In early-stage projects, prompt management is usually informal. Prompts live in notebooks, scripts, or Slack threads. That’s fine until the team grows, the system scales, or outputs end up being inconsistent and no one knows who changed what or why.
We experienced this ourselves a few years ago working with an early version of OpenAI’s SDK. Prompt management tools didn’t really exist yet **so managing changes of complex prompts quickly became a mess**, and beyond two versions things became unmanageable.
We were manually versioning everything and went so far as to tell people not to change the code without multiple approvals to avoid accidentally breaking something downstream. Needless to say, the process was slow and fragile, and anything but collaborative.
Purpose-built prompt management tools fix this. But many tools still treat prompts as static text blobs, more like CMS content than dynamic, testable code artifacts. This disconnect leads to drift between what you test and what runs in production.
We built [Lilypad](/docs/lilypad) to solve this problem. It encapsulates every LLM call with its full context in a Python function that can be versioned, tested, and improved over time. In the sections below, we explore Lilypad’s prompt management functionality along with four other leading prompt systems. We also discuss key questions to ask when looking for one.
The four systems we examine are:
1. [Lilypad](#1-lilypad)
2. [Agenta](#2-agenta)
3. [PromptHub](#3-prompthub)
4. [Langfuse](#4-langfuse)
## 4 Questions to Ask When Choosing a Prompt Management Tool
### 1. Does It Capture Context Beyond the Prompt String?
Many systems version prompts as standalone text templates, ignoring the code and logic that surround them. But LLM outputs are inherently non-deterministic and are influenced by more than the prompt string. Model responses also depend on LLM settings, helper functions, pre- and post-processing steps, and the runtime environment.
Tools that version only the prompt miss this broader execution context. That becomes a limitation in production, where reproducing or debugging a generation requires knowing everything that influenced the output. Without full context, you can't reliably trace what happened, rerun it accurately, or pinpoint what changed.
Systems that capture full context, on the other hand, snapshot not just the prompt but the entire function closure like inputs, model config, and associated logic. This makes it possible to test and review exactly what’s running in production, and provides a clear audit trail of changes over time.
### 2. Does It Embrace Rapid Iteration and Continuous Versioning?
Iteration is at the heart of prompt engineering since refining prompts through trial and error is often the only way to surface what actually works in practice.
Many tools require you to manually save or commit prompt changes, which can slow down iteration and make it easy to lose track of what changed and when.
Continuous versioning means the system automatically tracks any and all changes to prompts and saves these as distinct versions.
This creates an unbroken audit trail showing how prompts evolved over time, which helps in debugging regressions, running A/B tests, and setting up [prompt chaining](/blog/prompt-chaining). A system that embraces rapid iteration lets teams move fast without sacrificing control, traceability, or reliability, all key aspects of [LLM observability](/blog/llm-observability).
### 3. Can Technical and Non-Technical Teams Collaborate?
In systems where prompt templates are tightly coupled to application code, developers must redeploy or update code whenever non-technical collaborators make changes, slowing iteration and introducing cross-team dependencies.
[LLM tools](/blog/llm-tools) that, on the other hand, decouple prompt editing from code and ensure type safety and traceability make it easier to iterate quickly, empower non-developers to contribute safely, and preserve full reproducibility across versions.
Look for systems that offer a no-code [prompt optimization](/blog/prompt-optimization) environment where non-technical users like domain experts can suggest or test prompt changes without needing to touch the code, and that offer visibility into the prompt engineering process, like the prompt template, LLM outputs and traces, and call settings (e.g., provider, model, and temperature).
Such systems ideally also offer type-safe integrations that ensure prompts tested in the playground match the code running in production, preventing brittleness or drift.
### 4. Does the System Allow Teams to Annotate and Score Outputs?
In many teams, subject matter experts are often best positioned to judge whether an output is “good enough,” and so a production-ready prompt management system should offer a simple and structured way for them to review, annotate, and label outputs, without needing to write code or dig through logs.
This is important for quality control and risk mitigation because teams often catch issues that automated tests or developers might miss, such as subtle inaccuracies, tone mismatches, compliance risks, or brand inconsistencies, and their feedback needs to be incorporated directly into prompt iterations in the future.
A [prompt management tool](/blog/prompt-management-tool) should let users annotate and evaluate real outputs, not in isolation, but in the context of the prompt version, model parameters, and inputs that generated them.
