Iterative prompting is the process of refining a model’s response through a series of follow-up prompts until it produces the kind of output you want. Each prompt builds on the model’s previous outputs, allowing you to gradually enhance the accuracy, clarity, and depth of the final result.
This process is central to prompt engineering because the limitations of LLMs prevent them from producing perfect results in a single attempt. They’re non-deterministic, so iteration helps guide the model’s answers closer to your goal.
For example:
```plaintext
Prompt 1:
Summarize Macbeth for me.
Output:
Macbeth is a play by Shakespeare about a Scottish general who kills the king to become ruler himself, but is later consumed by guilt and paranoia.
```
You might realize the summary lacks structure and misses the deeper themes. So you refine your prompt:
```plaintext
Prompt 2:
Summarize Macbeth in bullet points, highlighting the key themes and moral lessons.
Output:
• Macbeth is a tragedy about ambition and moral corruption.
• It explores how unchecked ambition leads to downfall.
• The play highlights guilt, fate, and the psychological cost of power.
```
Each revision sharpens the instruction and moves the model closer to the kind of output you intended.
The challenge, though, is that it’s also a bit of a grind. You often end up with multiple versions, half-tracked edits, and no clear sense of what actually made one version better than the last.
To get real, repeatable results, you need more than clever wording; you need a way to measure, test, and verify how changes affect outcomes.
But most prompt tools don’t make it easy. That’s why we built [Lilypad](/docs/lilypad), our framework for prompt iteration that tracks every variable affecting output quality.
Lilypad enables this through rigorous, data-driven evaluation. It versions not just your prompt text, but also the code, model settings, and data transformations around it, so prompt experimentation becomes measurable, repeatable, and debuggable.
In this article, we share the iteration strategies we’ve found most useful in refining prompts for LLMs, and show how Lilypad turns prompt iteration into a structured optimization process, not just trial and error.
## How Iterative Prompting Works
This section breaks down the basic loop behind iterative prompting: how to refine a prompt step by step until the output matches what you’re aiming for.
### 1. Create the Initial Prompt
Start with a simple, direct instruction. Don’t worry about getting it perfect on the first try. The initial prompt is your baseline: it shows what the model produces with minimal guidance and gives you something to compare later iterations against.
Example (baseline):
```plaintext
Summarize the play Hamlet in a few paragraphs.
```
Use the baseline to note what’s missing or off (scope, tone, structure, missing context). Those observations are your input for the next prompt.
### 2. Analyze the Output
Next, look at the response and ask: Does this meet my goal? Pay attention to both what the model said and how it said it. Sometimes the initial response looks fine at first glance, but when you read closely, the AI response misses the emotional undertones or is too academic.
Different AI models have their own habits, so part of this step is simply noticing the patterns in how they interpret your instructions.
At this point, you’re not judging whether it’s good writing yet, but just whether it reflects your intent.
### 3. Identify the Gaps and Revise the Prompt
Now pinpoint what’s missing or unclear, and adjust your prompt to close those gaps. Add clarity, context, or constraints that guide the model closer to what you want.
For instance, if the first version was too broad, you might update it to:
```plaintext
Summarize Hamlet in bullet points, highlighting the major themes and character motivations.
```
You’re testing a new hypothesis about what the model needs to perform better.
### 4. Repeat and Refine
Run the new prompt, study the output again, and keep iterating until the result clicks. With each round, you’ll start to recognize patterns in how the model interprets phrasing, tone, and structure. It’s an iterative process, and the improvements usually come from small bits of refinement rather than huge rewrites, exactly the kind of incremental tuning that underlies [prompt engineering best practices](/blog/prompt-engineering-best-practices).
Over time, this back-and-forth stops feeling like trial and error. You start predicting how small adjustments shape the outcome, which is really the point of iterative prompting and is all part of prompt engineering best practices.
## 5 Advanced Techniques for Better Iteration
### 1. Few-shot Prompting
Few-shot prompting teaches a model how to think by showing, not telling. You demonstrate the pattern you want the model to follow by providing a handful of examples upfront.
