LangChain provides a mix of methods and tools for structuring LLM outputs. Below are some of the most commonly used ones:
- `.with_structured_output()`: A class method that uses a schema (like a JSON template) to guide the structure of the model’s response.
- `PydanticOutputParser`: Parses the model’s raw output using a Pydantic object to extract key information.
- `StructuredOutputParser`: Similar to the above, but works with simpler schema definitions like Python dictionaries or JSON schemas.
These tools are especially helpful when you need the model to return a consistent format. For instance, if you want a response with fields like `"name"`, `"date"`, and `"location"`, they let you define and enforce that structure, making downstream processing much easier.
LangChain offers off-the-shelf parsers for different use cases. But these often rely on its runnable abstraction (used for [prompt chaining](/blog/prompt-chaining/) operations) within the LangChain Expression Language (LCEL). While this enables composable workflows, it also introduces unnecessary complexity and requires you to learn its unique way of doing things.
For this reason, we built [Mirascope](https://github.com/mirascope/mirascope), our lightweight LLM toolkit that lets you define structured outputs in native Python and Pydantic, with no unique abstractions to learn.
But generating structured outputs is only part of the picture. You also need visibility into how those outputs are parsed and tracked across iterations and how prompt or logic changes affect results over time.
That’s where our other tool, an open source LLM engineering platform, [Lilypad](https://github.com/mirascope/lilypad), comes in: it handles prompt management, code versioning, and evaluation so you can iterate confidently and treat prompt engineering like the optimization problem it really is.
## How to Get Structured Outputs in LangChain
### 1. `.with_structured_output()`
This class method lets you define a schema (like a JSON object) to guide the model’s output format.
It only works with LLMs that support structured output natively, such as OpenAI (via JSON mode or tool calling), Anthropic, Cohere, and similar providers. If the model doesn’t support this feature, you’ll need to use an output parser instead.
Use `.with_structured_output()` to specify a particular format you want the LLM to use in its response, passing this format as schema into the prompt:
```python
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
# Instantiate the LLM model
model = ChatOpenAI(model="gpt-4o-mini", temperature=0)
class Trivia(BaseModel):
question: str = Field(description="The trivia question")
answer: str = Field(description="The correct answer to the trivia question")
# Define the prompt template
prompt = ChatPromptTemplate.from_template(
"Give me a trivia question about {topic}, respond in JSON with `question` and `answer` keys"
)
# Create a structured LLM using the `with_structured_output` method
structured_llm = model.with_structured_output(Trivia, method="json_mode") # [!code highlight]
# Chain the prompt and structured LLM using the pipe operator
trivia_chain = prompt | structured_llm
# Invoke the chain
result = trivia_chain.invoke({"topic": "space"})
# Output
Trivia(question='What is the largest planet in our solar system?', answer='Jupiter')
```
Here, we define Trivia as a Pydantic model that describes the structure we want the LLM to follow. To ensure the output is returned in that format, we pass `method="json_mode"` into `.with_structured_output()`.
Because we’re using Pydantic, any mismatch between the model’s output and the Trivia schema, like missing fields or incorrect types, will raise an error at runtime.
This method also wraps the LLM in a [runnable](/blog/langchain-runnables), which binds the model to the output schema. That’s what lets us later chain it to the prompt using LangChain’s pipe operator (|).
Runnables do offer some conveniences, like handling async calls and streaming responses, but they can get harder to manage as your [LLM chaining](/blog/llm-chaining/) logic grows. The more components you add, the trickier it becomes to debug and reason through each step.
That’s because runnables are LangChain-specific constructs built into the LangChain Expression Language (LCEL). While powerful, they add overhead to understanding what’s going on under the hood, and that learning curve can slow you down.
Mirascope takes a more Pythonic approach. You build chains using regular Python functions and types, a faster way to develop [LLM applications](/blog/llm-applications/) without the overhead of custom abstractions.
As for schemas: when using `.with_structured_output()`, you can define the structure using a TypedDict, JSON schema, or a Pydantic class. Here's how that affects the output:
* If you use a `TypedDict` or JSON schema, the model returns a plain dictionary.
* If you use a Pydantic class, the model returns a Pydantic object.
* When using a JSON schema dictionary, the model’s output will be a dictionary.
Streaming is also supported when the output is a dictionary, whether from a `TypedDict` or JSON schema.