We recommend you look for systems that allow binary pass or fail tagging, inline comments, or structured labels, ideally linked directly to a versioned trace of the output.
## Top Prompt Management Systems for LLM Developers
### 1. Lilypad
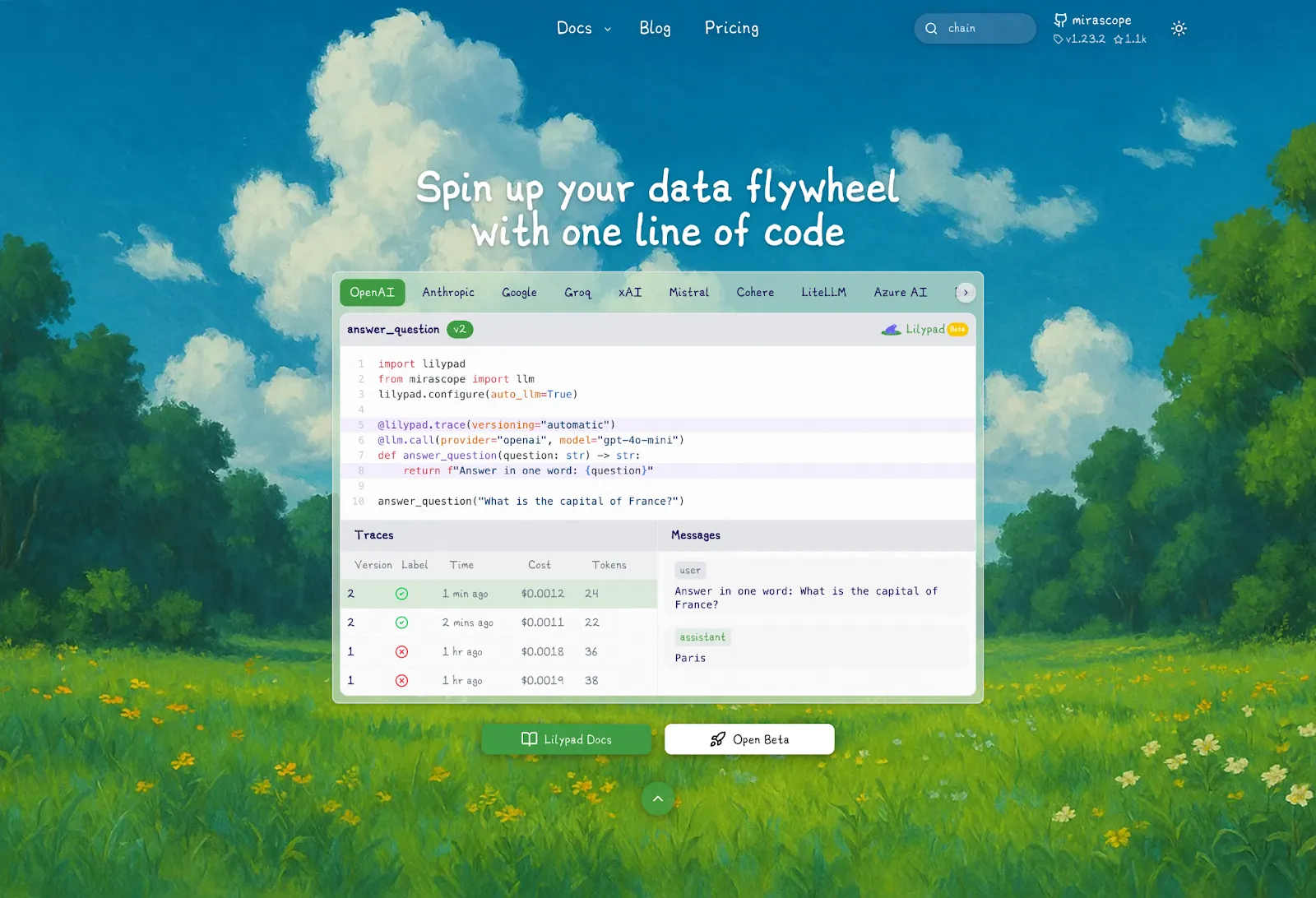
[Lilypad](/docs/lilypad) is an open source prompt management system that treats prompts like code, allowing you to automatically version changes, test outputs, and work with your team while making sure every version is tracked and testable.
