LLM application development is the process of building software that uses large language models as a core part of its functionality. Instead of running a model in isolation, developers integrate it into applications that can handle specific tasks like question answering, content generation, document summarization, or building AI-powered assistants like chatbots.
This matters because LLMs handle complex language tasks, like understanding intent, parsing user inputs, or generating responses, without the need for a rigid rules-based or manual logic approach. In practice, this makes your applications more intelligent and adaptable, allowing you to focus on creating better user experiences instead of hard-coding every interaction, which would be brittle.
But this process isn’t without its tradeoffs. For example, LLMs are non-deterministic, meaning the same input can produce different (yet valid) outputs. Without the right tools, it’s difficult to reproduce results, track prompt changes, or stay consistent across teams.
Some frameworks try to help, but they fall short by:
* Logging inputs and outputs, but not showing how a change to a prompt or setting affected results.
* Providing an environment where developers and non-technical teammates can work on prompts within a shared system of record, but decouple prompts from the application codebase.
* Offering ways to measure whether outputs meet intended goals, yet rely on complex evaluation standards rather than real-world benchmarks.
We built [Mirascope](https://github.com/mirascope/mirascope) and [Lilypad](/docs/lilypad) to overcome these shortcomings when designing and managing LLM applications. Our software lets you version, test, and iterate on prompts and model logic with the same discipline as traditional software.
In this article, we take a broad look at how LLM apps are built, the key steps involved, and the unique challenges they bring.
We also show a practical example of how to build a simple chat application using Mirascope, our lightweight toolkit for building LLM applications, and Lilypad, our open source framework for full-stack observability.
## 7 Essential Phases of Building LLM Applications
Building an LLM application usually follows a structured process, with each stage introducing its own considerations and tradeoffs.
Here are the core phases that apply across most projects:
### 1. Define the Scope of the Project
The first step is to clearly define what problem you want the LLM application to solve and what success looks like. This means outlining the project’s goals and narrowing down the use cases you’ll support in the first version.
Getting the fundamentals right here saves you time later, since it sets the direction for every technical and design decision that follows.
Think in terms of:
* **Task type**: Is this going to be predictive (e.g., sentiment analysis, classification) or generative (e.g., summarization, content creation)? This choice affects which model you use and how you evaluate results. Predictive tasks usually need clear answers and labeled datasets, while generative tasks focus more on writing good prompts and ensuring the output makes sense.
* **Business use cases**: Will the app be summarizing documents, generating customer responses, retrieving and ranking information, or triggering external actions like sending emails or updating a database? Defining these early helps align the technical design with real business needs.
* **Boundaries**: What’s in scope for this release, and what will be intentionally left out to keep the project focused? Starting small, for instance, makes it easier to measure success and make improvements.
Defining this scope upfront ensures you’re not building a general-purpose chatbot with no clear direction, for instance, but a focused application that achieves a specific goal.
### 2. Choose a Model
The foundation of any LLM app is the model itself: GPT-5, Claude, LLaMA, Mistral, and so on. Which one you pick depends less on brand and more on the type of application you’re building. A customer support bot might prioritize low cost and fast responses, while a legal summarization app might lean on models with stronger reasoning and accuracy.
There are also architectural considerations: closed-source APIs like GPT-5 give you strong performance without worrying about infrastructure, but they can be expensive and limit customization. Open-source models like LLaMA or Mistral offer flexibility to fine-tune and run locally, but you take on the overhead of hosting, scaling, and optimization.
Finally, the choice ties directly to how you’ll extend the system. Some models are easier to fine-tune, while others may integrate more smoothly with retrieval systems for retrieval augmented generation (RAG). Getting this decision right shapes everything downstream, from performance and cost structure to how maintainable your application will be in production.
### 3. Pick a Framework or Toolkit
Most teams don’t build everything from scratch. Popular frameworks like LangChain, LlamaIndex, and Hugging Face give you a broad ecosystem for chaining prompts, retrieval, and integrations. But such general-purpose frameworks can also feel heavy or opinionated if you just need a lightweight setup.
In these cases, developers can reach for lightweight, pythonic alternatives like [Mirascope](https://github.com/mirascope/mirascope) or [Lilypad](/docs/lilypad).
The key is matching the framework to your project. Your decision shapes not only developer experience but also how easy it’ll be to iterate, maintain, and evolve your application over time.
