Context engineering refers to structuring everything an LLM sees so it provides the right response. This involves curating and sequencing the information that’s sent to the model, a task that goes beyond just writing prompt instructions.
The term was first popularized by [Tobi Lutke](http://x.com/tobi/status/1935533422589399127) and reflects the real problem of how to reliably shape what an LLM sees across its memory, instructions, and retrieved knowledge, since sophisticated prompts alone aren’t enough to ensure accurate and useful outputs.
LLMs are also increasingly driving stateful, tool-using agents and multi-turn assistants requiring effective context management beyond static prompts.
Yet many observability tools still version and reproduce only the prompt itself, along with its instructions, placeholders, and model settings. They don't track other important elements influencing an LLM's output, like input arguments, helper functions, pre-processing logic, etc.
That's why we built [Lilypad](/docs/lilypad), a context engineering framework that versions, traces, and evaluates everything influencing an LLM’s output, not just the prompt, allowing you to reproduce, compare, and improve every input, parameter, and piece of context systematically, rather than through trial and error.
Below, we describe context and prompt engineering side-by-side and discuss what to look for in a context engineering platform. We then present the following five [LLM tools](/blog/llm-tools) for managing and orchestrating context:
1. [Lilypad](#1-lilypad)
2. [LangSmith](#2-langsmith)
3. [LlamaIndex](#3-llamaindex)
4. [PromptLayer](#4-promptlayer)
5. [LangChain](#5-langchain)
## What’s the Difference Between Context Engineering and Prompt Engineering?
Prompt engineering starts with the goal of writing a better prompt. While it can achieve good results for simple use cases, basic prompts often fall apart when consistency, accuracy, or scale are required.
Although we argue elsewhere why we see [context engineering](/blog/context-engineering) as just prompt engineering done right, the distinction lies in how seriously you treat the surrounding variables. Context engineering recognizes that most agentic failures aren’t due to bad model reasoning or insufficient instructions but to noisy, incomplete, or misstructured context, something that run-of-the-mill prompt engineering doesn’t address.
Whereas traditional prompt engineering involves taking a closer look at what you’re telling the model, context engineering means treating the entire context window as a system to be assembled and optimized, and factoring in not just the prompt but also memory, retrievals, tool outputs, and the sequence in which information is presented.
This broader view is important because even small changes (or no changes at all) can lead to different outputs, making reproducibility a major challenge in LLM app development.
To address this, context engineering takes an approach rooted in software development, treating each LLM interaction not as a one-off prompt, but as the output of a fully defined function.
In practice, this means capturing the full scope of what influenced a response rather than just the prompt. By packaging the entire context together, you can trace exactly what happened during a generation, test variations systematically, and roll back to previous versions when needed.
## Examples of Context
When we talk about context, we’re usually referring to:
* **System instructions or a persona**: high-level directives that define the model's role, personality, and constraints. For example, instructing the model to act as a helpful legal assistant specializing in contract review helps anchor its behavior and guides its responses across interactions.
* **User input**: this is the direct question or command provided by the user that triggers the model to generate its response.
* **Short-term and long-term memory**, allowing the model to remember recent exchanges and persist key facts or preferences across sessions so that its behavior remains coherent and consistent.
* Short-term memory functions like a conversation buffer, holding recent exchanges to maintain the coherence of the interaction.
* Long-term memory is more persistent, storing facts, user preferences, or summaries from previous sessions. This is often kept in external storage, such as a vector database, and retrieved when necessary to provide continuity.
* **Retrieved knowledge**, like in retrieval augmented generation (RAG): the use of automation to pull in up-to-date, factual information from external databases or knowledge sources. This helps the model ground its responses and reduces hallucinations.
* **Tool definitions and outputs**: for AI agents that utilize external tools, context includes definitions of available tools (e.g., APIs, search functions, databases), along with their names, descriptions, and parameters. After a tool is called by the model, its output is added back into the context for use in subsequent reasoning steps. This means that even the outputs of tools are an important piece of context engineering.
* **Structured output formats**: defined formats like JSON or XML ensure that the model returns data in a predictable, machine-readable form. This is important for reliably using the outputs in downstream systems.
## What to Look for in a Context Engineering Platform
A context engineering platform provides an [LLM orchestration](/blog/llm-orchestration) layer that manages the dynamic flow of information and tools. Instead of simply dumping all available context into the model, it should control when and how key elements, like memory, retrieved knowledge, and tool outputs, are assembled into the final input going into the LLM.
The goal is to ensure that the right information as described in the previous section is delivered at the right time.
The platform adapts the context in real time, pulling in only the most relevant information for each step of the interaction, ensuring responses remain accurate and grounded without overwhelming the model or exceeding token limits.
A good context engineering platform automatically tracks and versions everything that influences an LLM's output too, not just the prompt text, so you can reproduce past outputs and roll back to previous versions to debug issues, compare performance, and identify which changes improved or degraded results.
You should also be able to trace agent calls and visualize what steps were run to gather the data sent to the LLM in order to capture the full chain of events, like which tools were called, what inputs they received, what outputs they produced, and how those outputs were transformed before reaching the model.
This allows you to pinpoint where errors or inefficiencies occurred, such as a retrieval step returning irrelevant documents or a preprocessing function dropping key context.
Tracing provides visibility into latency and cost in tokens at each step, helping developers not only do [prompt optimization](/blog/prompt-optimization) but also improve their entire pipeline around it.
