RAG is a way to make LLM responses more accurate and relevant by connecting the model to an external knowledge base that pulls in useful information to include in the prompt.
**This overcomes certain limitations of relying on language models alone**, as responses now include up-to-date, specific, and contextually relevant information that aren’t limited to what the model learned during its training.
It also contrasts with other techniques like semantic search, which retrieves relevant documents or snippets (based on the user’s meaning and intent) but leaves the task of understanding and contextualizing the information entirely to the user.
RAG helps reduce the risk of hallucination and offers benefits in fields where accuracy, timeliness, and specialized knowledge are highly valued, such as healthcare, science, legal, and others.
As an alternative to RAG you can [fine-tune a model](/blog/prompt-engineering-vs-fine-tuning/) to internalize domain-specific knowledge, which can result in faster and more consistent responses - as long as those tasks have specialized, fixed requirements - **but it’s generally a time consuming and potentially expensive process**.
Also, the model’s knowledge is static, meaning you’ll need to fine-tune the model again to update it.
RAG, in contrast, gives you up-to-date responses from a knowledge base that can be adapted on the fly.
Below, we explain how RAG works and then show you examples of using RAG for different applications. Finally, we walk you through an example of setting up a simple RAG application in Python.
For the tutorial we use LlamaIndex for data ingestion and storage, and also Mirascope, our user-friendly development library for integrating large language models with retrieval systems to implement RAG.