### 4. Design Prompts and Workflows
Prompts can be as simple as a direct question or as complex as a templated instruction that pulls in variables from user inputs or a database.
Because LLMs rely on machine learning rather than fixed rules, the way you design prompts plays a big role in shaping the quality and consistency of their outputs.
You’ll want to:
* Write clear instructions so the model understands your intent.
* Use templates to keep prompts consistent and reusable.
* Incorporate context through techniques like RAG, so the model can pull in facts instead of guessing.
The workflow around prompts involves how inputs are prepared, how outputs are evaluated, and how each step connects within the broader application pipeline.
Without the right tooling, much of your time can be lost troubleshooting unpredictable behavior rather than improving your app’s performance.
### 5. Connect to Data and APIs
Few applications rely on the model alone. They integrate with databases, APIs, retrieval/search systems, or custom knowledge bases so the LLM can provide context-aware, accurate answers. Beyond that, you can combine multiple services so your application isn’t just generating text but also taking action.
The challenge here is orchestration. Models don’t “know” when to call an API or how to validate results without a defined workflow. Developers usually need to define pipelines that manage how data flows in, gets processed, and then informs the LLM’s response.
Frameworks like LangChain popularized this kind of chaining, but they can be rigid (imposing their unique abstractions) or lock you into their ecosystem. In contrast, tools like Mirascope let you call models cleanly by using native Python functions (e.g., using a simple `@llm.call` decorator), so prompts, settings, and responses stay centralized and consistent across providers. Mirascope's modular approach makes it plug-and-play friendly with other tools, including using provider SDKs directly.
### 6. Test and Evaluate Outputs
One of the biggest challenges in working with LLMs is they’re stochastic and don’t always give the same answer for the same input. This makes testing trickier than in traditional software, where the same input should give the same result.
That’s why you need to check whether the outputs are consistently good, not just occasionally right. Without solid testing and comparison, it’s almost impossible to tell if your system is actually improving or just changing.
Developers typically run side-by-side prompt tests, track system settings, and compare outputs against real-world scenarios in order to understand what works reliably – far more than just once.
The pain point is that most frameworks don’t give you an easy way to track all this. For example, LangSmith only versions the prompt template and settings. But in practice, reproducibility also depends on the code that calls the model, the surrounding parameters, and any data preprocessing.
With [LLM monitoring tools](/blog/llm-monitoring-tools) like Lilypad, you get to version everything involved in your workflow, not just the prompt text. This means you can roll back, compare runs, and debug why a model produced a certain response. More on this [below](#3.-lilypad) in our description of the Lilypad framework.
### 7. Deploy and Monitor
Once an app works in a dev environment, the next step is getting it into production. Deployment means packaging the app for users, scaling infrastructure, and continuously monitoring costs, latency, and response quality. This stage ensures the app holds up under real-world conditions.
Practically, deploying [LLM applications](/blog/llm-applications) isn’t a one-and-done job. It’s an ongoing cycle of monitoring, validating, and optimizing, much like any other engineering discipline. And the right tooling helps you streamline this process, making it less of a guessing game.
## Which Framework Should You Use?
[LLM frameworks](/blog/llm-frameworks) provide the building blocks and interfaces that simplify app integration, prompt management, and performance evaluation. The wrong choice here can mean fighting your framework instead of focusing on your product.
There are many frameworks available, but in this section, we’ll examine three that capture different approaches to building with LLMs.
### 1. LangChain
LangChain is perhaps the most widely known framework for building with LLMs, and for good reason. It popularized the idea of “chains” and “AI agents” that let you connect prompts, models, and tools in sequence. It comes with integrations for vector databases, APIs, and evaluation systems, making it a go-to for tutorials and prototypes in generative AI.
The tradeoff, however, is complexity. It seems like LangChain offers an abstraction for just about anything you want to do, rather than relying on pure Python or JavaScript, and so many teams find themselves bending their apps to fit LangChain’s patterns instead of the other way around.
For example, features like `Runnable` and LCEL require explicitly connecting each step of the LLM workflow, like prompts, models, and parsers, into a structured pipeline, which can feel like unnecessary complexity for relatively simple use cases.
That said, LangChain offers strong features for RAG and its companion tool LangSmith adds monitoring, evaluation, and debugging capabilities.
LangSmith is especially useful for tracking and analyzing application runs, though it skips the critical detail of versioning the full code context, including callable parameters. That makes it harder to reproduce a specific run exactly as it happened or to track down the cause of unexpected behavior. Without this, developers are left doing more manual work to debug or verify results.
