LangSmith is one of the most widely adopted platforms for managing and evaluating prompts in LLM applications, thanks to its integration in the LangChain ecosystem.
But LangSmith:
* Is closed source with no self-hosting option (unless you’re using a special setup with Docker or have an enterprise license).
* Treats prompts as static text templates, disconnected from the code and runtime context that actually influence behavior.
* Is tightly coupled with LangChain, offering a first-class experience there, but raising concern for teams trying to avoid vendor lock-in.
Other frameworks address some of LangSmith’s limitations. In this article, we’ll compare LangSmith with two other (open source) frameworks:
* **Langfuse**, an observability and evaluation platform that allows self-hosting, and which also allows you to track and trace prompts.
* [**Lilypad**](/docs/lilypad), our own LLM observability framework for managing and evaluating prompts, which also supports self-hosting. It captures not just the prompt text but its full behavioral context, including inputs, settings, and logic, and encapsulates this in a versioned function. This makes prompt management feel more like software engineering, where prompts are integrated, versioned, and tested as part of the codebase, rather than treating them as isolated text artifacts disconnected from your app logic.
We examine two key areas in each of these platforms:
* [Setting up and running prompts](#setting-up-and-running-prompts)
* [Running evaluations](#running-evaluations)
## Setting Up and Running Prompts
### LangSmith: Creating and Editing Prompts
LangSmith treats prompts as reusable, version-controlled text templates that are managed as standalone assets. By default, it builds on LangChain’s prompt abstractions, notably `ChatPromptTemplate` and `PromptTemplate`, which also conform to LangChain’s runnable interface. This means prompts are expected to behave like serialized, executable components rather than plain text strings.
While this structure brings consistency by enforcing typed, versioned templates, it also encourages viewing prompts as isolated artifacts.
You [manage prompts in LangSmith](/blog/langsmith-prompt-management) using either the UI or SDK:
#### LangSmith UI
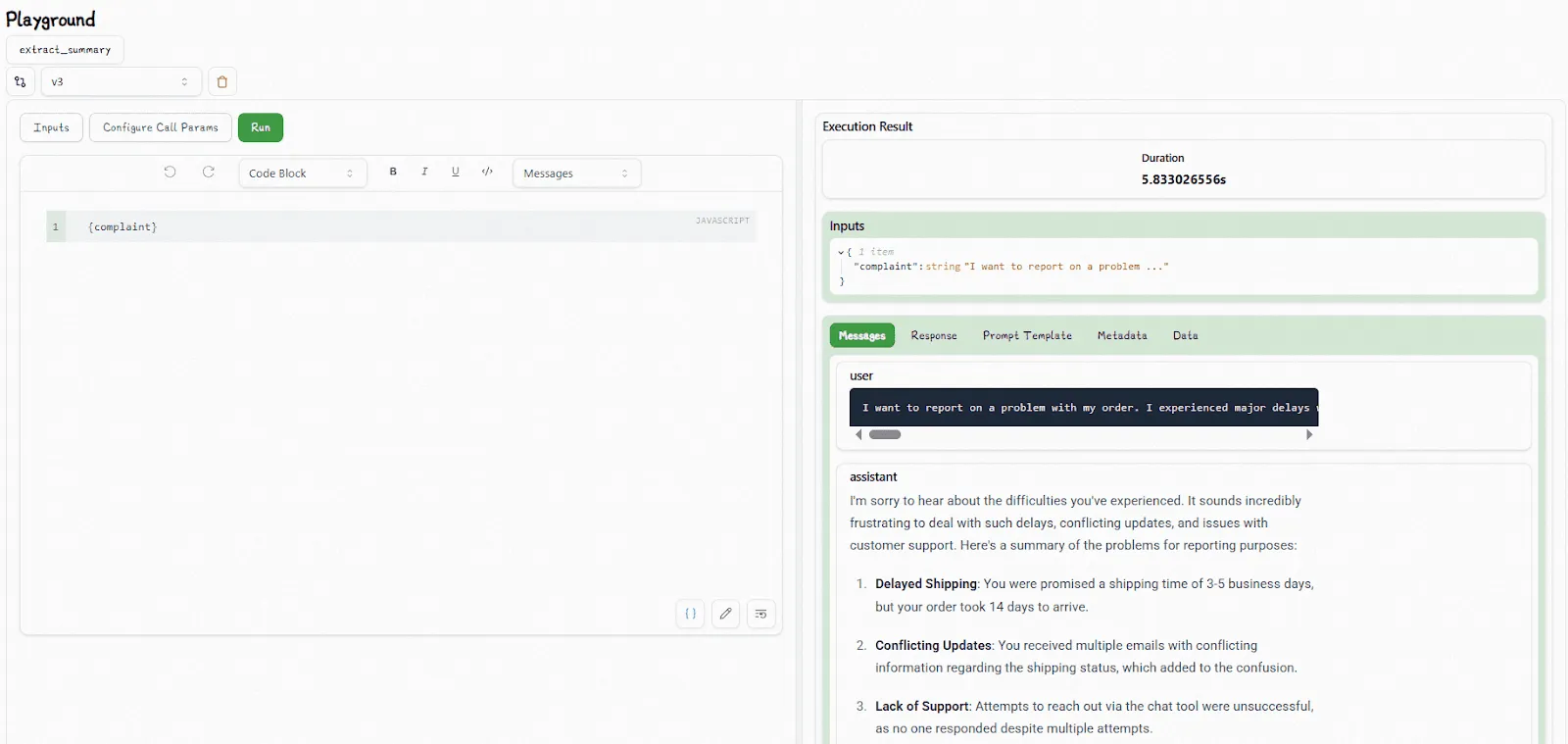
The user interface lets you try out different prompts and spin up experiments, evaluating them using datasets and reviews (automated or manual). We create a prompt called `extract_summary` that summarizes a customer complaint in one sentence:
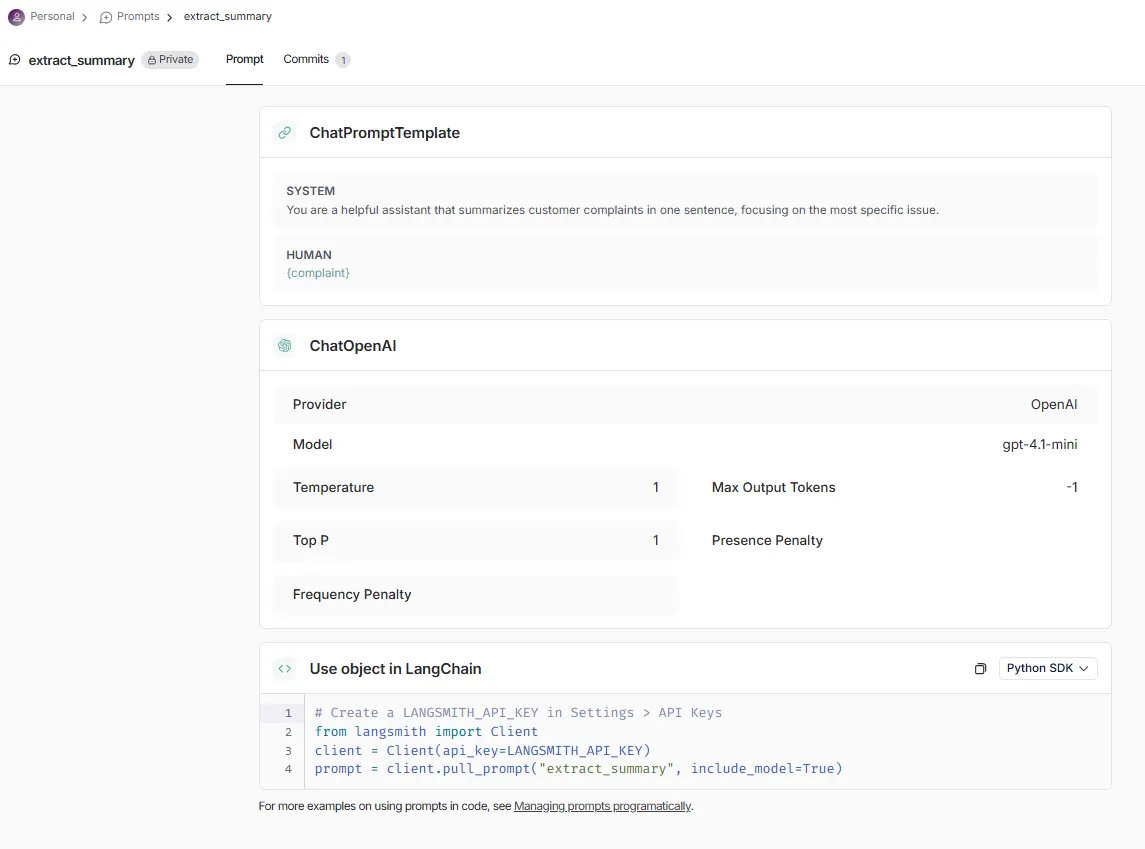
By default, `PromptChatTemplate` expects a sequence of messages with assigned roles, so we use the default `system` and `user` roles in our simple example. The template lets us specify various settings for large language models as well.
