LangChain is one of the most widely adopted frameworks for prototyping and building LLM applications and lets you do things like:
* Build prompts
* Chain multiple calls
* Route inputs through conditional logic
* Integrate external tools (like web search or code execution)
* Manage state across a conversation or task, and more
LangSmith, on the other hand, offers tools to version, monitor, and evaluate AI applications. Where LangChain helps you build, LangSmith helps you observe, debug, and optimize.
Both LangSmith and LangChain are basically the same ecosystem and work well together, though some developers report issues, for instance:
* LangChain’s framework **is comprehensive but uses homegrown abstractions** entailing a learning curve, which obscures what’s going on under the hood.
* The framework also doesn’t inherently enforce built-in type safety for the return values of functions, leaving you to discover these at runtime.
* In LangSmith, prompts are versioned separately from the code that uses them, which can make systems brittle.
* You also need to manually save prompts to version them (versioning isn’t automatic).
To solve these issues, we designed [Mirascope](https://github.com/mirascope/mirascope), an LLM toolkit for building applications, and [Lilypad](/docs/lilypad), an open-source solution that makes LLM calls easy to repeat, test, and improve.
In this article, we first discuss how LangChain and LangSmith fit into a typical application development workflow and the situations when you need one, the other, or both.
Then we present Lilypad as an alternative to LangSmith, and show how you can use it to track, evaluate, and optimize AI applications with less overhead, more transparency, and in a workflow that feels like standard software development.
## How LangChain and LangSmith Work
### LangChain: Building with Chains, Tools, and Prompts
LangChain supports both Python and JavaScript (Typescript) and offers reusable prompt template classes that include placeholders for variables that get dynamically resolved at runtime.
The framework offers different kinds of prompt templates depending on the type of model you're working with (e.g., completion or chat-based).
We cover the following [LangChain prompt templates](/blog/langchain-prompt-template) in more detail elsewhere, but here’s a quick rundown:
* `StringPromptTemplate` – great for basic completion models
* `ChatPromptTemplate` – for structured chat messages
* `MessagesPlaceholder` – to slot in past dialogue history dynamically
These are certainly good for getting started since they handle a good chunk of real-world use cases, but we find that things can get messy as your application scales and your app is making hundreds of calls, especially when you need to chain prompts or debug complex flows.
#### Prompt Chaining in LangChain
LangChain was (of course) built with [prompt chaining](/blog/prompt-chaining) in mind and provides abstractions that let you compose multiple steps of an LLM workflow.
It offers a flexible Python API centered around the `Runnable` interface, which is a feature of the LangChain Expression Language (LCEL), a declarative syntax that sometimes uses the `|` (pipe) operator to define the flow of data across components.
A simple LCEL chain might look like:
```python
chain = prompt | model | output_parser
```
This format works well for straightforward pipelines, being compact, readable, and easy to compose when you're dealing with single-step prompts or small utilities.
But once you go beyond the basics, like when you're building more dynamic workflows with multiple conditionals, branches, or parallel subchains, the abstractions start to get in the way. **Debugging chained operations can be tricky**, especially when you're forced to squeeze your logic into LCEL's specific object format.
We also found that components like `RunnablePassthrough`, which simply forwards inputs unchanged, feel like unnecessary scaffolding. They're often used to satisfy the chaining contract rather than solve a real problem.
For example, an internal service chatbot might pass a query asking about the status of a reimbursement request through a pipeline defined using a runnable, where `RunnablePassThrough` forwards the query unchanged.
A prompt formats the query for processing and `runnable.bind(stop=”END”)` tells the LLM to stop generating a response once it encounters the keyword `”END”`:
```python
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
model = ChatOpenAI(model="gpt-4-mini")
runnable = (
{"equation_statement": RunnablePassthrough()}
| prompt
| model.bind(stop="END")
| StrOutputParser()
)
print(runnable.invoke("What is the status of my expense reimbursement request?"))
```
From a developer usability standpoint, this code isn’t ideal since:
* The pipeline components (`RunnablePassthrough`, `prompt`, `model.bind`, and `StrOutputParser`) do different things, but their interaction and the data flow through them (particularly via the pipe operators) **aren’t especially intuitive** and require you to infer the underlying logic from documentation or trial and error.
* `.invoke` may seem like an easy way to run your chain, but there is no type safety or autocomplete on the inputs. This makes it difficult for downstream consumers of the chain to know what to supply as the input without digging through to the original code.
The more components you add to the pipeline, the more complicated it all gets.
What about using just plain Python (and a little bit of [Mirascope](https://github.com/mirascope/mirascope))?
```python
from mirascope import llm
@llm.call(
provider="openai",
model="gpt-4o-mini",
call_params={"stop": "END"},
output_parser=str
)
def answer_question(question: str):
return question
response = answer_question("What is the status of my expense reimbursement request?")
print(response)
```
The above code uses a Python function decorated with `@llm.call` to directly define LLM interactions, avoiding intermediary abstractions like operators or runnables and simplifying the logic into a single function that includes built-in output parsing that lets you write your output parsers using standard Python functions rather than requiring additional abstractions.
#### Tools and Agent Integration in LangChain
Another significant reason developers use LangChain is its built-in support for tools and AI agents. LangChain makes it easy to register external tools, like calculators, search APIs, or code interpreters, and then route user queries through an agent that decides which tool to call based on the input.
Below is an example of registering a Google Search tool and using an agent to decide when to call it based on the input prompt.
```python
from langchain.agents import initialize_agent, AgentType
from langchain.tools import Tool
from langchain.chat_models import ChatOpenAI
from langchain_community.utilities import GoogleSerperAPIWrapper
# Set up your language model
llm = ChatOpenAI(temperature=0, model_name="gpt-4")
# Define a search tool for real-time info gathering
search = GoogleSerperAPIWrapper()
search_tool = Tool(
name="Google Search",
func=search.run,
description="Fetches real-time info from Google Search"
)
tools = [search_tool]
# Initialize an agent using the REACT pattern
agent = initialize_agent(
tools=tools,
llm=llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
handle_parsing_errors=True,
verbose=True
)
# Run the agent
response = agent.run("Tell me about the latest AI regulation news")
print(response)
```
LangChain agents rely heavily on prompt templates behind the scenes. These prompts are designed to instruct the model to think step-by-step, select a tool, call it with the right input, and return a final answer.