### 2. `PydanticOutputParser`
Not all LLMs support structured outputs natively, so when features like tool calling or JSON mode aren’t available, you can make use of an output parser like `PydanticOutputParser`.
This parser is particularly useful where type safety matters. It ensures that the model’s response matches a defined Pydantic schema and raises an error if required fields are missing or the types don’t match.
Like `.with_structured_output()`, PydanticOutputParser is also a runnable, which means you can compose it with other LangChain components in a chain.
Below, we use PydanticOutputParser to specify a Book schema to ensure the title in the LLM’s output is a string and the number of pages is an integer:
```python
from typing import List
from langchain_core.output_parsers import PydanticOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
class Book(BaseModel):
"""Information about a book."""
title: str = Field(..., description="The title of the book")
pages: int = Field(
..., description="The number of pages in the book."
)
class Library(BaseModel):
"""Details about all books in a collection."""
books: List[Book]
# Set up a parser
parser = PydanticOutputParser(pydantic_object=Library) # [!code highlight]
# Prompt
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"Answer the user query. Wrap the output in `json` tags\n{format_instructions}",
),
("human", "{query}"),
]
).partial(format_instructions=parser.get_format_instructions())
# Query
query = "Please provide details about the books 'The Great Gatsby' with 208 pages and 'To Kill a Mockingbird' with 384 pages."
# Print the prompt and output schema
print(prompt.invoke(query).to_string())
```
```
System: Answer the user query. Wrap the output in `json` tags
The output should be formatted as a JSON instance that conforms to the JSON schema below.
As an example, for the schema {"properties": {"foo": {"title": "Foo", "description": "a list of strings", "type": "array", "items": {"type": "string"}}}, "required": ["foo"]}
the object {"foo": ["bar", "baz"]} is a well-formatted instance of the schema. The object {"properties": {"foo": ["bar", "baz"]}} is not well-formatted.
# Output schema
{
"type": "object",
"properties": {
"books": {
"type": "array",
"items": {
"type": "object",
"properties": {
"title": {
"type": "string",
"description": "The title of the book"
},
"pages": {
"type": "integer",
"description": "The number of pages in the book."
}
},
"required": ["title", "pages"]
}
}
},
"required": ["books"]
}
Human: Please provide details about the books 'The Great Gatsby' with 208 pages and 'To Kill a Mockingbird' with 384 pages.
```
Next, we invoke the chain:
```python
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(temperature=0)
chain = prompt | llm | parser
chain.invoke({"query": query})
```
The output conforms to the schema defined by Library, with the `books` list containing two Book objects, each with a title and pages field. The JSON tags would be added based on the instructions given in the prompt.
```
{
"books": [
{
"title": "The Great Gatsby",
"pages": 218
},
{
"title": "To Kill a Mockingbird",
"pages": 281
}
]
}
```
The parser raises a validation error if the output doesn’t match the expected structure or data types.
### 3. `StructuredOutputParser`
This parser works with most language models and lets you define your own schema using `ResponseSchema` objects. It’s especially useful when other parsers don’t support the structure you need.
Each `ResponseSchema` represents a key-value pair and has the following fields:
* **Name**: The key or field name expected in the output
* **Description**: A brief explanation of what the field represents
* **Type**: The expected data type (e.g., `str`, `int`, or `List[str]`)
In the example below, we ask the model to return a recipe and ingredients list for *Spaghetti Bolognese*.
We first define two `ResponseSchema` objects, one for `recipe` and the other for `ingredients`, both expected to be strings.
```python
from langchain.output_parsers import ResponseSchema, StructuredOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
# Define the schema for the expected output, including two fields: "recipe" and "ingredients"
response_schemas = [ # [!code highlight]
ResponseSchema(name="recipe", description="the recipe for the dish requested by the user"), # [!code highlight]
ResponseSchema( # [!code highlight]
name="ingredients", # [!code highlight]
description="list of ingredients required for the recipe, should be a detailed list.", # [!code highlight]
), # [!code highlight]
] # [!code highlight]
# Create a StructuredOutputParser instance from the defined response schemas
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)
# Generate format instructions based on the response schemas, which will be injected into the prompt
format_instructions = output_parser.get_format_instructions()
# Define the prompt template, instructing the model to provide the recipe and ingredients
prompt = PromptTemplate(
template="Provide the recipe for the dish requested.\n{format_instructions}\n{dish}",
input_variables=["dish"],
partial_variables={"format_instructions": format_instructions},
)
model = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# Create a chain that connects the prompt, model, and output parser
chain = prompt | model | output_parser
# The output will be structured according to the predefined schema with fields for "recipe" and "ingredients"
chain.invoke({"dish": "Spaghetti Bolognese"})
```
We then create the `StructuredOutputParser` using the defined `response_schemas` to ensure the LLM’s output conforms to the structure defined by the schemas.