It’s especially useful when the task is unconventional or when you want the outputs to stay consistent. The model learns the underlying logic, tone, and structure from the examples, even if you never explicitly explain the rules. That’s in-context learning at work.
In the example below, we want the model to tell whether a sentence expresses a *positive* or *negative* mood. Instead of just asking, you can teach it through examples:
Example:
```plaintext
Classify the mood in each sentence as “Positive” or “Negative.”
Example 1:
Sentence: “I finally finished my project and it turned out even better than I expected!”
Answer: Positive
Example 2:
Sentence: “The meeting dragged on forever and nothing got resolved.”
Answer: Negative
Now classify:
Sentence: “The team hit every milestone this week and we’re ahead of schedule.”
Answer:
Response:
Answer: Positive
```
### 2. Chain-of-Thought Prompting
This technique encourages the model to show its reasoning process step by step before giving a final answer, and is especially useful for tasks that require logic, reasoning, or math (basically anything where the process matters as much as the outcome). By laying out its thoughts, the LLM becomes less likely to skip steps or make careless mistakes, and you get to see *how* it arrived at an answer, not just *what* it is.
Example:
```plaintext
Let’s solve this step by step. If 3 pencils cost $6, how much do 10 pencils cost?
```
Response:
```plaintext
Response:
Step 1: If 3 pencils cost $6, then 1 pencil costs $6 ÷ 3 = $2.
Step 2: If 1 pencil costs $2, then 10 pencils cost 10 × $2 = $20.
Final Answer: $20
```
In practice, you can trigger this behavior by using cues like *“Let’s think step by step,”* or *“Explain your reasoning before answering.”* This improves performance on reasoning-heavy prompts. Newer models that have reasoning capabilities built-in offer the ability to configure how much effort (i.e. number of tokens) should be spent on the reasoning process.
### 3. Role-Based Prompting
Role-based prompting is one of the simplest prompting strategies for getting more focused, context-aware answers.
It involves assigning a specific identity or point of view to the model before asking it to perform a task. Instead of treating it like a blank-slate assistant, you assign it a role (e.g, teacher, recruiter, developer, marketer, etc) and let that context shape how it reasons and responds.
This works because LLMs adjust their tone, priorities, and reasoning style based on the role they think they’re playing. When you set that frame clearly, you get more focused and context-aware answers.
Example:
```plaintext
Prompt: You are an experienced career coach. A client wants to negotiate a higher salary after receiving a job offer. Explain your reasoning steps clearly and give them a confident, practical script they can follow.
```
Response:
```plaintext
As a career coach, I’d guide them through a simple approach that keeps the conversation calm, clear, and confident. I’d start by helping them organize their reasoning steps — gratitude first, then the evidence that supports why they deserve more, like their skills, past results, and the typical market range for the role.
Laying things out this way strengthens the response quality and makes the guidance easy to follow.
Here's a script they can follow:
“Thank you again for the offer. I’m excited about the role. Based on my experience with X and what I’m seeing in the market, I was hoping we could explore a salary closer to [range]. I’m confident I can contribute quickly, and I’m open to discussing options that work for both of us.”
```
When you structure AI prompts with a clear role like this, the AI outputs tend to be more focused and practical because the model knows exactly what point of view to adopt.
### 4. Prompt Chaining
[Prompt chaining](/blog/prompt-chaining) is about breaking a complex task into smaller, connected steps instead of trying to get everything in one massive prompt. Each step feeds into the next — the output of one prompt becomes the input for another.
Think of it as building a reasoning pipeline. You’re guiding the model through a sequence of focused tasks rather than one overloaded instruction. This helps maintain clarity, reduce confusion, and improve accuracy, especially when the goal involves multiple layers of logic or formatting.
For example, let’s say you want the model to write a short product description for a new AI tool:
Example:
```plaintext
Prompt 1: Summarize this product in one sentence.
Output: “An AI-powered writing assistant that helps teams draft content faster.”
Prompt 2: Based on that summary, list three key benefits.
Output: “1. Speeds up content creation. 2. Ensures tone consistency. 3. Reduces editing time.”