It's also important that the platform offer strong evaluation systems to measure how well responses align with expectations, allowing you to assess how well memory is applied, whether the system maintains consistency over time, and how effective prompts are.
## Five Context Engineering Platforms for Teams Building Agentic Workflows
### 1. Lilypad
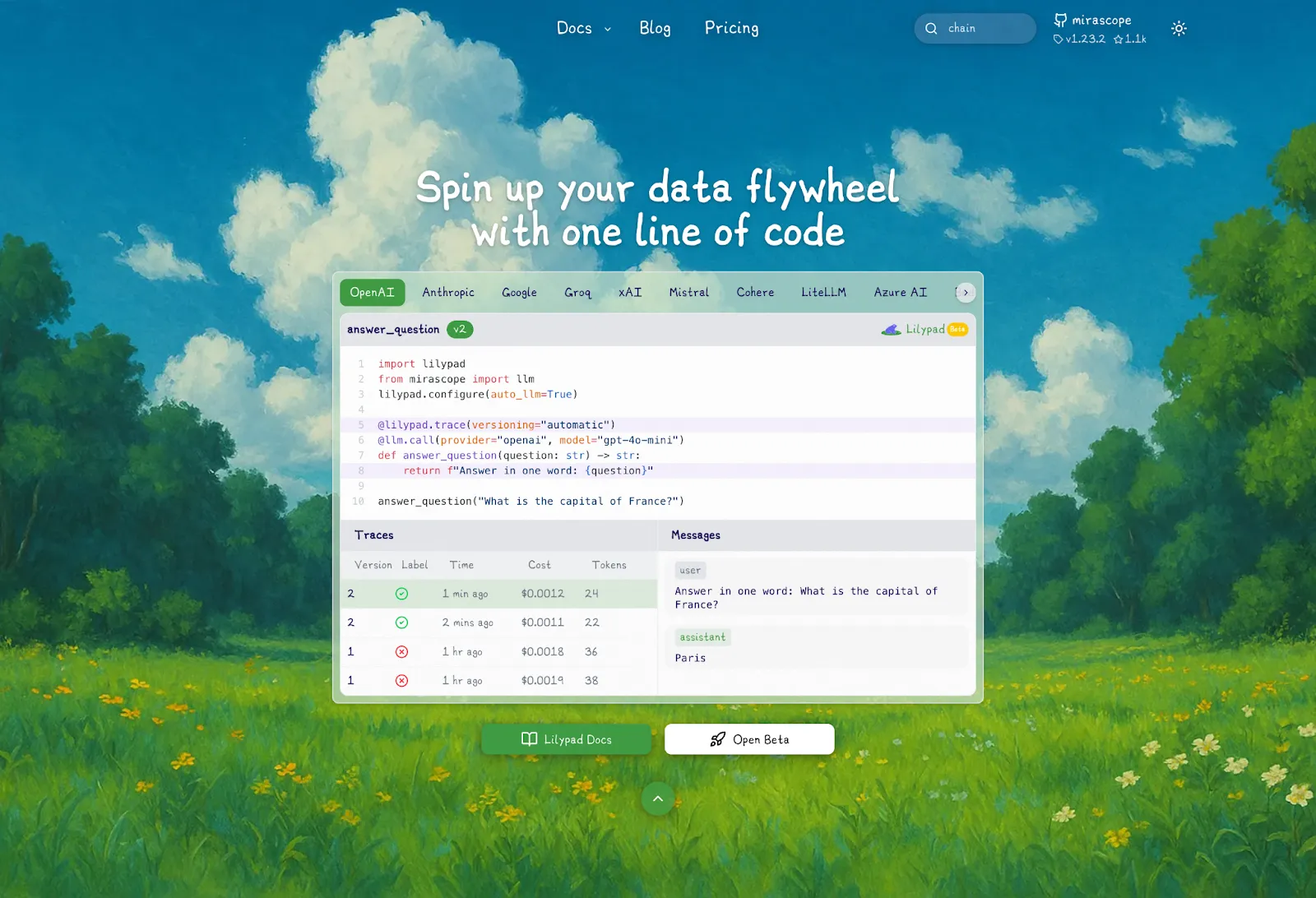
[Lilypad](/docs/lilypad) is an open source context engineering framework that treats LLM interactions like an optimization problem, recognizing that reliable outputs depend on the entire context, not just the prompt.
Consistent with this approach, the platform automatically versions not only the prompt but also other key factors, including any code, parameters, helper functions, preprocessing logic, and anything else that could influence the model’s behavior, ensuring that every output can be traced, reproduced, and compared across versions.
Lilypad also traces every LLM call, capturing inputs, outputs, costs, and latency to give developers complete visibility in analyzing and debugging model outputs.
As a lightweight open source tool, Lilypad integrates with existing workflows and libraries (like LangChain, Mirascope, or direct provider SDKs), making it framework-agnostic. It can also be self-hosted.
Lilypad supports popular models like OpenAI, Google, AWS Bedrock, Anthropic, Azure, and many others.
Below, we highlight how Lilypad helps you manage context in building LLM applications.
#### Structuring and Managing Context
To ensure consistency across iterations, Lilypad encourages developers to organize their code and prompts within Python functions that encapsulate LLM calls.
In this way, every call is treated as a complete software artifact since all elements relevant to a particular call, like user queries, chat history, prompts, model settings, etc., are contained within one versioned function, ensuring each interaction is consistent and reproducible.