We also specify `format_instructions` based on the `StructuredOutputParser` created previously to tell the language model how to format its response so this matches the structure defined by the ResponseSchema objects.
Our [prompt template](/blog/langchain-prompt-template) then asks the language model to provide a recipe and the list of ingredients for a specified dish, and includes the format instructions we previously specified.
Lastly, we create a chain (which returns a runnable) using the pipe moderator and invoke it to run, receive, and parse the response according to our defined schemas:
```
{
"recipe": "To make Spaghetti Bolognese, cook minced beef with onions, garlic, tomatoes, and Italian herbs. Simmer until thickened and serve over cooked spaghetti.",
"ingredients": "Minced beef, onions, garlic, tomatoes, Italian herbs, spaghetti, olive oil, salt, pepper."
}
```
##
## How to Get Structured Outputs in Mirascope (And How It Differs from LangChain)
Mirascope takes a simpler approach that doesn’t require wrapping models in runnables, which makes it easier to avoid the overhead often introduced by more complex [LLM frameworks](/blog/llm-frameworks/).
It’s built to work directly with Python and Pydantic, so you can define your output schema using regular classes — no extra wrappers or custom parsers required. This simplicity is ideal for applications like [synthetic data generation](/blog/synthetic-data-generation/), where model outputs need to align with predefined data schemas.
It also supports Pydantic V2, which gives you access to faster performance, async validation, and more modern Python features out of the box.
**Note**: [Pydantic V2](https://pydantic.dev/articles/pydantic-v2-final) isn’t backward-compatible with V1, so using frameworks that depend on the older version may introduce conflicts or limitations.
### Output Parsing in Mirascope
In Mirascope, you write output parsers as regular Python functions that work alongside call decorators, which you can apply to any function to turn it into an LLM API call. These decorators make it easy to switch between models or compare outputs across providers, since Mirascope supports a growing list of providers.
Like LangChain, Mirascope supports OpenAI’s JSON mode and structured outputs using both JSON schema and tool calls.
The example below shows a custom output parser that extracts structured data into a Movie object, with a decorator that sends the prompt to Anthropic.
```python
from mirascope.core import anthropic, prompt_template
from pydantic import BaseModel
class Movie(BaseModel):
title: str
director: str
def parse_movie_recommendation(response: anthropic.AnthropicCallResponse) -> Movie: # [!code highlight]
title, director = response.content.split(" directed by ") # [!code highlight]
return Movie(title=title, director=director) # [!code highlight]
@llm.call(
model="claude-3-5-sonnet-20240620", output_parser=parse_movie_recommendation # [!code highlight]
)
@prompt_template("Recommend a {genre} movie in the format Title directed by Director")
def recommend_movie(genre: str):
...
movie = recommend_movie("thriller")
print(f"Title: {movie.title}")
print(f"Director: {movie.director}")
```
Note that we pass `output_parser` to the call decorator to change the return type of the decorated function to match the parser’s output. While you could run the parser manually, adding it to the decorator ensures it runs automatically with every call, which is useful since the parser and prompt are often tightly coupled.
Notice that we also separate prompt instructions from the function itself by using the `@prompt_template` decorator. This makes it easier to keep prompts consistent across multiple calls and tweak them independently of other logic.
Separating prompt logic from output parsing improves code reuse and makes functions easier to maintain, which is especially helpful in [advanced prompt engineering](/blog/advanced-prompt-engineering/), where keeping logic modular improves reusability and traceability.
Here are a few more ways Mirascope differs from LangChain:
#### **Documentation and Linting in Your IDE**
As part of good coding practice, Mirascope provides type hints for function returns and variables, helping your IDE catch issues like missing arguments and other common errors as you write.