Prompt 3: Use the summary and benefits to write a 50-word product description.
Output: “This AI writing assistant helps teams create content faster and stay on-brand. It improves collaboration, ensures tone consistency, and saves hours of manual editing every week.”
```
By chaining prompts, you give the model room to *think and refine*. Each stage tackles a smaller problem, which makes the final output more coherent and deliberate than if you tried to do it all in one go.
Prompt chaining is especially useful for structured workflows, such as data extraction, content generation, multi-step reasoning, or evaluation pipelines. It turns a single-shot interaction into a guided, step-by-step collaboration.
### 5. Sequential Prompting
Sequential prompting is about guiding the model through a series of evolving prompts that build on one another. Each step refines or expands the previous response, gradually moving toward a final, polished output.
It’s similar to prompt chaining, but the goal here isn’t to split one big task into different parts; it’s to improve the same piece of work over multiple passes. It’s more like having a conversation where each turn gets you closer to what you actually want.
Example:
```plaintext
Prompt 1: Write a short LinkedIn post about AI tools improving workplace productivity.
Output: “AI tools are helping teams automate repetitive tasks and save time, allowing employees to focus on higher-value work.”
Prompt 2: Make it more conversational and engaging.
Output: “AI tools are quietly changing how we work. The best part? They handle the boring stuff so you can focus on what actually matters.”
Prompt 3: Add a call to action for readers to share their favorite AI tools.
Output: “AI tools are quietly changing how we work. The best part? They handle the boring stuff so you can focus on what actually matters. What’s one AI tool you can’t work without?”
```
Here, each round sharpens the output, helping the model get closer to your intent. This iterative flow is great for writing, refining tone, or developing ideas that can’t be captured in one shot.
In practice, sequential prompting mirrors how humans work; you draft, review, adjust, and polish. It’s especially useful when the “perfect prompt” doesn’t exist yet, but you’re willing to refine your way there.
## Common Challenges In Prompt Iteration
### The Non-Deterministic Nature of LLMs
LLMs are inherently non-deterministic, which means the same prompt won’t always give you the same output. Even if everything looks identical on your end, the model might take a slightly different reasoning path each time. Sometimes that’s a good thing, as it keeps the responses creative and varied. But when you’re trying to build something predictable, that variability can be challenging.
This randomness is one of the biggest challenges that prompt iteration tries to solve. You get to refine, test, and re-test until the model’s responses feel consistent enough to trust. However, it’s never truly fixed, since you’re working within a system that’s designed to be adaptable.
Popular frameworks like LangChain and LlamaIndex have tried to solve this by adding structure, pipelines, chains, and runnables that help organize how prompts, models, and tools interact. For prototypes or small apps, that structure is often enough. But as systems scale, say, when you’re orchestrating hundreds of LLM calls across multiple components, it can quickly get complicated. That extra abstraction can make it harder to debug or fine-tune individual steps.
[We built Mirascope, our LLM toolkit](https://github.com/mirascope/mirascope), to rely on plain Python so you can build and iterate naturally without having to rewrite your workflows or follow framework-specific constructs.
### Ambiguous Instructions
A lot of the time, the problem isn’t with the model’s reasoning, but how we prompt it. Models are sensitive to phrasing and don’t really understand context the way humans do, so when a prompt is vague, they just fill in the gaps however they think makes sense. And many times, that’s not what you had in mind.
That’s why getting the output you actually want often takes a few rounds of rewording and reframing. And oddly enough, stuffing everything into one giant, detailed prompt doesn’t help either; the model can lose focus or blend things that were meant to stay separate.
It’s usually cleaner to split a complex instruction into a few smaller ones, each doing one clear thing. That way, the model isn’t left guessing, and you can see exactly where things go off track.
### Overfitting the Prompt
When you tweak a prompt too many times to fix one issue, it can start performing worse on others. This is overfitting; optimizing for one scenario while breaking general performance.
It’s the same problem data scientists face when a model memorizes the training data instead of actually learning from it. In our case, the model isn’t the issue; the prompt is. You can optimize it so tightly around a narrow use case that it stops being generalizable.