Unlike tools that only version the prompt string, Lilypad captures the full context of a generation, including the logic surrounding the LLM call, input variables, and model settings, making it easier to reproduce behavior and debug issues.
It’s built for developers but supports non-technical users through a type-safe playground and built-in evaluation tools, so teams can iterate quickly without relying on redeploys or manual syncing. It also integrates with a number of other [LLM application development](/blog/llm-application-development) frameworks like Mirascope and others, and can be hosted locally.
#### Tracking Everything That Influences an LLM Output
Lilypad encourages developers to wrap LLM calls and any code influencing those calls in a Python function to capture its full execution context, so every output can be traced, versioned, and reproduced exactly.
You then decorate this function with the line `@lilypad.trace(versioning="automatic")` to automatically version any and all changes within the function’s closure and to create a record of the prompt and its context.
This allows you to rapidly iterate on prompts and replay the inputs that went into every output, without having to manually track versions, guess what changed, or reverse-engineer results from logs after the fact.
Lilypad also automatically traces outputs, both at the API and at the function level, capturing everything inside the decorated code block.
You initiate API level tracing of all calls by adding the line `lilypad.configure(auto_llm=True)` to track metadata like inputs, outputs, token usage, cost, latency, and model parameters for any LLM call made (e.g. via OpenAI, Anthropic, and others).
This ensures broad observability and cost tracking with minimal instrumentation, even of calls outside of decorated functions.
```python{4,7-13}
from google.genai import Client
import lilypad
lilypad.configure(auto_llm=True)
client = Client()
@lilypad.trace(versioning="automatic")
def answer_question(question: str) -> str | None:
response = client.models.generate_content(
model="gemini-2.0-flash-001",
contents=f"Answer this question: {question}",
)
return response.text
response = answer_question("What is the capital of France?") # automatically versioned
print(response)
# > The capital of France is Paris.
```
Lilypad uses the [OpenTelemetry GenAI spec](https://opentelemetry.io/), which also records surrounding context like messages, warnings, and other useful metadata.
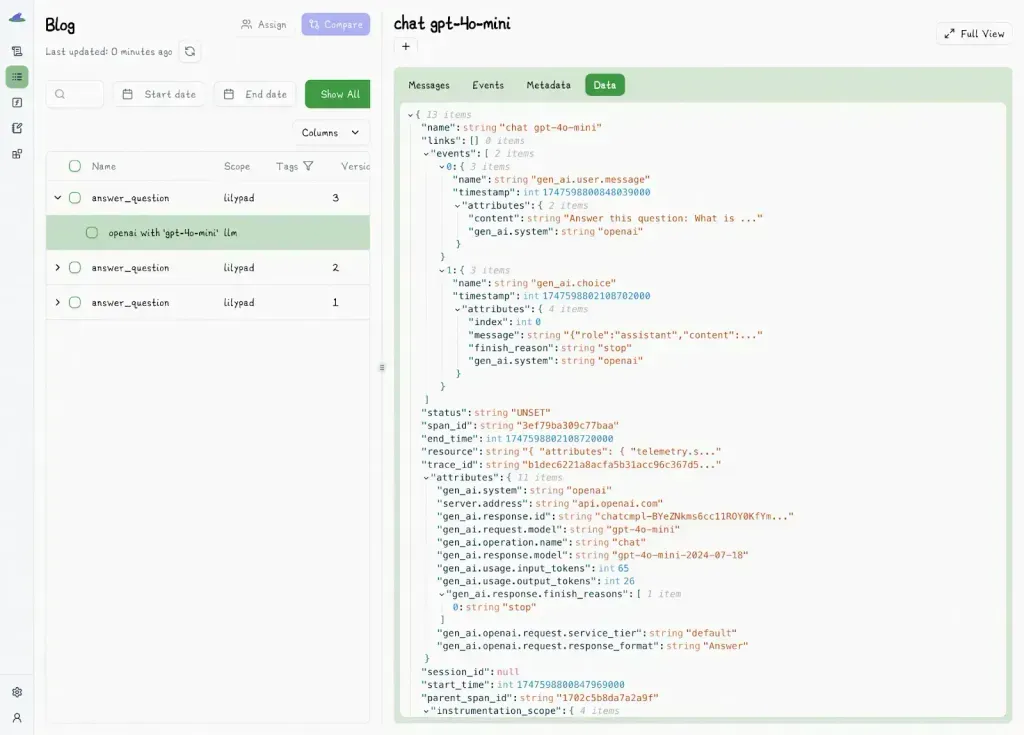
The Lilypad UI shows all versions that were created for the function, along with traces of their outputs:
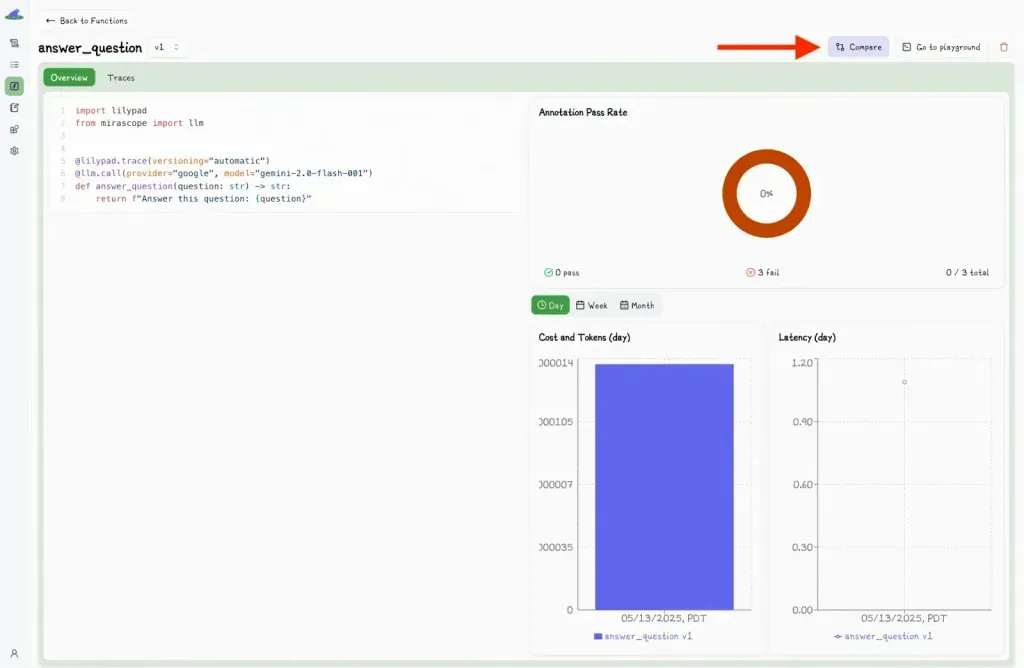
You can also compare metadata and output differences between different versions of code by clicking the “Compare” button:
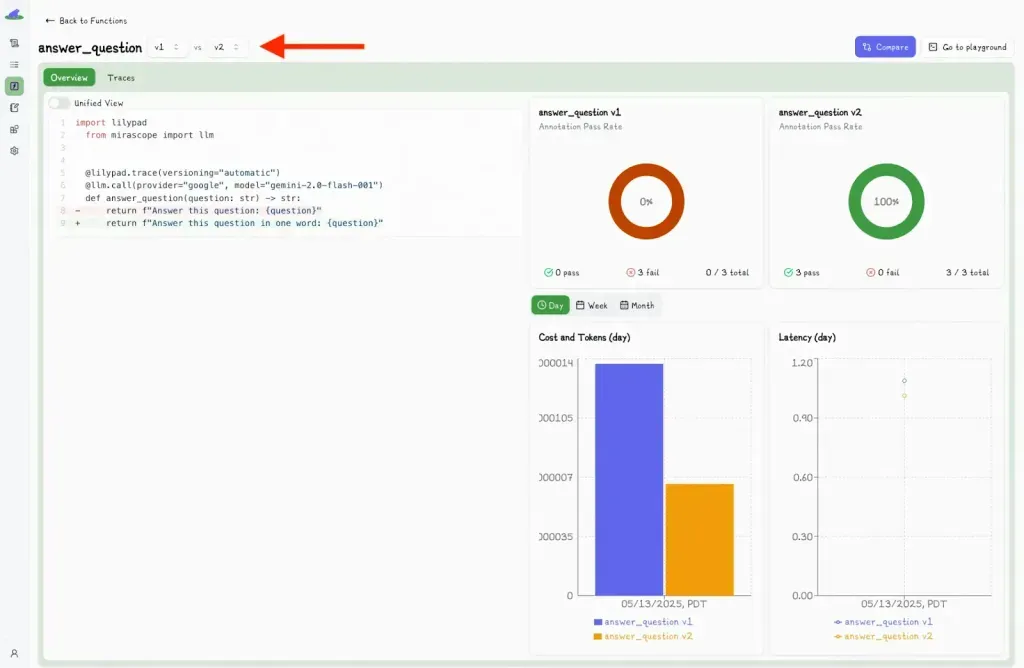
Clicking this displays a second dropdown menu, where you can select another version and view the differences side-by-side.