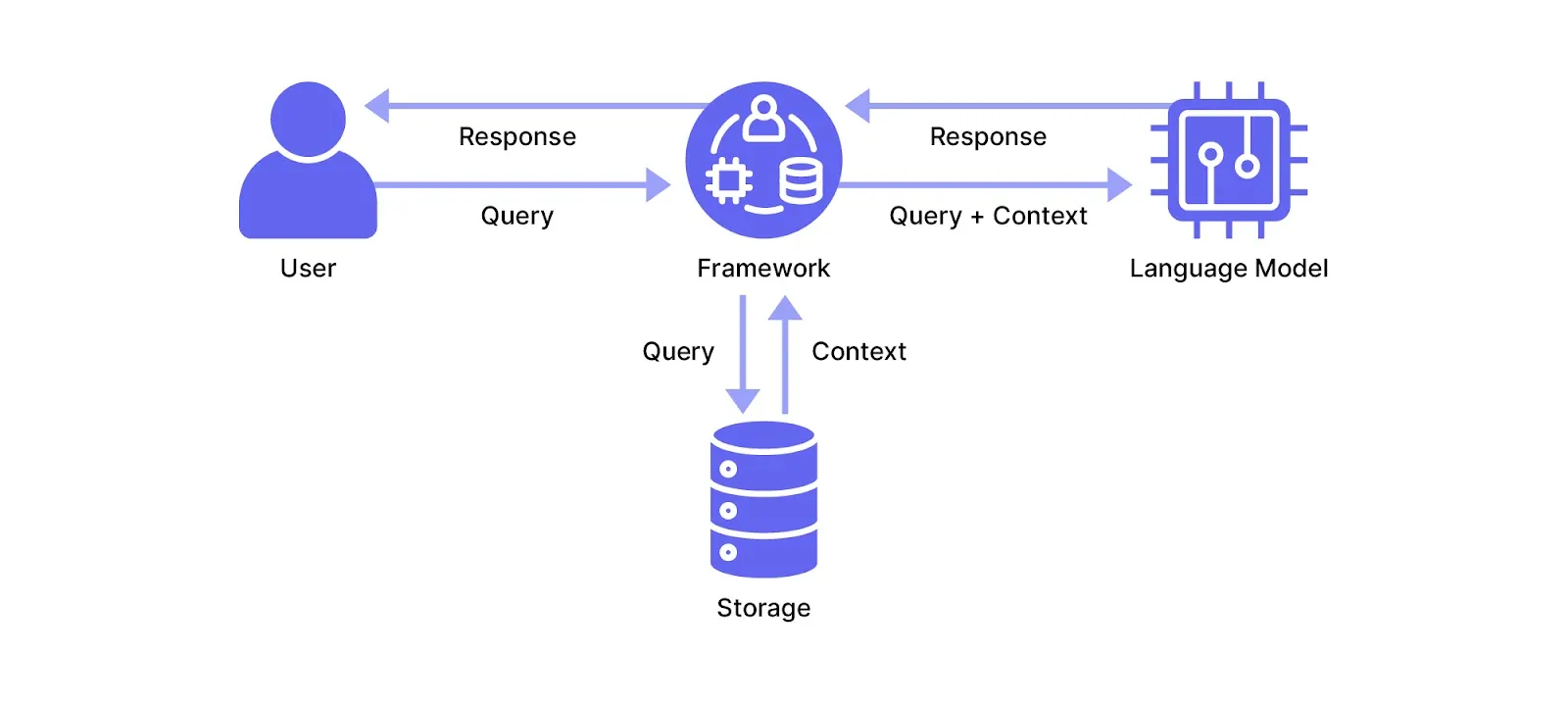
## How Does RAG Work?
To send the right information (or “context”) to the LLM along with your query, you need to set up a pipeline that [orchestrates data flows](/blog/llm-orchestration/) for data ingestion, preprocessing, storage, retrieval, and response generation.
In this section, we describe the broad steps of such a pipeline but keep in mind it’s very generalized since RAG implementations can vary heavily according to project requirements.
For instance:
* Some applications (like an internal knowledge application for an insurance company) might work with proprietary documents, making confidentiality and user access controls important - so the [pipeline](/blog/llm-pipeline/) might include authentication measures, access permissions, and audit trails for secure and compliant retrieval.
* Others, such as specialized domains like medicine or biotech, might use ontologies to organize and retrieve information from structured databases, or undergo strict quality checks (such as automated checks to ensure compliance with industry standards) before being sent to the LLM as context.
Below, we describe a generic RAG setup in three phases:
1. Ingesting documents and segmenting them into chunks
2. Preprocessing each chunk and storing them
3. Retrieving relevant chunks for language model generation
### Step 1: Data Ingestion and Segmentation
Depending on your needs, RAG can involve ingestion of both *unstructured* data like documents (e.g., PDFs, presentations, webpages, and call transcripts), images, and video recordings, and *structured* information like databases, logs, and spreadsheets.
During ingestion, documents are parsed for their useful content (e.g., headers are extracted from documents, content is extracted from HTML pages). [Frameworks](/blog/llm-frameworks/) like LlamaIndex and LangChain offer specialized loader classes for different types of documents and structured data types.
Data is next segmented into manageable chunks using text-splitting software. The size of these chunks, which are generally split according to a predetermined number of tokens or characters, has an impact on retrieval efficiency and often involves certain trade-offs.
For example, simply dividing a 2,000-word article into 200-word chunks without considering the meaning is a quick way to process text but makes it harder to retrieve relevant and coherent information, as connections between segments may be lost.
On the other hand, segmenting according to a document’s natural structure (e.g., by section, paragraph, etc.) and ensuring each chunk is a self-contained idea yields variable-sized chunks that are more complex to segment but leads to more contextually relevant retrievals.
### Step 2: Preprocessing and Storage
The goal of this step is to prepare the chunks to be represented numerically (i.e., as vectors or embeddings), that can be efficiently searched and understood by the retrieval system.
(Note that vectors aren’t the only retrieval system that can be used in RAG, but it’s a popular option)
First, the raw text of chunks are “cleaned” to remove irrelevant elements that might interfere with the process, such as special characters.
Metadata like source information and dates might also be extracted to provide context during the generation step.
The processed text is also typically organized into an index for efficient searching and retrieval.
Finally, we use an embedding model to encode each chunk into a vector (also known as an embedding) and store them in a vector database. Companies like OpenAI and Cohere offer their own embeddings, though you can find many more in places like [Hugging Face](https://huggingface.co/mteb).
Vectors capture semantic meaning and make it easier to retrieve relevant information based on similarity even if the query doesn’t contain exact words or phrases from the document.
This similarity is typically measured by calculating the distance in vector space between query and content using metrics such as cosine similarity or Euclidean distance.
### Step 3: Retrieval and Response Generation
User queries are converted into vectors (using the original embedding model) in order to match them with information in the database.
A similarity search (using the method described in the previous section) retrieves a set of chunks with varying degrees of relevance to the query. The system also might rank these chunks and even assign a relevance score to each.
This context is then sent to the LLM, along with the user’s query. Responses might include numbered references to provide users with evidence for the information presented.