LangChain wraps this behavior into its agent classes, so you don’t have to build it from scratch, **but you still need to define the tools, prompt logic, and output parsers yourself**.
```python
from langchain.agents import initialize_agent, Tool
from langchain.agents.agent_types import AgentType
from langchain.chat_models import ChatOpenAI
# Define a simple tool
def add_numbers(a, b):
return str(int(a) + int(b))
tools = [
Tool(
name="Adder",
func=lambda x: add_numbers(*x.split()),
description="Adds two numbers. Input should be two integers separated by space."
)
]
llm = ChatOpenAI(temperature=0)
# Initialize agent
agent = initialize_agent(
tools,
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True
)
agent.run("What is 2 plus 5?")
```
Setting `verbose=True` as shown above shows the full prompt that LangChain constructs for the LLM, including tool names, usage instructions, and expected output format.
In simpler cases and for prototyping, this might work just fine. But as we mentioned earlier, the more your toolset expands or your application logic grows, the harder it becomes to trace what’s actually happening, especially when debugging agent decisions or fine-tuning the prompts that guide them.
So while LangChain gives you a good jumpstart for building tool-using AI agents, it also introduces more abstractions that you have to understand and maintain.
*See also our latest in-depth comparison of [LlamaIndex vs. LangChain](/blog/llamaindex-vs-langchain)*.
### LangSmith: Observing, Evaluating, and Debugging LLM Behavior
LangSmith, which is closed source, is useful for [prompt optimization](/blog/prompt-optimization) and tracks inputs, outputs, tool calls, and intermediate steps. It allows you to inspect these in detail, review model behavior step by step, and diagnose errors or unexpected outcomes.
[LangSmith prompt management](/blog/langsmith-prompt-management) features include a UI for tracking latency, API calls, token usage, and custom-defined business metrics. These [LLM observability](/blog/llm-observability) features come especially in handy when using chaining, routing, or agent logic, making it easier to see what’s going wrong and why.
Beyond tracing, LangSmith supports dataset-based evaluations (more on that below), allowing you to run input-output comparisons using reference answers, AI judges, or custom scoring logic. It also supports human feedback and integrates with CI pipelines to automate evaluation workflows.
It’s available as a managed cloud service or a self-hosted instance under a paid enterprise license.
#### Prompt Management
LangSmith provides Git-style versioning, where each manual save is assigned a unique commit hash and can be tagged (e.g., `v1` or `prod`) for easy tracking and rollback. You can also share prompts publicly on [LangChain Hub](https://smith.langchain.com/hub).
The platform also includes a visual prompt playground, which lets you create, edit, and test prompts in a point-and-click interface:
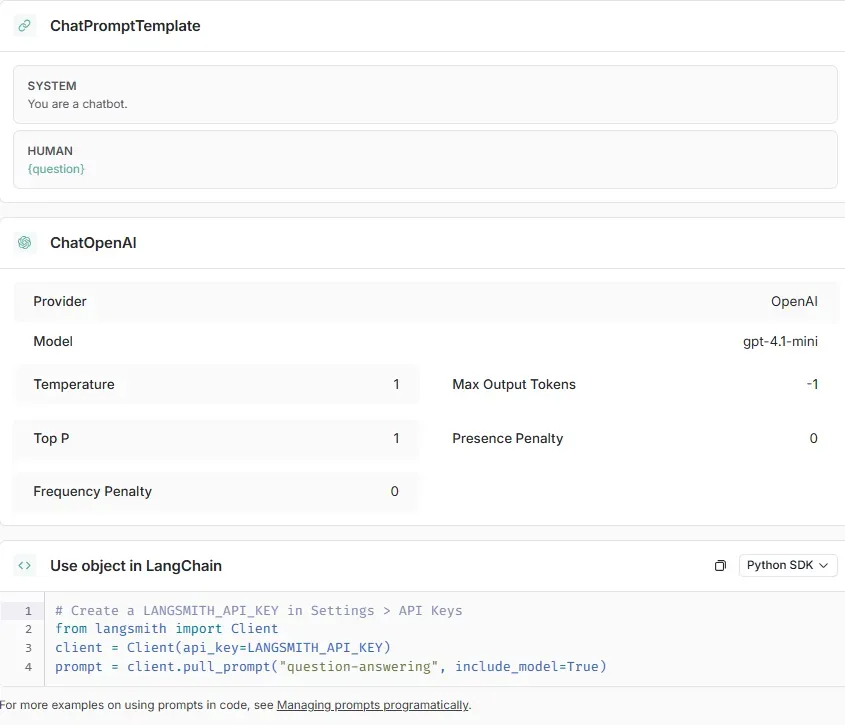
This is especially useful for non-developers or cross-functional teams who want to experiment with prompts without diving into code. The playground defaults to LangChain’s `ChatPromptTemplate` format, allowing structured inputs like user/system messages and plug-in variables like `{question}` or `{context}`.