We then open this prompt in the playground, where we can test it and iterate:
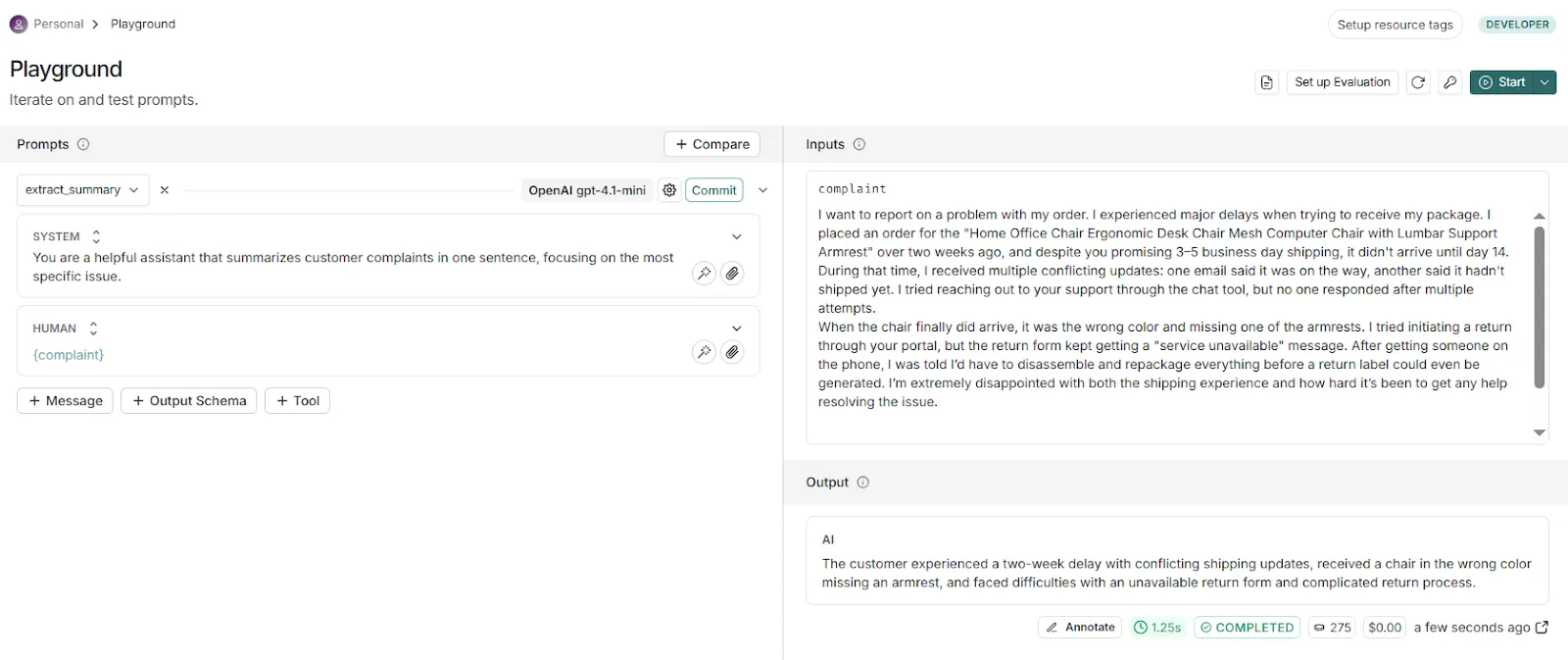
This prompt is simple, but for more complex prompts LangSmith also offers a prompt canvas, which can be accessed from the playground and provides an LLM-based assistant if we need help.
For instance, we can ask it to revise the prompt so that it focuses instead on identifying the root cause of complaints:
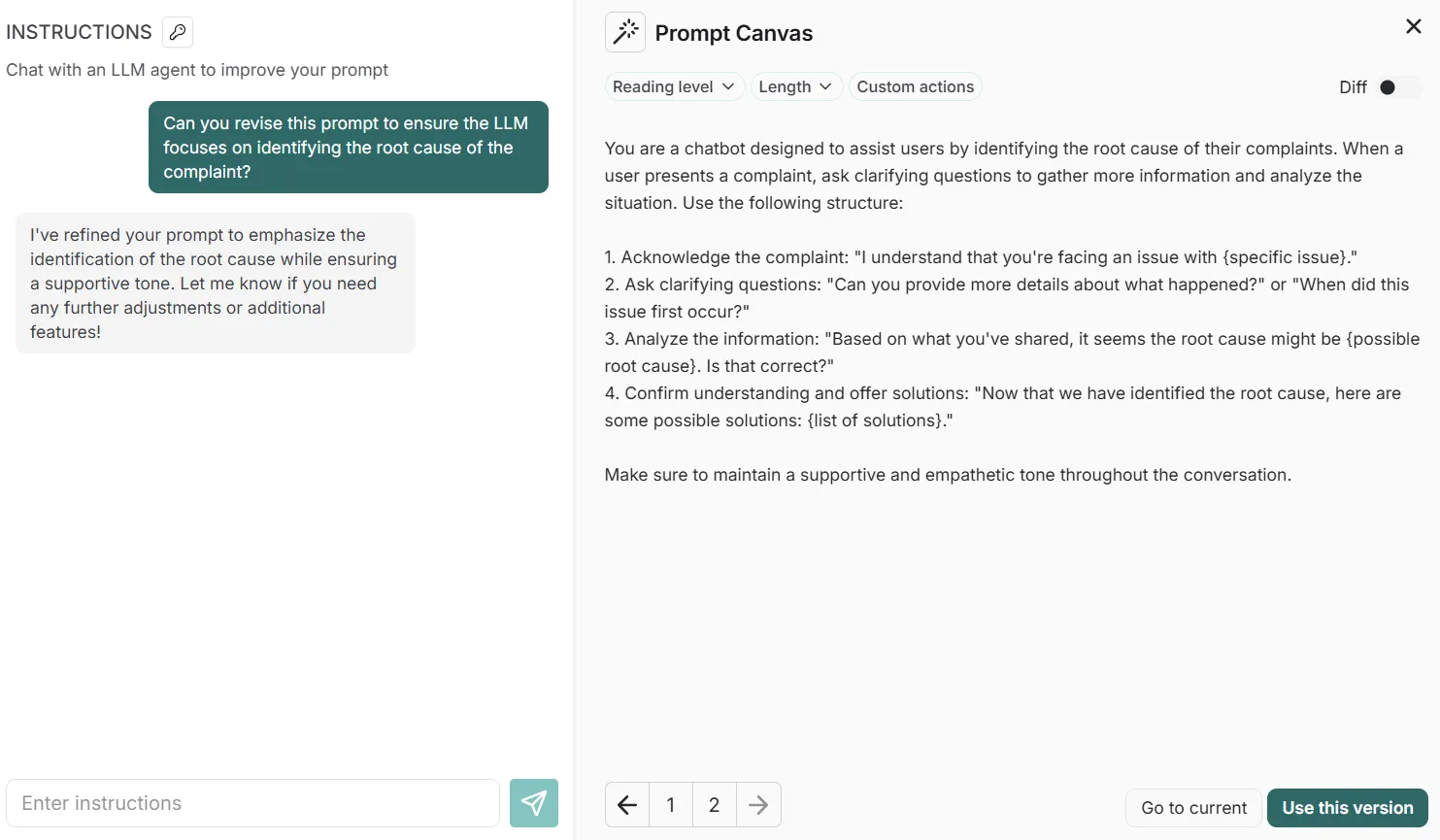
You save prompts manually by clicking buttons like “Use this version” in the prompt canvas above, and the commit generates a unique SHA-based identifier. Versions can also be further tagged with unique identifiers like `prod`, `qa`, and `beta` to track prompt deployments across environments.
LangSmith allows users to run traces on prompts executed in its playground to view values like inputs, outputs, costs, number of tokens, trace spans, etc.
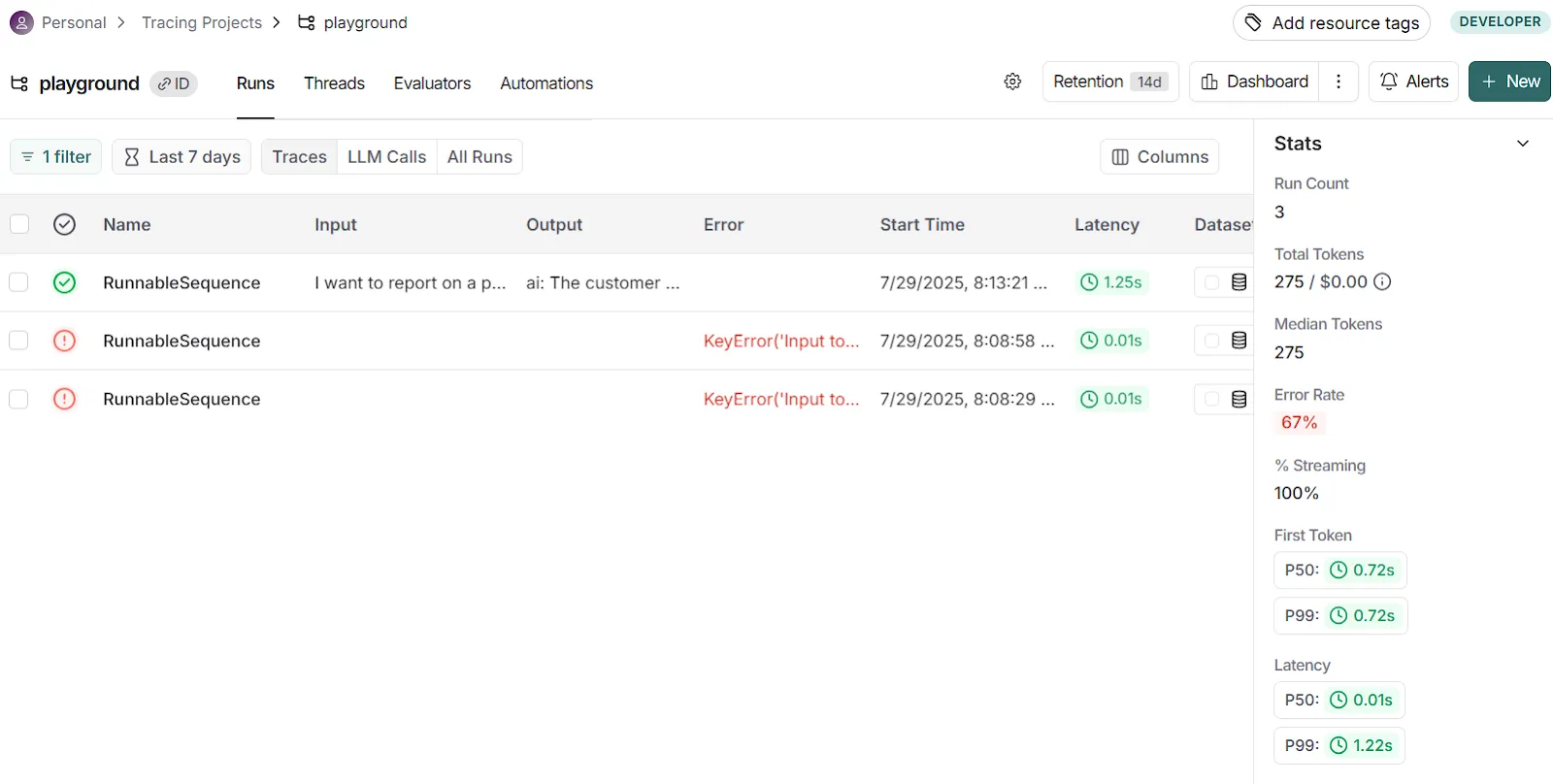
#### LangSmith SDK
The SDK, available in Python and TypeScript, integrates directly into CI/CD pipelines and LangChain workflows by enabling users to push, pull, tag, and evaluate prompts directly from code, according to their specific needs.