Downstream, developers can also access specific versions by using the `.version` command, which allows them to re-run specific versions for A/B testing, or to reproduce certain results.
```python
response = answer_question.version(3)("What is the capital of France?")
```
#### No-Code Prompt Editing, Backed by Your Codebase
The Lilypad playground allows subject matter experts (marketers, legal reviewers, product managers, and others) to test and refine prompts without developer intervention.
Changes made in the [prompt editor](/blog/prompt-editor) are sandboxed by default, meaning they won't affect production code or logic until they’re explicitly reviewed by a developer. This setup supports safe experimentation while ensuring developers retain control over what gets deployed to production.
Prompts always remain connected with the codebase however, and, unlike systems that allow developers to pull prompts downstream to work on separately, Lilypad keeps prompts in sync with the type-safe Python code that developers are running downstream.
This means what you test in the playground is exactly what’s in the codebase, so if Lilypad goes down then it’s not an issue.
The playground supports markdown-based editing with typed variable placeholders, which helps prevent errors like missing values, incorrect formats, or injection vulnerabilities.
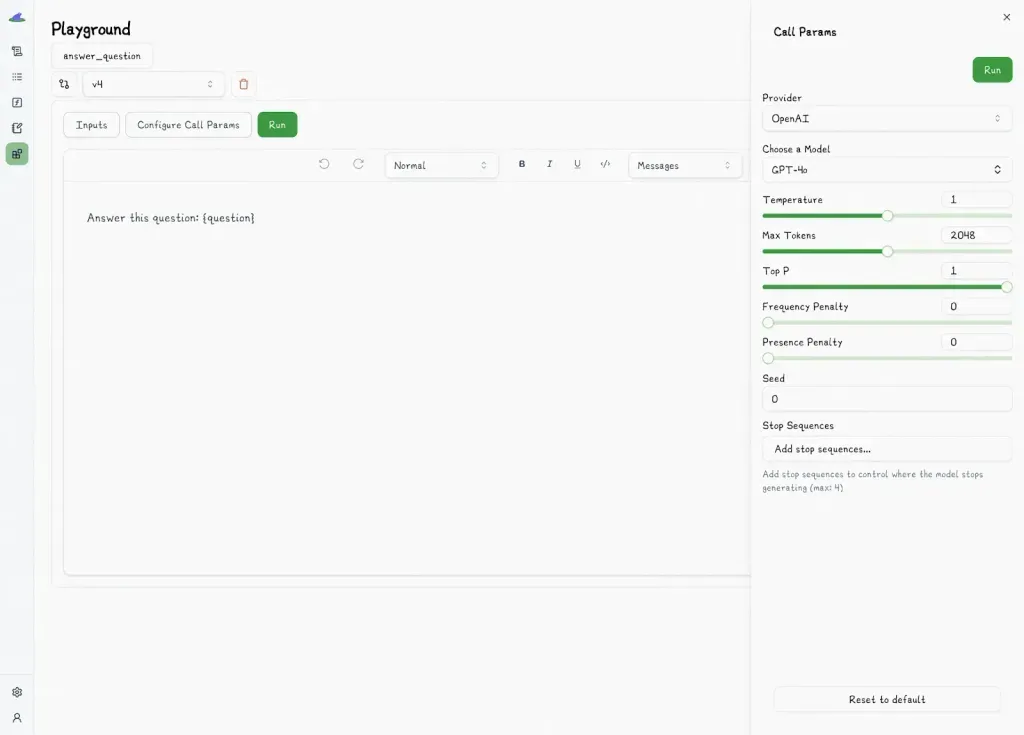
Users can also directly adjust model settings like `temperature` and `top_p`.
Because prompts in Lilypad are functions decorated with `@lilypad.trace`, the playground auto-generates type-safe input forms based on the function’s arguments to ensure inputs are validated at runtime and that team members don’t need to guess what kind of data to provide.
Changes that users make to prompts are also automatically versioned.
