Prompt management helps teams version, evaluate, and track changes to prompts so they can iterate easily when building LLM applications.
In this post, we’ll cover five leading tools, with an in-depth look at our open source framework, [Lilypad](/docs/lilypad).
Lilypad treats prompts like full-fledged code artifacts, versioning not only the text itself but also the logic, model parameters, and structured outputs that shape an LLM’s behavior. This makes it easy to debug behavior, compare outputs, and collaborate across teams while keeping track of what changed and why.
The five prompt management tools we’ll compare are:
1. [Lilypad](#1-lilypad-full-context-prompt-management-for-llm-workflows)
2. [Langsmith](#2-langsmith-prompt-management-inside-the-langchain-ecosystem)
3. [Langfuse](#3-langfuse-open-sourced-control-over-your-prompt-lifecycle)
4. [Agenta](#4-agenta-a-self-hostable-platform-for-versioning-testing-and-evaluating-prompts)
5. [PromptLayer](#5-promptlayer-a-visual-workspace-for-prompt-versioning-and-testing)
## How to Choose a Prompt Management Tool
Anyone who’s worked with stochastic LLMs knows how unpredictable they can be. Even tiny changes in wording can lead to different results that can become impossible to reproduce without proper versioning and tracing.
That’s where prompt management tools come in; they (in some aspects) focus on observability and give teams the structure to organize, track, and improve prompts across their lifecycle.
In this sense, prompt management complements prompt engineering: while engineering is about designing the right inputs to guide LLMs, management ensures those inputs are systematically tested, tracked, and refined over time.
We recommend you look for a tool that:
### Tracks and Versions *Every* Prompt Change
Versioning and tracing allow you to treat prompting like real software development rather than as trial-and-error guesswork because it preserves the history of changes and records what actually happened on each run.
At the very least, a good tool allows you to select and save a given prompt change, which is useful since it lets you run controlled experiments without losing track of what worked before.
But having to manually save changes introduces some friction while ideally you shouldn’t *have* to think about what to save. An advanced tool will just save all your changes automatically while you focus on [prompt optimization](/blog/prompt-optimization).
A strong versioning system also links each prompt to not only metadata like model type, version, and parameters, but also to its surrounding context like the execution flow around the LLM call, its input formatting, and any downstream validation steps. All this creates an auditable trail that supports debugging and compliance.
### Allows Technical and Non-Technical Teams to Collaborate
Having a space where domain experts can separately iterate on prompts without involving developers lets them experiment faster without needing to change or redeploy the code.
Basic requirements for such a space are:
* Clear visibility into prompt history, versions, and related metadata.
* Role-based access control with granular permissions for developer, domain expert, and reviewer roles.
* A no-code editing environment for non-technical users.
* The capability to preview and test prompt changes instantly.
* Support for prompt templates with input variables.
An advanced system also works with existing version control systems like Git or CI/CD pipelines so developers can automate testing and deployment while non-technical contributors safely make updates.
### Enables Systematic Testing, Validation, and Side-by-Side Prompt Comparisons
One of the hardest aspects of [advanced prompt engineering](/blog/advanced-prompt-engineering) is knowing whether a change actually improved performance. This is where a good prompt management tool helps: by making it easy to test, compare, and monitor prompts throughout their lifecycle, teams can reliably identify, improve, and maintain the best-performing prompts.
It provides a live experimentation environment to adjust prompts and instantly see output changes, so you can fine-tune parameters and iterate quickly without redeploying code.
It should also allow you to directly compare outputs from different prompt versions or large language models (especially side-by-side) to identify performance differences to iterate effectively.
Users can then annotate and evaluate outputs accordingly, creating a permanent, searchable feedback history. Validating and labeling outputs in this way also strengthens the dataset for comparing different versions and detecting regressions.
Advanced systems also let users collaboratively evaluate prompts against predefined criteria like relevance, accuracy, consistency, and readability. To make evaluations easier at scale, some tools provide automated scoring and the ability to compare outputs against reference answers.