For example, below we define a function `answer_question` and decorate it with `@lilypad.trace(versioning="automatic")` to set up tracing with every run, and automatically version everything within the function’s closure whenever a change is made:
```python
import lilypad
from mirascope import llm
lilypad.configure(auto_llm=True) # [!code highlight]
@lilypad.trace(versioning="automatic") # [!code highlight]
@llm.call(provider="openai", model="gpt-4o-mini")
def answer_question(question: str) -> str:
return f"Answer this question in one word: {question}"
response = answer_question("What is the capital of France?")
print(response.content)
# > Paris
```
This provides a snapshot of all that directly influences an LLM call's outcome.
Both Lilypad and Mirascope (for which Lilypad gives first-class support) provide out-of-the box pythonic abstractions for managing the context fed into the prompt.
For example, in the code above, [Mirascope’s `@llm.call` decorator](/docs/v1/learn/calls) turns the prompt function into a call with minimal boilerplate code.
`@llm.call` provides a unified interface for working with model providers like OpenAI, Grok, Google (Gemini/Vertex), Anthropic, and many others, and you can change the provider by changing the values for model and provider in the decorator’s arguments.
This decorator also provides an interface for [tool calling](/docs/v1/learn/tools), [structured outputs and schema](/docs/v1/learn/output_parsers), Pydantic-based input validation, [prompt chaining](/blog/prompt-chaining), type hints (integrated into your IDE), and others.
You can work with prompts and their associated code within the Lilypad UI, a no-code environment that lets non-technical users test, edit, and evaluate prompts while keeping them tied to the exact versioned code that runs in production.
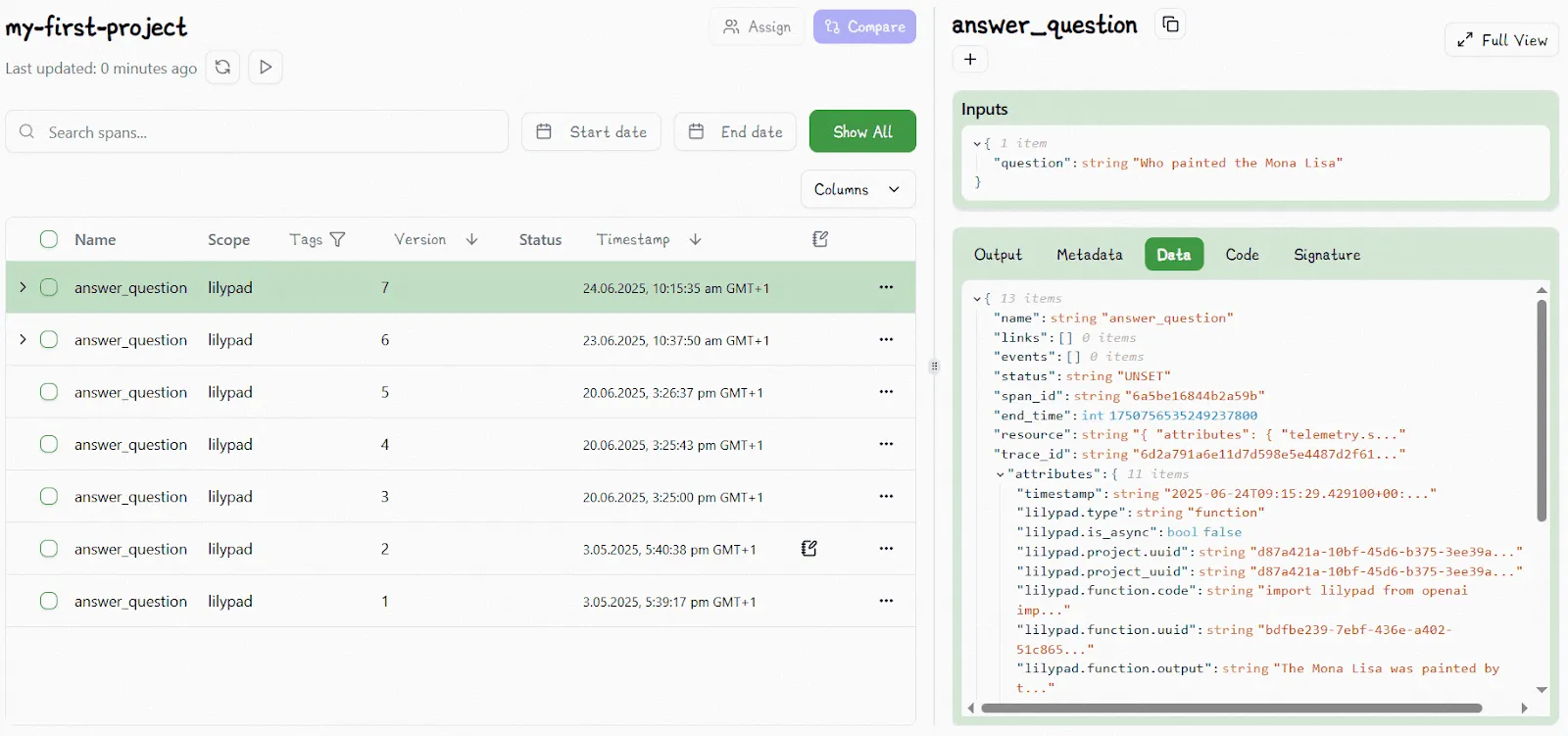
Lilyad uses the [OpenTelemetry Gen AI spec](https://opentelemetry.io/) to instrument calls and their surrounding code, capturing metadata like costs, token usage, latency, messages, warnings, and others.