To fix this, keep testing your prompt across multiple examples, not just one. A good prompt should work reliably across variations, not just the one that happens to fit.
### Ignoring the Model’s Context Window
Each LLM has a limit to how much text it can “remember” in one go. If your iterative tests rely on long context or multi-turn reasoning, that memory can abruptly end without warning.
This becomes a real problem during iteration, especially when you’re working with large datasets. You might be refining a prompt and wondering why the model suddenly stops producing coherent answers, when really, it’s just running out of space to “remember” what you told it.
One way around this is by using a [RAG application](/blog/rag-application). Instead of stuffing everything into the prompt, you let the model pull in only the most relevant snippets from external sources as it generates. And as frontier models expand their context windows, this limitation is becoming less painful.
### Losing Track of Versions
When you’re testing multiple prompt variations, it’s easy to forget which one worked best. Without proper tracking, you can end up with five “almost perfect” prompts but no clear record of how you got there.
This is a subtle but serious problem. Most people just overwrite the old prompt and move on. By the time they circle back, they can’t tell whether the new version is actually better or just different.
Some observability frameworks try to manage this, but they often treat prompts as isolated entities, detached from the application code that calls them. That means you lose the surrounding context that matters: the logic, the function, and the data flow that actually shape how a prompt behaves in production.
This separation makes debugging harder and collaboration messy. Developers need a view that captures not just *what* the prompt says, but *where* and *how* it’s being used.
Below, we discuss best practices for [prompt optimization](/blog/prompt-optimization) through iteration, including how Lilypad helps you handle these challenges when working directly with LLM APIs inside a software project.
## Best Practices for Systematically Iterating Prompts
Manual prompt iteration works fine when you’re experimenting or working on one-off use cases. But when prompts are part of [LLM applications](/blog/llm-applications) where they directly influence system behavior, you need more structure. In that context, a “good prompt” isn’t enough. It has to be consistent, testable, and easy to version and improve over time.
Below are five best practices that we’ve found to make iterative prompting more reliable and measurable. Along the way, we illustrate these using examples from Lilypad, our [context engineering platform](/blog/context-engineering-platform).
### Define Goals and Constraints Up Front
We recommend stating not only the goal, but also the constraints and assumptions that shape the task. For instance:
* Define any limits on length, format, or scope (e.g., “Responses must not exceed 200 words”).
* Make hidden assumptions explicit (e.g., “Assume the audience is a software engineer”).
* Clarify the role or perspective you want the model to adopt (e.g., “You are a product manager evaluating feedback”).
This upfront clarity helps reduce unnecessary trial-and-error and ensures that subsequent iterations are aligned with a single, well-defined objective. It also makes it easier to compare results objectively when you begin testing new prompt versions later on.
### Version All Prompt Changes
Prompt iteration works best when it’s treated like an experiment; measurable, reproducible, and grounded in data. Every time you tweak a prompt, adjust a model parameter, or edit a configuration, that change needs to be versioned. This provides a [prompt testing framework](/blog/prompt-testing-framework) ensuring you always know what changed, when it changed, and why it changed.
Otherwise, it’s easy to lose track of what caused a particular improvement (or regression). You might notice that your outputs suddenly got worse, but unless you’ve logged prompt versions, retracing the root cause can turn into guesswork. Versioning eliminates that uncertainty. It allows you to compare results across different iterations, run A/B tests, and analyze how specific edits impact output quality.
Prompt iteration platforms should include functionality for iterating on prompts. For example, Lilypad encourages developers to use Python functions to encapsulate their prompts and any logic influencing them. Capturing context in this way makes prompt iteration more reliable by ensuring you can trace, reproduce, and understand exactly what influenced each output.
We decorate prompt functions using `@lilypad.trace()`, which can automatically version every change as the function evolves.