## Five Leading Tools for Prompt Management
### 1. Lilypad: Full-Context Prompt Management for LLM Workflows
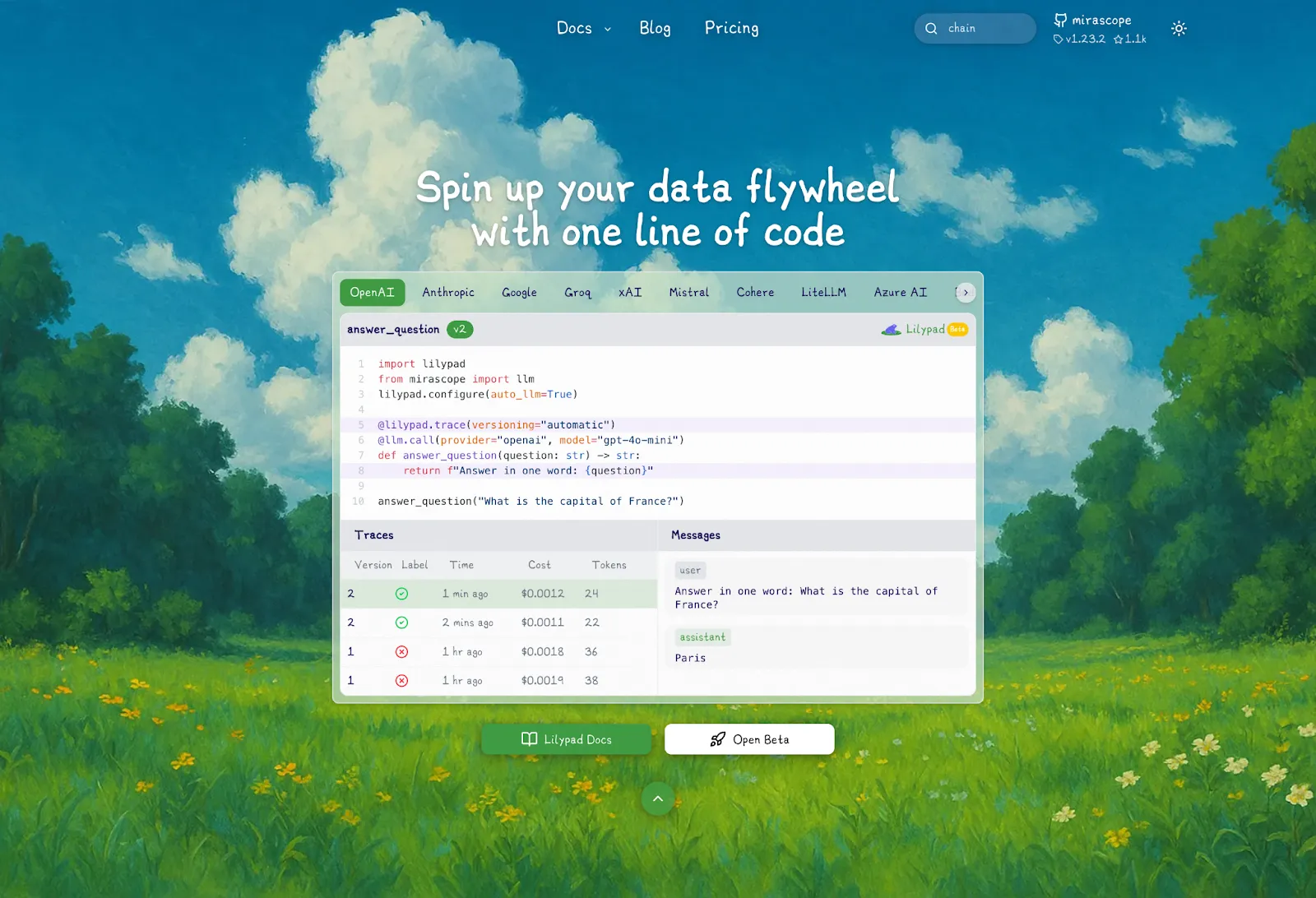
[Lilypad](/docs/lilypad) approaches prompt engineering as an optimization problem, applying proven software engineering practices to LLM application development. It allows users to version, trace, and optimize workflows by capturing the full context of every LLM interaction.
Instead of treating prompts as disconnected text assets, Lilypad treats them as part of version-controlled functions. This lets users debug, measure, and improve everything that influences outputs.
Below, we break down key Lilypad prompt management and observability capabilities that help teams version, trace, and continuously improve their LLM workflows.
#### Capturing the Full Story Behind Every LLM Call
To record the full context of a prompt, Lilypad encourages users to wrap the prompt, the LLM call, and any surrounding code in a Python function. This snapshots everything that influences the call's outcome, including:
* Input arguments, such as the user query or chat history
* LLM model settings
* Any pre- or post-processing steps and helper functions
* The code logic within the function's scope
Everything within the function’s closure effectively becomes the prompt, rather than just the prompt instruction.
You decorate the function with `@lilypad.trace(versioning="automatic")`, which automatically versions any changes within the function’s closure, creating a complete record of the prompt and its context. With this, all conditions that led to a specific output are preserved, so you can replay it exactly as it occurred.
In addition, you can automatically trace all API-level metadata across your codebase by adding a single line: `lilypad.configure(auto_llm=True)`. This captures key metadata about calls like inputs, outputs, token usage, cost, and latency (even for calls outside decorated functions but that are still within the function closure).
```python
from openai import OpenAI
import lilypad
lilypad.configure(auto_llm=True) # [!code highlight]
client = OpenAI()
@lilypad.trace(versioning="automatic") # [!code highlight]
def answer_question(question: str) -> str:
resp = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": f"Answer this question: {question}"}],
)
return resp.choices[0].message.content
answer = answer_question("Who painted the Mona Lisa?") # automatically versioned
print(answer)