Lilypad traces LLM calls not only at the level of the API to tell you what the model call did as [LLM call spans](/docs/lilypad/observability/spans), but also at the function level, capturing how your code shaped the call through inputs, logic, and outputs.
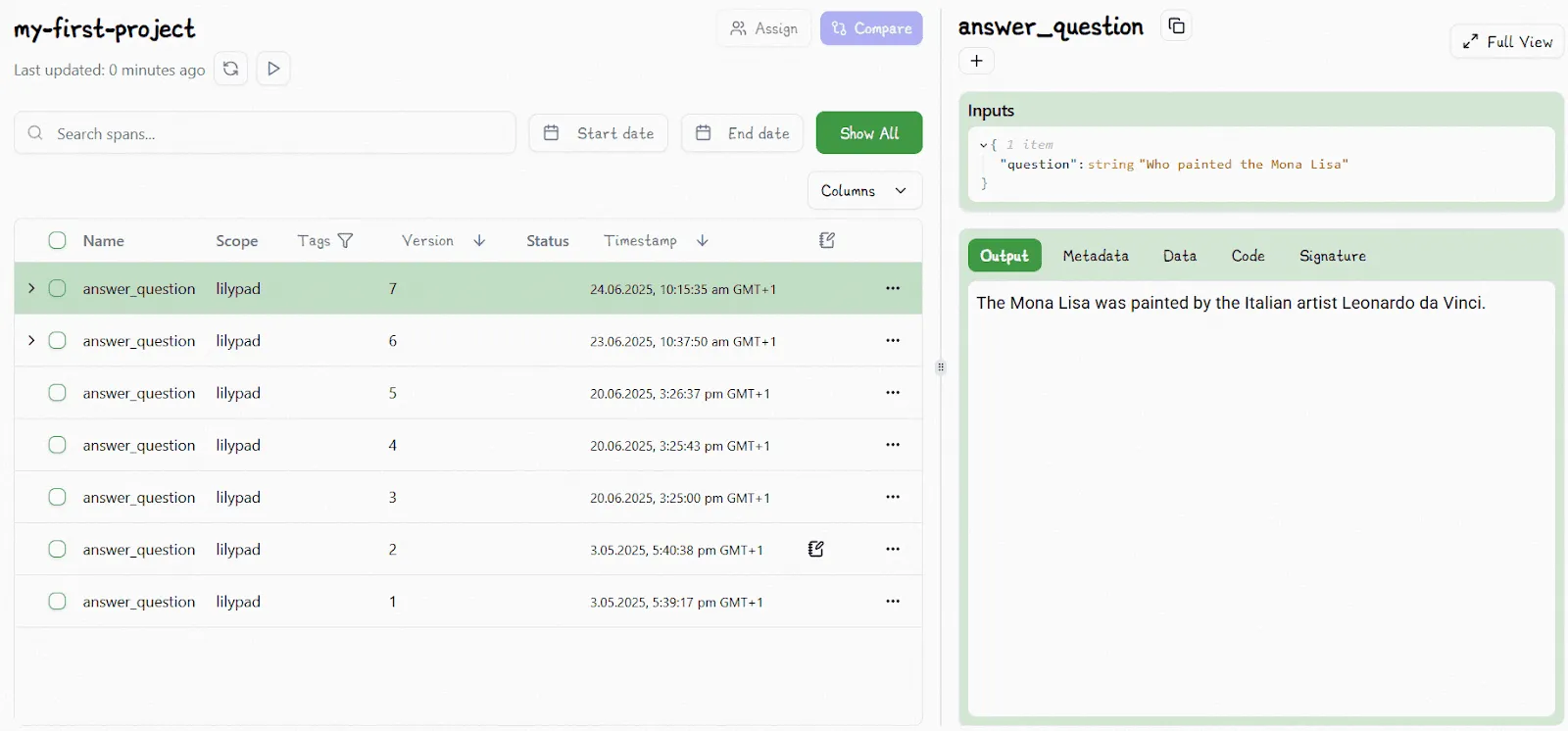
The Lilypad UI also shows the output of every call, as well as any changes made to the prompt or its context:
The UI also lets you easily compare the outputs of different versions:
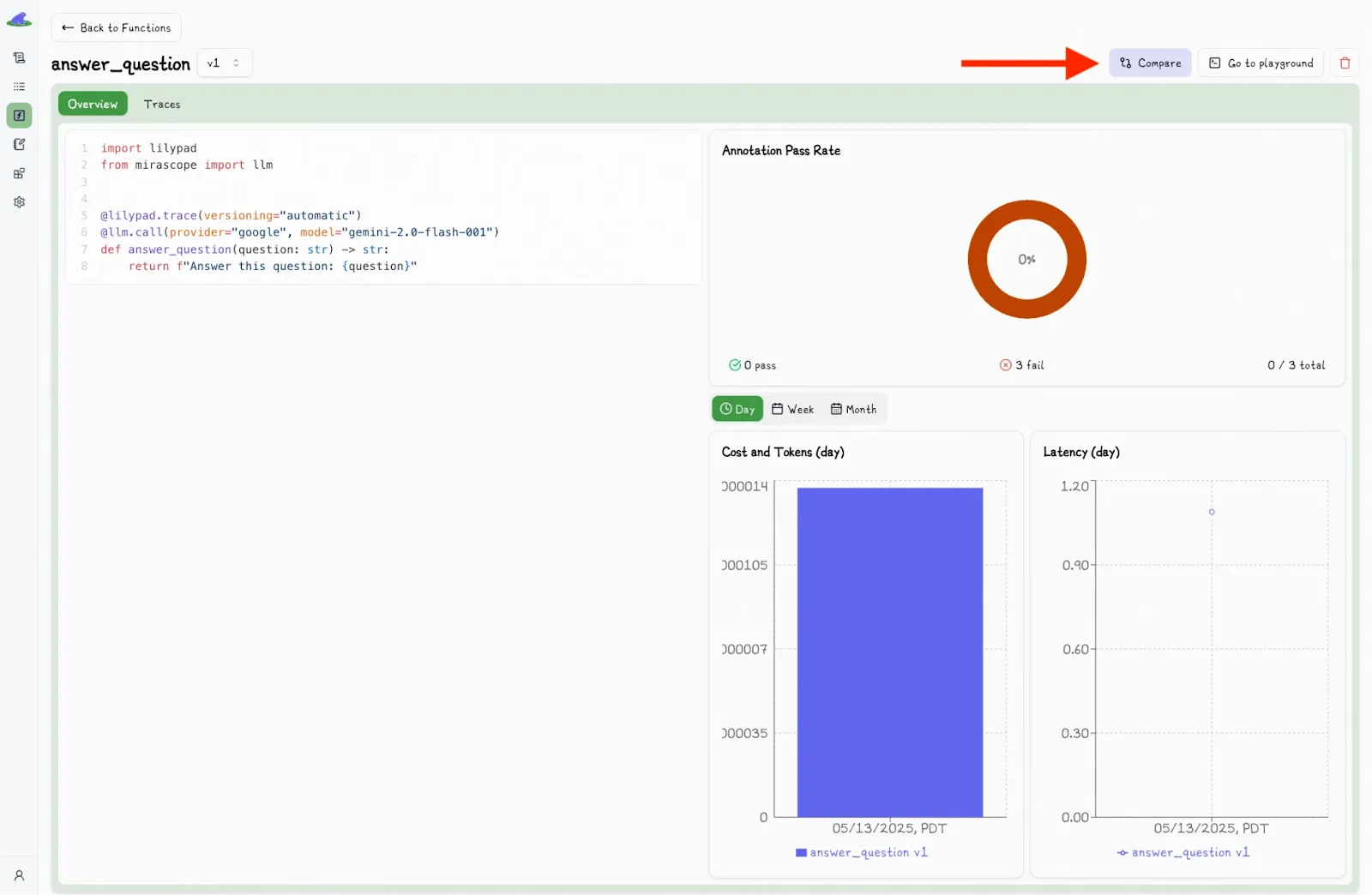
You can select another version and view the differences side-by-side:
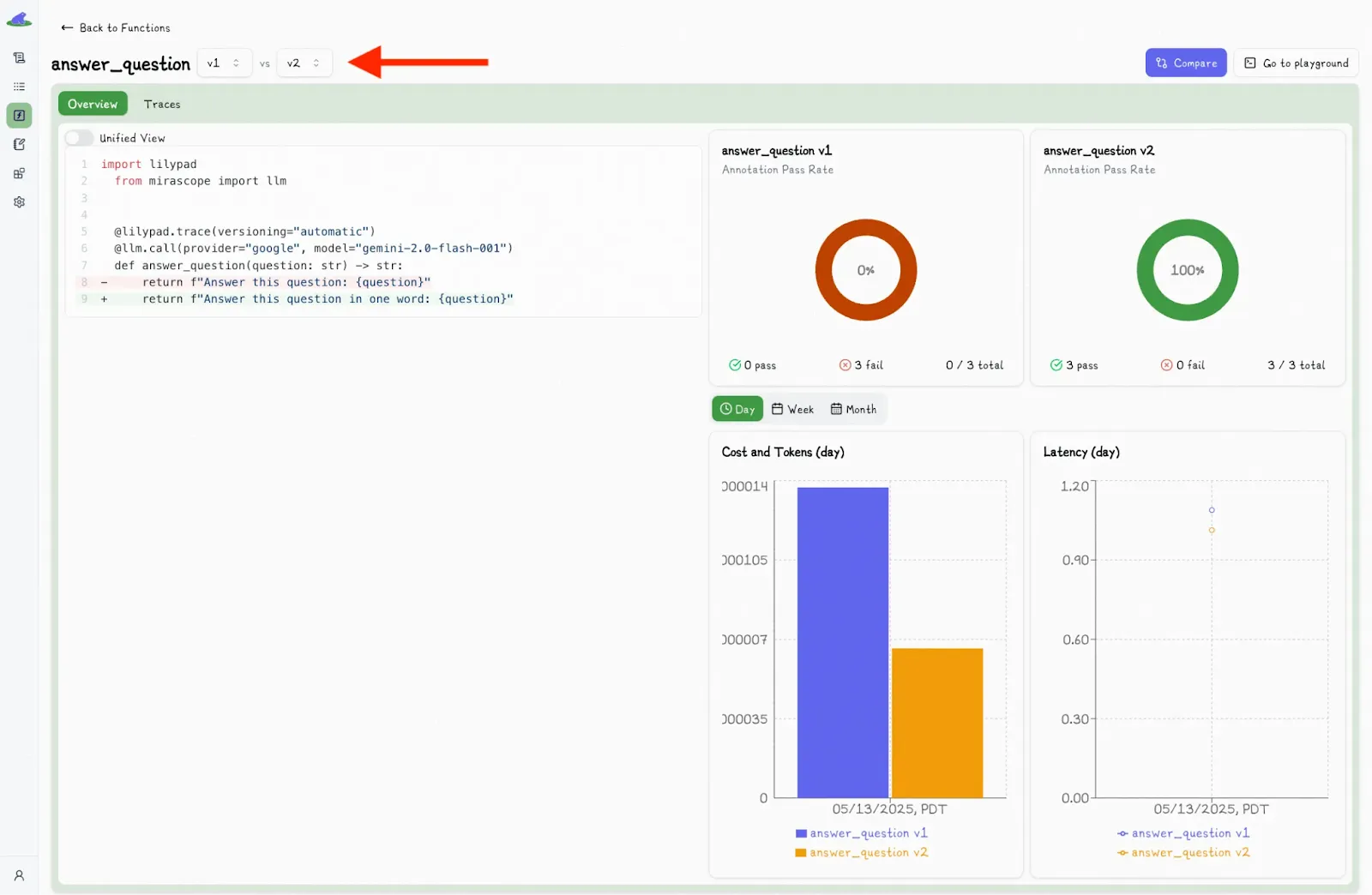
Alongside each call, the UI also shows detailed metadata, like latency, cost, and inputs, giving you full visibility into what happened and what influenced the result.