It allows you to customize model settings (e.g., temperature, provider, model version), add tools, and define output schemas:
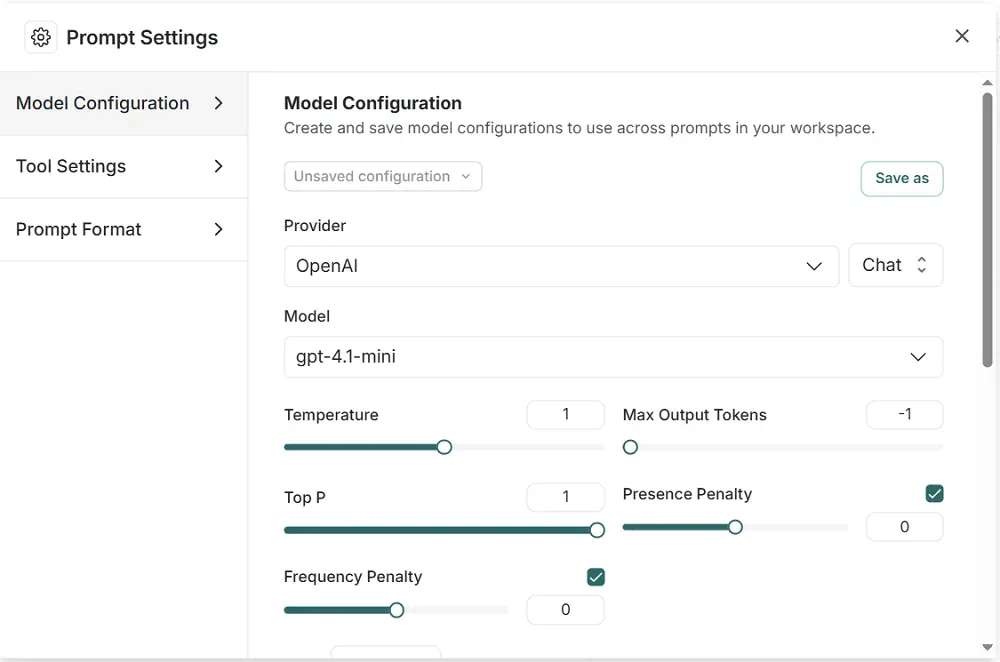
For more advanced workflows, you can use its “Prompt Canvas” editor, which lays out complex prompt chains visually and includes an LLM assistant to help write or improve prompts.
If you prefer to manage prompts in code, the LangSmith SDK (available in both Python and TypeScript) lets you push prompt templates into LangSmith directly from your codebase using `client.push_prompt()`, pull specific versions with `client.pull_prompt()`, or tag and audit them through methods like `list_prompts()` or `delete_prompt()`:
```python
from langsmith import Client
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate([
("system", "You are a career advisor."),
("user", "What are some good job options for someone with a background in {background}?"),
])
client.push_prompt("career-advice-prompt", object=prompt)
```
This makes it easier to integrate prompt changes into CI/CD pipelines or local application development workflows.
*See our latest article on [prompt engineering vs fine-tuning](/blog/prompt-engineering-vs-fine-tuning)*.
#### Evaluation in LangSmith
LangSmith’s evaluation system is built around structured AI workflows that emphasize predefined tests and measurable comparisons. **It works with datasets**, which include the inputs (such as user questions or system prompts) and either expected outputs or clear criteria that describe what a “good” response looks like.
Once uploaded, these permit repeatable evaluations across different prompt versions, letting you benchmark changes over time.
Datasets are versioned and can be split into subsets, allowing teams to iterate quickly on small slices or run full evaluations pre-deployment.
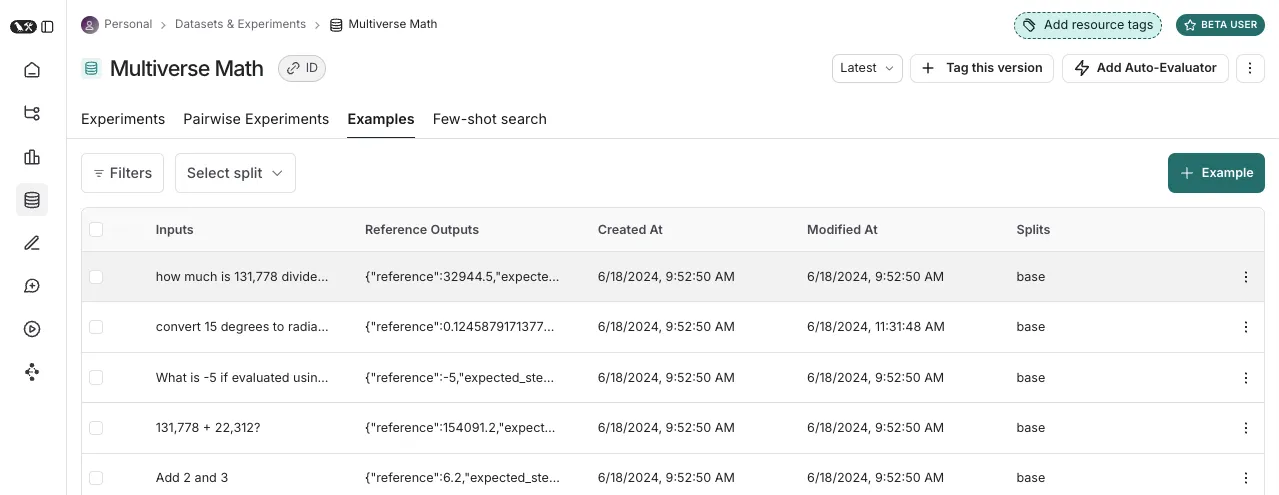
LangSmith also provides evaluators that can be automated or used manually. It supports AI-based judges, custom Python evaluators, and human reviewers. This setup gives you flexibility in how you define quality, whether that’s strict factual accuracy or more subjective criteria like helpfulness or tone.
LangSmith usually expects you to have test data ready ahead of time, or to go in and add labels to your results by hand. That works well when you already know exactly what you’re testing for, like in official benchmarks or performance checks.
But it’s not great when you’re just starting out, still trying to figure out what a good result even looks like. In that case, you’d have to stop, set up your tests, and decide what to look for before you can really make progress.
This setup is similar to how traditional machine learning works, where you need a clear dataset and scoring system before you begin. But real-world prompt work isn’t always that straightforward. You often need the freedom to test an idea, see what happens, adjust it, and keep going, especially when you're working in a team and things are changing fast. Having to define tests up front can slow down that process.
## Lilypad’s Developer-Friendly Approach to LLM Observability
Lilypad is based on the idea that a model’s output depends on more than just the prompt text. Things like the logic of your code, the flow of your program, and settings like the `model`, `temperature`, and `top_p` all play a role. So if you want to improve your prompts, you need to pay attention to all of these parts, not just the words you send to the model.
That’s why Lilypad encourages you to encapsulate all that affects the output of large language models into a Python function. This makes it easier to track what’s happening, test different versions, and see how changes affect the results. It also helps you reproduce outputs and improve things step by step.