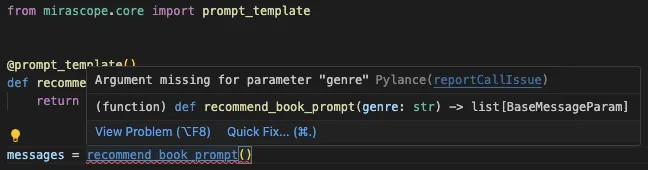
This type safety applies across all Mirascope functions and classes, including output parsers and response models (which we cover later).
We also offer auto suggestions:
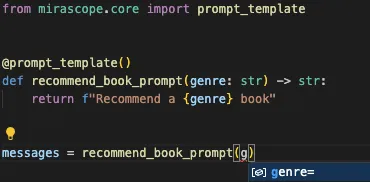
This makes it easy to catch mistakes before running your code and reflects Mirascope’s promotion of [best coding practices](/blog/engineers-should-handle-prompting-llms).
### Specifying Language Model Outputs with Response Models
Mirascope’s `response_model` lets you define the type of output you expect from the LLM using a Pydantic class, like `Recipe` in the example below.
The benefit is that it allows you to catch schema mismatch or validation issues before runtime. This is a notable improvement in developer experience compared to LangChain, which (at least out of the box) only surfaces such errors during runtime.
Once you’ve defined the model against which to extract the output, you insert the model name into the argument of the call decorator as `response_model` in order to specify the LLM’s return type:
```python
from mirascope.core import openai
from pydantic import BaseModel
class Recipe(BaseModel): # [!code highlight]
dish: str # [!code highlight]
chef: str # [!code highlight]
@llm.call(model="gpt-4o-mini", response_model=Recipe) # [!code highlight]
def recommend_dish(cuisine: str) -> str:
return f"Recommend a {cuisine} dish"
dish = recommend_dish("Italian")
assert isinstance(dish, Recipe) # [!code highlight]
print(f"Dish: {dish.dish}")
print(f"Chef: {dish.chef}")
```
This automatically validates and structures the LLM’s output according to your predefined model, making the output easier to integrate into your application logic.
Like LangChain’s `.with_structured_output()`, Mirascope passes your Pydantic model and config to the LLM to steer the response into the expected format.
Below are a few of the most useful settings available for response models:
#### **Returning Outputs in Valid JSON**
Setting `json_mode=True` in the call decorator will apply [JSON mode](/docs/v1/learn/json_mode/), if it’s supported by your LLM, rendering the outputs as valid JSON:
```python
import json
from mirascope.core import openai
@llm.call(model="gpt-4o-mini", json_mode=True) # [!code highlight]
def get_movie_info(movie_title: str) -> str:
return f"Provide the director, release year, and main genre for {movie_title}"
response = get_movie_info("Inception")
print(json.loads(response.content)) # [!code highlight]
# > {"director": "Christopher Nolan", "release_year": "2010", "main_genre": "Science Fiction"}
```
##
#### **Adding Few-Shot Examples to Response Models**
Mirascope response models also let you add few-shot examples as shown below, where we add `examples` arguments in the fields of Destination:
```python
from mirascope.core import openai, prompt_template
from pydantic import BaseModel, ConfigDict, Field
class Destination(BaseModel):
name: str = Field(..., examples=["KYOTO"])
country: str = Field(..., examples=["Japan"])
model_config = ConfigDict(
json_schema_extra={"examples": [{"name": "KYOTO", "country": "Japan"}]} # [!code highlight]
)
@llm.call("gpt-4o-mini", response_model=Destination, json_mode=True)
@prompt_template(
"""
Recommend a {travel_type} travel destination.
Match example format EXCLUDING 'examples' key.
"""
)
def recommend_destination(travel_type: str): ...
destination = recommend_destination("cultural")
print(destination)
# > name='PARIS' country='France'
```
You can learn more about Mirascope’s response model [here](/docs/v1/learn/response_models).
## Versioning and Observability in LangChain (And How Lilypad Does It Better)
Structured outputs aren’t just easier to work with, they’re important for observability. When your outputs follow a predictable format (like JSON), it becomes practically feasible to reliably trace, evaluate, and monitor model behavior over time, which lays the groundwork for better [LLM evaluation](/blog/llm-evaluation/) and performance tracking.
But most observability tools split this workflow across multiple platforms. You edit prompts in one place, trace runs in another, and evaluate results in a third. That disconnect makes it hard to tell whether a change was actually helpful, especially since LLMs are inherently non-deterministic and can return slightly different results across runs, even with the same input.