#### Real-World Prompt Evaluation
The Lilypad UI also lets domain experts annotate outputs and leave comments and assign reviews to team members via annotation queues.
In Lilypad, outputs are linked to the context that produced them, which gives reviewers insights behind why a prompt behaved the way it did and allows them to recreate those conditions if needed.
Lilypad supports Pass or Fail (binary) judgements for outputs, which are efficient and practical for evaluating non-deterministic outputs, especially in collaborative workflows. This "good enough" metric is clearer and allows for more consistent evaluations than granular numeric scoring (e.g., 1–5 scales).
For example, instead of spending time deciding whether a partially correct answer deserves a 3 or a 4, the reviewer simply asks: “Would I ship this output or not?” a decision that’s quicker and maps directly to real-world standards.
Existing annotations are also hidden from the evaluator during review to reduce bias and promote objective evaluation.
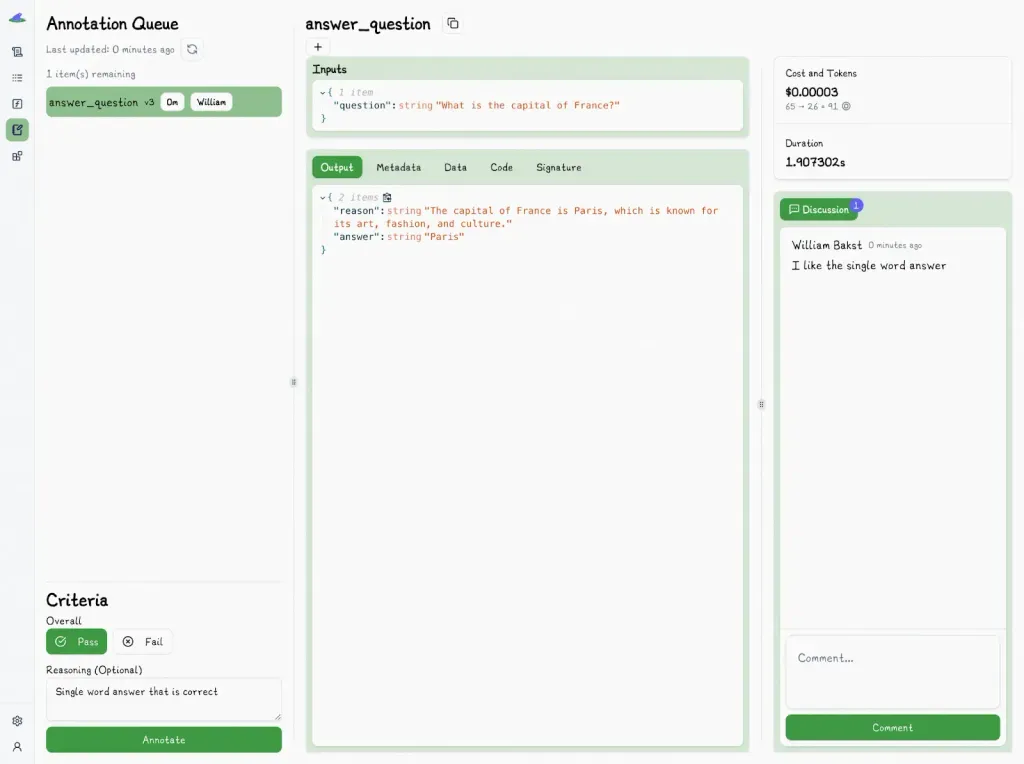
Successive annotations build up a human-reviewed dataset over time, which is useful for regression testing and prompt tuning.
Lilypad also allows you to annotate traces directly within code, allowing labels and reasoning to be submitted as part of a script or pipeline:
```python{7,19-25}
import os
from lilypad import Lilypad
client = Lilypad()
client.ee.projects.annotations.create(
project_uuid=os.environ["LILYPAD_PROJECT_ID"],
body=[
{
"span_uuid": "...",
"project_uuid": os.environ["LILYPAD_PROJECT_ID"],
"function_uuid": "...",
"label": "pass",
"reasoning": "this is a pass because...",
"type": "manual",
"data": {},
"assigned_to": ["..."],
"assignee_email": ["e@mail.com"],
}
],
)
```
Using `mode="wrap"` in the `@trace` decorator converts the function’s return value into a `Traced[R]` object, which makes it easy to log feedback directly in code.