You can also work with different versions downstream using commands like .version, for example:
```python
response = answer_question.version(4)("What's the capital of France?")
```
This gives you access to much of the same versioning functionality as the Lilypad UI, such as A/B testing for different subsets of users.
#### Editing and Refining Prompts
Lilypad’s playground is a [prompt management tool](/blog/prompt-management-tool) allowing you to create, modify, test, and evaluate prompts without needing to alter the underlying code.
It features Markdown-supported prompt templates with type-safe input variables to ensure that inputs provided in the playground match the associated function's schema (here we’re referring to the Python functions we described in the last section, which also contain the prompt) preventing injection bugs, missing parameters, or incorrect input formats.
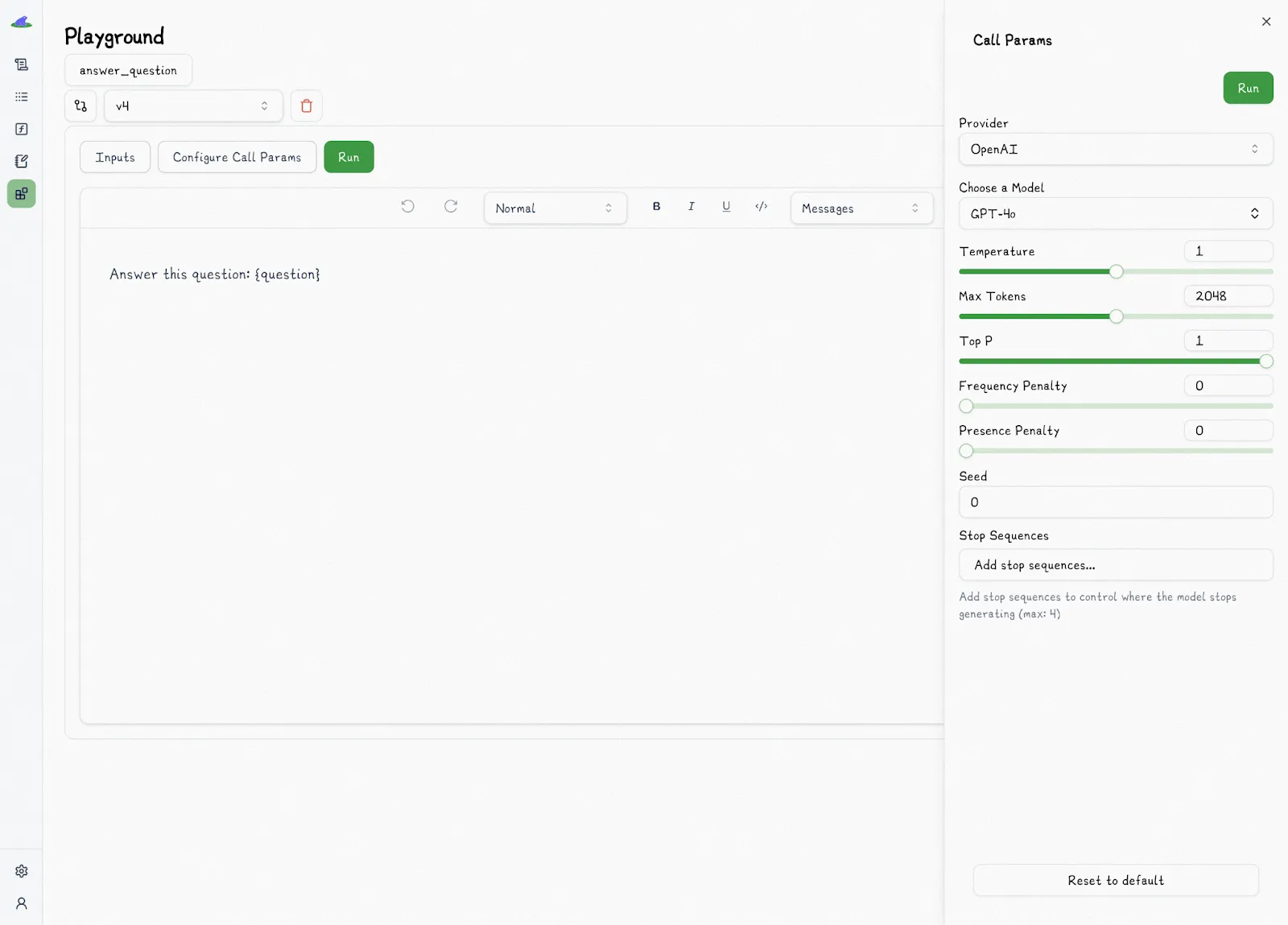
Prompt templates are mapped to Python function signatures for strong typing and reproducibility, and allow users to define call settings like the LLM provider, model, and temperature.