# > The Mona Lisa was painted by the Italian artist Leonardo da Vinci.
```
All this offers a complete audit trail of what changed and why (not only in the prompt but in the prompt’s context). Incremented versions are shown in the Lilypad UI:
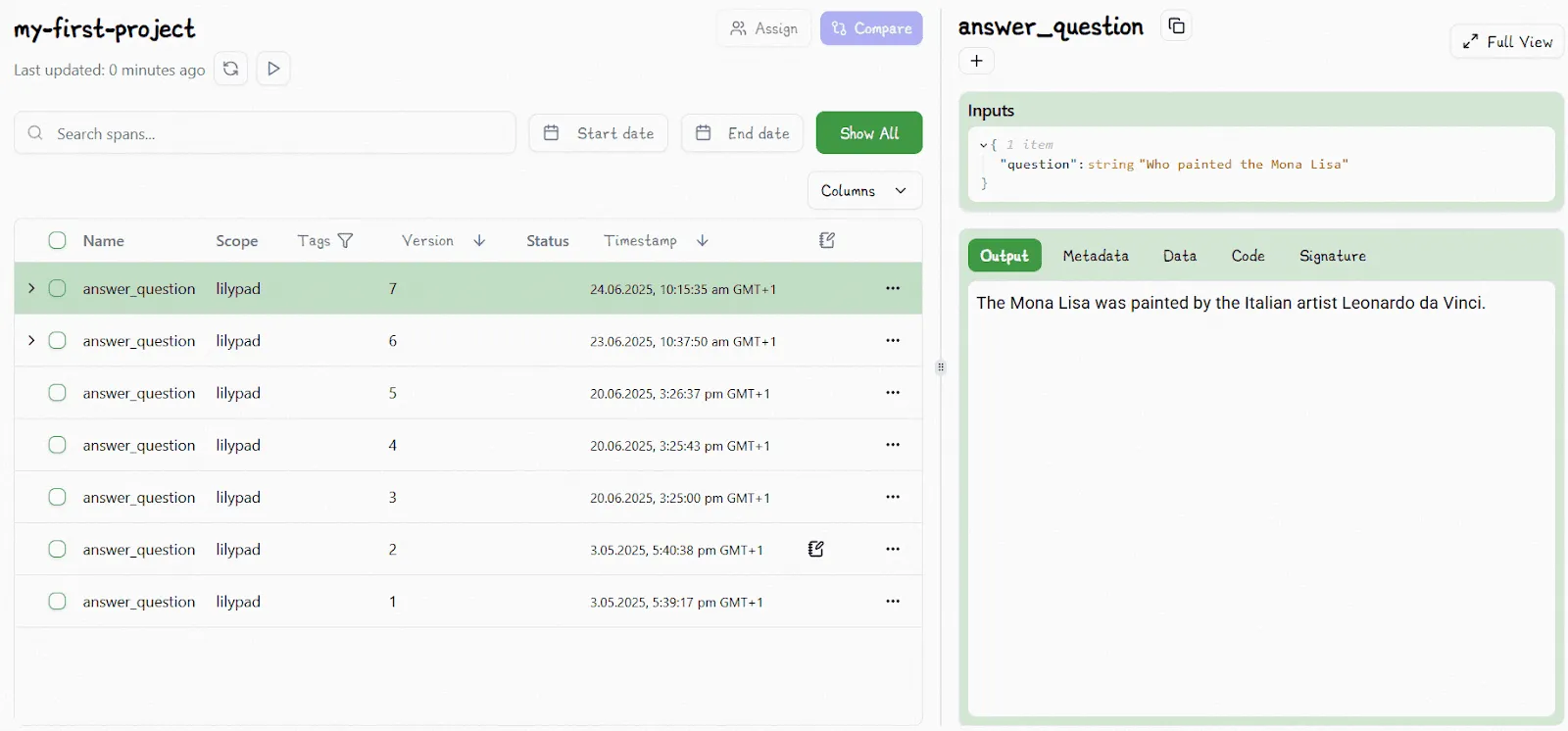
It even logs and tracks changes to user-defined functions or classes outside the main prompt function as long as these are within the decorated function’s scope.
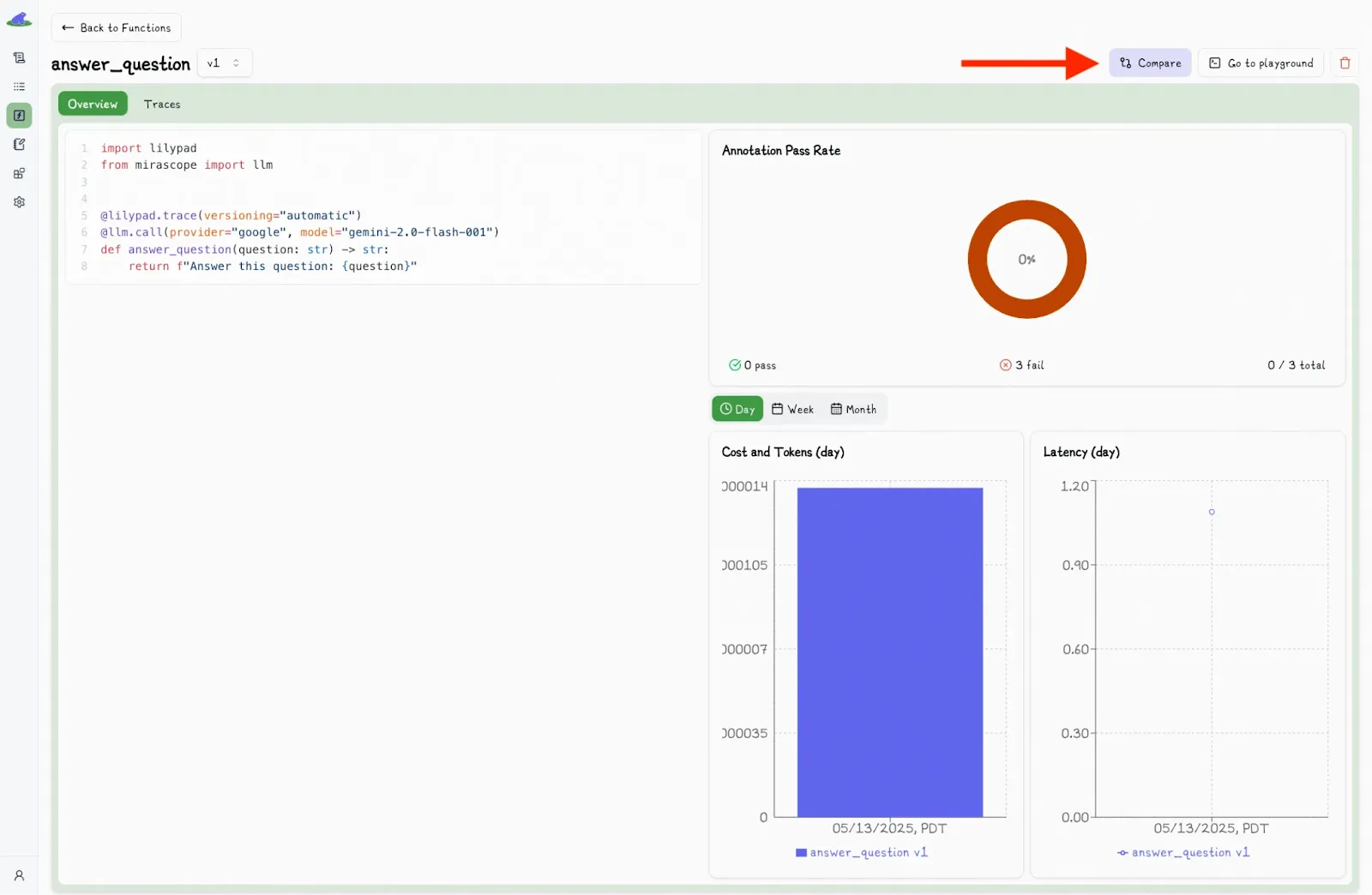
The “Compare” button in the Lilypad UI allows you to see the differences between various versions of the code:
Clicking this displays a second dropdown menu, where you can select another version and view the differences side-by-side:
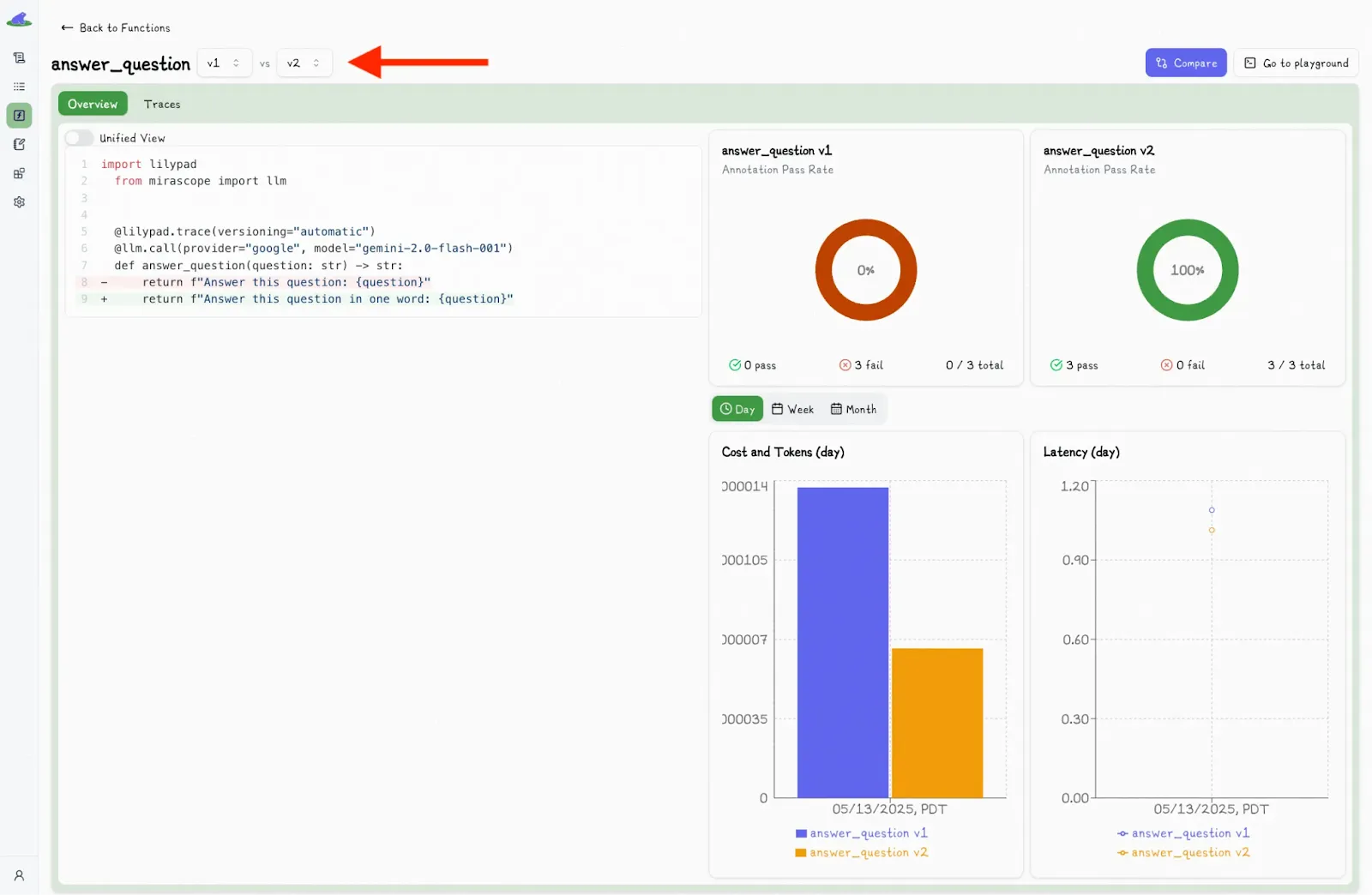
The UI also lets you inspect trace data for any LLM call in a function in order to see the full picture of what happened during the run, including any changes to inputs, logic, prompt changes, and model settings:
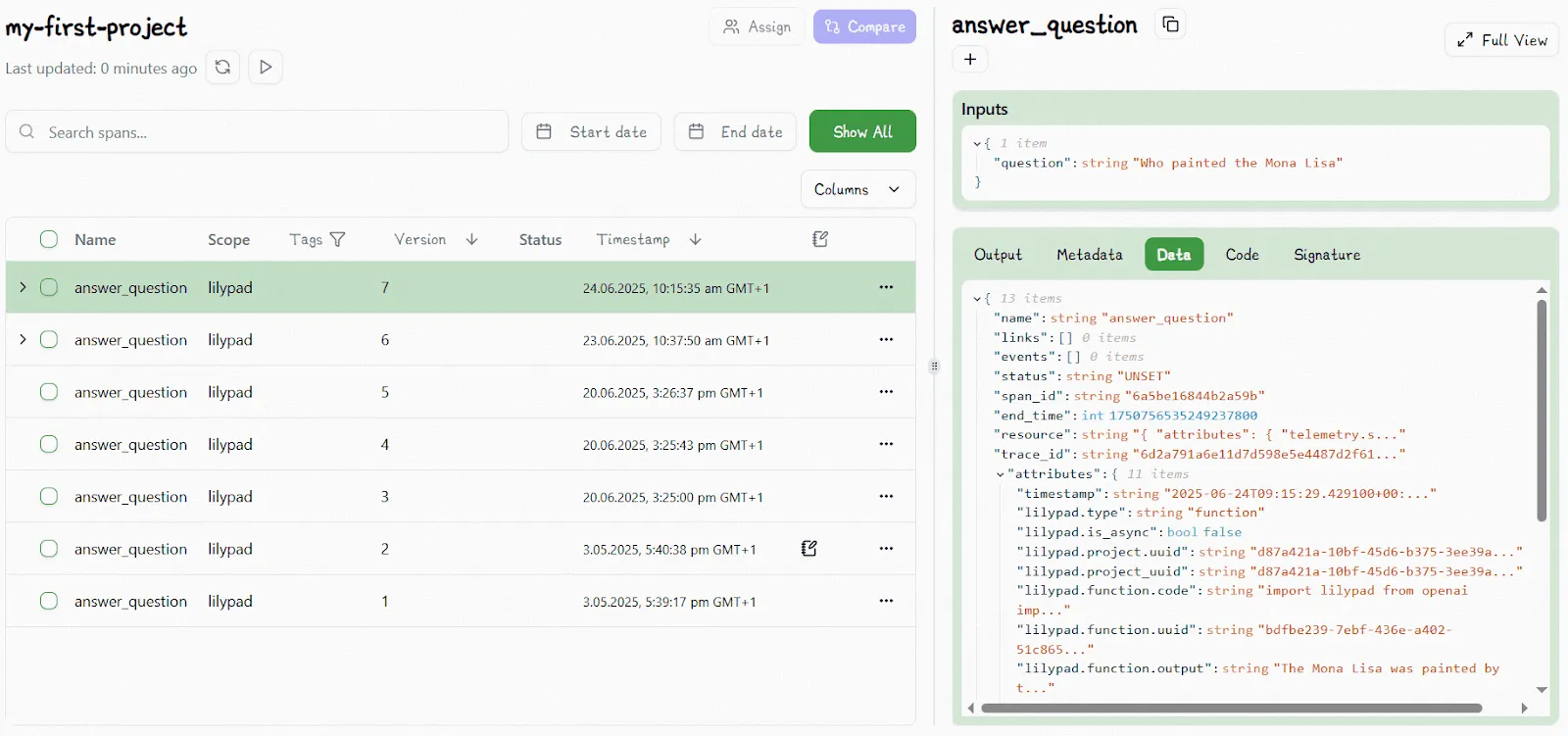
Downstream, you can use the `.version` method to compare outputs, track changes, or reproduce earlier results.
```python
response = answer_question.version(4)("Who painted the Mona Lisa?")
```
This returns type-safe function signatures that match the expected arguments for that specific version and also provides type hints for your IDE.
#### A Workspace That Keeps Prompts in Sync With Your Code
Lilypad’s no-code UI gives users a place to collaborate on prompts, with every change linked directly back to the underlying code.
Under the hood, Lilypad ensures prompt edits stay in sync with the exact type-safe Python code that developers run downstream. That means what you test in the workspace is exactly what’s in the codebase, which avoids the brittleness of other systems where prompts live separately.
Unlike tools that only version the text of a prompt, Lilypad versions the code itself. Every change, whether a change of wording or a parameter adjustment, creates a new version of the underlying function.