Below, both prompt and model settings are contained in `answer_question()`, which is decorated by `@lilypad.trace` — which we describe further down. These treat prompt and context as a single observable unit, which makes tracing, versioning, and evaluating simpler:
```python
from google.genai import Client
import lilypad
lilypad.configure(auto_llm=True)
client = Client()
@lilypad.trace(versioning="automatic") # [!code highlight]
def answer_question(question: str) -> str | None:
response = client.models.generate_content(
model="gemini-2.0-flash-001",
contents=f"Answer this question: {question}",
)
return response.text
response = answer_question("What is the capital of France?") # automatically versioned
print(response)
# > The capital of France is Paris.
```
Keeping prompt logic and settings together gives you a clear view of what’s affecting your outputs, especially as your application grows and outputs start varying in subtle, hard-to-track ways.
### Automatic, Full-Context Versioning
When you set the versioning argument of `@lilypad.trace` to `”automatic”`, Lilypad versions all changes within the function closure automatically. This means all changes made to model settings, parameters, helper functions, and the surrounding logic within scope of the closure are captured, making each result reproducible and traceable, without needing to manually tag or manage versions.
It also allows you to compare different versions by clicking the “Compare” button in the Lilypad UI:
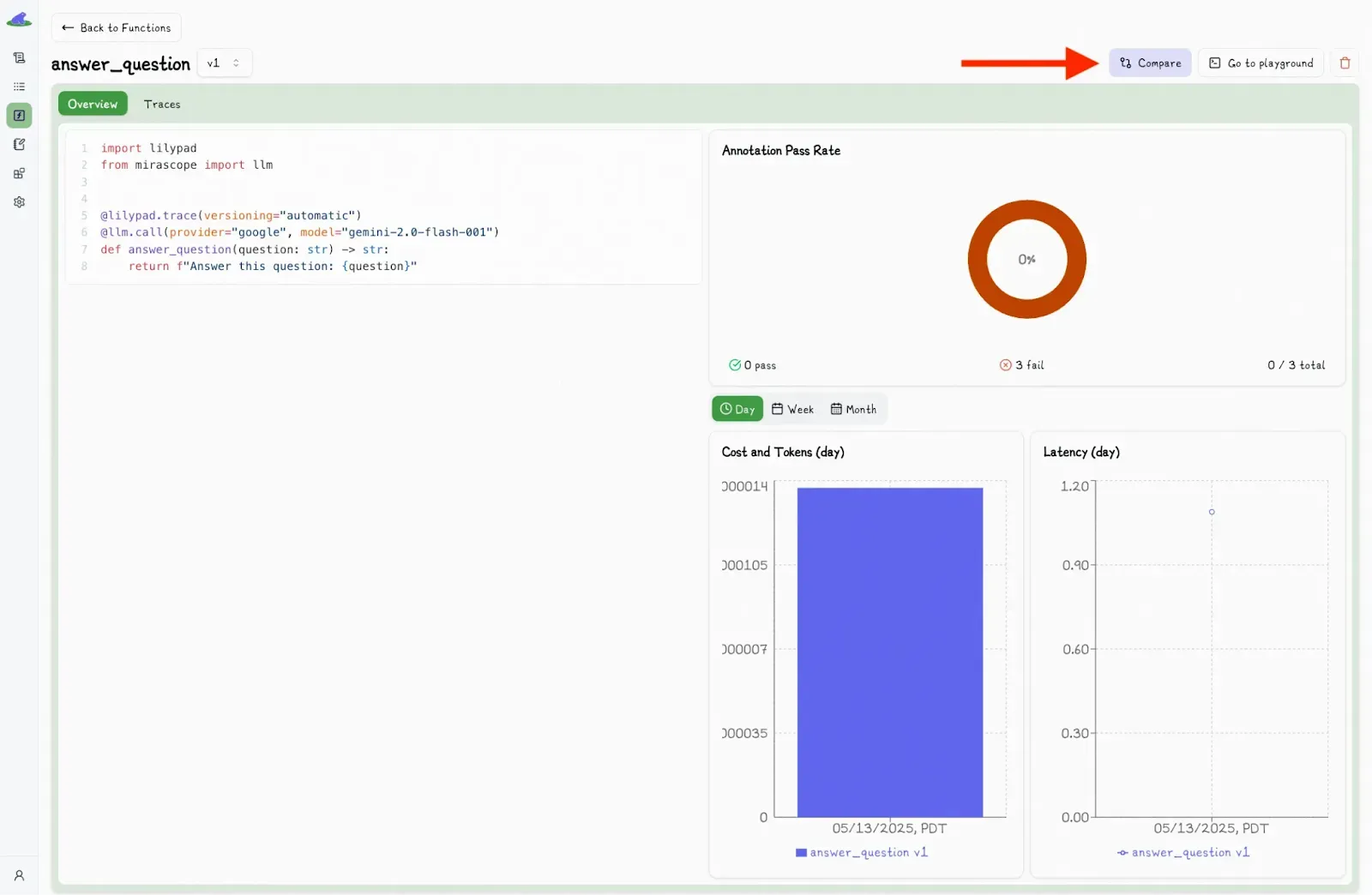
This toggles a second dropdown menu, where you can select another version and view the differences side-by-side.