We built Lilypad to unify that workflow. It automatically versions your LLM function logic, tracks every input and output, and ties [LLM prompt](/blog/llm-prompt/) updates, model settings, and structured outputs into one continuous, reviewable loop, making it especially useful when building [LLM agents](/blog/llm-agents/) that require observability across multiple calls.
### Automatic Output Versioning System
LangSmith (and LangChain Hub) offers Git‑style prompt history, commits, tags, downloads, but linking any given output back to the exact prompt version requires you to push each revision to the prompt hub, tag it (e.g., “v2” or a hash), then explicitly pull that identifier in your code or look it up in the UI.
Because the mapping isn’t automatic, you often end up hard‑coding tags or hashes (like 3b452769) or trawling the LangSmith dashboard to discover which prompt produced a specific result.
Lilypad solves this by automatically versioning not just the prompt but the entire function that calls the LLM, including model settings, input parameters, helper functions, and even the logic used to process the output into a structured format.
Any change to this function is automatically tracked as a new version, giving you a complete snapshot of what generated each output.
To enable automatic tracking and versioning, you simply decorate your LLM-calling function with `@lilypad.trace(versioning="automatic")`:
```python
import lilypad
import os
from openai import OpenAI
lilypad.configure()
client = OpenAI()
@lilypad.trace(versioning="automatic") # [!code highlight]
def answer_question(question: str) -> str:
completion = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": question}],
)
return str(completion.choices[0].message.content)
