Prompt testing frameworks show how well your prompts are performing across different inputs, models, or settings within an [LLM application](/blog/llm-applications).
While prompt engineering is about creating prompts to get better results from language models, prompt testing is about checking those prompts in a clear and repeatable way to make sure they still work, even when things change.
With the right testing framework, you can:
* Define and automate test cases for your prompts
* Compare results across models or prompt versions
* Apply pass/fail logic using rules, LLM-as-a-judge, or human review
* Track prompt behavior and catch regressions early to improve quality
These tasks have traditionally been difficult to do reliably, largely because LLM outputs are subjective and non-deterministic. As a result, the same prompt can produce different results, and there often isn’t a single “right” answer to test against.
Also, human judgment can be inconsistent, biased, or too slow for iterating quickly. And if you’re not tracking the surrounding context as well as the prompt itself, **it becomes very hard to isolate why performance changes or degrades**.
In this article, we discuss what to consider in a prompt testing framework and share some of the top options, starting with our open-source platform, [Lilypad](/docs/lilypad), which helps you structure tests so you can iterate, compare, and optimize prompts at scale.
## What to Look for in a Prompt Testing Framework
At a minimum, a prompt testing framework should let you:
* Run structured tests across multiple prompts, models, or inputs to cover a wide range of scenarios in [prompt optimization](/blog/prompt-optimization).
* Integrate with CI/CD pipelines to make prompt evaluation part of your regular development workflow.
* Support human evaluation workflows by allowing reviewers to label, score, or annotate outputs.
* Version prompts so each test run captures the exact context in which it was executed.
* Support collaboration by making it easy for non-technical users to experiment with prompts without touching the codebase.
* Log requests and responses along with standard telemetry/performance key metrics like token counts, latency, costs, and error rates of LLM interactions.
Advanced frameworks offer a few more features:
* **Capture full LLM context,** not just the prompt and output, but every parameter, nested span, and intermediate step that influenced the result, following [OpenTelemetry GenAI](https://opentelemetry.io/) standards, for example.
* **Automatically version prompts and their context** so every test result is tied to the exact version that produced it, without manual saves.
* **Enable A/B testing and experimentation**, letting you compare prompts or models side by side to see which performs better.
* **Keep your prompts together with your code** archiving prompts separately, to ensure you're testing exactly what runs in production, making debugging and tracing much easier.
Many [LLM frameworks](/blog/llm-frameworks) for testing prompts handle the basics, but few combine these capabilities into something scalable and easy to use across teams. In the next section, we’ll look at the most notable frameworks, starting with Lilypad, which we designed with these priorities in mind.
## 6 Leading Frameworks for Testing Prompts
### 1. Lilypad: Full-Context Prompt Testing, Versioning, and Collaboration
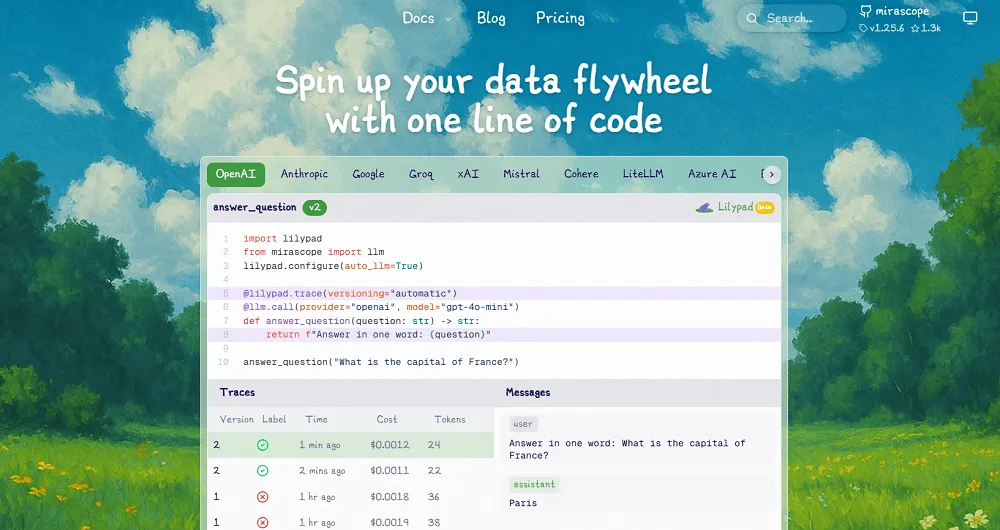
[Lilypad](/docs/lilypad) is built around the idea that prompt quality isn’t only about the instruction, but everything that affects it, including the code, the model you’re using, `temperature`, `top_p`, and others.
Rather than treating prompts as isolated text blocks, Lilypad encourages you to encapsulate everything that affects an LLM's behavior into a single Python function. This approach makes prompt design part of your overall [LLM integration](/blog/llm-integration), so you capture not only the outputs but the full context, making it easier to understand why results change, compare versions, and improve over time.