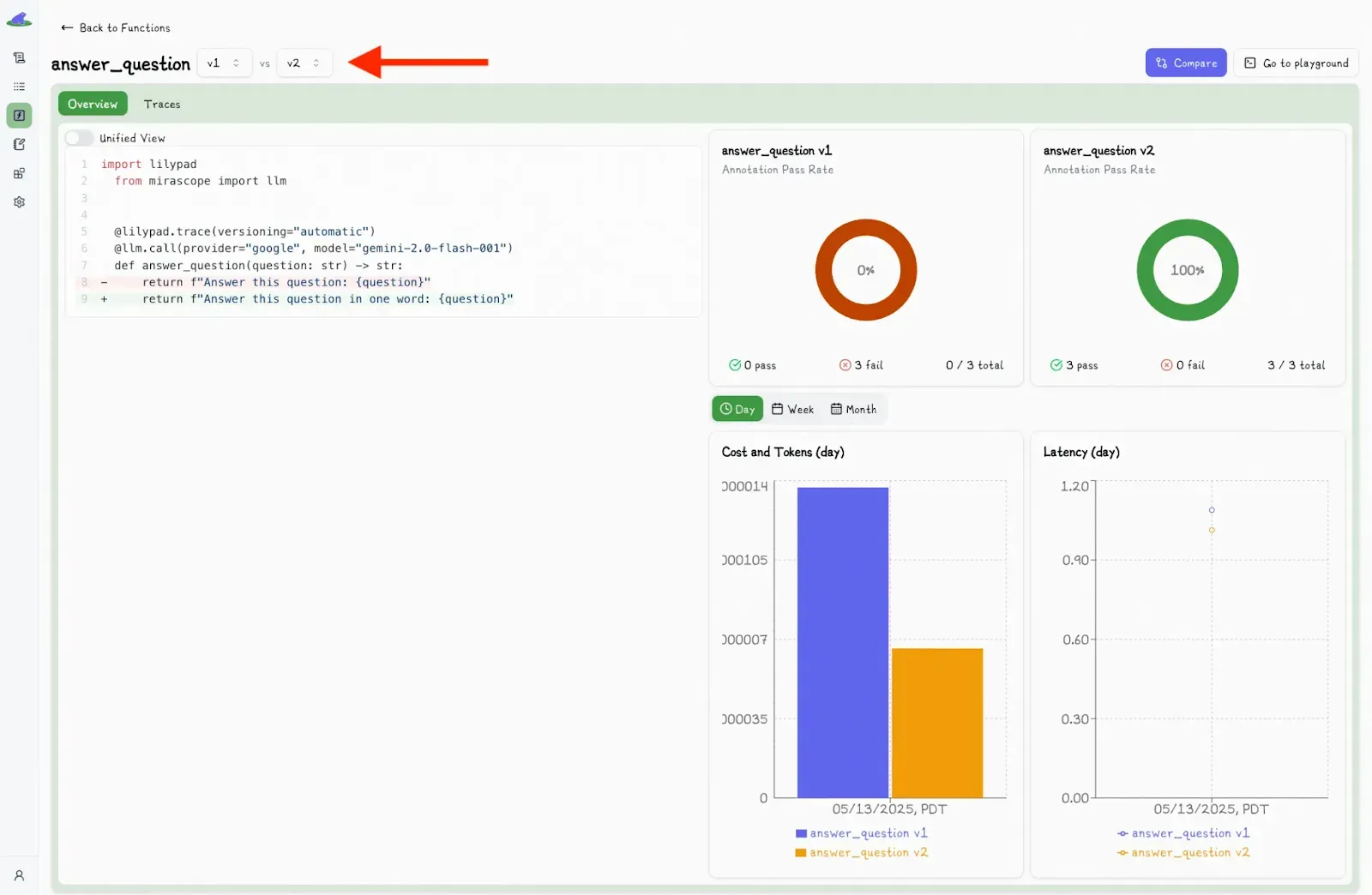
Under the hood, Lilypad uses the [OpenTelemetry GenAI spec](https://opentelemetry.io/) to structure each trace to quantify what was asked, how it was asked, and what came back.
It also shows all the metadata: inputs, outputs, details of AI models, token usage, latency, and cost, making it easy to debug, monitor, and optimize AI workflows.
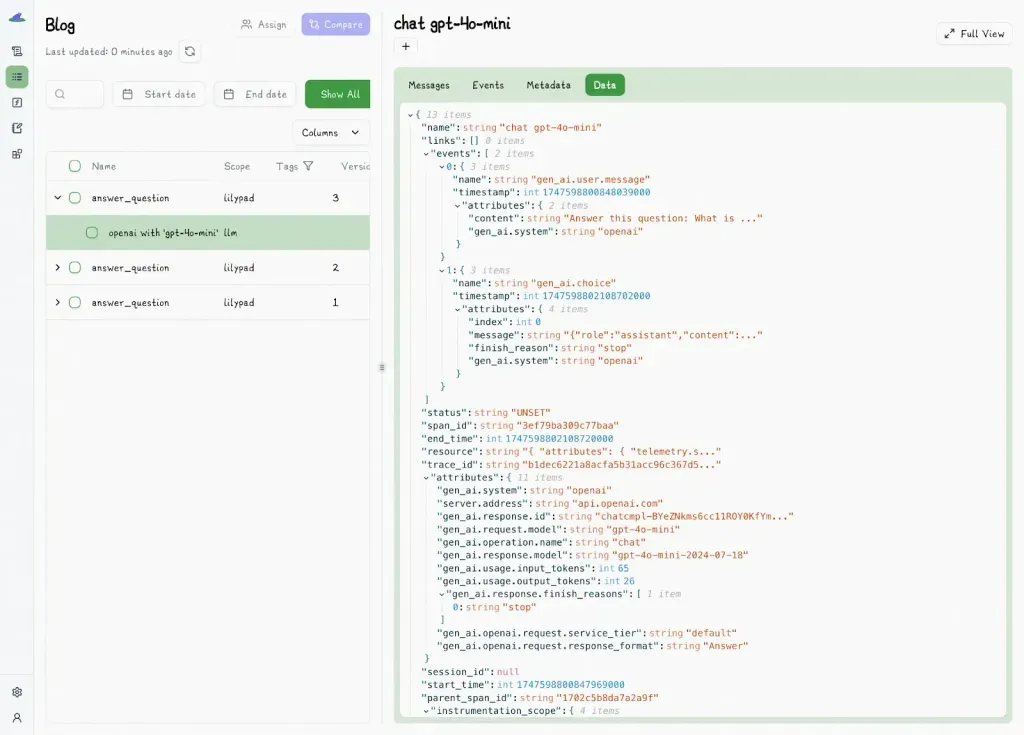
### Prompt Management and Collaboration
Lilypad’s UI isn’t just for viewing version history; it’s also a live prompt editor and collaboration space. Engineers and non-technical teammates, like product managers, domain experts, or content leads, can create, edit, and test prompt changes in the playground:
This includes leaving comments, suggested edits, or reviews of outputs without needing to touch the codebase or wait on an engineer to redeploy every change.