```python{4-13}
import os
import lilypad
from openai import OpenAI
lilypad.configure(
project_id=os.environ["LILYPAD_PROJECT_ID"],
api_key=os.environ["LILYPAD_API_KEY"],
auto_llm=True,
)
client = OpenAI()
@lilypad.trace(versioning="automatic")
def answer_question(question: str) -> str | None:
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": f"Answer this question: {question}"}],
)
return response.choices[0].message.content
response = answer_question("Who painted the Mona Lisa?")
print(response)
# > Leongardo da Vinci painted the Mona Lisa.
```
By decorating the function with `@lilypad.trace`, you also see it inside the Lilypad UI. Every versioned function produces trace data, and in the next section, we’ll dig into how that tracing gives you full visibility into each run.
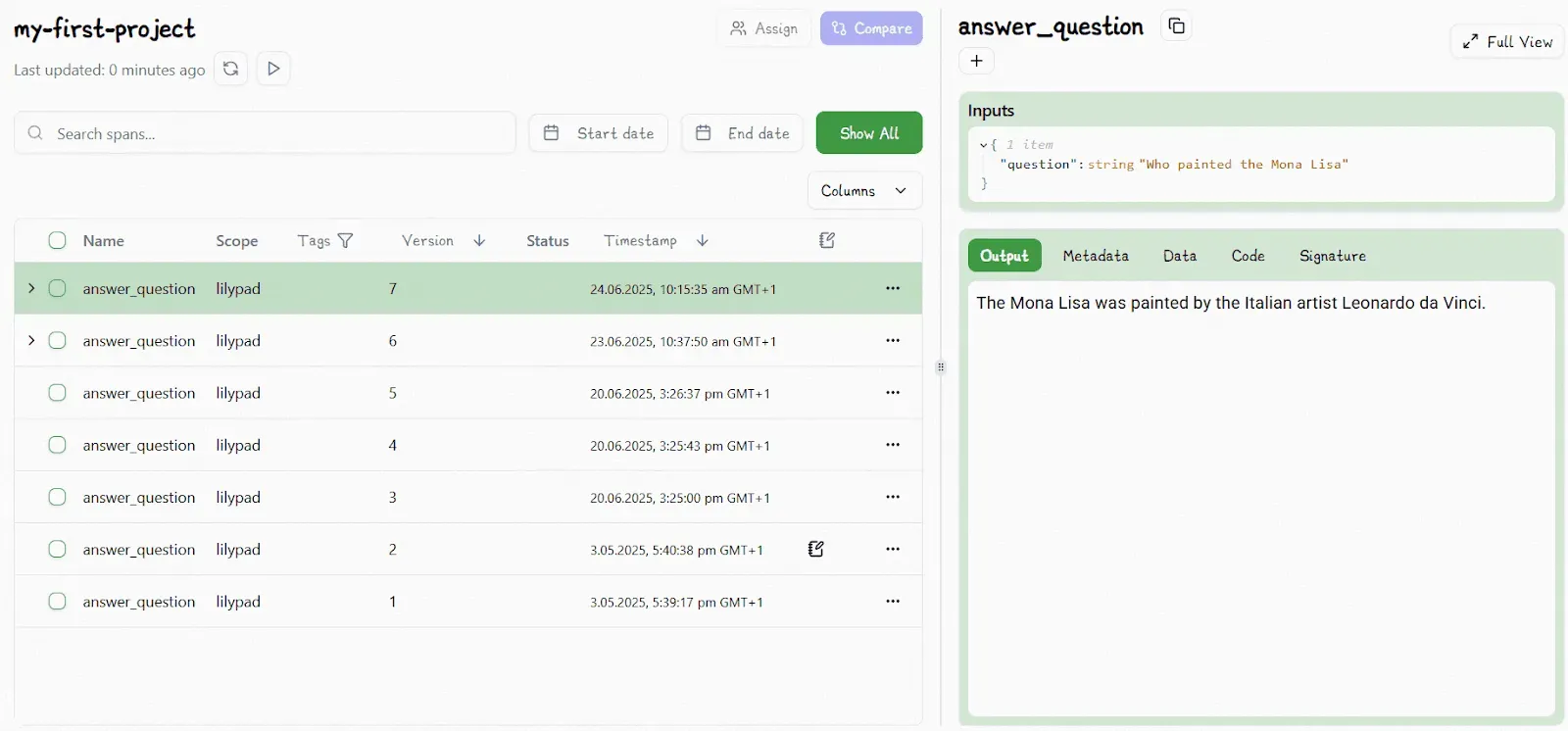
Automatic versioning saves time and ensures every change is recorded, so you don’t forget anything and can always see what changed and why. You can also revisit or re-run any previous version directly in code.