Lilypad is open source and works with any model provider, and you can run it either in the cloud or [self-host](/docs/lilypad/getting-started/self-hosting) (Docker, PostgreSQL, and Python) it, with no vendor lock-in.
#### Tracks and Versions your Testing Workflow
Before you can start tracing, you configure Lilypad with your project details. By calling `lilypad.configure()`, you enable automatic tracing at the API level. This logs key metadata such as inputs, outputs, token usage, and costs, so you always have a reliable footprint of your calls.
Then, by adding the @lilypad.trace(versioning="automatic") decorator to the Python functions containing your calls, Lilypad automatically versions and tracks all changes occurring within the function’s closure, without you needing to manually save or label anything.
Both the command and the decorator give you the raw API observability and the structured view of where and why each function and call was invoked, letting you run controlled tests, compare results, and optimize over time based on performance.
```python
from google.genai import Client
import lilypad
lilypad.configure(auto_llm=True) # [!code highlight]
client = Client()
@lilypad.trace(versioning="automatic") # [!code highlight]
def answer_question(question: str) -> str | None:
response = client.models.generate_content(
model="gemini-2.0-flash-001",
contents=f"Answer this question: {question}",
)
return response.text
response = answer_question("What is the capital of France?") # automatically versioned
print(response)
# > The capital of France is Paris.
```
Each trace is directly tied to the exact code that produced it, so you can always see what code ran, what inputs it used, and what output it returned.
Every function is captured as a full snapshot of its inputs, outputs, model details, token usage, latency, and cost, instrumented via the OpenTelemetry GenAI spec, which also records surrounding context like messages, warnings, and other useful metadata.
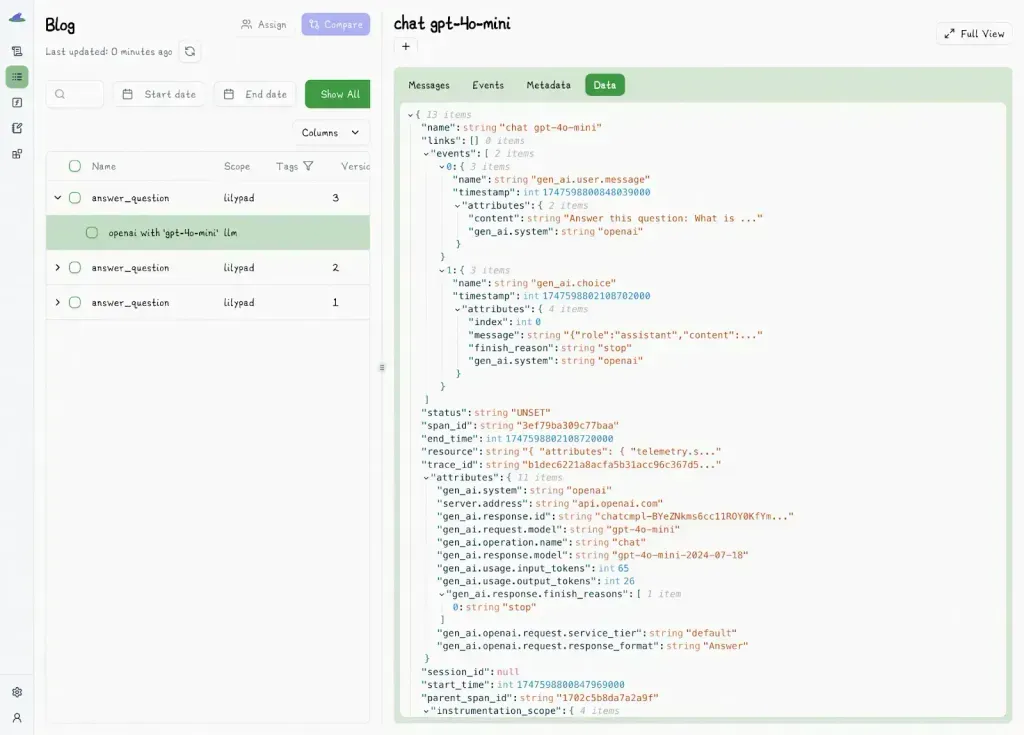
This guarantees you can reproduce any test run exactly, even months later, making it significantly easier to investigate regressions or failures.
Developers can access specific versions downstream by using the `.version` command. This gives them the ability to re-run a specific state of their code to compare outputs (e.g., for A/B testing), track changes, or reproduce earlier results:
```python
response = answer_question.version(3)("What is the capital of France?")
```
See [Lilypad’s documentation](/docs/lilypad) for similarly useful prompt management commands.
#### Prompt Management and Collaboration
Prompt iteration is often tied to code deployment, but it’s not a developer-only concern. Subject matter experts bring the domain knowledge needed to shape a prompt’s framing, specificity, tone, and constraints, all of which directly affect prompt quality.
Lilypad’s visual no-code playground allows engineers and non-technical collaborators to work together, with domain experts editing and testing prompts, tracking results, and exploring prompt variations without needing to touch the underlying code.
This lets engineers, in turn, focus on infrastructure and the logic of AI applications.