This setup creates a clear division where developers manage infrastructure and application logic, and subject matter experts handle prompt wording and logic.
This separation is only virtual, however, and doesn’t extend to how prompts are actually stored or deployed. Your prompts remain part of the same versioned function they’re associated with.
Platforms like LangSmith manage prompts outside of the codebase, which might seem clean at first. But because the prompt is decoupled from the logic and parameters tied to it, it becomes hard to trace exactly which version of the prompt produced which output.
**In Lilypad, prompts aren’t managed in a separate interface and then pulled into your code** — **they *are* your code**. That tight coupling is what makes the system reliable because every playground run is tied to the same versioned function that you call downstream. And if Lilypad goes down, your code and prompts remain unaffected.
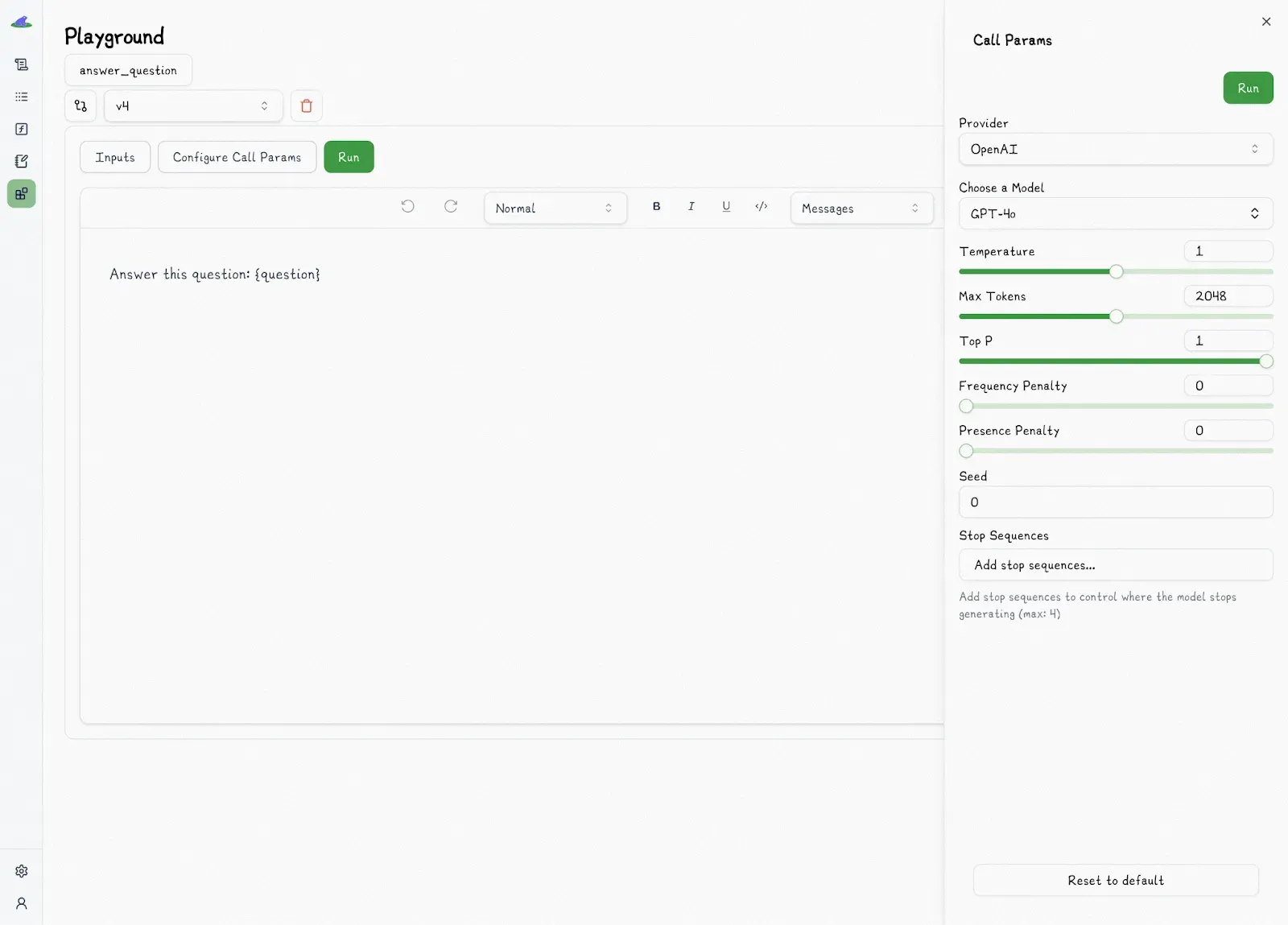
Also, changes made in the playground are sandboxed by default and won’t affect production unless explicitly synced by an engineer. Once synced, they ship as part of your app, just like any other code change.
Inside the playground, users can edit markdown-supported prompt templates with type-safe variables and edit prompt metadata. Lilypad automatically generates type-safe function signatures, so the inputs you test always match the function’s schema, reducing the risk of injection bugs or mismatched formats.
Because prompts are part of the function logic, what you see in the playground is exactly what runs in dev, staging, or production. There's no risk of a config file drifting out of sync or some prompt variant behaving differently in production.
### Prompt Evaluation Workflow
When it comes to judging the [quality](/blog/llm-evaluation) of outputs, traditional scoring systems like 1–5 stars can be ambiguous and hard to interpret, since the difference between, say, a 3 and a 4 can be challenging to pin down (and subjective). Over time, these kinds of scoring systems become inconsistent, especially when multiple reviewers are involved.
Lilypad uses a simple pass/fail system to evaluate outputs, allowing you to simply mark responses as acceptable or not, or plug in your own test logic, whether through scripts or automated [LLM-as-a-judge](/blog/llm-as-judge) flows (coming soon).
Unlike LangSmith, which requires predefined datasets to use its full functionality, Lilypad lets you evaluate prompts organically and as you build. You don’t have to stop and formalize your test set before you start learning. You can just try variations, mark what works or doesn’t, and layer in structure later.