### 2. Mirascope
Mirascope is a lightweight Python toolkit that follows a *“use-when-you-need”* design philosophy. This means instead of imposing heavy abstractions or locking you into an ecosystem, Mirascope offers modular building blocks you can drop into your existing workflow as needed. This lets you spend more time building an app that solves problems and less on dealing with the constraints of your framework.
#### Python-first Approach to App Development
We believe LLM app development deserves the same engineering rigor, tooling, and best practices as traditional software systems. To support this, Mirascope leans into native Python (along with the Pydantic library). Ideally, if you already know Python, you already know Mirascope.
Tasks that other frameworks wrap in custom abstractions, like chaining steps or formatting prompts, remain clean, readable, and fully native in Mirascope. This keeps everything intuitive and transparent, while still giving you full control over scaling and managing your applications.
For example, while frameworks like LangChain rely on multiple abstraction layers like runnables, chain objects, and prompt templates for tasks, which tend to get in the way and obscure what’s happening under the hood, Mirascope uses [native Python and function chaining](/blog/prompt-chaining) so you can manage workflows directly. With fewer moving parts, you get more visibility into what’s going on, better control over execution, and far less overhead when you want to scale.
Some more benefits:
#### Consistent and Convenient LLM Calls
For some frameworks, important details like prompt formatting and model settings are usually scattered across the codebase. This makes it harder to manage changes and often forces developers to write extra boilerplate just to switch providers or keep things running smoothly.
Mirascope centralizes these concerns with the [@llm.call decorator](/docs/v1/learn/calls). You define the provider, model, and response format in one place. The interface is the same across providers like OpenAI, Anthropic, and Mistral, so switching is as simple as updating the provider argument, with no need to rewrite boilerplate.
To keep prompts clean and reusable, Mirascope also provides the [`@prompt_template` decorator](/docs/v1/learn/prompts). You can stack it with `@llm.call` on any Python function, keeping templates next to the logic that uses them:
```python
from mirascope import llm, prompt_template
from pydantic import BaseModel
class Book(BaseModel):
title: str
author: str
@llm.call(provider="openai", model="gpt-4o-mini", response_model=Book) # [!code highlight]
@prompt_template("Extract {text}") # [!code highlight]
def extract_book(text: str): ... # [!code highlight]
book = extract_book("Pride and Prejudice by Jane Austen")
print(book)
# Output: title='Pride and Prejudice' author='Jane Austen'
```
And if you pair it with Lilypad (our prompt engineering library, which we describe in more detail below), you get automatic tracing and [prompt versioning](/blog/prompt-versioning):
```python
from mirascope import llm, prompt_template
@lilypad.trace(versioning="automatic") # [!code highlight]
@llm.call(provider="openai", model="gpt-4o-mini", call_params={"max_tokens": 512})
@prompt_template("Recommend a {genre} movie")
def recommend_movie(genre: str): ...
response: llm.CallResponse = recommend_movie("comedy")
print(response.content)
# "You should watch *Superbad*. It's a hilarious coming-of-age comedy packed with awkward teenage moments and great one-liners."
```
#### Built-in Response Validation
Most frameworks don’t handle response validation, requiring you to write boilerplate to check if the LLM actually returned what you expected.
Mirascope solves this with its [built-in response validation based on Pydantic](/docs/v1/learn/response_models). You simply define what the output should look like, and Mirascope automatically validates it before returning. This built-in automation eliminates repetitive guardrails you’d otherwise code by hand, giving you a clean, type-safe Python object that becomes your function’s return value.
Hovering your cursor over a response in your IDE shows an inferred instance of your response model:
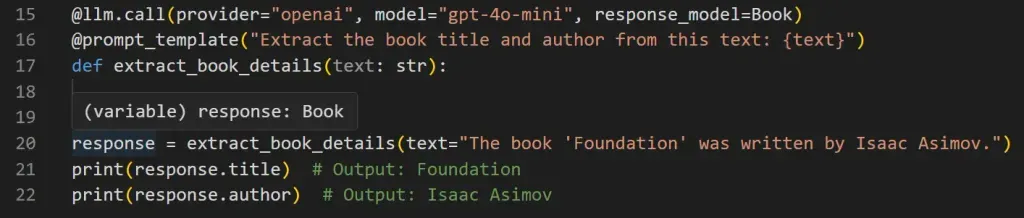
This means you immediately know whether the return type matches your expectations. Mirascope also provides autocomplete.