response = answer_question("Who is a jack of all trades?")
print(response)
```
Structuring your calls in this way gives room for effective optimization. Every time a structured output is generated, you know exactly what changed, when it changed, and why.
Lilypad is also tool-agnostic and supports any other prompt engineering library you might be using.
### Playground to Manage Versions, Inputs, and Code Logic
When domain experts like product, marketing or legal teams want to tweak a prompt, they often need developers to make the change, test it, and redeploy the app, even for small updates.
Lilypad solves this with managed prompts and a playground UI that lets non-technical users edit and test prompts without touching the underlying code. This separates concerns: domain experts handle prompt logic, while engineers focus on the system architecture.
This separation only happens in the user interface. Behind the scenes, the prompts are still part of the versioned code: they aren’t stored in some separate system. With Lilypad, every prompt you test in the playground connects directly to the exact version of the function it’s part of.
This makes it easy to track changes, fix bugs, and improve your app over time. Other tools treat prompts as their own thing, separate from the rest of the code. We think that’s a mistake, because it breaks the link between how the prompt works and how the app actually behaves.
We believe keeping prompts tied to code is essential for reliability and iteration.
That’s why Lilypad snapshots the entire function, prompt logic, model settings, inputs, and outputs, each time you decorate it with `@lilypad.trace`. Any change creates a new version that shows up in the playground, ready to test.
Below is an example of a traced function displayed in the playground as V6:
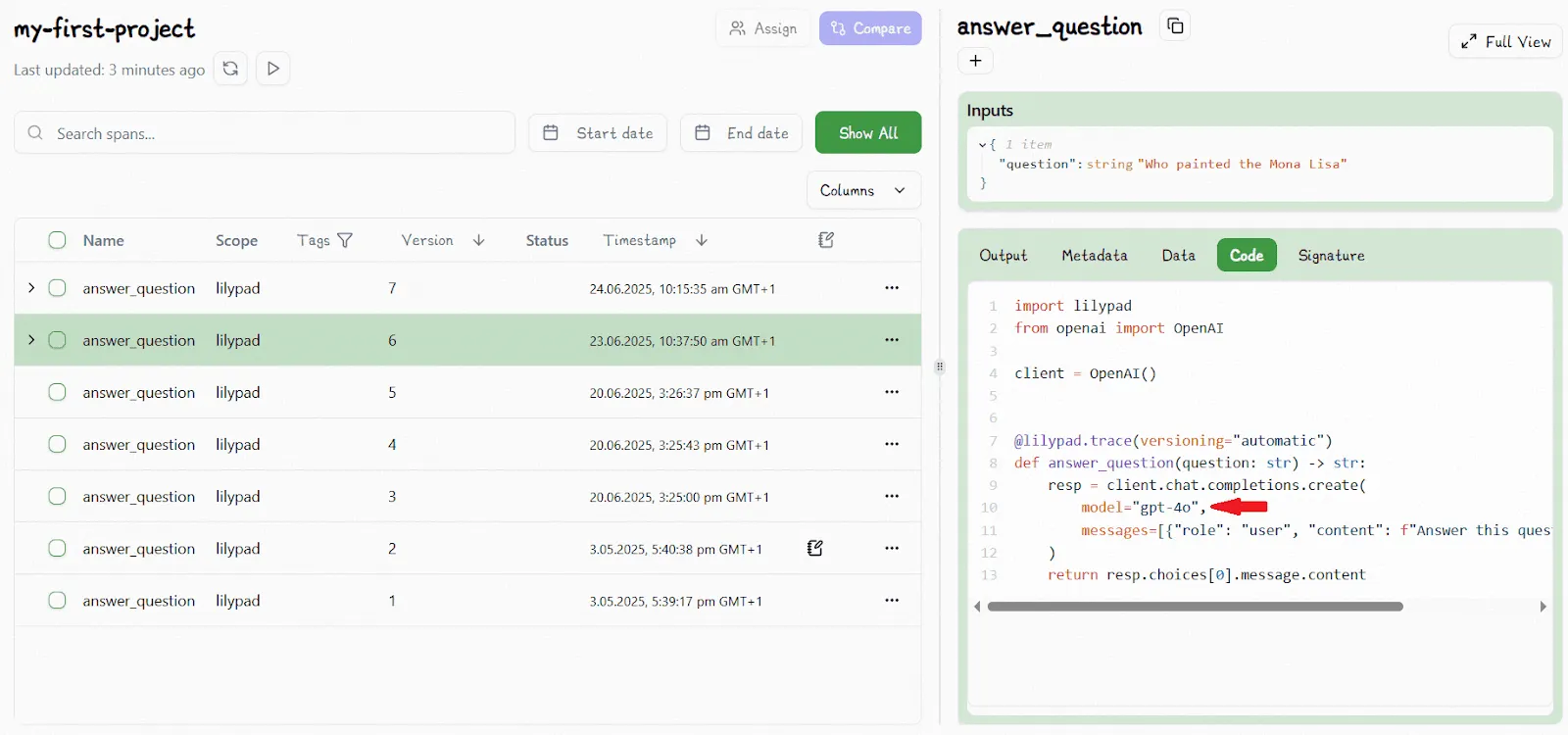
After updating the function to switch the model type gpt-4o-mini, Lilypad detects the change and increments the version automatically. The playground now reflects this as version V7:
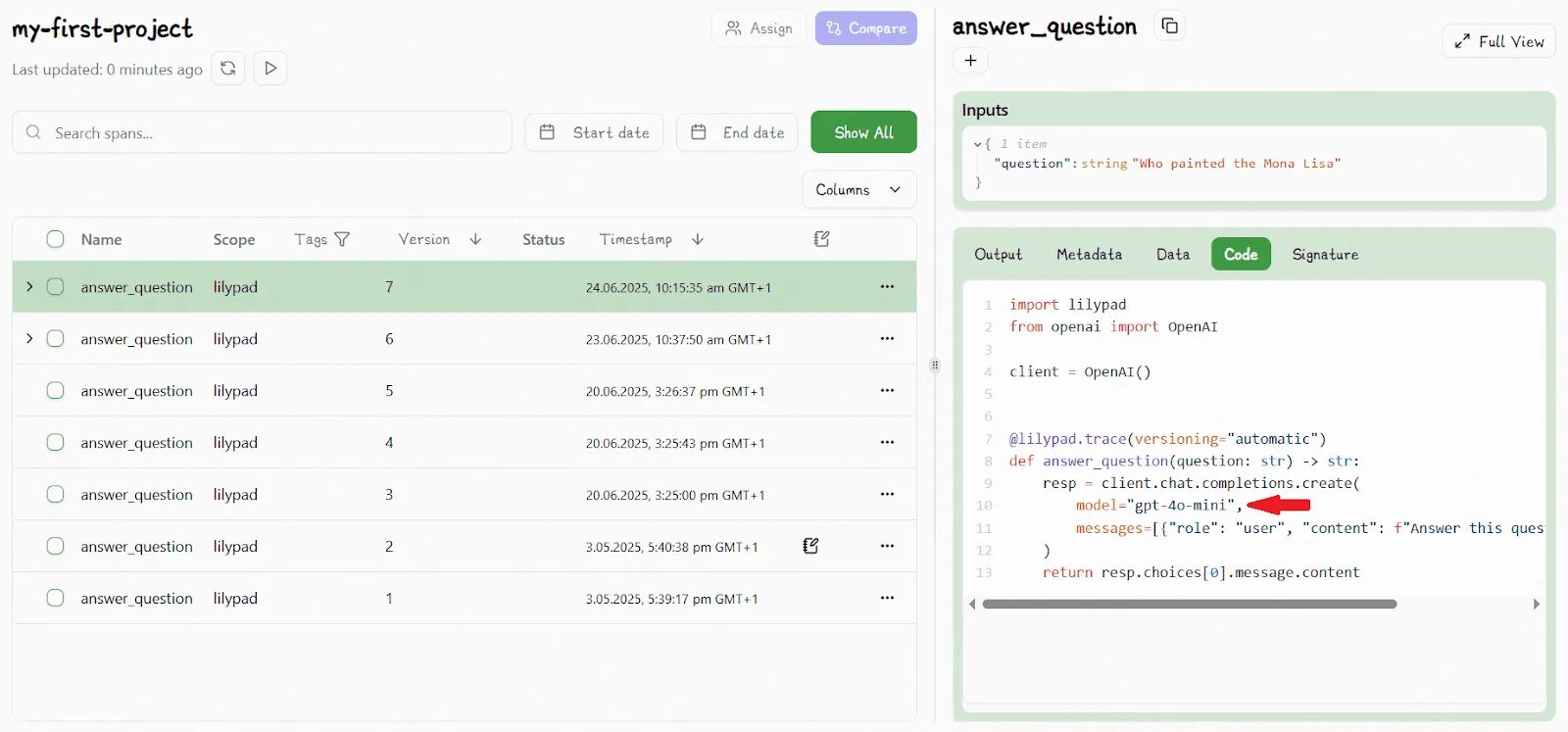
This automatic versioning removes the need to track these changes manually and lets you roll back or compare versions as needed.
And if your changes are functionally identical to a previous version, Lilypad won’t increment the version. This prevents duplication and keeps the version history clean and meaningful.
Domain experts can define prompt templates with input variables, and Lilypad automatically generates type-safe function signatures to keep everything structured, as shown below:
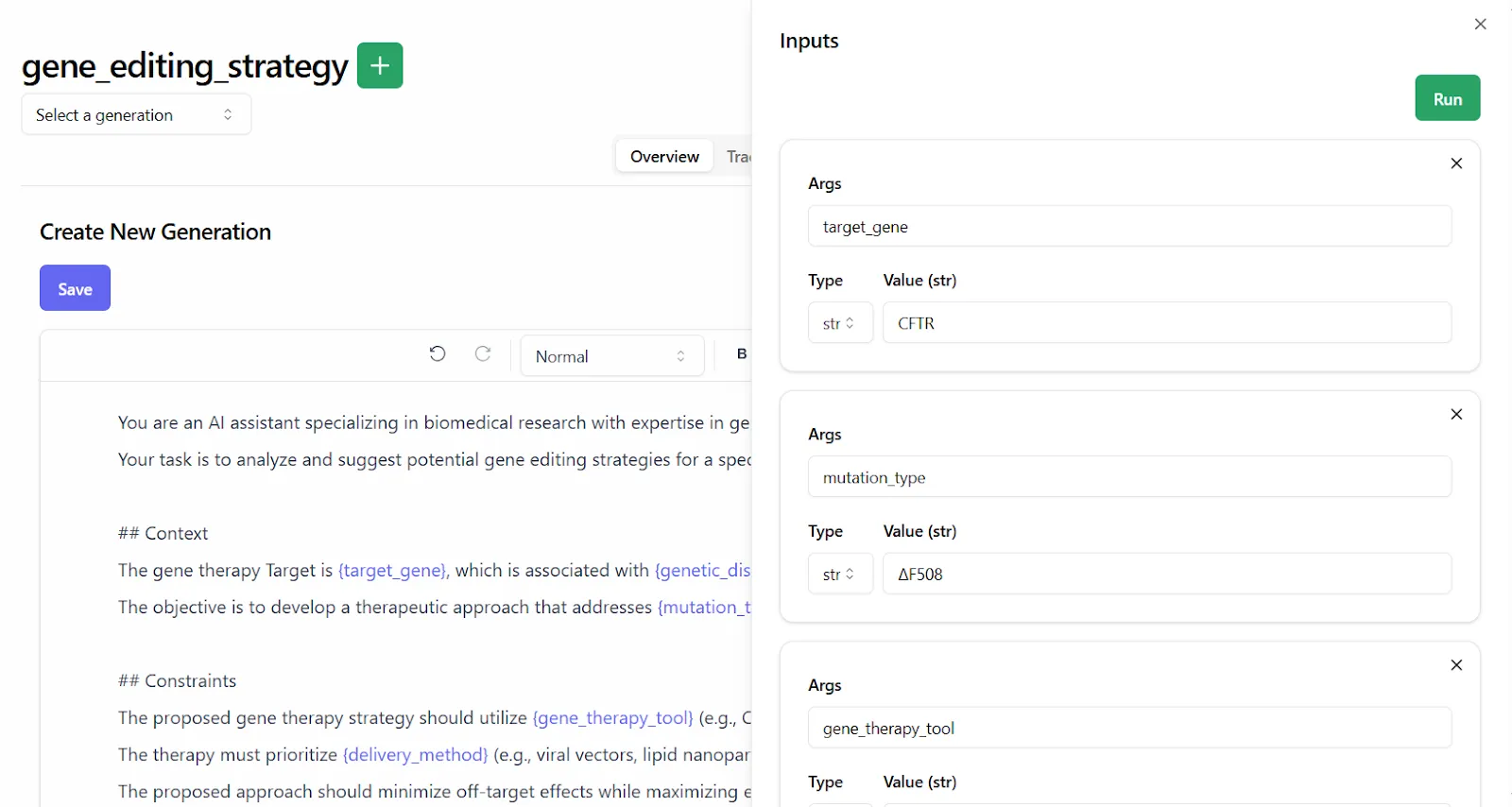
The Playground’s no-code dashboard gives full visibility into each step of your prompt engineering workflow. Everything is versioned, traceable, and easy to review.
The playground shows:
* Prompt templates (in markdown), alongside their corresponding Python functions
* LLM outputs, paired with full trace data
* Call settings like provider, model, and temperature
* Metadata such as cost, token usage, and latency
Lilypad also uses the [OpenTelemetry Gen AI spec](https://opentelemetry.io/) to trace every call made by a generation. This is important for debugging and improving complex workflows, as you can get to see precisely what was asked, how it was asked, and what was returned:

### Evaluation of LLM Outputs by (Non-Technical) Domain Experts
Once your outputs are versioned and traceable, the next step is evaluation. In Lilypad, domain experts can review structured outputs directly in the playground using a simple pass/fail system.