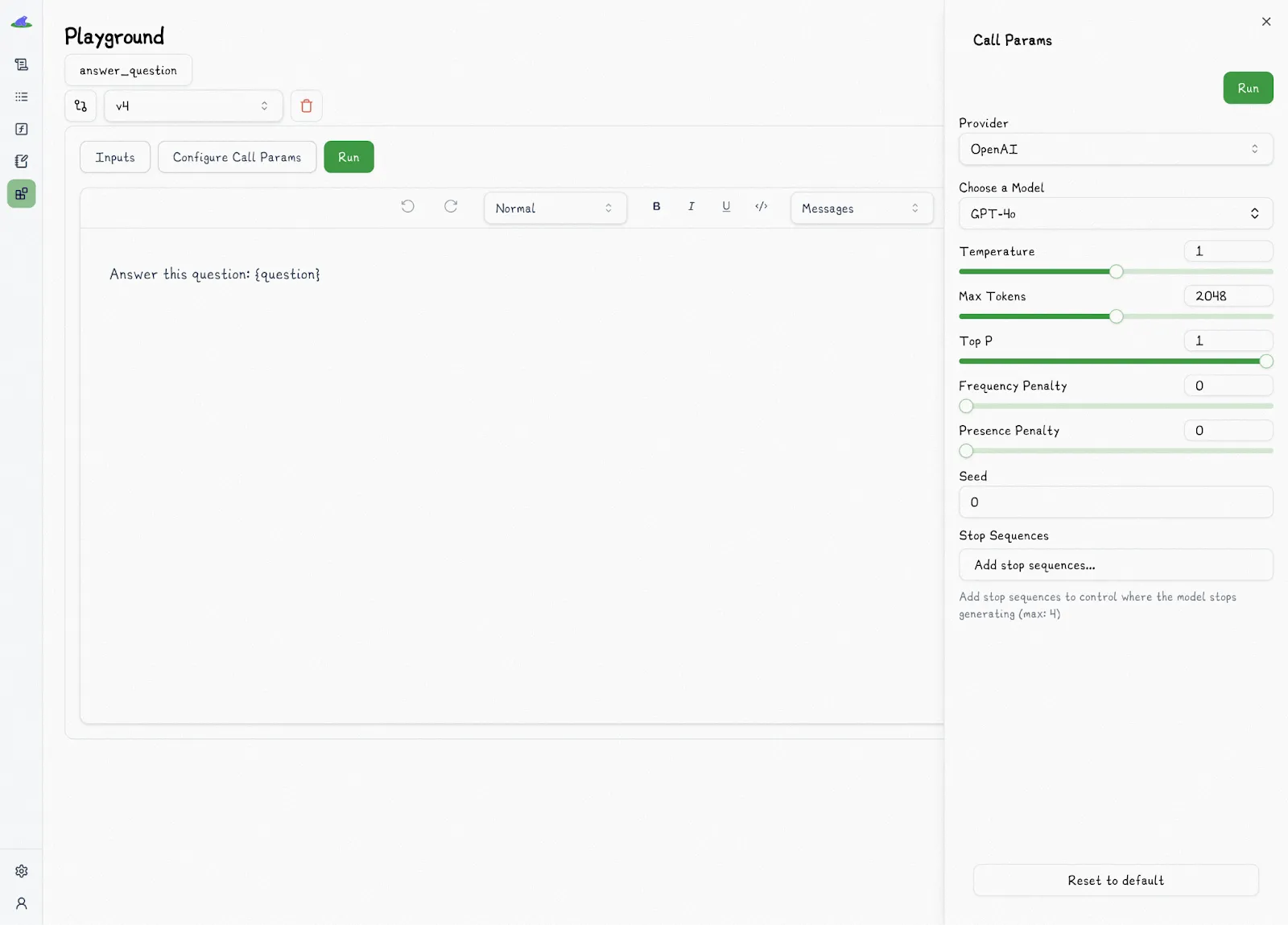
The Lilypad playground supports markdown-based editing with typed variable placeholders, which helps prevent common errors like missing values, incorrect formats, or injection vulnerabilities.
Users can also directly adjust model settings like temperature or `top_p`. Together, these features ensure all prompt edits remain consistent, traceable, and fully integrated into the application’s codebase.
#### Building Reliable Evaluation Pipelines
Lilypad allows teams to annotate LLM outputs to track evaluation decisions alongside version history, trace data, and prompt changes.
Every review is tied to the exact function version, inputs, prompt text, and model settings that produced the output. This means teams can always see why a prompt behaved the way it did and recreate those conditions if needed.
But evaluation goes beyond checking if an answer is right or wrong. In many real-world cases, the goal is to decide whether an output is “good enough” for the intended use. For this, human judgment often plays a central role.
For example, on a 1–5 scale, one reviewer might rate a response a 3 while another rates it a 4, showing how subjective judgment can shape evaluations even when both reviewers agree the output is usable.
Because of this subjectivity, evaluation tools need a structured way to capture and organize feedback. The Lilypad UI lets teams assign outputs to specific reviewers to turn individual judgments into structured data.
The outputs to evaluate appear in structured queues, where reviewers can label them as pass or fail and add reasoning notes. To reduce bias, existing annotations remain hidden until the review is complete.