### Log and Trace for Full Visibility
As your prompt system evolves, visibility becomes more important, meaning you should always be able to trace how a specific output was generated, which version of the prompt produced it, what parameters were used, what model handled it, and under what conditions. Without that visibility, debugging or optimizing becomes guesswork.
We recommend treating every prompt execution as an event worth logging in order to tell the full story behind every output. Capture inputs, outputs, metadata (like temperature, latency, or model version), and any contextual variables that could influence results. These traces form the backbone of a reproducible workflow where every decision and change is auditable.
In Lilypad, using `@lilypad.trace()` as we describe above also automatically records a full execution log of prompt inputs, model configuration, output, latency, and even any downstream calls that occur during the run.
Each log entry becomes a “trace” that’s viewable in Lilypad’s dashboard, so you can explore what happened without manually instrumenting code. For example, you can inspect a past trace to see how a model responded under different temperature settings, or compare multiple traces from the same prompt version to spot performance drift.
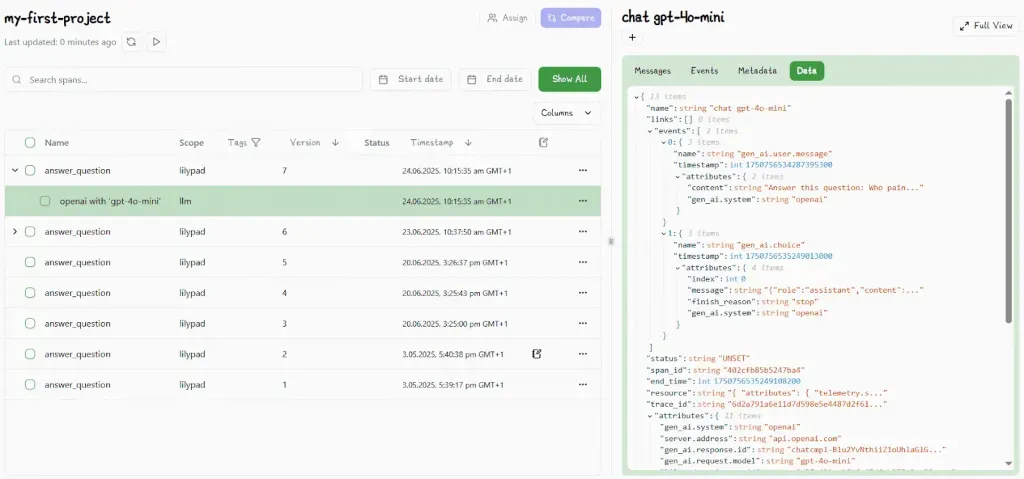
Every time this function runs, Lilypad captures a complete record, creating a searchable timeline of runs, parameters, and results. These logs are built on the [OpenTelemetry JSON spec](https://opentelemetry.io/), so they include nested spans, meaning you can trace how one function triggered another and measure how each part performed.
### Adopt a Collaborative Workflow
Prompt development shouldn’t be a solo effort of developers. In most real-world AI projects, both technical and non-technical contributors shape how a system behaves, from developers refining logic to subject matter experts tuning tone or phrasing. A strong workflow makes it easy for everyone to contribute safely without breaking production.
We recommend adopting a workflow that separates experimentation from deployment. One that lets teams iterate freely in a sandboxed environment while keeping production prompts versioned, reviewable, and type-safe. This ensures creativity doesn’t come at the cost of reliability.
You structure this process around three principles:
1. Collaborate in shared spaces, using environments where non-technical users can view and adjust prompts without diving into code.
2. Version every change, such that each edit creates a new version where teams can compare results or revert if needed.
3. Keep parity with production so test prompts run exactly as they would in production, using the same types, parameters, and configurations.