## 3 Real-World RAG Examples
Below we describe three use cases for RAG.
### Automating Email Responses
[An IT solutions provider](https://vstorm.co/case-study/rag-automation-e-mail-response-with-ai-and-llms/) has integrated a language model with their email inbox and product catalog to rapidly and accurately reply to customer questions about their products.
In the past, customers would email their questions and these would queue up in the company inbox to await a reply.
An employee would respond by first looking up the details in the company’s vast product catalog, which could be laborious as they had to sift through multitudes of products, filtering by country, category, and others to give precise answers.
These answers needed to be professional and follow company guidelines, which was time consuming to manually write up and send.
The company now uses RAG to both encode customer questions and use similarity searches to compare these against entries in their product database. The system retrieves the relevant entries and forwards these, along with the original question, to the LLM for a personalized response.
It uses two popular frameworks: LlamaIndex for preprocessing product catalog details and [LangChain](/blog/langchain-rag/) for overall data orchestration from query processing to sending the response back to the customer.
### Routing Support Calls
[A call center has implemented RAG](https://vstorm.co/case-study/llm-powered-voice-assistant-for-call-center/) to verify incoming customer calls and route these to the correct department (or to escalate them).
Instead of answering questions, the system uses past call records and customer emails as a knowledge base, which provides a basis for making informed decisions about how to handle customer queries.
This is in contrast to the old way of manually handling calls, which used to lead to delays in responses and wasn’t very scalable as the customer base grew, especially across countries and languages.
The current RAG implementation handles calls in real time and uses question-answering capabilities to further improve responses.
When the call center receives an inbound call, an LLM-powered voice assistant initiates the process by verifying the caller’s identity and determining the purpose of their call.
It then processes the caller’s query in real time, using language models to analyze and understand the request. Once the type of query is identified, the system automatically routes the call to the appropriate department or escalates it if higher-level intervention is needed.
The system supports multiple languages and runs 24/7.
### Onboarding New Hires
A company can use RAG as an internal onboarding chatbot that consolidates training materials scattered across internal wikis, shared drives, and manuals to reduce the time that trainers spend on repetitive Q&A.
Such materials can be organized as a [knowledge graph](/blog/how-to-build-a-knowledge-graph/) - whose nodes are stored in a vector database as embeddings, and retrieved via semantic search - allowing the system to deeply understand the relationship between nodes and the context of the query.
The grounding of RAG-generated responses in authoritative documents minimizes bias and provides consistent, reliable guidance. Moreover, the system’s knowledge base can be continuously refreshed to remain up to date according to the changing needs of the organization.
With RAG handling routine and repetitive questions from users, trainers are free to focus on strategic mentorship and more complex aspects of onboarding, ultimately improving the overall experience of new employees and trainers.
## Building a RAG-Based Chatbot for Question-Answering
Below, we build an example RAG system that answers questions about Alan Turing’s scientific papers.
We’ll use two libraries for our implementation:
* LlamaIndex for preprocessing and information retrieval
* Mirascope for simplifying [prompt engineering](/blog/advanced-prompt-engineering/) and handling the response
LlamaIndex is a framework designed to handle large datasets and provides [tools](/blog/llm-tools/) for loading and preprocessing documents from a variety of data sources. It also converts these into embeddings for storage and indexing.
Mirascope is a library for interacting with language models in plain Python that provides developer-agnostic tools to optimize prompts, manage state, and [validate outputs](/blog/langchain-structured-output/).
In the steps below, we use LlamaIndex to ingest, preprocess, and store Turing’s scientific papers, as well as to instantiate a retriever object to find relevant papers for our queries.
We then use Mirascope to send both the retrieved context and our queries to the LLM.
### Set Up the Environment
We import LlamaIndex modules for loading, indexing, and vectorizing the papers.