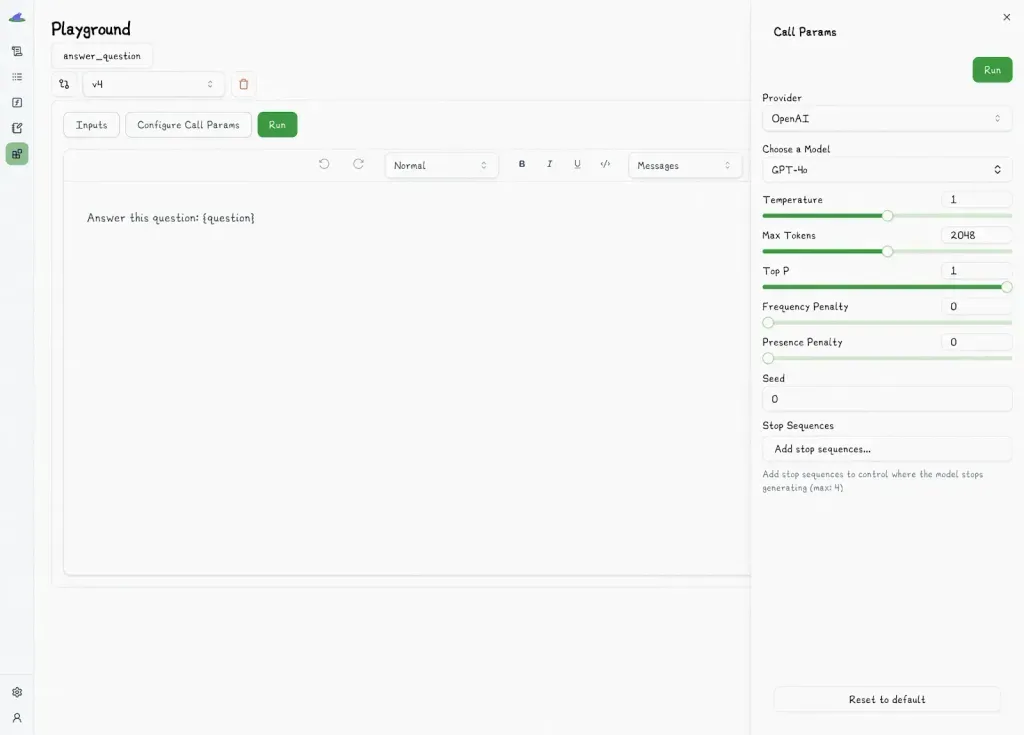
The functional separation of concerns doesn’t change how prompts are stored or deployed. In Lilypad, everything stays in one place, and your prompts are a part of your code and not pulled in from an external system.
This contrasts with other platforms like Langsmith (which works together with LangChain) that effectively separate prompts from code. This decouples logic and parameters, making it harder to trace which prompt version produced a given output. It also means your workflow depends on an external system, which, if it goes down, so does your testing. But this wouldn't be the case with Lilypad.
*See our latest article on [Langsmith alternatives](/blog/langsmith-alternatives)*.
In the playground, you can also edit markdown-supported prompt templates and prompt metadata. Lilypad then automatically generates type-safe function signatures so test inputs always match the function schema, reducing the risk of injection bugs or mismatched formats.
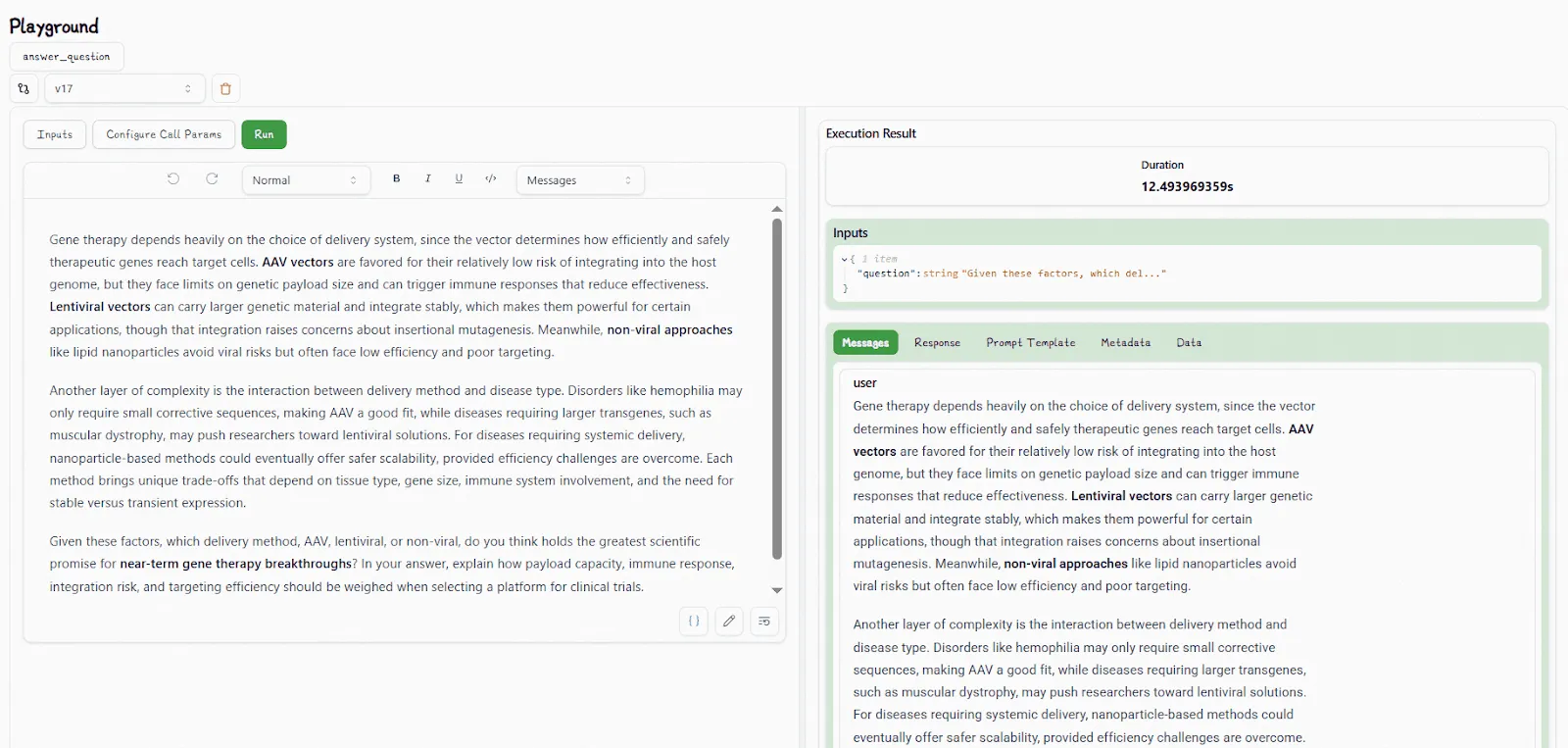
All changes in the playground are sandboxed by default, so they won’t touch production until they’re reviewed and explicitly synced by an engineer.
And because prompts are part of the function logic, they stay in sync across all environments: development, staging, and production, removing the risk of config files going out of sync or prompt variants breaking in production, even when used in more complex workflows like [prompt chaining](/blog/prompt-chaining).