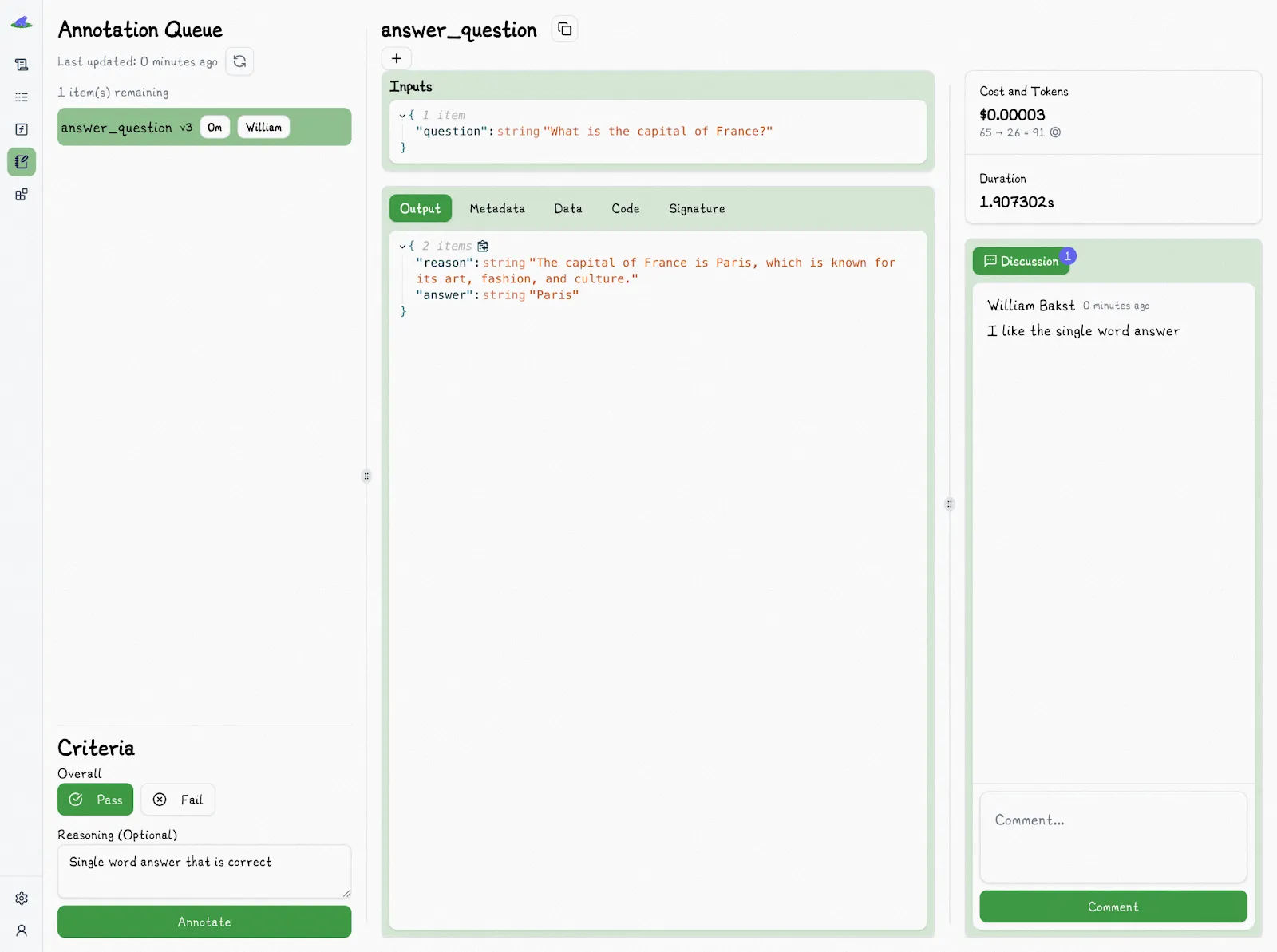
The result is a body of searchable evaluation data stored alongside trace details and version history, making reviews easy to audit and reproduce.
Developers can set `mode="wrap"` in `@lilypad.trace` to make the function’s return value annotatable through `.annotate()`. This makes it easy to add annotations in code, integrate automated checks, or plug evaluations into CI/CD pipelines without needing to switch to the UI.
```python
from google.genai import Client
import lilypad
client = Client()
lilypad.configure()
@lilypad.trace(name="Answer Question", versioning="automatic", mode="wrap") # [!code highlight]
def answer_question(question: str) -> str | None:
response = client.models.generate_content(
model="gemini-2.0-flash-001",
contents=f"Answer this question: {question}",
)
return response.text
trace: lilypad.Trace[str | None] = answer_question("Who painted the Mona Lisa?")
print(trace.response) # original response
# > The Mona Lisa was painted by the Italian artist Leonardo da Vinci..
annotation = lilypad.Annotation( # [!code highlight]
label="pass", # [!code highlight]
reasoning="The answer was correct", # [!code highlight]
data=None, # [!code highlight]
type=None, # [!code highlight]
) # [!code highlight]
trace.annotate(annotation) # [!code highlight]
```
We believe having humans evaluate outputs creates solid datasets for accurate automation later on, via methods like [LLM-as-a-judge](/blog/llm-as-judge), which reduces manual labeling workload by eventually shifting humans into a verification role.
Nonetheless we encourage manual spot-checking to catch more subtle errors that automated judging might miss
You can [sign up for Lilypad](https://lilypad.mirascope.com/?_gl=1*o5ec17*_ga*NDUwMDMyNjI4LjE3MjgxOTExMzk.*_ga_DJHT1QG9GK*czE3NTUyNjUzMzQkbzYyNCRnMSR0MTc1NTI2NjE0NyRqNDQkbDAkaDA.) using your GitHub account and get started with tracing and versioning your LLM calls with only a few lines of code.
### 2. LangSmith: Prompt Management Inside the LangChain Ecosystem
[LangSmith](https://www.langchain.com/langsmith) (part of the LangChain ecosystem) provides observability and helps teams manage, test, and optimize prompts. It offers a central workspace where prompts can be organized, versioned, evaluated, and integrated into applications.