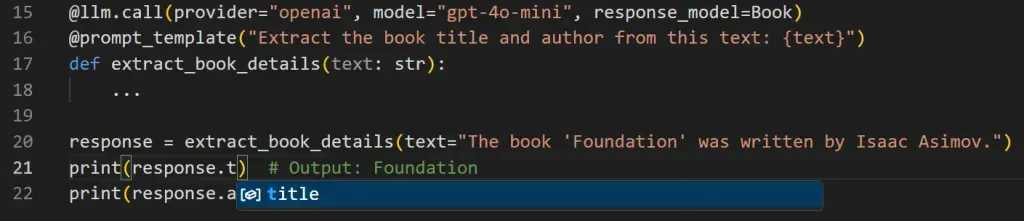
Whenever the output deviates from your model, Mirascope shows a clear ValidationError at runtime.
Start building scalable LLM applications with Mirascope’s [developer-friendly toolkit](https://github.com/mirascope/mirascope). You can also find code samples and more information in our [documentation](/docs/v1/learn).
### 3. Lilypad
Lilypad is built on the understanding that LLM outputs are inherently unpredictable, so every change to a prompt, and the context around it, must be tracked, since even small adjustments can lead to significantly different results.
#### Code-level Tracking
Unlike frameworks that focus only on prompt text, Lilypad captures the full context around each LLM call by wrapping it in a single Python function. It encourages developers to structure all the logic that influences an output, like input arguments, pre- and post-processing, and model settings, around that function and decorate it with `@lilypad.trace` for automatic tracking and versioning.
This makes experiments more reproducible, lets you compare versions side by side, and do [prompt optimization](/blog/prompt-optimization) step-by-step without losing sight of what actually changed.
In the example below, both the prompt and model settings live inside `answer_question()`, which is wrapped with `@lilypad.trace` in order to treat everything that affects the output as a single unit.
```python
from google.genai import Client
import lilypad
lilypad.configure(auto_llm=True)
client = Client()
@lilypad.trace(versioning="automatic") # [!code highlight]
def answer_question(question: str) -> str | None:
response = client.models.generate_content(
model="gemini-2.0-flash-001",
contents=f"Answer this question: {question}",
)
return response.text
response = answer_question("What is the capital of France?") # automatically versioned
print(response)
# > The capital of France is Paris.
```
Setting `@lilypad.trace` to `”automatic”` captures every change within the function’s closure as a versioned snapshot, no manual saving required. Each run is preserved with its full context, so you can easily revisit, compare, or re-run it later.
Lilypad instruments LLM outputs via the [OpenTelemetry GenAI spec](https://opentelemetry.io/), which also records surrounding context like messages, warnings, and other useful metadata.
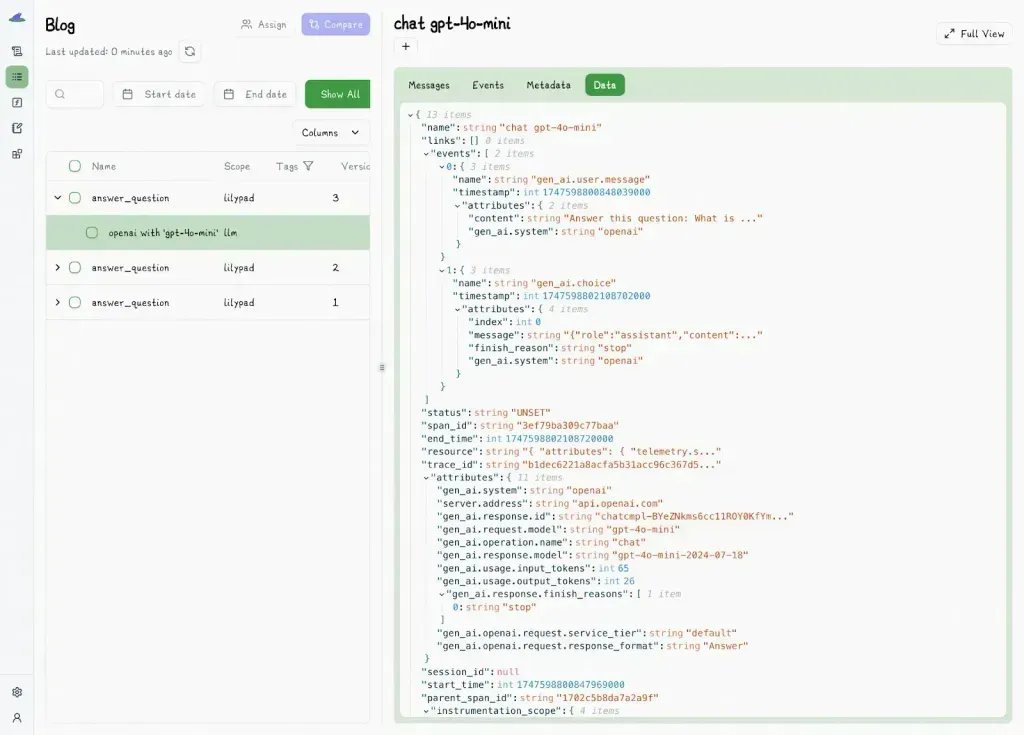
Developers can easily get specific snapshots using the`.version` method, which lets you access, compare, and rerun any saved version of a function.