#### Testing Prompt Quality Through Evaluations
Traditional unit tests expect consistent outputs, but large language models don’t work that way; their responses can vary run to run. That’s why prompt testing often goes hand in hand with [LLM observability](/blog/llm-observability), giving you the visibility to understand and measure this non-determinism.
With Lilypad, the focus isn’t on checking for exact matches. Instead, a [prompt evaluation](/blog/prompt-evaluation) asks: *Does the output meet the intended criteria?* In practice, that means looking at whether results are more useful, relevant, and consistent than before, even if the exact wording changes.
Some frameworks approach this by splitting tests into categories (e.g., scoring accuracy, tone, and relevance separately) or using star ratings (e.g., 1-5), but these methods are often subjective and harder to interpret, since you can’t exactly tell what a “3 in tone” or a “2 in relevance” means.
Lilypad takes a more straightforward approach. It lets you mark an output with a simple pass/fail verdict: “Pass” means the prompt aligns with your defined standards, and “Fail” means it doesn't.
This contrasts with frameworks that rely heavily on predefined datasets to use their full functionality, Lilypad lets you evaluate prompts organically as you build.
You don’t have to stop and formalize your test set before you learn what “good” even looks like. Instead, you test variations as you go, marking what works or doesn’t. This keeps your testing process lightweight and iterative, which is especially useful in early-stage development.
To keep your tests meaningful, the Lilypad UI also lets you leave comments explaining why a test passed or failed.