For example, you can write new prompts and push them to LangSmith using `client.push_prompt()`, which uploads your prompt template along with optional tags or descriptions:
```python
from langsmith import Client
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate([
("system", "You are a helpful assistant that summarizes customer complaints in one sentence, focusing on the most specific issue."),
("user", "{complaint}"),
])
client.push_prompt("extract-summary", object=prompt)
```
You can fetch a given version of a prompt using `client.pull_prompt(prompt_name:commit_hash)`, and can list all your prompts using `client.list_prompts()` or clean up old ones with `client.delete_prompt()`.
If you want to share prompts publicly, you can push them to LangChain Hub, a community repository.
At first glance, this seems like a convenient way to share prompts with others, but this mostly allows you to share prompt instructions with little further context. This design assumes prompts are separate from the codebase, which can lead to drift and make debugging harder because it disconnects prompt behavior from the logic that actually uses it.
Lilypad (which we describe further below) takes the opposite approach, treating prompts not as standalone text blobs but as versioned functions embedded in real code. This captures the full behavioral context, including inputs, logic, and settings, so that prompt behavior stays tightly coupled to the application code that drives it.
### Langfuse: Working with Prompts
Langfuse defines a prompt as a versioned, named object that includes the prompt text, dynamic variables, and some configuration details. As in LangSmith, prompts are kept separate from the application code. That means they don’t include context such as the surrounding logic or functions.
On the other hand, Langfuse‘s LLM observability allows developers to update, test, and release new versions of prompts without having to touch the main codebase or start a new deployment.
You can work with prompts either through the Langfuse web console or via their SDK.
#### Langfuse Console
The Langfuse Console is the main hub where users interact with the platform and helps them debug, analyze, and improve LLM applications. From the console, users can access all of Langfuse’s key features, like tracing, prompt management, evals, and performance analytics.
Much like LangSmith’s UI, the Langfuse Console is straightforward to use for prototyping. After setting up an account, just go to the “Prompts” area in the left sidebar and click “New prompt.” Here, we’ve set up `extract_summary`, as we did with LangSmith earlier:
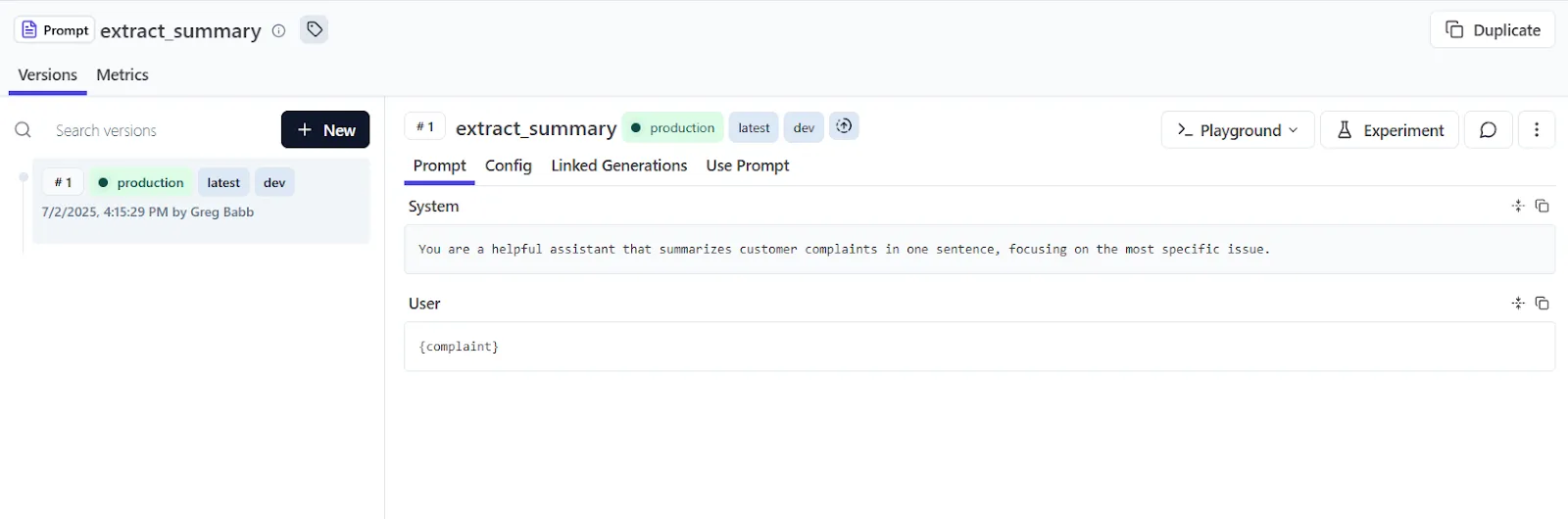
We then click the “Playground” button and enter our example customer complaint for the LLM to summarize, which we find at the bottom of the screen:
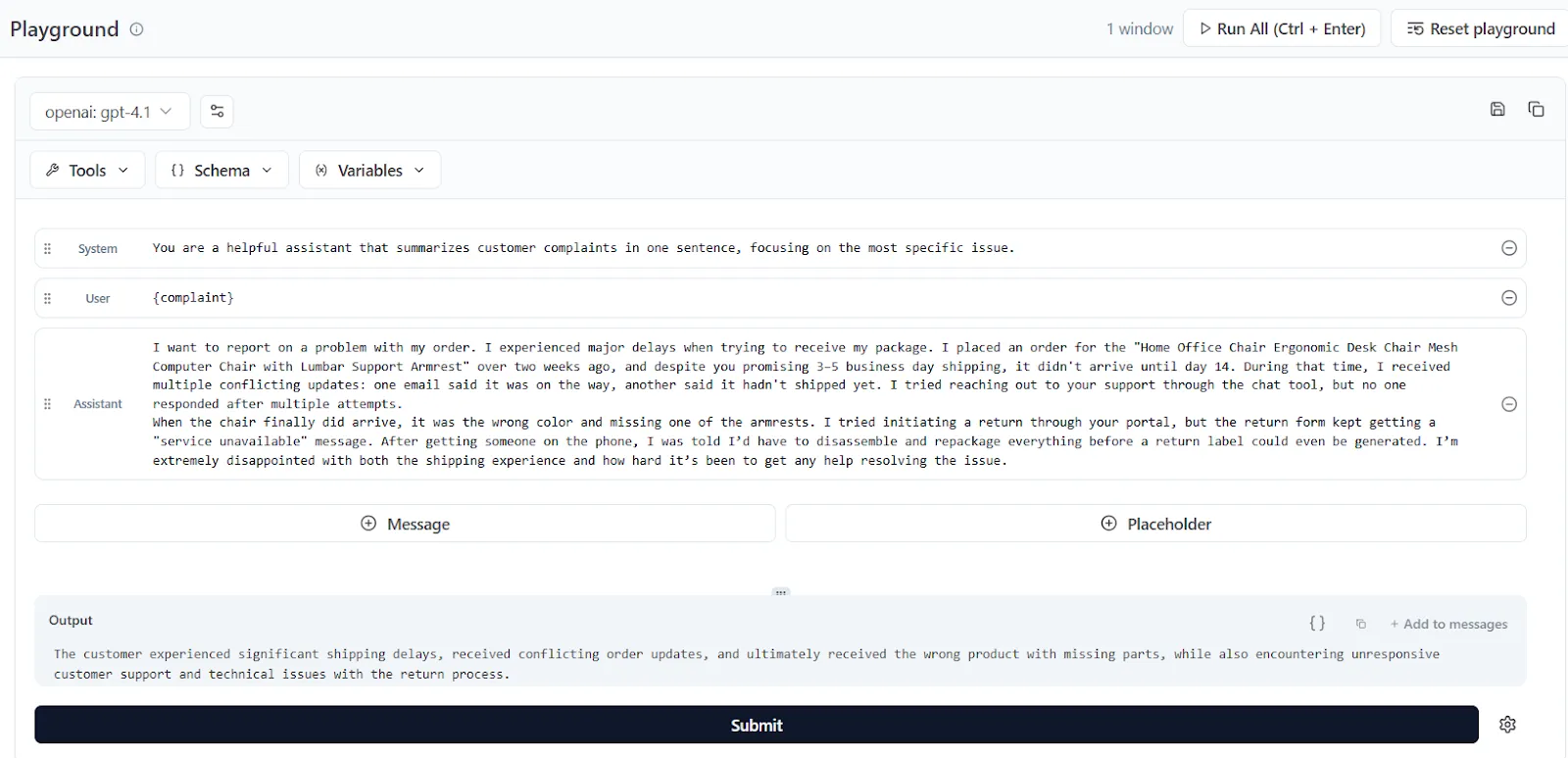
The system offers developers basically the same functionality for prompt management as in LangSmith, including a playground, the ability to tag prompts (like `prod` or `dev`), change model settings, and leave comments on prompts.