```python
response = answer_question.version(3)("What is the capital of France?")
```
See the [Lilypad documentation](/docs/lilypad) for similar useful commands.
####
#### Prompt Management and Collaboration
Lilypad’s [advanced prompt engineering](/blog/advanced-prompt-engineering) bridges the gap between technical and non-technical teams by offering an intuitive playground for prompt management.
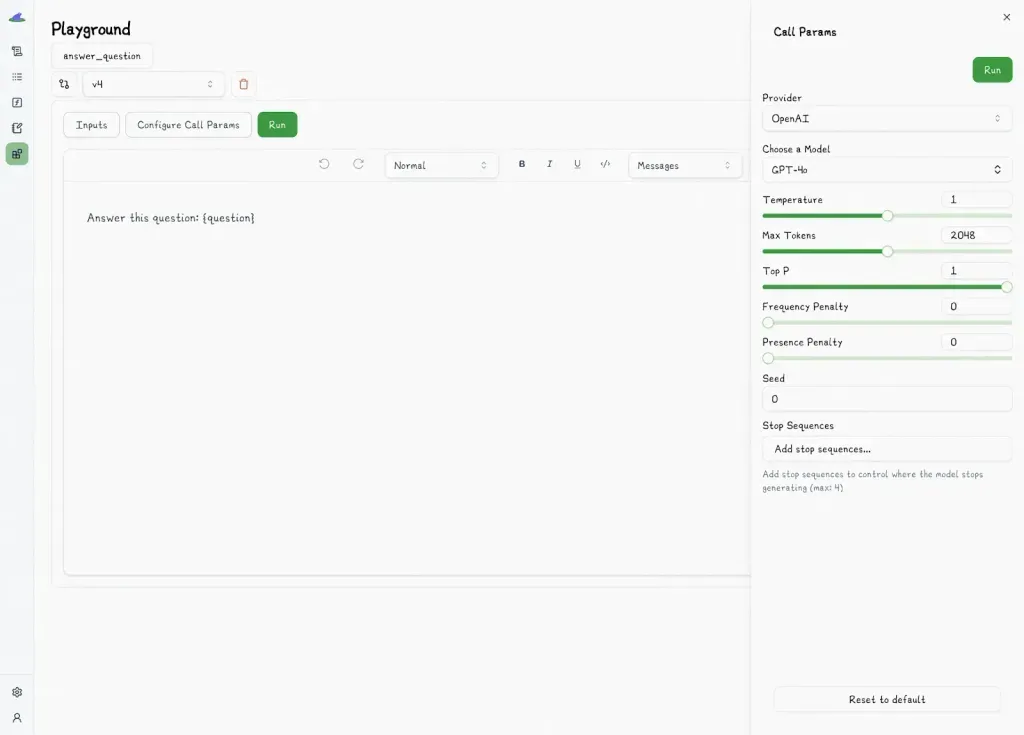
The playground supports multiple providers like OpenAI, Anthropic, Gemini, Mistral, OpenRouter, and more, including setting a default provider for an individual prompt.
Instead of requiring developers to update every tweak or experiment, subject matter experts can step in, make changes, and validate updates themselves.
Inside the playground, SMEs can:
* Edit prompt templates directly in the markdown editor, complete with `{variables}` for dynamic content.
* Fill in those variables through auto-generated forms tied to the underlying Python function signatures.