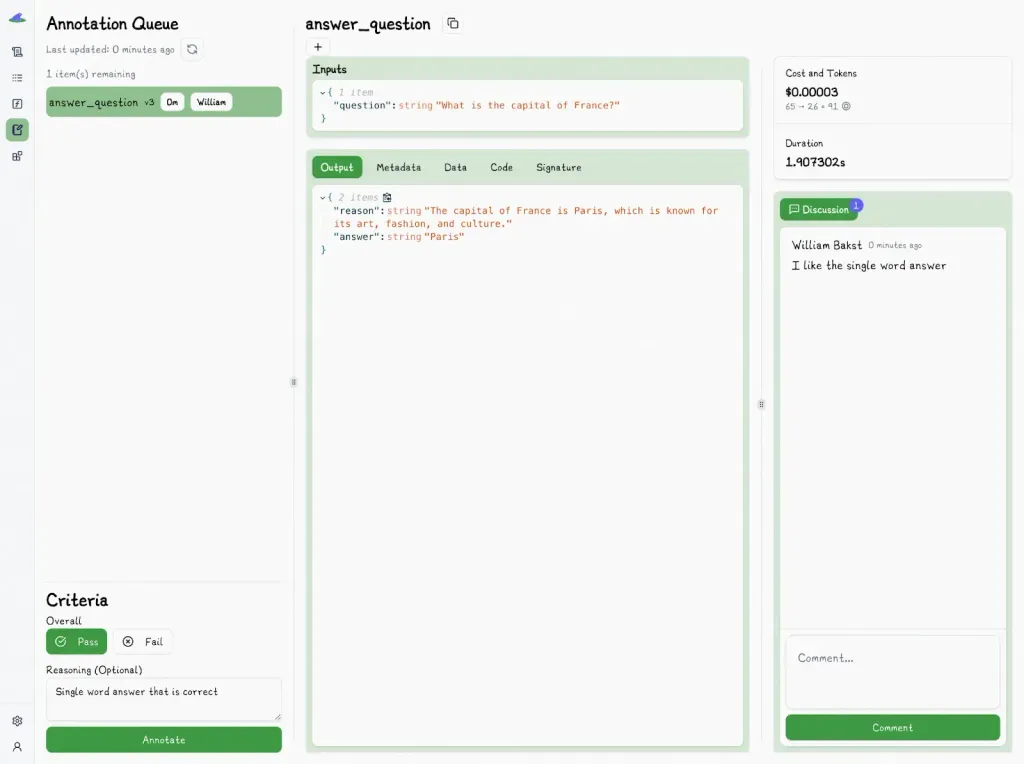
Each annotation is tied to a specific trace, so every time you test a prompt, you also capture the full context of how it ran. That way, teammates can review the run in detail and discuss improvements with all the necessary information at hand.
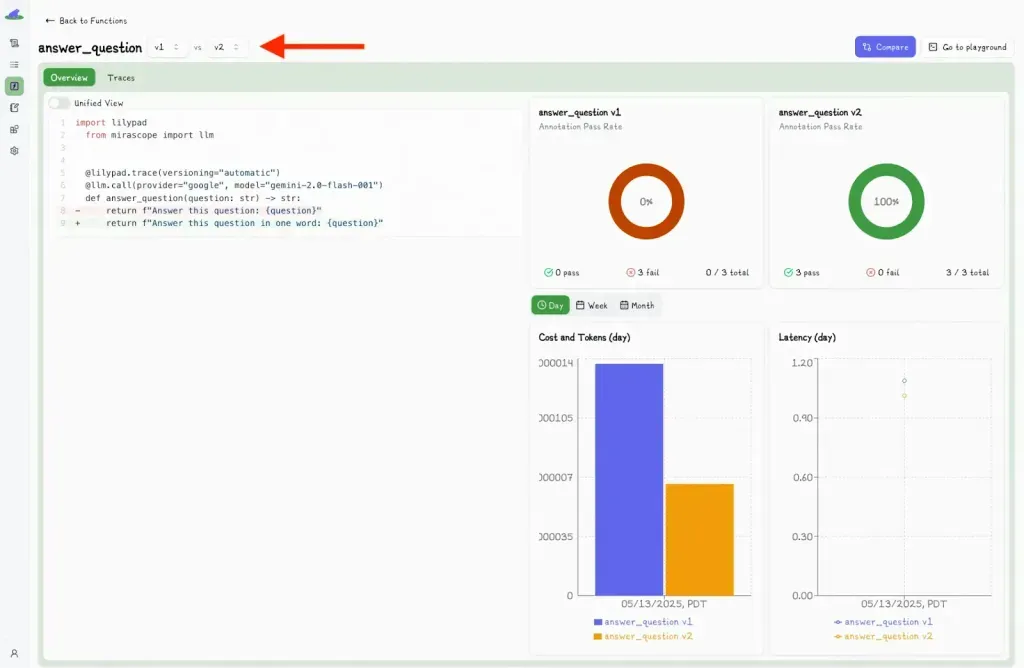
You can also compare different versions by clicking the “Compare” button:
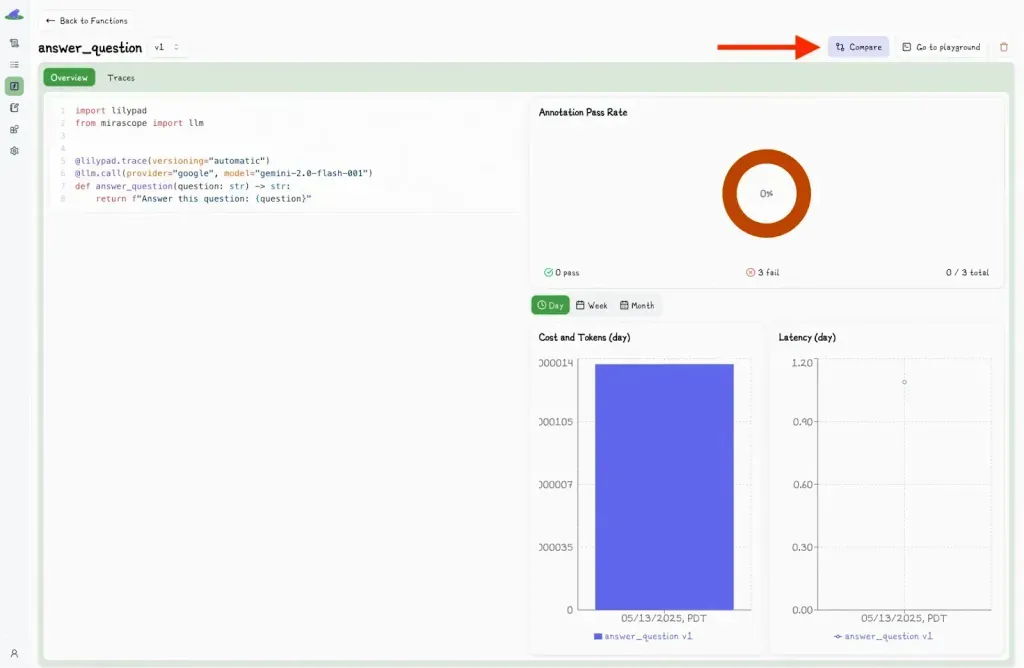
This toggles a second dropdown menu, where you can select another version and view the differences side-by-side.