For instance, Lilypad provides a no-code playground where teams can safely experiment, edit, and test prompts in Markdown-based [prompt editor](/blog/prompt-editor).
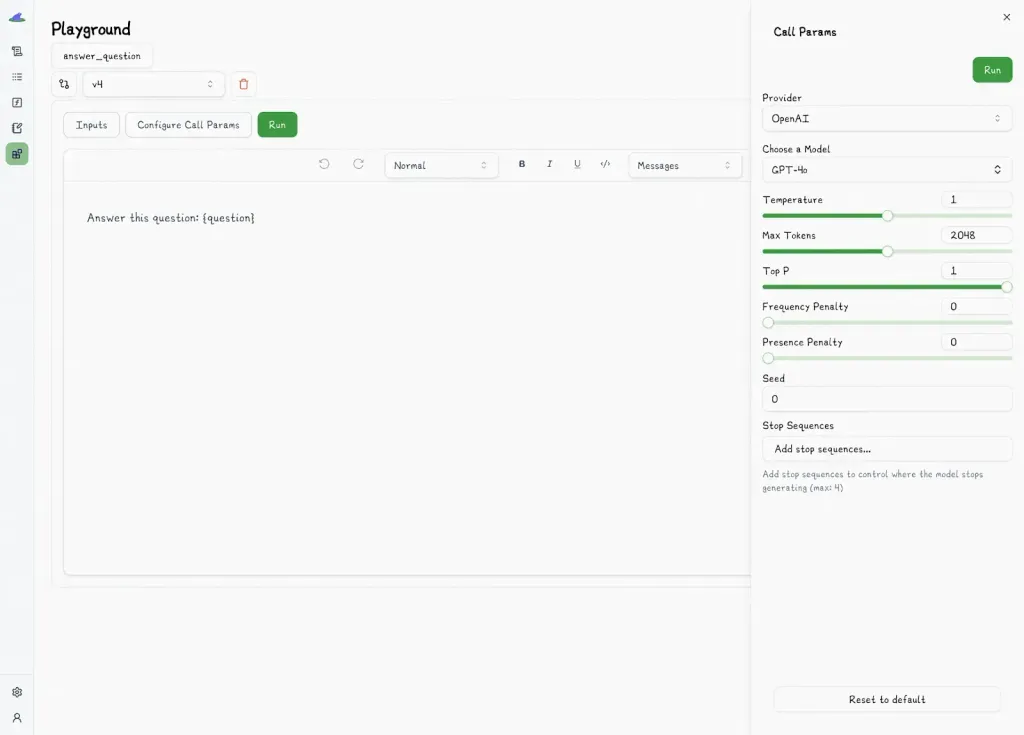
Every edit is versioned automatically, so developers and non-developers can collaborate without overwriting each other’s work.
For developers, this means production remains stable. For SMEs and other non-technical users, it means you can experiment, refine language, or adjust parameters without waiting on developers to redeploy every tweak. This is especially valuable in advanced use cases like [LLM agents](/blog/llm-agents), where prompt components and control logic often need to evolve independently.
And because templates in our [prompt management tool](/blog/prompt-management-tool) use type-safe placeholders that mirror your function’s parameters, they run exactly as they would in production. So even if Lilypad goes offline, your application will still run as expected.
### Test and Verify for Quality Control
No matter how carefully you write or version a prompt, it’s only as good as its results. That’s why prompt iteration should include systematic testing, not just to check if outputs look “good,” but to verify whether they actually meet your quality standards over time.
To achieve this, you have to treat [prompt evaluation](/blog/prompt-evaluation) as an ongoing feedback loop. Each iteration should be tested against real examples, tracked for consistency, and annotated for quality. Instead of focusing on whether the model gives the “right” answer once, look at whether it performs reliably across multiple runs and inputs.
To make this process meaningful:
* Collect evaluation data continuously. Don’t wait for a major update to test; log and review outputs as part of your normal iteration cycle.
* Use clear, interpretable metrics, like binary pass or fail outcomes with reasoning, which align more closely with how decisions are made in practice (you either accept an output or you don’t) than more granular scoring (like rating an output on a scale from 1 to 5) .