To update a prompt’s version we need to manually save it in order to create a new version, but one difference with LangSmith is that Langfuse uses regular integers as version numbers, unlike LangSmith’s SHA-based commit IDs.
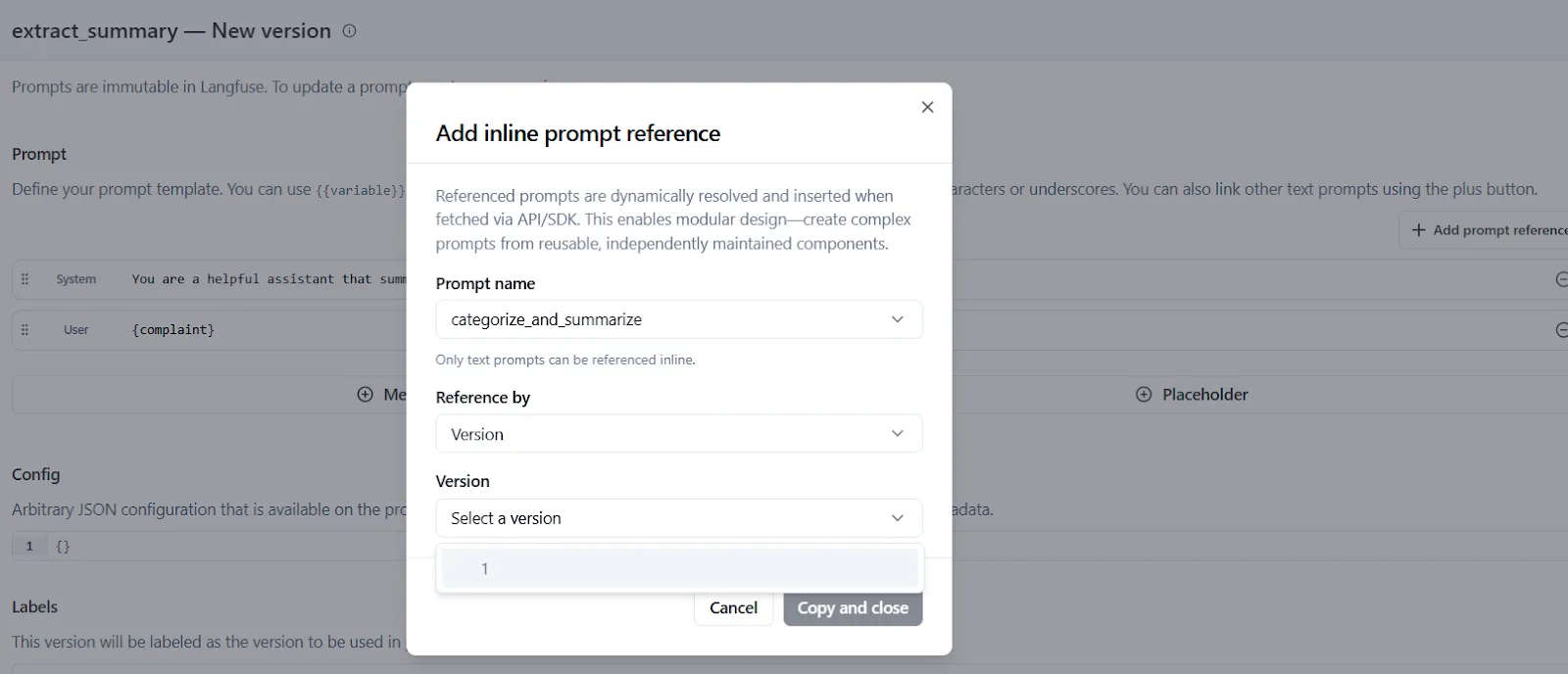
The console also allows you to reference existing prompts from within others (known as prompt composability) with the “Add prompt reference” button in the playground. This inserts a tag like: `@@@langfusePrompt:name=OtherPrompt|label=production@@@` directly inside the prompt, which pulls in the content of another prompt version:
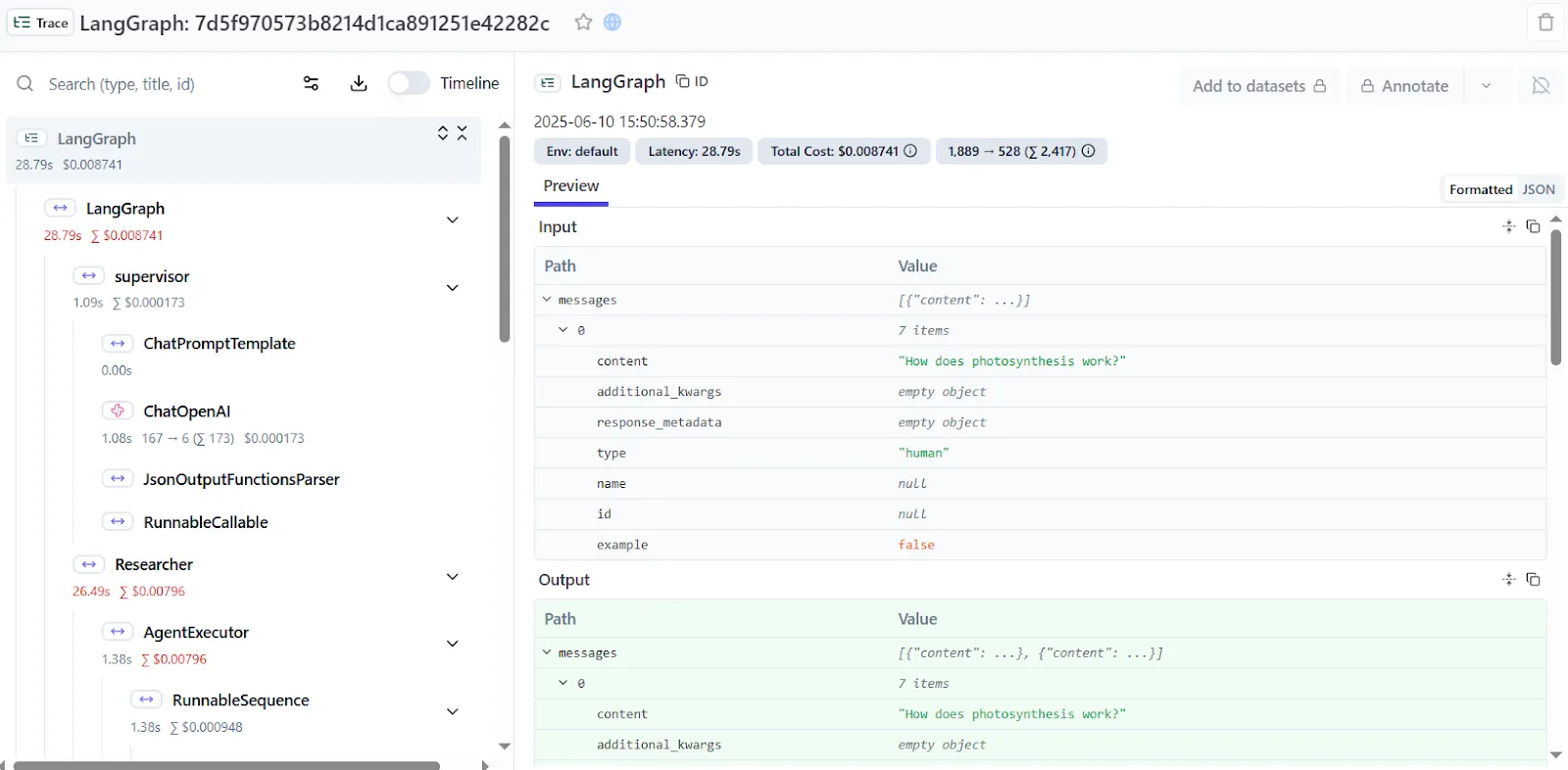
The Langfuse Console also allows you to trace outputs and view metadata in real-time for individual spans like costs, latency, tokens used, LLM responses, and more.
#### Langfuse SDK
The SDK is useful for teams wanting to integrate prompt management into larger workflows.
You programmatically create prompts using the `create_prompt` method:
```python
from langfuse import Langfuse
langfuse = Langfuse()
langfuse.create_prompt(
name="extract-summary",
type="text",
prompt="You are a helpful assistant that summarizes a customer {{complaint}} in one sentence, focusing on the most specific issue.",
labels=["production"], # immediately tag this version as “production”
config={
"model": "gpt-4o",
"temperature": 0.7,
"supported_languages": ["en", "fr"],
}
)
```
If a prompt with that name already exists and there are changes, Langfuse automatically creates a new version. You can also assign one or more labels like `”production”` to point to this version, so it gets used by default in your application. Labels act as pointers that map to specific prompt versions.
You can fetch prompts by referencing their name using `get_prompt`:
```python
prompt_obj = langfuse.get_prompt("extract_summary")
final_text = prompt_obj.compile(complaint="I want to report on a problem with my order. I experienced major delays when trying to receive my package...")
print(final_text)
# -> "The customer experienced a two-week delay with conflicting shipping updates..."
```
Here, `get_prompt("extract_summary")` fetches the latest version tagged with the “production” label. The `prompt_obj` contains a template with the placeholder `{{complaint}}`. When you call `prompt_obj.compile(...)`, those placeholders get populated with your variables at runtime.
Note that the SDK caches prompts locally after the first fetch to reduce latency. Also, Langfuse’s prompt retrievals aren’t type-safe (unlike Lilypad’s) and so there’s no automatic check to make sure `get_prompt` receives the correct template arguments.
Using labels like "latest" (which always point to the most recent version), you can build workflows to promote versions, like creating a new prompt version in code, tagging it as staging, testing it, then updating the production label to promote it.