Developers can also add annotations directly in code by setting `mode="wrap"` in the `@lilypad.trace decorator`. The function’s return value then becomes a special object that still includes the output, but also lets you add annotations with `.annotate()`.
```python
from google.genai import Client
import lilypad
client = Client()
lilypad.configure()
@lilypad.trace(name="Answer Question", versioning="automatic", mode="wrap") # [!code highlight]
def answer_question(question: str) -> str | None:
response = client.models.generate_content(
model="gemini-2.0-flash-001",
contents=f"Answer this question: {question}",
)
return response.text
trace: lilypad.Trace[str | None] = answer_question("What is the capital of France?")
print(trace.response) # original response
# > The capital of France is Paris.
annotation = lilypad.Annotation( # [!code highlight]
label="pass", # [!code highlight]
reasoning="The answer was correct", # [!code highlight]
data=None, # [!code highlight]
type=None, # [!code highlight]
) # [!code highlight]
trace.annotate(annotation) # [!code highlight]
```
This allows for automated testing, scripted evals, and CI/CD workflows without needing to switch to the Lilypad UI.
We generally recommend building a dataset of annotated traces, ideally curated by domain experts. These annotations form a living record of what worked, why it worked, and where prompts fell short.
Over time, that history of labels, examples, and explanations not only improves prompt quality but also lays the groundwork for using [LLM-as-a-judge](/blog/llm-as-judge).
While we’re actively working to make this feature available in Lilypad, we still recommend keeping a human in the loop to catch edge cases a model might miss and ensure automated judgments align with real-world quality standards.
You can [**sign up for Lilypad**](https://lilypad.mirascope.com/) using your GitHub account and get started with tracing and versioning LLM calls with only a few lines of code.
### 2. PromptLayer: Middleware for Logging and Ranking Prompts
[PromptLayer](https://www.promptlayer.com/) is a closed-source devtool for LLM applications that acts as middleware around your OpenAI API calls, logging every prompt and response along with metadata. It provides a web dashboard where you can search and explore your prompt history, compare prompt templates, and manage versions.
In practice, you add PromptLayer to your code and it records each query, saving prompts, completions, and parameters for later analysis. You can also assign numeric values (0, 100) or user feedback to each completion (via thumbs-up/down). PromptLayer then ranks prompts by their average score, cost, or usage, helping identify which prompt versions perform best.
That said, PromptLayer separates prompt management from your codebase. Users often struggle to keep local changes, production prompts, and team feedback in sync, especially when working with subject matter experts. Versioning, in particular, isn’t built-in; you’ll need to set that up yourself. With Lilypad, version history is automatic and tied to your evaluations, so you don’t lose track of how prompts evolved or which changes actually moved the needle.
### 3. Promptfoo: Stress-Test and Red-Team AI Applications
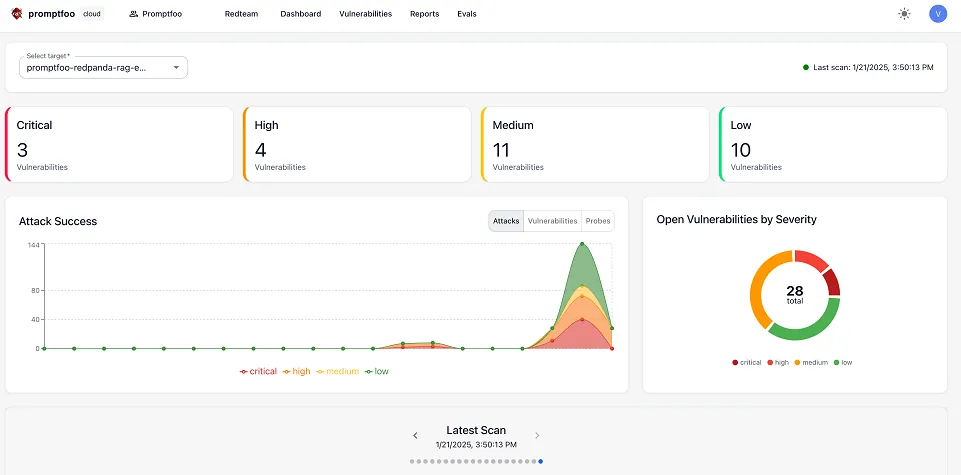
[Promptfoo](https://www.promptfoo.dev/) is open-source and lets you test and refine LLM applications without relying on trial-and-error. It runs entirely on your local machine, keeping prompts private while letting you run automated evaluations, compare different models side-by-side, and stress-test AI systems through red-teaming and vulnerability scanning.