This allows both developers and downstream users to annotate traces inline as they interact with outputs, without needing to manually look up or manage trace metadata.
```python{14-15}
from google.genai import Client
import lilypad
client = Client()
lilypad.configure()
@lilypad.trace(name="Answer Question", versioning="automatic", mode="wrap")
def answer_question(question: str) -> str | None:
response = client.models.generate_content(
model="gemini-2.0-flash-001",
contents=f"Answer this question: {question}",
)
return response.text
trace: lilypad.Trace[str | None] = answer_question("What is the capital of France?")
print(trace.response) # original response
# > The capital of France is Paris.
annotation = lilypad.Annotation(
label="pass",
reasoning="The answer was correct",
data=None,
type=None,
)
trace.annotate(annotation)
```
We generally recommend starting with human-labeled outputs that set a reliable baseline before moving to automated methods like [LLM-as-judge](/blog/llm-as-judge). As those datasets grow, tools like LLM-as-a-judge can handle more of the heavy lifting.
[You can sign up for Lilypad](https://lilypad.mirascope.com/) using your GitHub account and turn every LLM call into a testable, versioned function.
### 2. Agenta
[Agenta](https://agenta.ai/) is an open source prompt management platform that focuses on collaborative development, rapid iteration, and evaluation of prompts, helping both technical and non-technical users manage LLM-driven workflows.
Core features include:
* Unified workflow management allows not just individual prompt versioning, but also full application-level configurations such as retrieval augmented generation pipelines and multi-step LLM chains.
* Integrated evaluations by linking prompt versions to evaluation outcomes to offer detailed audit trails and rollback functionality.
* Collaboration features to support multi-user workflows, human-in-the-loop evaluation, and enterprise-friendly governance tools (SOC 2, granular roles).
* A prompt playground supporting live comparisons of prompts across multiple LLM providers.
* Prompts management with git-like branching, environment tagging, and atomic rollback, similar to best practices in software engineering.
### 3. PromptHub
[PromptHub](https://www.prompthub.us/) is a collaborative prompt management system that helps teams develop, organize, test, and deploy prompts for AI and language models, serving as a repository for prompt engineering and providing version control, workflow automation, and evaluation features.
It provides:
* Versioning based on SHA hashes, allowing teams to branch, merge, and revert prompt changes similar to software development workflows; this supports precise auditing, rollback, and collaborative change management.
* API integration to simplify the deployment of prompts into real-world applications and continuous delivery pipelines.
* Cloud-based or self-hosted deployment with a Docker image.
* Collaborative features like real-time feedback, comment threads, version history browsing, and approval workflows.
* A collection of prompts for various use cases (e.g., chatbots, extractors), that allow users to quickly bootstrap sophisticated applications without reinventing common prompt structures.
### 4. Langfuse
[Langfuse](https://langfuse.com/) is an open source prompt management system that centralizes, versions, and optimizes prompts for LLM-driven applications, and enables experimentation, collaboration, and observability throughout the prompt development lifecycle.
Langfuse offers:
* Versioning not only of the prompt text but the entire context, including logic, model settings, parameters, and structured return types.
* A web console allowing both technical and non-technical users to edit, label (e.g. production, staging), organize, and push prompt updates without touching code or redeploying applications.
* A no-code, type-safe playground that mirrors production behavior, letting teams interactively test prompt versions and model parameters.
* Dynamic referencing of other prompts within a prompt, enabling modular and reusable prompt architectures that support DRY (Don't repeat yourself) prompt engineering directly in the UI.
* Structured evaluation features like datasets for benchmarking, A/B testing workflows, and user feedback capture mechanisms.
## Build Reliable LLM Applications with Full Traceability
Lilypad is a [context engineering platform](/blog/context-engineering-platform) that keeps a full record of what ran, what changed, and who changed it. Lilypad versions everything that matters to make it easier to implement [prompt engineering best practices](/blog/prompt-engineering-best-practices): code, inputs, outputs, and even annotations, so you get a full audit trail, reproducible results, and reliable deployments.
Want to learn more about Lilypad? Check out our code samples on our [website](/docs/lilypad) or on [GitHub](https://github.com/mirascope/lilypad). Lilypad offers first-class support for [Mirascope](https://github.com/mirascope/mirascope), our lightweight toolkit for building agents.
4 Best Prompt Management Systems for LLM Developers in 2025
2025-11-26 · 7 min read · By William Bakst