### Lilypad: Prompts With Full Context
Because LLM outputs can vary even with the same input, tracking only the prompt text isn’t enough. This is the essence of [context engineering](/blog/context-engineering), and it’s where Lilypad differs from tools like LangSmith and Langfuse by capturing the *entire* context behind every LLM generation.
Even if you can’t reproduce the exact output, Lilypad lets you recreate the conditions under which it was produced. It does this by wrapping everything that influences the generation (prompt text, model settings, variable logic, inputs, outputs, and supporting code) inside a Python function decorated with `@lilypad.trace`:
```python
import lilypad
from openai import OpenAI
lilypad.configure(auto_llm=True) # [!code highlight]
client = OpenAI()
@lilypad.trace(versioning="automatic") # [!code highlight]
def extract_summary(complaint: str) -> str:
completion = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "assistant", "content": f"You are a helpful assistant that summarizes customer complaints in one sentence, focusing on the most specific issue."},{"role": "user", "content": f"{complaint}"} ]
)
return str(completion.choices[0].message.content)
response = extract_summary("I want to report on a problem with my order. I experienced major delays when trying to receive my package...")
print(response)
# > The customer is frustrated with significant shipping delays, receiving incorrect...
```
This treats prompts as full-fledged software artifacts rather than simple templates. It gives developers prototyping tools to:
* Version, debug, and compare entire prompt behaviors, not just the text.
* Reproduce and trace LLM calls with complete context, including code, inputs, outputs, and settings.
The sections below show how Lilypad applies this approach to [prompt optimization](/blog/prompt-optimization) in its UI and SDK.
#### Lilypad UI
When you decorate a function that wraps an LLM call with `@lilypad.trace`, it becomes part of Lilypad’s traceability model and you can work with its prompt in the UI.
The prompt remains part of the underlying function (type safe and versioned) which avoids the brittleness common in systems that separate prompts from the codebase.
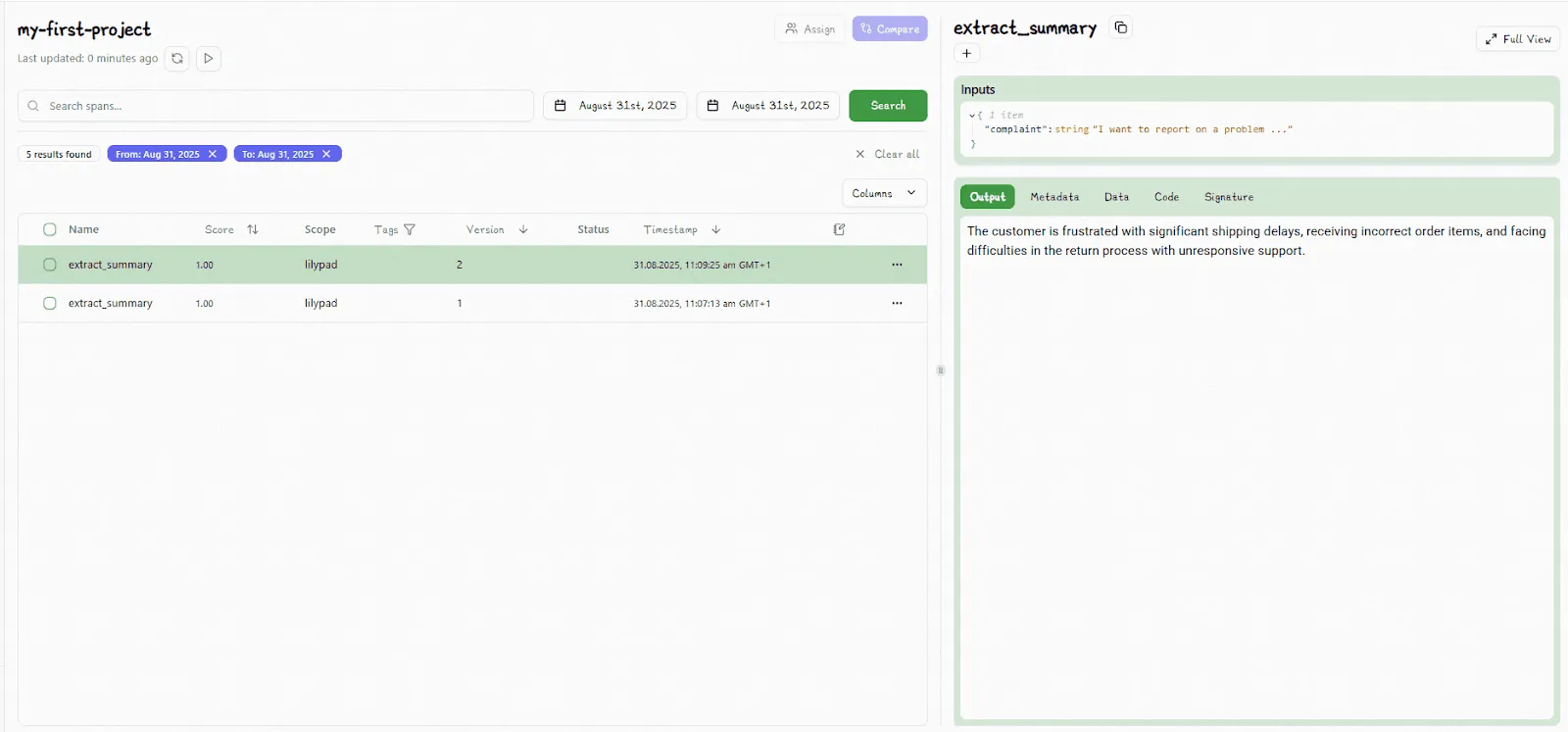
By adding the argument `versioning="automatic"` inside of the decorator, you ensure all changes made within the scope of the function closure are automatically versioned.
The Lilypad UI allows you to directly compare different versions by selecting any two versions and clicking the “Compare” button:
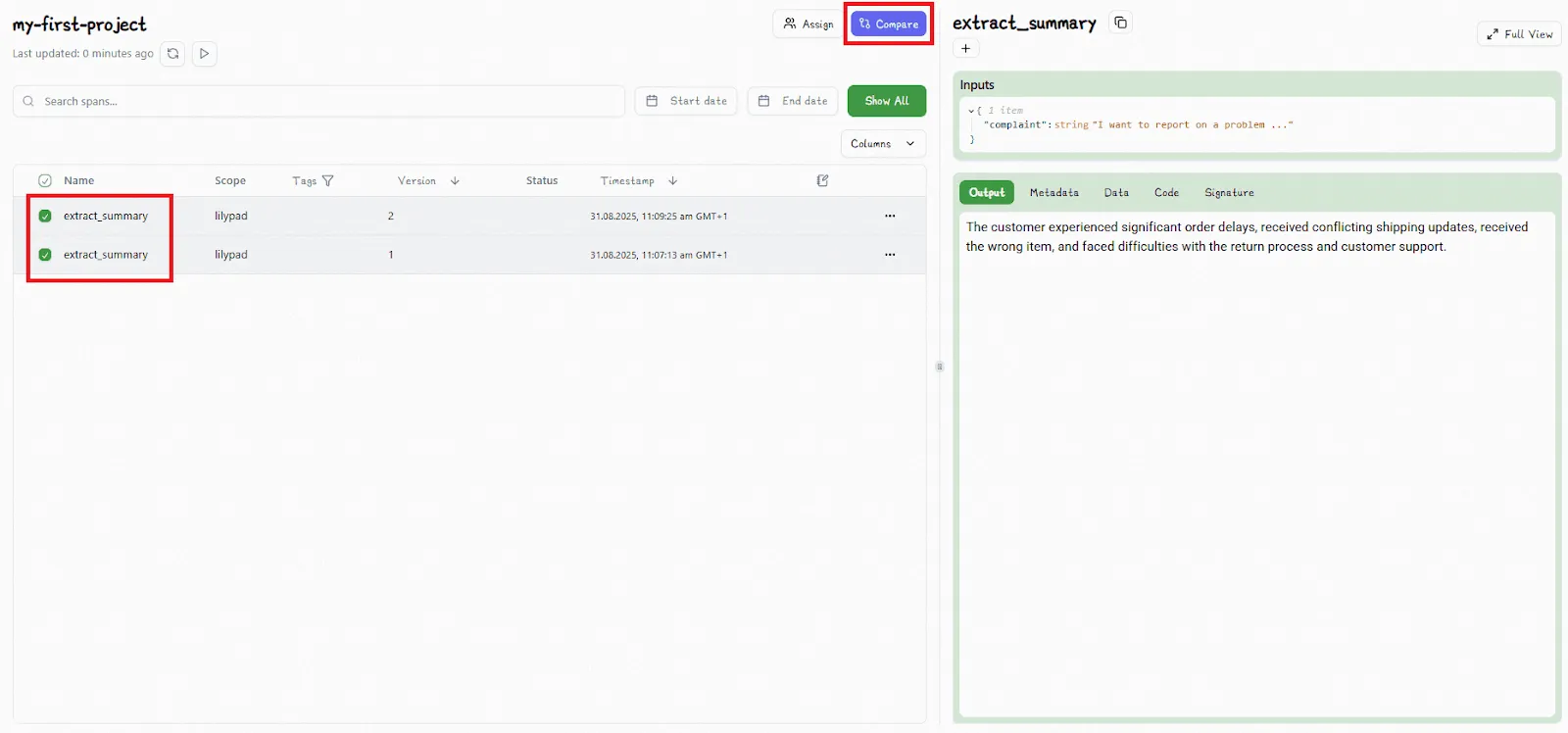
You then view the outputs and metadata for each version side by side:
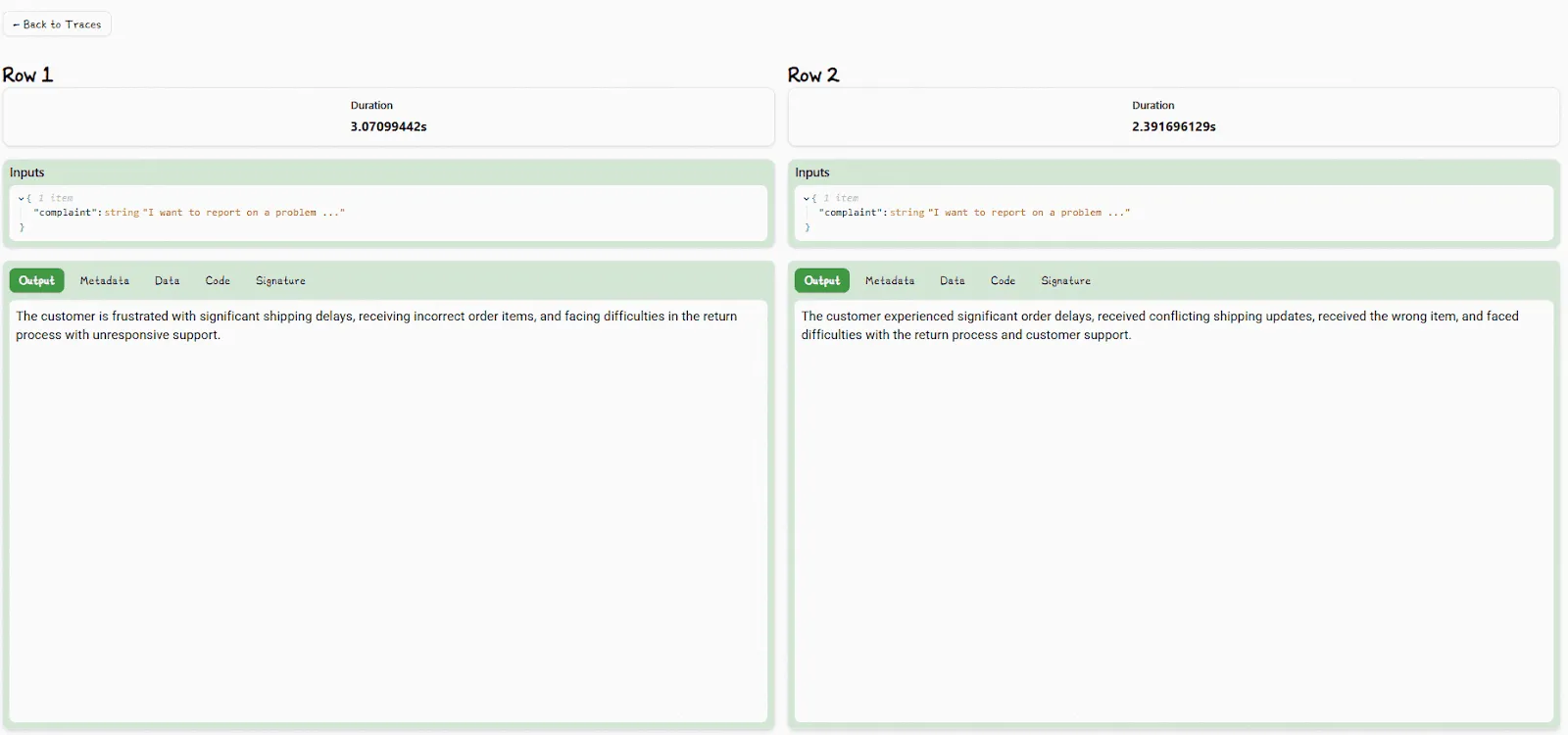
You can also view detailed trace data (like latency, cost, token usage, inputs, etc.) about any LLM call in real-time. Lilypad uses the [OpenTelemetry GenAI spec](https://opentelemetry.io/) to produce a full record of a model's execution path.
