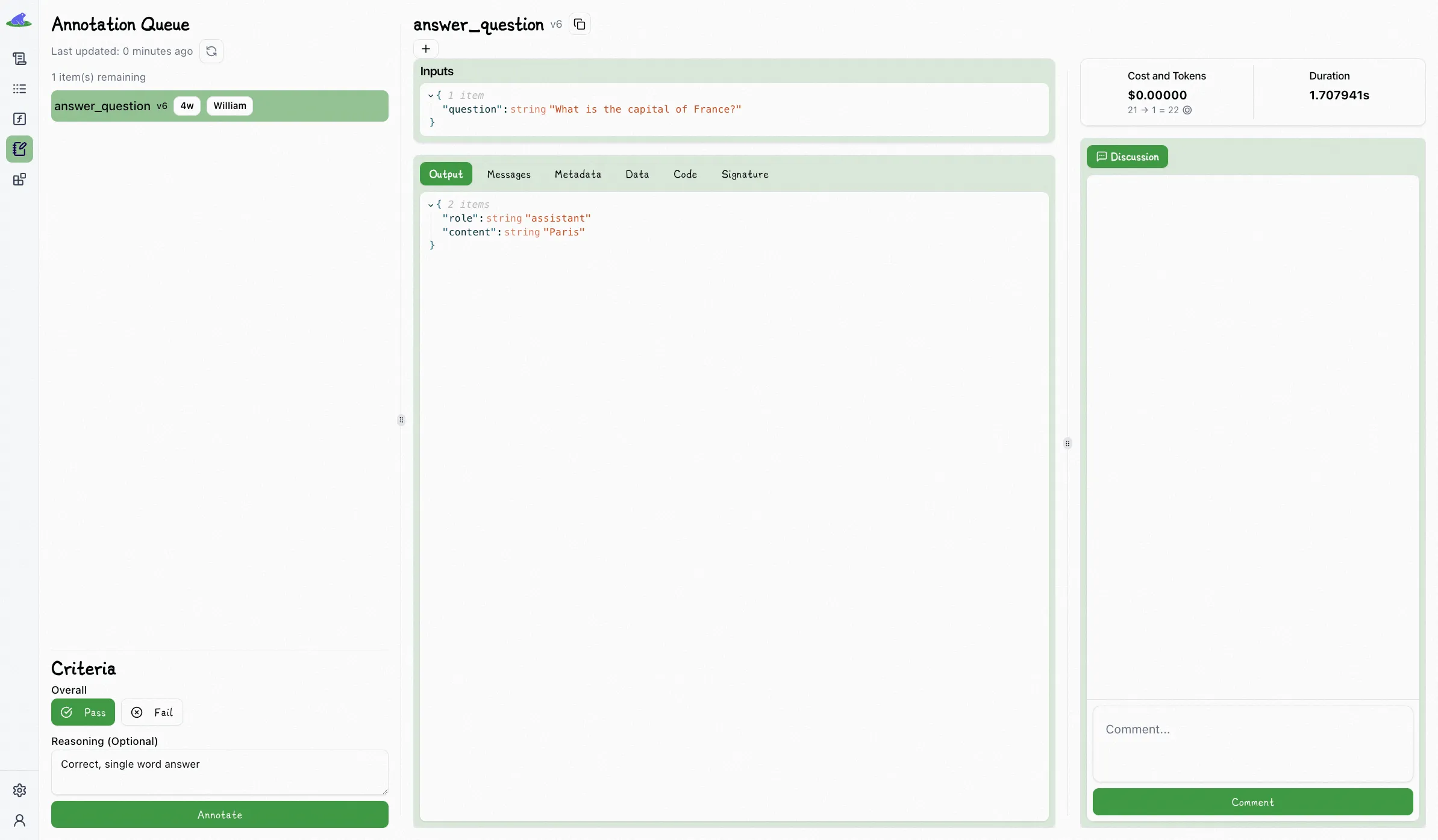
Lilypad’s unified [LLM evaluation](/blog/llm-evaluation/) workflow provides a better dev experience whether you’re testing LLM apps built on an SDK or building apps like chatbots because it ties every output directly to the exact code, prompt, and settings that produced it.
(*See our latest article on [how to make a chatbot](/blog/how-to-make-a-chatbot/).*)
This means you can confidently trace issues, measure improvements, and iterate without guessing what changed. Plus, the simple pass/fail scoring makes it easy to spot what’s working and fix what’s not, especially in complex, multi-step conversations.
We generally recommend starting with manual labeling early in a project to build a high-quality, human-annotated dataset that can eventually serve as training data for automated evaluations, like [LLM\-as-a-judge](/blog/llm-as-judge/).
That said, we still advise manually verifying results as LLM judges can sometimes be uncertain or lack confidence in edge cases.
To get started with Lilypad, you can sign up for the [playground](https://app.lilypad.so/) using your GitHub credentials and instantly begin tracing and versioning your LLM functions with just a few lines of code.
## A Better Stack for LLM Development
Mirascope and Lilypad are built on a simple idea: **use what you need, skip what you don’t**. Instead of locking you into a bloated framework, they give you flexible [LLM tools](/blog/llm-tools/) you can mix and match, from LangChain, LlamaIndex, LangGraph, or wherever else, to build exactly the [LLM integration](/blog/llm-integration/) and generative AI app you want.
When you use Lilypad alongside Mirascope, you get automatic versioning and tracing for every LLM function. That means it tracks not just your prompts, but also the code behind them, so you always know what ran and why.
Want to learn more? You can find more Lilypad code examples on both our [documentation site](/docs/lilypad) and [GitHub](https://github.com/mirascope/lilypad). Lilypad offers first-class support for [Mirascope](https://github.com/mirascope/mirascope), our lightweight toolkit for building AI agents.
Does LangChain Suck? What to Use Instead
2025-06-30 · 13 min read · By William Bakst