Instead of [rating quality](/blog/llm-evaluation/) with vague 1–5 scores or subjective rubrics, Lilypad encourages reviewers to ask one question: *Is this output good enough for production use?* If yes, it’s a pass. If not, it’s a fail, with optional feedback explaining why:

We recommend manually labeling outputs as much as possible early in a project. And since each label is tied to a specific versioned output, you get clean, reliable training data for automating future evaluations.
When using [LLM-as-a-judge](/blog/llm-as-judge/) (a feature we intend to launch in the near future), we still recommend keeping a human in the loop for final verification, as judges can sometimes struggle with or lack confidence in certain tasks.
To get started with Lilypad, sign up for the [playground](https://app.lilypad.so/) using your GitHub account. From there, you can start tracing and versioning your LLM functions with just a few lines of code.
## Generate Structured Outputs with Ease and Consistency
Mirascope’s integration with Pydantic and its use of Pythonic conventions make it easy to define structured outputs, and simplifies [LLM integration](/blog/llm-integration/) without requiring new abstractions or complex frameworks.
Paired with Lilypad, you get automatic versioning, better [prompt evaluation](/blog/prompt-evaluation/) workflows, and traceable outputs across iterations.
Want to learn more? You can find Lilypad’s code samples on both our [documentation site](/docs/lilypad) and on [GitHub](https://github.com/mirascope/lilypad). Lilypad also supports [Mirascope](https://github.com/mirascope/mirascope/), our lightweight toolkit for building AI agents.
LangChain Structured Outputs: A Guide to Tools and Methods
2025-06-30 · 10 min read · By William Bakst