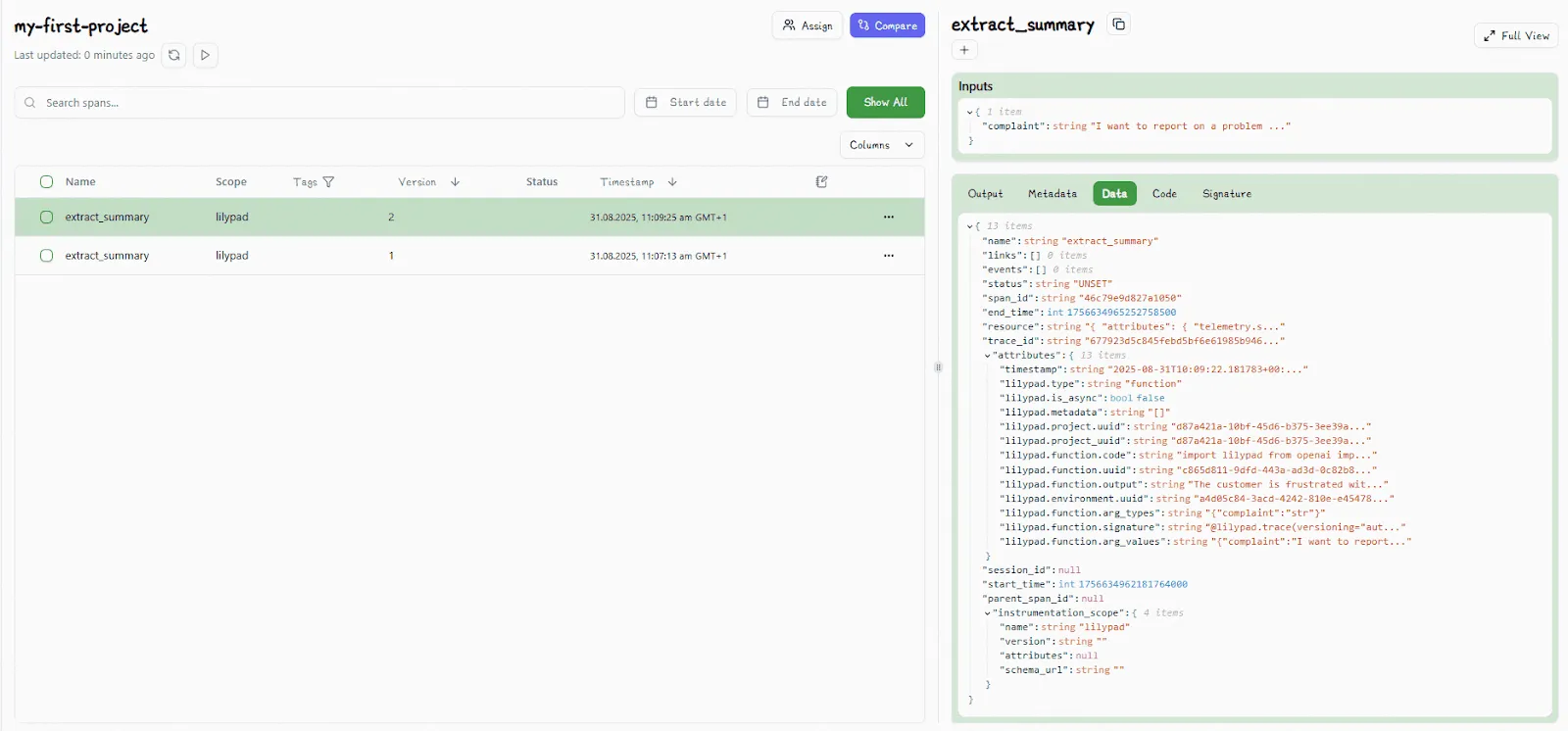
Non-technical team members (like SMEs and domain experts) can use the playground to create and edit markdown-based prompt templates using typed variable placeholders for inputs. Prompt optimization tasks, like rewriting a sentence or changing a model setting will generate new versions of the underlying function behind the scenes.
All prompt edits are sandboxed by default, so changes stay isolated until a developer explicitly integrates the approved version, with nothing going live without review.
#### Lilypad SDK
Our SDK provides an open source framework allowing you to integrate prompts into production-ready [LLM applications](/blog/llm-applications) and AI agents.
For example, you can access and re-run any specific version of a Python function that has been decorated with `@lilypad.trace(versioning="automatic")` via the the `version()`method:
```python
response = extract_summary.version(3)(complaint)
```
This can be useful for comparing different LLM outputs for purposes of A/B testing, prompt optimization, or ensuring safe rollbacks.
Lilypad’s SDK allows you to do everything you can do using the UI, including annotating traces, which we describe in the next section.
Lilypad doesn't lock developers in and is framework agnostic, allowing developers to retain full control over their AI stack. It works with any underlying LLM application development toolkit, like Mirascope or Langchain.
[Mirascope](https://github.com/mirascope/mirascope) in particular simplifies building with LLM applications and AI agents by providing pythonic building blocks for prompt engineering, structured output, and function calling across numerous LLM providers.
Mirascope works together with Lilypad by turning Python functions into LLM API calls when you use Mirascope’s `llm.call` decorator:
```python
import lilypad
from mirascope import llm
lilypad.configure(auto_llm=True) # [!code highlight]
@lilypad.trace(versioning="automatic") # [!code highlight]
@llm.call(provider="openai", model="gpt-4o-mini")
def answer_question(question: str) -> str:
return f"Answer this question in one word: {question}"
response = answer_question("What is the capital of France?")
print(response.content)
# > Paris
```
`@llm.call` provides a unified interface for working with model providers like OpenAI, Grok, Google (Gemini/Vertex), Anthropic, and many others.
## Running Evaluations
### LangSmith’s Evaluation Workflow
LangSmith supports a structured, evaluation-driven workflow that focuses on predefined testing and metric-based comparisons.
At the heart of this system are datasets made up of input and output examples. These allow prompts to be tested systematically over their lifecycle against benchmarks to measure accuracy, relevance, and overall quality.
To get started, you need a dataset that contains input prompts along with either expected outputs or rules that define what counts as success.