Because it works with any LLM API or programming language, Promptfoo fits neatly into most workflows and can integrate with CI/CD pipelines to automate checks before deployment. Features like live reload, caching, and flexible configuration make iteration fast, while its metrics-driven approach helps teams choose prompts and AI models based on real performance data instead of guesswork.
### 4. LangSmith: Dataset-Centered Prompt Testing and Evaluation
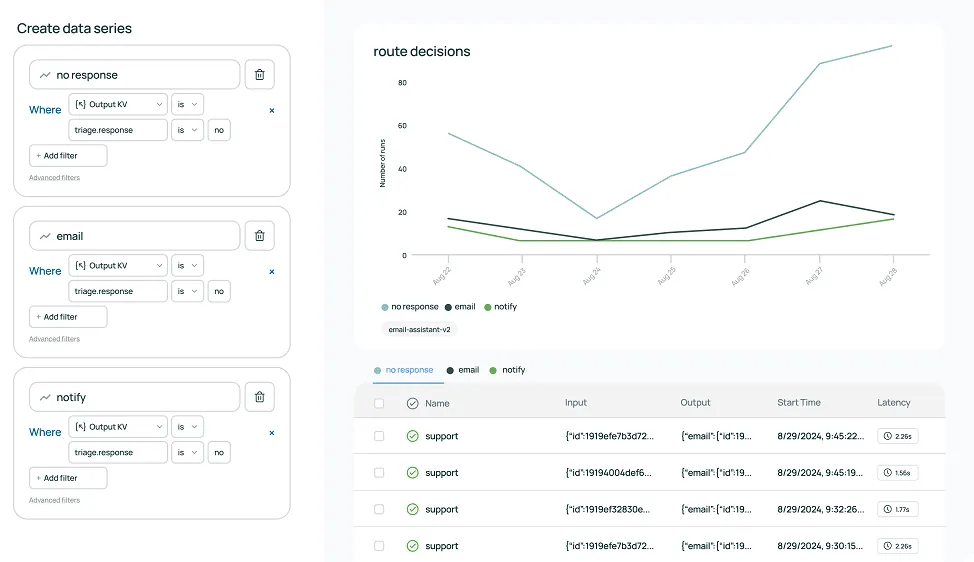
[LangSmith](https://www.langchain.com/langsmith) is closed-source and part of the LangChain ecosystem, and provides end-to-end tracing of agent and prompt executions. It allows you to find failures by stepping through each LLM call and tool action. For prompt testing, LangSmith lets you save real or synthetic usage traces as evaluation datasets and then score the responses.
[LangSmith prompt management](/blog/langsmith-prompt-management) also gives teams a central place to version, edit, and experiment with prompts, making it easier to track changes and collaborate.
While LangSmith’s evaluation flow is usually built around datasets, giving you consistency, repeatability, and clear benchmarks, you don’t always need one. For structured experiments and batch testing, creating a dataset is required, but in production monitoring or quick ad hoc checks, you can evaluate prompts without formalizing a dataset or test suite first.
You can also run automated eval pipelines where large language models (like GPT-5) act as a judge, or collect human feedback on outputs, to measure response relevance, correctness, or safety. Its web UI also includes a prompt playground and a prompt canvas, where you can experiment with different prompt versions and compare outputs side-by-side. Teammates can collaboratively edit prompts, run them against AI models, and view differences in completion quality across prompt variants.