* Catch errors instantly with real-time validation, so mistakes never slip through unnoticed.
Every edit lives in a sandbox until it’s explicitly approved, ensuring nothing accidentally slips into production.
This separation is only virtual; it doesn’t change how prompts are stored or deployed. Prompts in Lilypad map directly to the same versioned function you’ll call in production. And because of this tight coupling, if Lilypad ever goes down, your code and prompts keep working without interruption.
By contrast, platforms like LangSmith manage prompts outside of the codebase. While that can look tidy, it makes it harder to trace outputs back to the exact prompt, logic, and parameters that produced them.
#### Evaluation Workflow
Traditional methods of [LLM evaluation](/blog/llm-evaluation), such as star ratings or numeric scores, often create more confusion than clarity. The gap between a 3 and a 4, for example, is subjective and hard to define. And when multiple reviewers are involved, these ratings quickly lose consistency and reliability.
Lilypad uses a simple pass/fail system for evaluation, which makes reviews quicker, easier to agree on, and more useful. It helps teams tell if an output is good enough, and gives clear feedback to improve prompts and build better tools over time.
You can mark outputs as pass or fail, along with any comments, e.g, “hallucinated response.” You can go further by plugging in your own test logic, whether that’s scripts or automated [LLM-as-judge](/blog/llm-as-judge) flows (coming soon).
Unlike LangSmith, which depends on predefined datasets to support full evaluations, Lilypad lets you test prompts as you go without needing to pause and formalize a test set up front. This makes it easier to experiment with few-shot examples, iterate quickly, and evaluate outputs in real time. You can always layer in structure and benchmarks later, once your workflow matures.
To begin, choose the trace you want to evaluate:
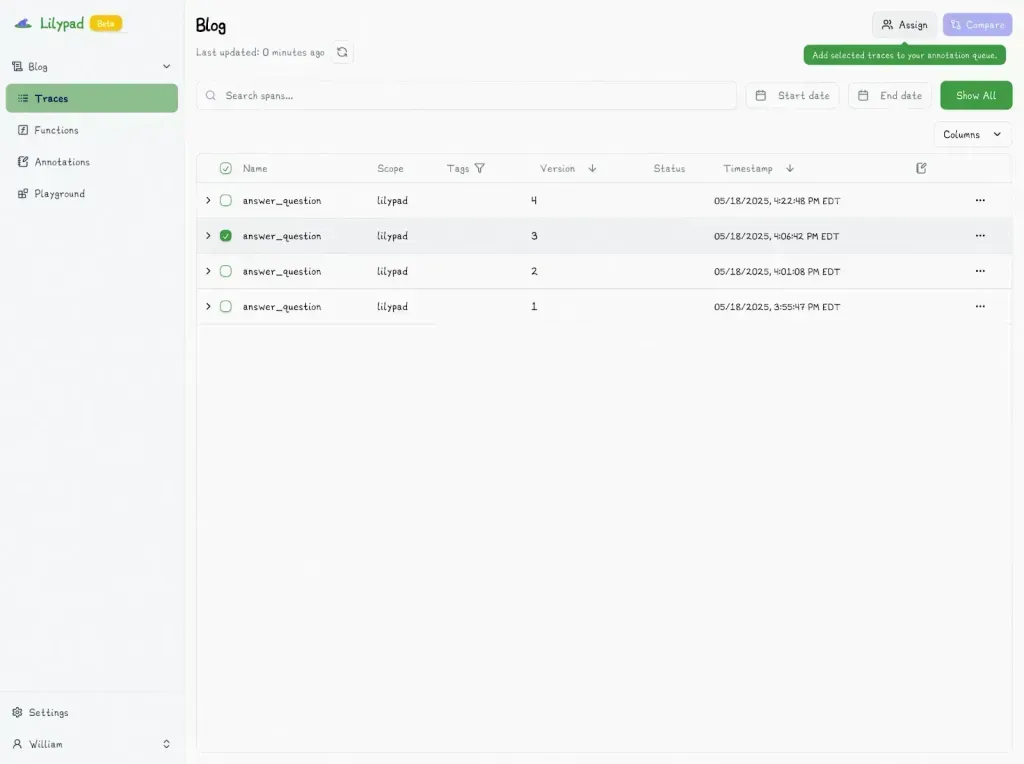
And mark it with “Pass” or “Fail”:
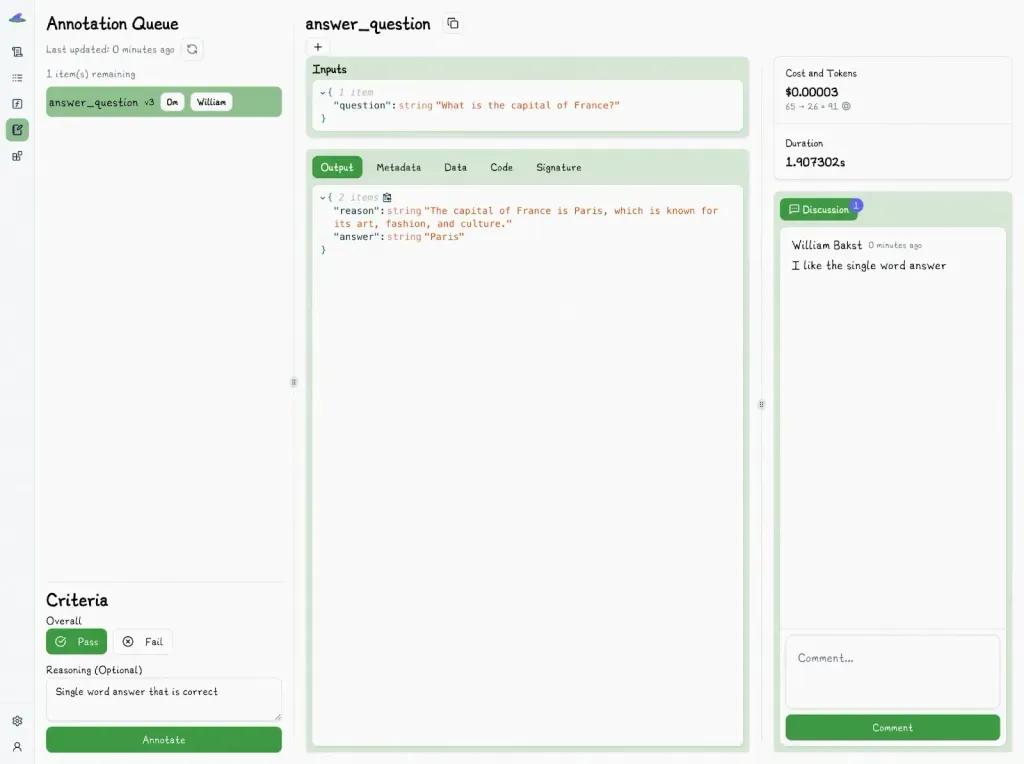
These quick annotations help build a clear picture of what strong vs. weak outputs look like over time.
We generally recommend that teams start with manual evaluations from a domain expert. As you build up a library of labeled examples (pass/fail plus reasons), you’ll have the foundation to train an automated evaluator to mirror those judgments at scale.
Human oversight still matters, though, so we recommend reviewers always step in to verify the judge’s calls and keep the system aligned with human standards.
Lilypad is open source and can be self-hosted or run in the cloud. To get started, sign up for the Lilypad [playground](https://lilypad.mirascope.com/) using your GitHub credentials and begin tracing calls with just a few lines of code.
## An Example of Building an LLM Application
Below, we walk through the steps of building a simple chat application that lets customers query your documentation directly, instead of clicking through multiple pages or search results.
We’ll build this as a [RAG LLM example](/blog/rag-llm-example) where you’ll store documents in a database (or vector store) and convert these into vector representations for efficient search and retrieval. When a user asks a question, the system retrieves the most relevant chunks of content and feeds them to the LLM.
This combination improves accuracy by grounding the model’s answers in your documentation, reducing the risk of vague or incorrect outputs that might occur if the LLM were working without context.
For this application, we use LlamaIndex for data ingestion, embedding, and retrieval, and Mirascope for prompt engineering and response generation. Together, they let you pass both the user’s query and the retrieved context into the model in a single, clear call.
*See our latest article on [LlamaIndex vs LangChain](/blog/llamaindex-vs-langchain)*.