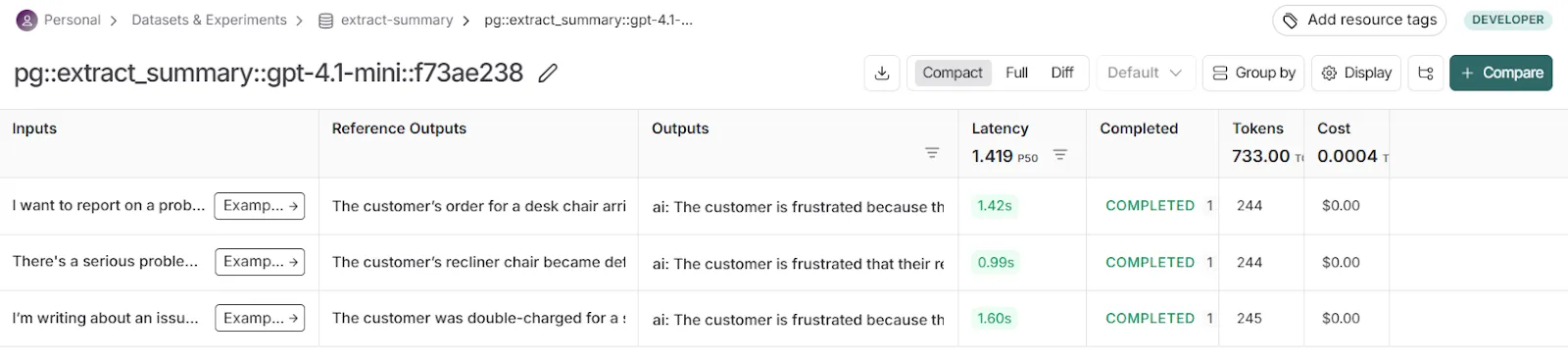
After you upload them to LangSmith, the sets let you test different prompt versions repeatedly and see how each change affects performance.
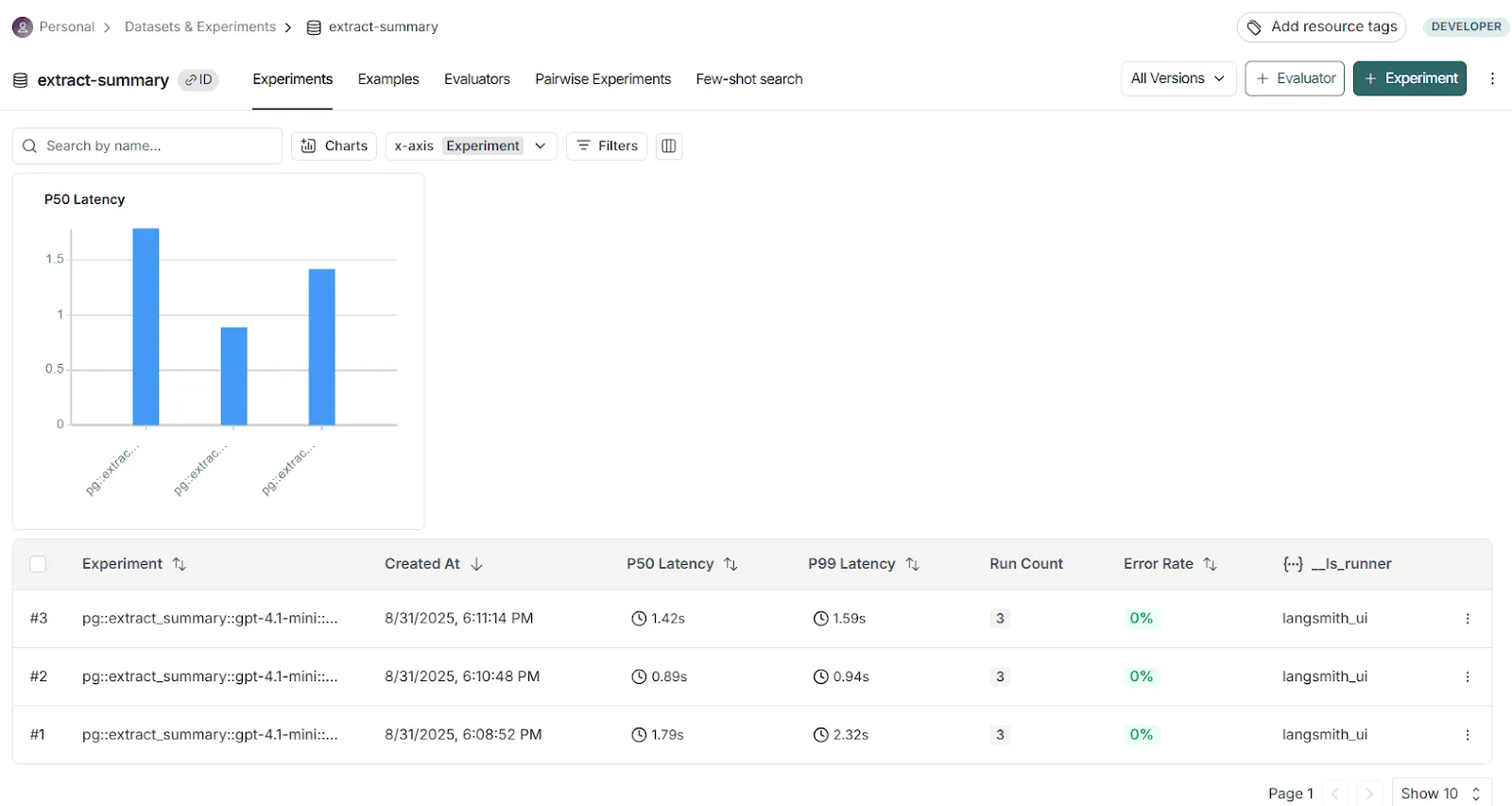
To make these evals reliable, LangSmith automatically logs and links each run to details such as:
* Prompt version (commit or tag)
* Model configuration
* Input/output traces
* Evaluation results
Evaluators can be automated AI judges, custom Python functions, or human reviewers. This lets you choose the right standard for output quality, whether you need strict accuracy or a more subjective measure of usefulness.
LangSmith often expects you to have benchmarks or test data on hand for evaluations, which works well when you know exactly what you’re testing for. But it’s less effective when you’re just starting out and figuring out what a good result looks like.
In that case, you have to stop, set up tests, and decide on success criteria before continuing. This setup mirrors traditional machine learning, where you need a dataset and scoring system defined from the start. But real-world prompt engineering is rarely so clearcut, and requiring predefined tests can slow down the process, especially when working in a fast-moving team environment.
### How Langfuse Handles Evaluation
Langfuse offers several ways to evaluate prompts, including [LLM prompt](/blog/llm-prompt) experiments, LLM-as-a-Judge, and manual annotations and feedback.
Prompt experiments are a feature of [Langfuse Prompt Management](/blog/langfuse-prompt-management) that let you test prompts against a fixed dataset of examples. In this setup, you create a dataset of input cases and reference outputs (ground truths), then run a specific prompt version on all of them.
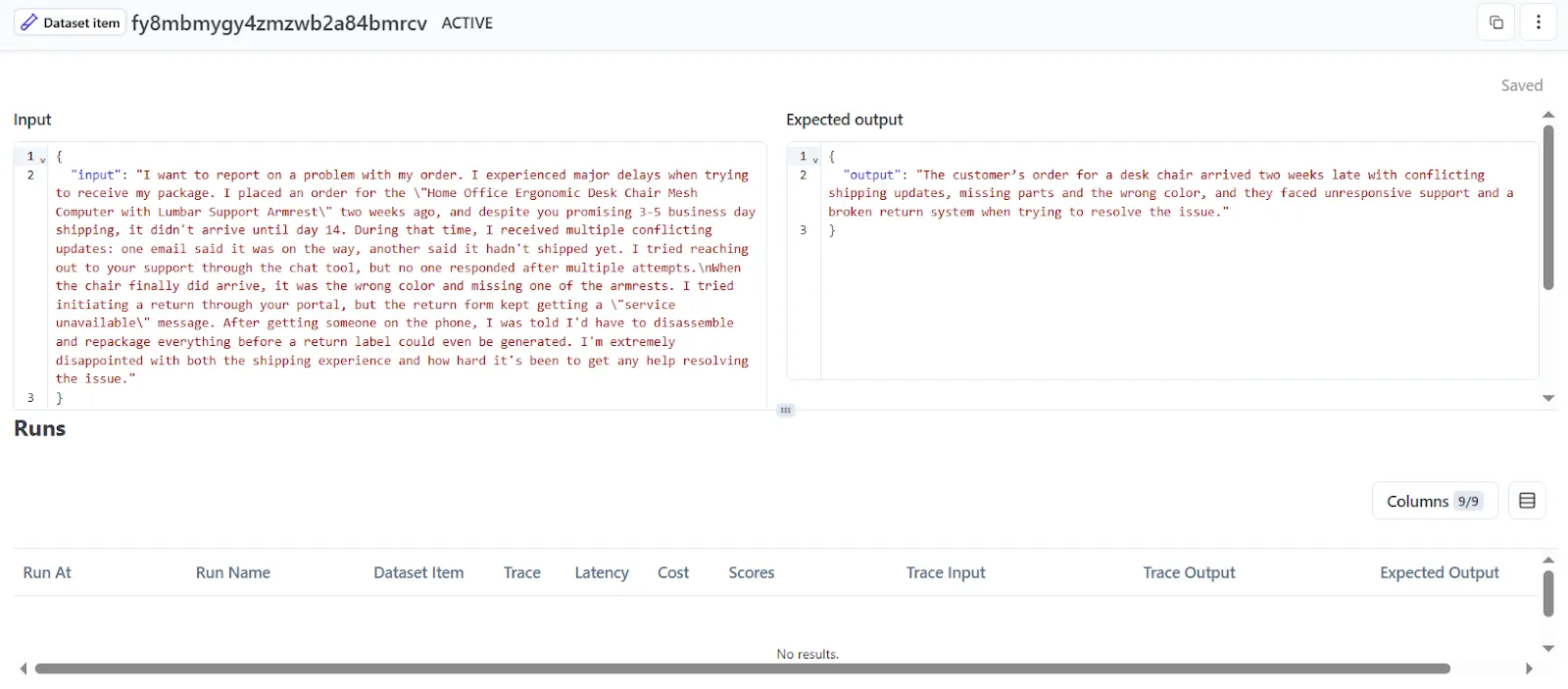
You pick a prompt and a dataset, map the dataset fields to the prompt variables, and run the prompt against the set.