Key prompt management features include:
* A visual environment (playground) to create, edit, and experiment with prompts, adjust parameters (like model, temperature), and test outcomes.
* Version control with commit-like identifiers (SHA numbers) and tags to separate development, QA, and production versions; versions must be explicitly saved, as the system doesn’t track them automatically..
* The ability to run prompts against datasets, measure prompt performance with automated or human evaluators, and compare different versions in a structured, metric-driven way.
* A shared workspace for team members to co-create, edit, comment on, and review prompt changes.
* Make prompts public or private and share or collaborate across different teams and projects, including publishing to the broader LangChain community if desired (via LangChain Hub).
* Management of prompts via the SDK that offers tight coupling with code-driven workflows.
LangSmith is closed source and requires an enterprise license to self-host.
### 3. Langfuse: Open Sourced Control Over Your Prompt Lifecycle
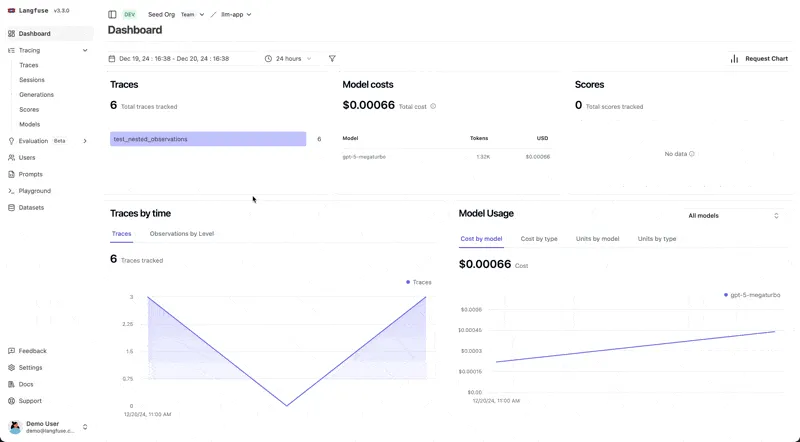
[Langfuse](https://langfuse.com/) is an open source prompt management system that enables creation, storage, versioning, testing, and deployment of prompts.
[Langfuse prompt management](/blog/langfuse-prompt-management) offers:
* A prompt management tool for creating and editing prompts, allowing you to build, template (with variables), and update text and chat prompts using the UI or SDKs.
* Simple labeling and version tagging enabling quick rollback, reliable tracking, and parallel experimentation with different prompt versions.
* Real-time collaboration via shared UI and APIs; tracking who made changes and when.
* The capability of marking prompts for usage in development, staging, or production environments, and switching versions instantly via label promotion.
* Integration with performance tracking and evaluation dashboards for [LLM observability](/blog/llm-observability) and to monitor how changes in prompts affect model outputs, latency, and cost metrics over time.
* Fetching, compiling, and deploying the latest version of prompts via code, without manual intervention.
### 4. Agenta: A Self-Hostable Platform for Versioning, Testing, and Evaluating Prompts
[Agenta](https://agenta.ai/) is an open source platform focused on prompt management for teams. It helps users systematically create, test, version, and evaluate prompts as part of the app development lifecycle.
Key prompt management features include:
* AI tools for tracking every version of an [LLM prompt](/blog/llm-prompt), maintaining history of changes, and enabling comparison of performance between versions.
* Running experiments that compare outputs from different prompt versions or model configurations, and visualizing these outputs side by side.
* Associating each prompt version with its testing and production metrics, allowing organizations to see which prompt was used for any output and how changes affected results over time.
* An interactive environment for building and testing prompts collaboratively, including the ability to compare outputs from different large language models, adjust parameters, and deploy new prompt versions or variants as needed.
* The ability to self-host their projects, and to modify the source code to fit their workflow, and benefit from community contributions.
### 5. PromptLayer: A Visual Workspace for Prompt Versioning and Testing
[PromptLayer](https://www.promptlayer.com/) is a closed source, prompt management platform that allows team members to store, organize, version, evaluate, and iterate on AI prompts for large language models like Anthropic, OpenAI, and Google. It provides a central prompt workbench for deploying and monitoring prompts in [LLM applications](/blog/llm-applications).
Key prompt management features include:
* Version control for maintaining a historical record of changes and supporting easy rollbacks and comparisons for designing LLM interactions using, e.g., [prompt chaining](/blog/prompt-chaining).
* A user-friendly UI for editing, A/B testing, and deploying prompts visually.
* Multi-user editing, reviews, and roles, bridging technical and non-technical team members.
* Functionality and AI tools for testing prompts against usage history, with support for regression and batch tests.
* The capability to assign permissions, managing who can view, edit, or deploy prompts.
## Bring Engineering Discipline to Prompt Management
Prompt engineering doesn’t have to be trial-and-error. Lilypad’s code-first approach unifies version control, [LLM evaluation](/blog/llm-evaluation), and collaboration so your team can iterate faster without sacrificing quality. Lilypad lets you manage prompts the same way you manage software, systematically and with full visibility.
Want to learn more about Lilypad? Check out our code samples on our [documentation site](/docs/lilypad) or on [GitHub](https://github.com/mirascope/lilypad). Lilypad offers first-class support for [Mirascope](https://github.com/mirascope/lilypad), our lightweight toolkit for building [LLM agents](/blog/llm-agents).
Prompt Management Tool: What It Is, Why It Matters, and the Best Options
2025-09-19 · 9 min read · By William Bakst