### 1. Set Up Your Environment
First, install the necessary packages of Mirascope and LlamaIndex:
```python
!pip install "mirascope[openai]"
!pip install llama-index
```
Next, import the necessary components. From LlamaIndex, we bring in the pieces to load docs, create an index, and retrieve content. From Mirascope, we import the decorators for prompt engineering and LLM calls:
```python
from llama_index.core import SimpleDirectoryReader, VectorStoreIndex
from llama_index.core.base.base_retriever import BaseRetriever
from mirascope.core import openai, prompt_template
```
### 2. Preprocess, Embed, and Store Mirascope’s Documentation
We load the documentation files from a local directory and vectorize them for efficient search:
```python
documents = SimpleDirectoryReader("./docs").load_data()
retriever = VectorStoreIndex.from_documents(documents).as_retriever()
```
From the code above:
* `SimpleDirectoryReader` loads your documentation files from `./docs`.
* `VectorStoreIndex` embeds and stores them for similarity-based retrieval.
* `as_retriever()` exposes an interface for fetching the most relevant docs to any query.
### 3. Query and Generate an Output
Now we configure our [RAG application](/blog/rag-application) workflow with Mirascope. Below, we write a function that retrieves context from Mirascope’s docs and generates a clear, grounded response:
```python
@llm.call("gpt-4o-mini")
@prompt_template("""
SYSTEM:
You are a helpful assistant that answers user questions based on the provided documentation.
Here are some excerpts from the docs that may be relevant:
<context>
{context}
</context>
USER: {query}
""")
def ask_docs(query: str, retriever: BaseRetriever):
"""Retrieves relevant excerpts from the docs and generates a response."""
context = [node.get_content() for node in retriever.retrieve(query)]
return {"computed_fields": {"context": context}}
```
Here:
* The system message sets the assistant’s role: answer only from docs. This prevents the model from hallucinating or making up stuff outside of the docs.
* `{context}` is dynamically filled with retrieved excerpts, so the model has the right reference material at call time.
* `{query}` is the user’s question.
* The function uses the retriever to fetch relevant chunks and passes them into the template for the LLM call.
Mirascope’s call decorator `@llm.call` takes a normal Python function and doubles it as a prompt definition and an API call. It colocates the call and prompt in one place so you don’t have to handle scattered files or boilerplate code.
Mirascope’s call is model agnostic, so switching providers is as simple as swapping the namespace, e.g, `@llm.call("anthropic:claude-3-sonnet")`.
This way, you keep the same prompt logic while trying different models for speed, accuracy, or cost, all without touching the rest of your code.
### 4. Run the Application
Finally, let’s try it out:
```python
query = input("(User): ")
response = ask_docs(query, retriever)
print(response.content)
```
Example run:
```python
(User): How does prompt_template work in Mirascope?
(System): The prompt_template decorator lets you define reusable prompt patterns with placeholders. Instead of hardcoding strings, you can pass variables into the template, keeping your prompts clean, consistent, and easier to maintain as your application grows.
```
### 5. Add Observability with Lilypad (Optional)
At this point, you have a working chat app powered by Mirascope. In a real project, though, you’d also want to keep track of how prompts evolve over time and make sure outputs stay reliable as your app grows.
With a single `@lilypad.trace(versioning="automatic")` decorator, Lilypad lets you log, version, and evaluate every call without changing your workflow:
```python
import lilypad
lilypad.configure(auto_llm=True)
@lilypad.trace(versioning="automatic")
@llm.call("gpt-4o-mini")
@prompt_template("""
SYSTEM:
You are a helpful assistant that answers user questions based on the provided documentation.
<context>
{context}
</context>
USER: {query}
""")
def ask_docs(query: str, retriever: BaseRetriever):
context = [node.get_content() for node in retriever.retrieve(query)]
return {"computed_fields": {"context": context}}
```
Every time you run `ask_docs()`, Lilypad automatically creates a versioned trace you can inspect in the UI, so you know exactly which prompt, parameters, and code produced each response.
This keeps your app observable without adding boilerplate and ensures your prompts remain reproducible as they change.
## Build Production-Grade Applications With Confidence
Mirascope lets you build and manage LLM apps in native Python, following [prompt engineering best practices](/blog/prompt-engineering-best-practices) with the same structure and discipline expected in any production software project.
Lilypad complements this by automatically recording a snapshot of every generation in your pipeline, so you can test, compare, and optimize your app with full visibility over time.
Want to learn more? Find Mirascope’s code samples in our [docs](/docs/mirascope) and on [GitHub](https://github.com/mirascope/lilypad). Lilypad also offers first-class support for [Mirascope](https://github.com/mirascope/mirascope).
A Guide to LLM Application Development (+ How to Build One)
2025-09-27 · 12 min read · By William Bakst