### 5. Helicone: Open-Source Prompt Testing with Production Data
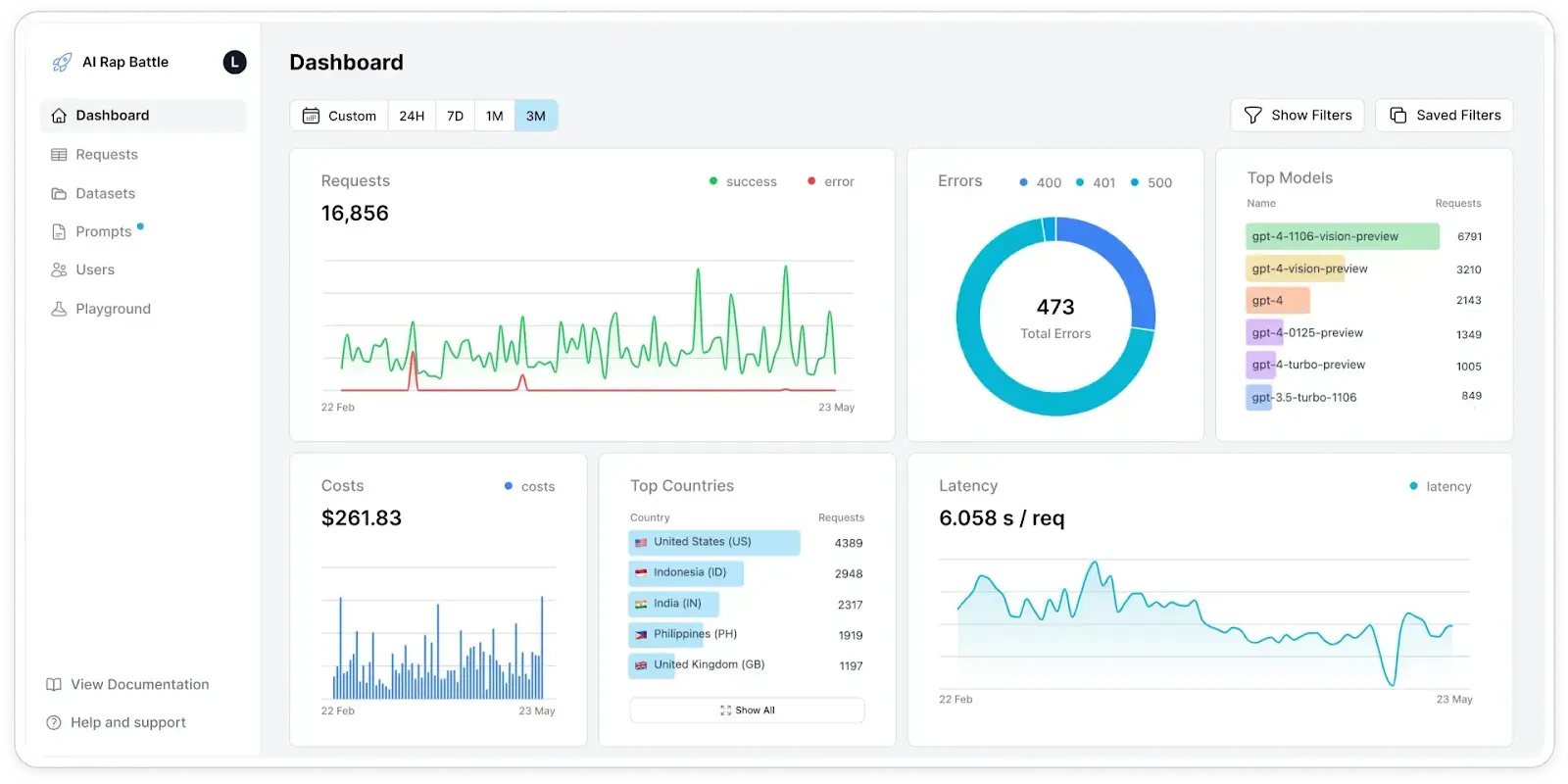
[Helicone](https://www.helicone.ai/) is open-source and lets you run controlled prompt experiments against real production data, compare results, and catch regressions before they reach users. You can track and version every prompt change directly from your code, roll back when needed, and evaluate outputs for an automated test using either LLM-as-a-judge or custom evaluators written in Python or TypeScript.
Beyond testing, Helicone gives you real-time visibility into API usage, costs, and performance, so issues with AI systems can be spotted early. It also supports capturing user feedback to guide refinements, visualizing multi-prompt workflows for easier debugging, and optimizing prompts through features like templates, caching, and random sampling of production data.
Integration is lightweight, often just a single line of code, making it simple to start improving quality without overhauling your existing setup.
### 6. Opik: From Development to Production with LLM Trace Logging
[Opik](https://www.comet.com/site/products/opik/) (by Comet) is an open-source platform for logging, inspecting, and evaluating LLM traces through development and production. It helps teams catch and fix issues early by recording each LLM call, along with its inputs, outputs, and metadata, and then providing tools to score and compare results in AI systems over time.
In development, Opik supports multiple ways to capture traces (SDKs, Python decorators, or integrations) and lets you annotate or label them directly in the UI. For evaluation, it offers both LLM-as-a-Judge and heuristic scoring, the ability to store datasets for running test suites, and even pytest integration to compare results between test runs.
Once in production, Opik scales to handle massive volumes and can ingest more than forty million traces per day while providing real-time metrics, scoring, and dashboards so you can monitor prompt performance, track token usage, and spot regressions before they affect users.
## Test Your Prompts with Lilypad
Lilypad automatically records every prompt version and its trace so you can test, compare, and refine over time. This full transparency helps you spot regressions early, avoid repeated mistakes, and steadily build consistent, effective prompts.
Want to learn more? Find Lilypad code samples in both our [docs](/docs/lilypad) and on [GitHub](https://github.com/mirascope/lilypad). Lilypad offers first-class support for [Mirascope](/docs/mirascope), our lightweight toolkit for building [LLM agents](/blog/llm-agents).
6 Top Prompt Testing Frameworks in 2025
2025-09-19 · 7 min read · By William Bakst