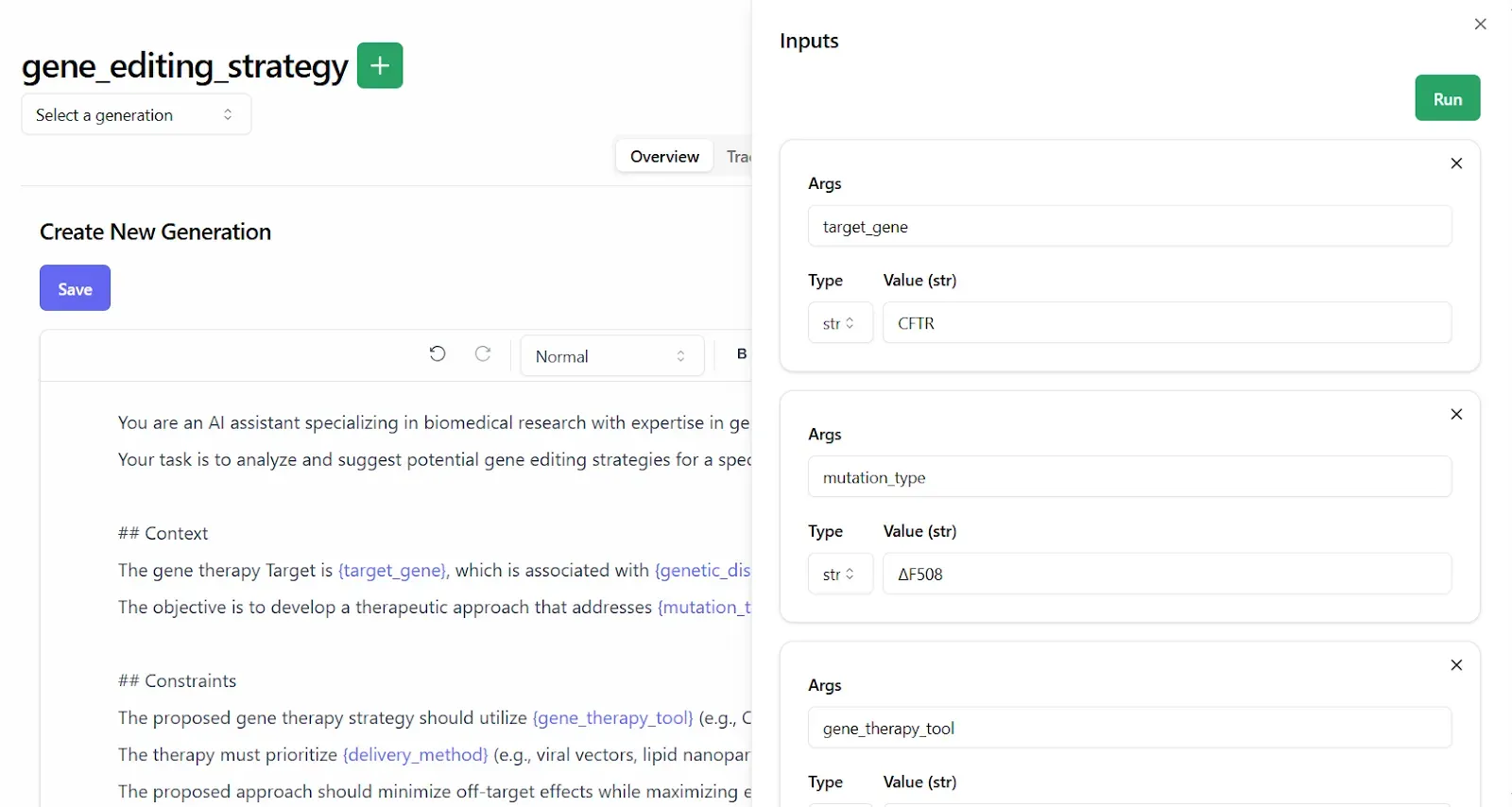
To begin, simply choose the trace you want to evaluate:
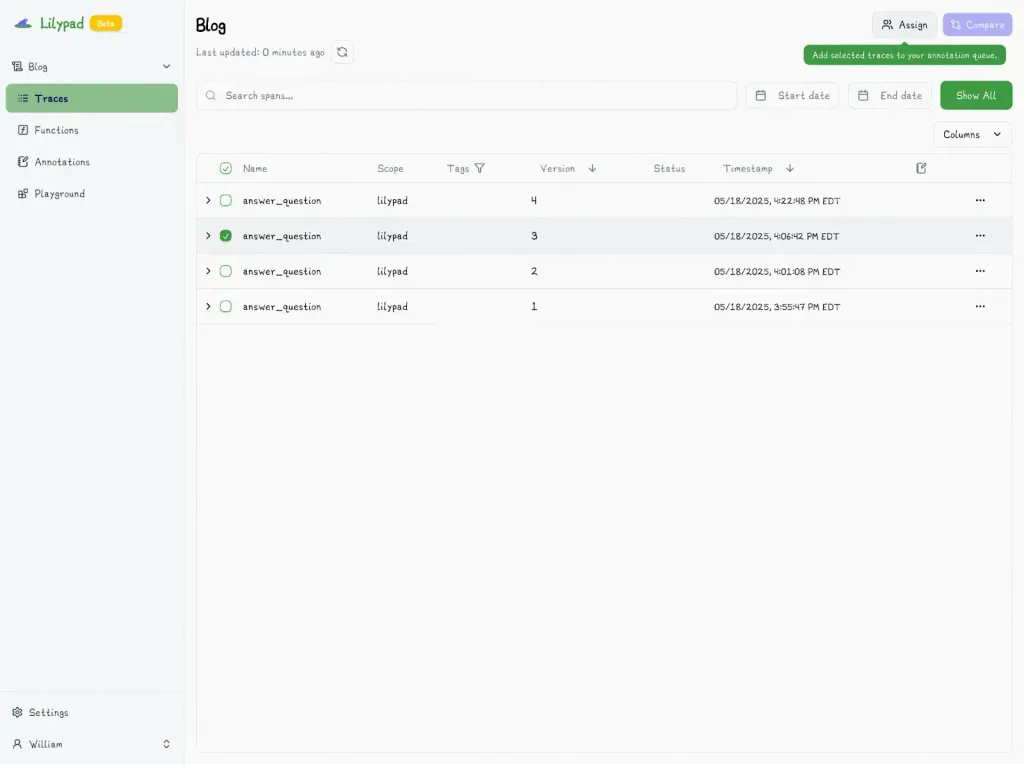
And mark it with “Pass” or “Fail”:
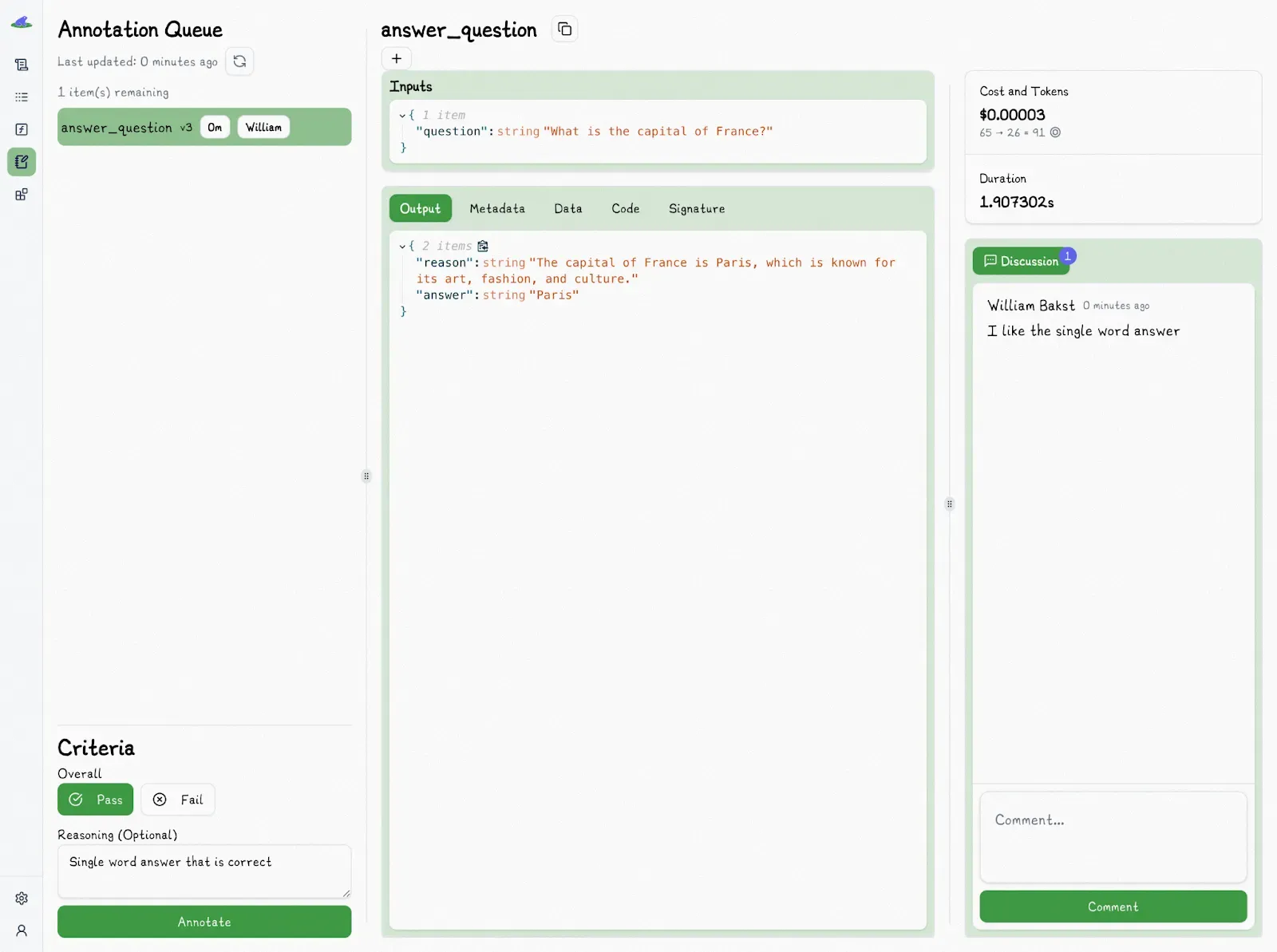
Reviewers need just answer the practical question: "Is this good enough to deploy?" They can also add a quick explanation to explain why something failed, like “missed a key detail” or “hallucinated fact.” These quick notes help build a picture of what good and bad look like over time.
And because every [LLM evaluation](/blog/llm-evaluation) is tied to a specific versioned prompt and function, you can trace patterns across iterations and app versions — something that’s harder to do in systems like LangSmith, where evaluations are often tied to static datasets or separated from prompt logic.
We generally recommend starting with manual evaluations by a domain expert. Once you build a solid base of labeled examples (pass or fail + explanations), you’ll be able to train an automated evaluator, i.e., an LLM-as-a-judge, later, to replicate those decisions at scale.
This doesn’t eliminate human oversight, as we recommend that human evaluators consistently step in to verify the judge’s decisions and ensure alignment with human standards.
## Get Started with Lilypad
Lilypad helps you track and improve individual [LLM applications](/blog/llm-applications) and functions, like AI agents, tools, and chains, while optimizing the overall system they’re part of. It’s designed for complex, non-deterministic AI workflows where outputs vary and constant evaluation is needed.
Lilypad is also tool-agnostic and supports self-hosting options. You can start for free, with no credit card required. Just sign up with your GitHub or Google account.
Want to learn more? Find more Lilypad code samples in both our [docs](/docs/lilypad) and on [GitHub](https://github.com/mirascope/lilypad). Lilypad offers first-class support for [Mirascope](/docs/mirascope), our lightweight toolkit for building [LLM agents](/blog/llm-agents).
Comparing LangChain vs LangSmith vs Lilypad
2025-08-06 · 7 min read · By William Bakst