Every time a user runs an [LLM prompt](/blog/llm-prompt) in the UI, Lilypad automatically versions and traces the prompt against the underlying function.
This lets SMEs run prompts and practice [prompt engineering best practices](/blog/prompt-engineering-best-practices) without needing the involvement of developers, who can access prompts and context downstream via methods like `.version` that return type-safe signatures matching the expected arguments.
Other systems treat prompts as standalone assets managed separately from the application code, which developers then have to manually pull downstream to interact with.
Lilypad takes a different approach by versioning prompts as part of the codebase itself, ensuring that what runs in the playground is the same type-safe code developers run downstream in production, eliminating the brittleness of separating prompts from the rest of the system.
#### Evaluating the Quality of Context-Driven Outputs
Over time, running code with automatic [prompt versioning](/blog/prompt-versioning) and tracing builds up real-world datasets that serve as living benchmarks for testing changes, refining prompts, and validating improvements.
To make use of these datasets, Lilypad provides lightweight evaluation tools that turn raw runs into actionable feedback.
These allow users to evaluate runs using a pass or fail labeling system, which provides a clearer, faster, more consistent, and more real-world evaluation of outputs than a granular scoring system that often adds noise without improving insight.
For example, instead of asking evaluators to score a response on a scale of 1 to 5 for relevance or style, which often leads to inconsistent judgments, they can simply decide whether the output is acceptable or not (i.e., Pass or Fail).
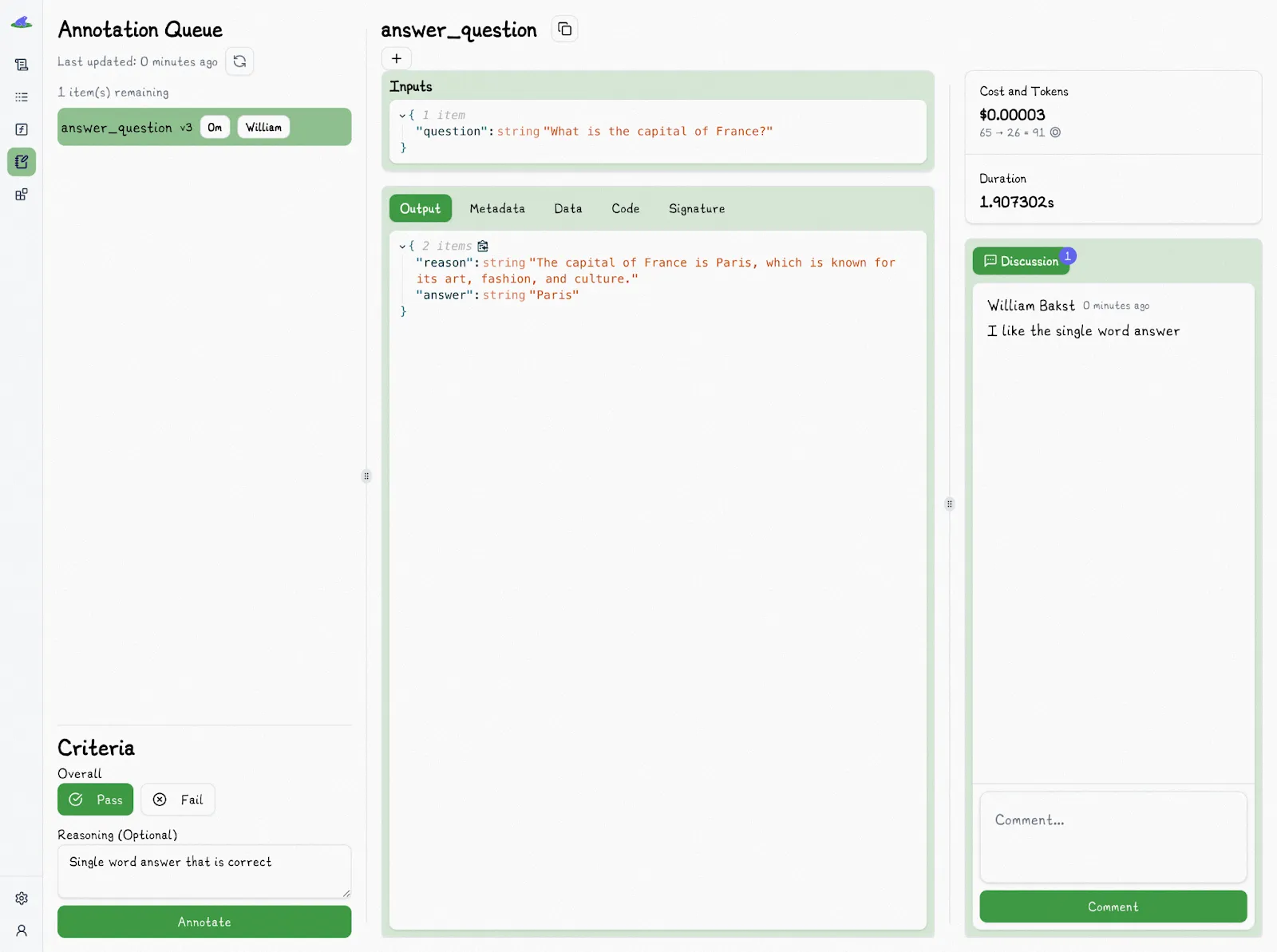
Lilypad also offers features allowing teams to collaborate on evaluations and discuss results, as well as to assign tasks to other users.