From Mirascope, we import modules for interfacing with the OpenAI API (setting up LLM calls) and for constructing prompts:
```python
from llama_index.core import SimpleDirectoryReader, VectorStoreIndex
from llama_index.core.base.base_retriever import BaseRetriever
from mirascope.core import openai, prompt_template
```
Note that:
* We’ll use LlamaIndex’s `SimpleDirectoryReader` for data ingestion and preprocessing, and `VectorStoreIndex` for embedding and storage
* `BaseRetriever` is the class from which we’ll instantiate the retriever object
* We also import Mirascope’s modules for working with OpenAI and for formulating prompts
### 1. Load and Preprocess the Documents
We load the papers and preprocess them by splitting them into chunks and vectorizing them:
```python
# Load documents and build index
documents = SimpleDirectoryReader("./alan_turing_papers").load_data()
retriever = VectorStoreIndex.from_documents(documents).as_retriever()
```
Here, `SimpleDirectoryReader` loads an entire subdirectory containing PDFs (this class also manages other formats like CSV, Microsoft Word documents, Jupytr notebooks, MP3s, and more), and extracts the text and metadata from each file.
We next use `VectorStoreIndex` to build a searchable index of the retrieved documents we’ve loaded by splitting them into chunks and preprocessing them (via `from_documents`).
Once these chunks (or “nodes” as [LlamaIndex](/blog/llamaindex-vs-langchain/) refers to them) are created, `VectorStoreIndex` uses a default embedding model to vectorize and store these in memory. (You can also use a separate vector store such as Pinecone.)
Lastly, we instantiate a retriever object to fetch relevant content given a user query using `.from_retriever`.
### 2. Query and Retrieve Context
We define a function to query our Alan Turing library:
```python
# Define the function to ask "Alan Turing" a question
@openai.call("gpt-4o-mini", call_params={"temperature": 0.6})
@prompt_template("""
SYSTEM:
Your task is to respond to the user as though you are Alan Turing, drawing on ideas from
"Computing Machinery and Intelligence."
Here are some excerpts from Turing’s paper relevant to the user query.
Use them as a reference for how to respond.
<excerpts>
{excerpts}
</excerpts>
""")
def ask_alan_turing(query: str, retriever: BaseRetriever) -> openai.OpenAIDynamicConfig:
"""Retrieves excerpts from 'Computing Machinery and Intelligence' relevant to `query` and generates a response."""
excerpts = [node.get_content() for node in retriever.retrieve(query)]
return {"computed_fields": {"excerpts": excerpts}}
```
The `ask_alan_turing` function:
* Receives a query string and our retriever object, and returns a dictionary containing `excerpts` from the set of scientific papers.
* Calls `retriever.retrieve(query)` to search the vector store for the most semantically relevant excerpts of Turing’s papers that relate to the user’s query.
* Fetches and processes excerpts at runtime (to insert in the [prompt template](/blog/langchain-prompt-template/)) via `OpenAIDynamicConfig` and computed fields.
We add two Mirascope decorators to turn the function into an LLM API call:
* The `openai.call` decorator makes calls more readable by turning any Python function into an LLM call and is provider agnostic: we could’ve instead written, e.g., `anthropic.call`, `google.call` or any of a number of others, with minimal code adjustments.
* Mirascope’s `prompt_template` decorator enables defining the prompt as a template that instructs the model to respond as if it’s Alan Turing and injects a list of the retrieved excerpts.
Both of these decorators, when added to any function, illustrate the best practice of colocation of prompts and calls, which makes the code eminently more readable as the logic for preparing input data, [building prompts](/blog/llm-prompt/), and LLM invocation is centralized in a single place.
### 3. Generate a Response from the Query
Finally, the user asks a question about Turing’s research papers:
```python
# Get the user's query and ask "Alan Turing"
query = input("(User): ")
response = ask_alan_turing(query, retriever)
print(response.content)
# > How does Turing address the objections to the idea that machines can think?
> This question delves into the various arguments Turing discusses in his paper, such as the theological objection, the "heads in the sand" objection, ...
```
The code captures the user’s query and calls `ask_alan_turing`, which retrieves the relevant excerpts from the cache of Turing’s papers in `documents`. Both the query and the excerpts are then sent to the model as a response.
## Optimize Your RAG Pipeline
Take the complexity out of implementing retrieval augmented generation with Mirascope’s native Python-based library. It lets you use RAG in your question-answering systems, allowing you to build smarter, more data-aware [LLM applications](/blog/llm-applications/) that answer questions with accuracy at scale.
Want to learn more? You can find more Mirascope code samples both on our [website](/docs/mirascope) and on our [GitHub page](https://github.com/mirascope/mirascope).
Retrieval Augmented Generation - Examples & How to Build One
2025-01-14 · 12 min read · By William Bakst