Langfuse will generate outputs for each case and let you compare versions side by side. This allows you to spot problems when you change a prompt, since you can see if things got better or worse.
Prompt experiments in Langfuse can be used with LLM-as-a-judge evaluators to automatically score results and increase scalability. You simply choose the evaluator(s) in the UI, and Langfuse runs them across your dataset.
There are two ways to use LLM-as-a-Judge:
1. **Managed evaluators**: pre-built options and dashboards designed to check common quality metrics such as hallucination, relevance, toxicity, and helpfulness. These come with optimized prompts and settings, so you can get started quickly with little configuration.
2. **Custom evaluators**: your own tailored evaluators, where you select the LLM and define parameters like temperature and token limits to suit your needs.
You’re also not limited to automated scoring; you can also add manual annotations and collect direct user feedback. This is especially helpful in early development or for tasks where quality is more subjective.
For example, you can pick a set of traces and label each answer as “Correct” or “Incorrect,” or rate them on a 1–5 scale. These labels are stored as evaluation scores and are linked directly to the trace, just like any other performance metric. Langfuse also includes an annotation queue that lets you assign tasks to teammates and keep scoring consistent across the project.
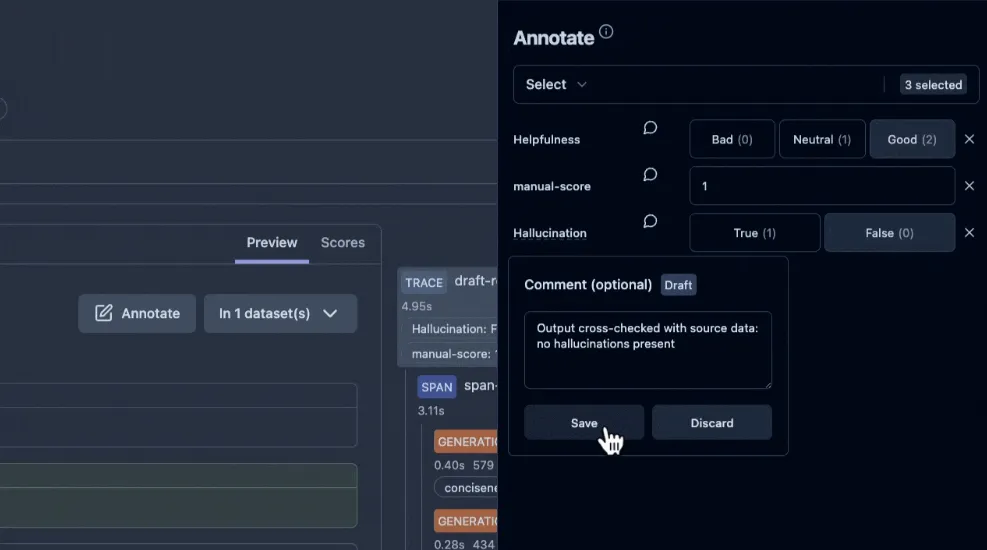
User feedback can be captured directly from your application as well, such as a chat interface with thumbs-up and thumbs-down buttons, or a star rating beside each bot response.
Langfuse collects this feedback through its SDKs or APIs and attaches it to the related execution trace. Feedback doesn’t even have to be explicit; it can also be implicit, such as whether the user accepted a suggestion or how much time they spent reading the output. Either way, Langfuse treats feedback as another score dimension, giving you an accurate picture of how your system performs during a prompt’s entire lifecycle.
### Lilypad’s Approach to Prompt Evaluation
When working with LLMs, we often face tasks that resist strict definitions of correctness. Summarizing a customer support ticket, for instance, **doesn’t have a “right” answer; it has outputs that are more helpful or less so**.
Traditional evaluation methods, like exact-match scores or numeric ratings, break down in such situations. For instance, when it comes to rating an output, we find that teams usually care less about whether it scored a 3 or a 4, and more about whether it’s good enough to use.
That’s why Lilypad uses pass or fail to denote whether an output meets the bar for usefulness. And in case an output is labeled as “Fail,” users can annotate why.
Lilypad also takes a trace-first approach to evaluation. Instead of requiring predefined datasets and fixed expected outputs, it automatically logs each prompt execution as a fully versioned trace. These traces serve as real-world [LLM evaluation](/blog/llm-evaluation) data, giving you a complete snapshot of the inputs, outputs, and context so you can evaluate performance without curating datasets upfront.
That means any trace can be opened and labeled with a Pass or Fail tag, along with an optional explanation that captures your reasoning.
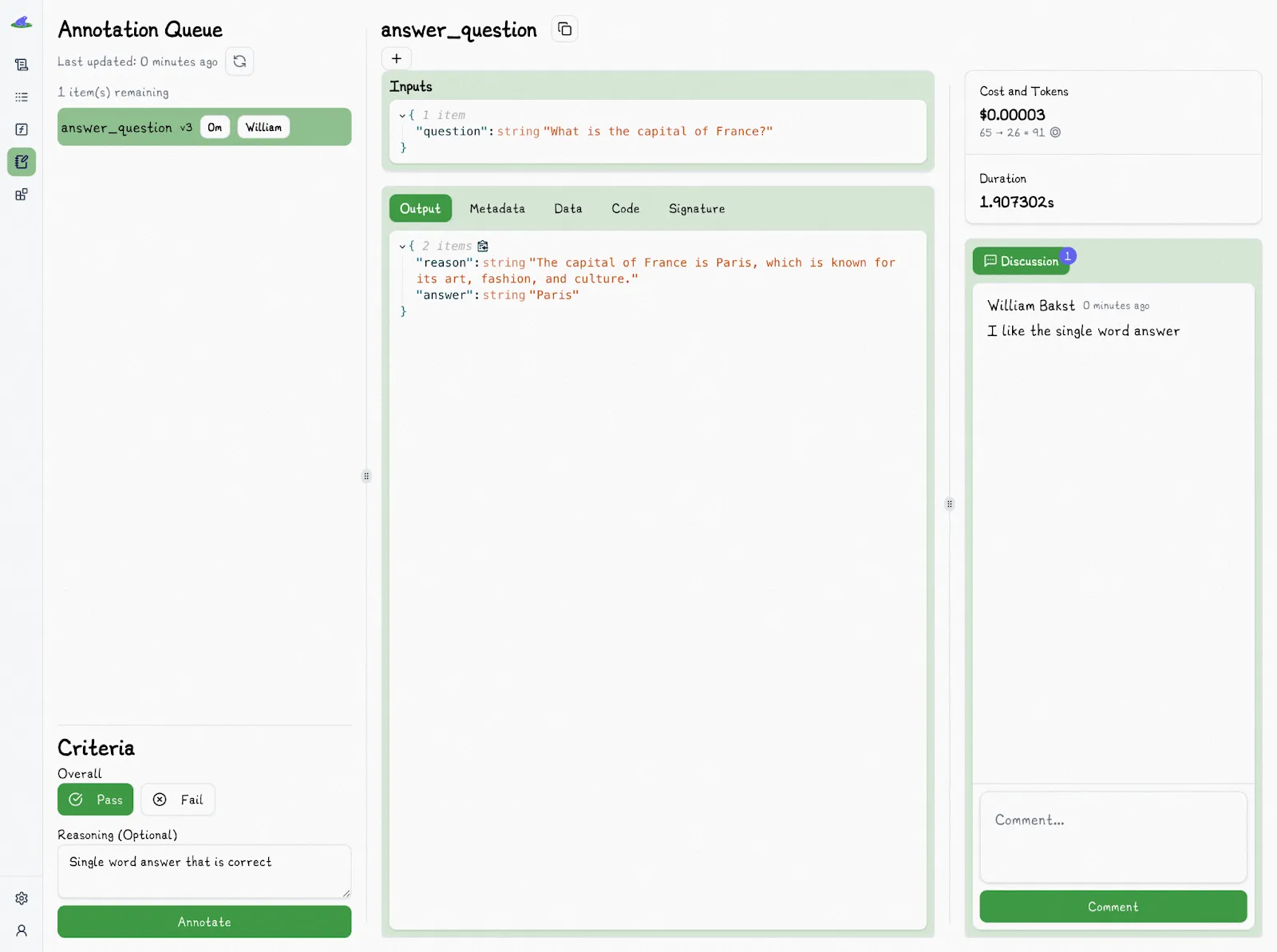
The Lilypad UI also offers collaborative features for evaluations, such as the ability to discuss specific traces with team members and assign evaluation tasks to them.
Lilypad assembles a dataset of human-labeled feedback, especially as you tag more outputs, so you can eventually use a custom [LLM-as-a-judge](/blog/llm-as-judge) to increase scalability and replicate your decisions, thereby automating the scoring process based on your own past annotations.
We nonetheless recommend manually verifying all outputs as this ensures reliability, quality, and trust in the system.
## From Experiments to Real Applications
Lilypad helps you bridge the gap between iteration and deployment. By treating LLM prompts as full functions, complete with type safety, metadata, and code context, you can version, test, and monitor your workflows with dashboards according to your specific needs like any other software component.
Want to learn more? You can find more Lilypad code samples in both our [docs](/docs/lilypad) and on [GitHub](https://github.com/mirascope/lilypad). Lilypad offers first-class support for [Mirascope](/docs/mirascope), our lightweight toolkit for building [LLM agents](/blog/llm-agents).
LangSmith vs Langfuse vs Lilypad: A Hands-On Comparison
2025-09-19 · 18 min read · By William Bakst