As for building datasets, we encourage manual labeling of outputs, especially at the beginning of a project, since human-annotated feedback contributes to high-quality datasets.
The ultimate goal is to transition to semi-automated evaluations using [LLM-as-a-judge](/blog/llm-as-judge), where an LLM proposes labels, and human evaluators ultimately verify or reject these.
This shifts the majority of work for humans from labeling to verification, speeding up the process while keeping humans in the loop for final accuracy verification.
You can [sign up for Lilypad](https://lilypad.mirascope.com/) using your GitHub account and get started with tracing and versioning your LLM calls with only a few lines of code
### 2. LangSmith
[LangSmith](https://www.langchain.com/langsmith) is a closed source observability and evaluation platform built for monitoring, debugging, and testing LLM-powered applications, especially those built with Langchain. It helps developers trace, optimize, and validate the flow of context into language models, ensuring robust agent performance and reliability.
Key features of LangSmith include:
* LLM call tracing and versioning that allows developers to see exactly what context (inputs, tool results, prompt components, retrieved knowledge) is sent to the LLM at each call.
* Evaluation features allowing users to run experiments, compare agent runs with different context strategies, and measure their impact on performance.
* Tool and memory interaction logging for monitoring how agents use external tools and memory, giving insight into RAG flows, dynamic data gathering, and the effectiveness of long- or short-term memory utilization in context assembly.
* Token usage tracking across prompt runs, helping developers optimize context size and fit critical information within model context windows.
### 3. LlamaIndex
[LlamaIndex](https://www.llamaindex.ai/) is a framework designed to orchestrate, manage, and refine retrieved data, chat history, tool outputs, and workflow state to optimize agent and chatbot performance.
LlamaIndex’s features include:
* Dynamic data integration and retrieval for allowing applications to connect LLMs directly to enterprise data sources, databases, documents, and APIs, to enable context-aware information retrieval.
* Workflow-oriented context management for managing short- and long-term memory, prior interactions, as well as dynamic context assembly across agent steps.
* Memory architectures and chat history to support both short-term (e.g., conversation history) and long-term memory (persisted knowledge or histories).
* Event-driven workflows for breaking complex information retrieval and reasoning tasks into orchestrated steps and preventing context overload, while supporting modular context routing based on user intent or workflow needs.
### 4. PromptLayer
[PromptLayer](https://www.promptlayer.com/) provides granular logging, tracking, and management of prompts, input context, and LLM metadata, letting developers analyze and optimize how context is constructed and delivered to language models.
Key features of PromptLayer include:
* Prompt logging and versioning, allowing developers to audit how context and instructions evolve over time. This lets teams identify which context compositions led to successful LLM outputs and refine them systematically.
* Context history tracking for facilitating conversational and multi-turn AI agents. By preserving context from previous turns and enabling its retrieval, PromptLayer supports context engineering workflows that rely on both short- and long-term memory.
* Metadata capture, which stores information about prompt inputs, outputs, and system instructions to provide visibility into all elements that form the context window for LLMs.
* Integration with external tools and functions for allowing developers to manage not only prompt instructions but also dynamic context provided by external data sources or functions.
### 5. LangChain
[LangChain](https://www.langchain.com/) is a framework for building control systems that provide information, instructions, and tools in the right format so that LLMs can effectively accomplish tasks. It allows detailed management of what goes into the LLM's context window and how context is dynamically assembled and maintained across long-running agentic workflows.
Key features of LangChain include:
* Dynamic context assembly for providing information for each step of an app’s trajectory, balancing limited token window capacity with relevant context.
* Tool integration and management for providing external information or actions to supplement an LLM’s capabilities.
* Memory and scratchpads for short-term and longer-term memory management, allowing an app to save and recall contextual data across task steps or multiple sessions.
* LangGraph for fine control over LLM workflows, and for deciding which steps to run, what data is passed, and how outputs are stored.
## Bring Context Engineering Into Your Workflow
Lilypad helps you version, trace, and evaluate every factor that shapes an LLM’s output, allowing you to reproduce results, debug faster, and ensure your applications behave reliably as they grow in complexity.
Want to learn more? Check out Lilypad code samples on our [documentation site](/docs/lilypad) and [GitHub](https://github.com/mirascope/lilypad). Lilypad offers first-class support for [Mirascope](/docs/mirascope), our lightweight toolkit for building AI agents.
Context Engineering Platform: A Guide to Tools, Features, and Benefits
2025-09-27 · 6 min read · By William Bakst