* Keep a full trace context so you can link each test back to the exact prompt version, configuration, and model used.
* Combine human judgment with automation. Human reviewers should establish the baseline, then you can bring in [LLM-as-judge](/blog/llm-as-judge) evaluators for scale, always manually validating their results periodically.
For example, Lilypad lets you attach evaluations directly to prompt traces. Each trace captures the input, output, and environment, while users can mark whether the result “passed” or “failed” according to your team’s standards.
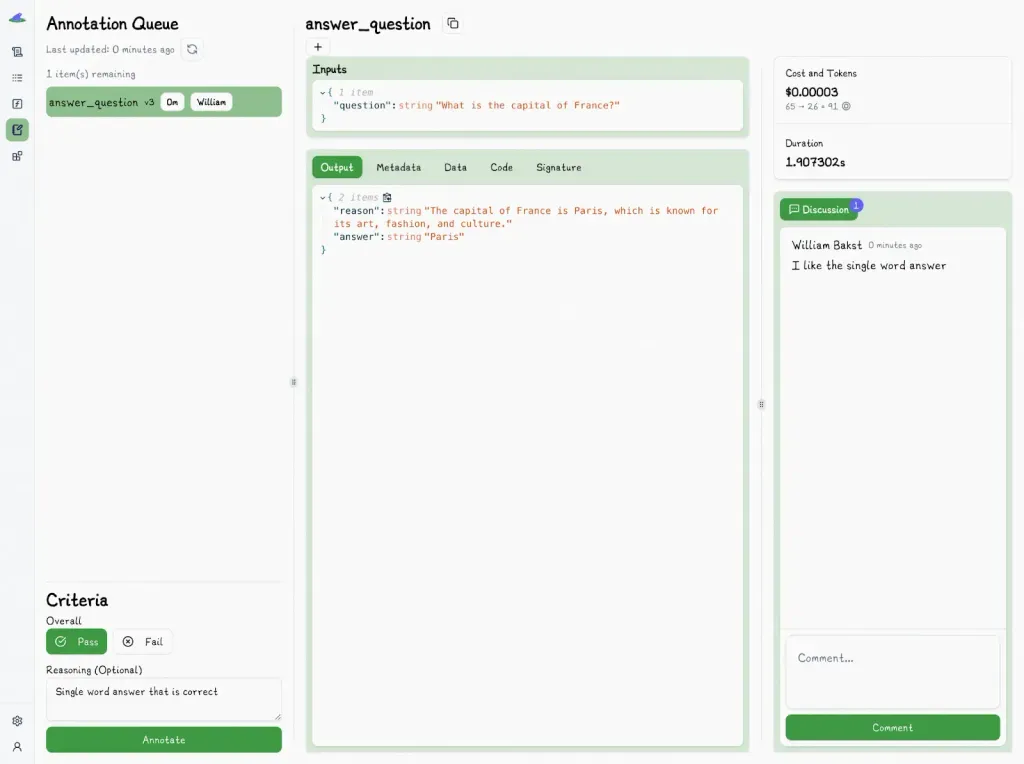
Every annotation in Lilypad is tied to a specific trace, so you get a full context of how and when a prompt was run, including its inputs, outputs, and environment. You can also assign annotations to teammates, so it's easy to review and discuss results collaboratively.
## Iterate Better with Lilypad
Lilypad makes prompt iteration for [LLM application development](/blog/llm-application-development) systematic so you can version every change, trace every run, and collaborate without losing context. It’s open source and can be self-hosted or run in the cloud.
To get started, sign up for the Lilypad [playground](https://lilypad.mirascope.com/) using your GitHub credentials and begin tracing calls with just a few lines of code.
Want to learn more? Explore our [docs](/docs/lilypad) or check out our [GitHub](https://github.com/mirascope/lilypad). Lilypad also offers first-class support for [Mirascope](https://github.com/mirascope/mirascope), our lightweight toolkit for building agents.
A Guide to Prompt Iteration: Strategies and Examples
2025-11-26 · 6 min read · By William Bakst