Prompt orchestration is the process of defining how prompts are used together, whether in a sequence, with conditions, or broken into smaller parts, to help the LLM complete complex tasks. Instead of trying to do everything in one go, prompt orchestration lets the AI solve problems step by step.
This helps the model stay on track during longer tasks, to use outside information, and to remember parts from earlier steps. For example, a customer service chatbot might use retry logic and escalation when an LLM fails to resolve an issue. If the first answer isn’t good, it could ask another LLM to try it again with a better prompt.
Prompt orchestration helps fix common problems with language models:
* Most real-world tasks require multiple steps, like researching, planning, and decision making, which a single prompt generally doesn’t handle reliably.
* With single prompts, it’s harder to check for mistakes mid-process, so if a model gets something wrong early, an error can flow into steps that follow.
* Large language models are stateless but complex tasks involve remembering things across steps and even conversations, which usually requires external systems or workflows.
To handle these challenges, we built [Mirascope](/docs/mirascope) and [Lilypad](/docs/lilypad) to help developers build structured, modular, and traceable LLM workflows, where each step can be validated, retried, and changed independently as part of a reliable, state-aware system.
In this article, we cover key techniques, problems, and best practices for prompt orchestration, illustrating these with examples from Mirascope and Lilypad.
## Key Techniques of Prompt Orchestration
### Prompt Chaining
This is a foundational technique where you break a bigger task into a sequence of smaller, focused LLM calls. Instead of asking one long prompt to do everything, you create a series of prompts, each focused on one part of the task.
For example, you might:
* First ask the model to summarize a text.
* Then take that summary and ask it to rewrite it in a different tone.
* Finally, send the rewritten version to a prompt that fact-checks the details.
Each step uses the result from the previous one. This creates a clear pipeline where the output from one prompt becomes input for the next.
[Prompt chaining](/blog/prompt-chaining) helps in several ways:
* Each step is simpler and easier to understand.
* You can check or edit the results after each step before moving on.
* It works well when tasks are too big for one prompt, like long documents or deep reasoning tasks.
Examples of prompt chaining might be:
* Travel planning: first find flights → then list places to visit → then find hotels.
* Document processing: break a long report into smaller parts → summarize each one → analyze the full set.
* Create research reports: ask a series of questions → feed each answer into the next step to build a full report.
### Dynamic Routing
Here, a language model acts as a classifier or router that inspects a given input and decides which workflow, chain, tool, agent, or model should run next. Instead of using hard-coded “if this, then that” rules, the model uses natural language understanding to choose the right path.
The model can route based on:
* What the user is asking (intent).
* What type of content was received (like a document or a sentence).
* What kind of task needs to be done (like translation, summarization, or search).
This approach is helpful for assistants that serve multiple functions (e.g., summarization, translation, search) and must select the correct response flow based on context. It also works well in systems with multiple prompt chains, where the model has to decide which one to run.
Examples of dynamic routing include:
* Figuring out if a user question should be answered with a summary, a translation, or a web search.
* Sorting customer support messages by topic, like billing, tech issues, or account help, and sending them to the right team or response flow.
* Classifying incoming documents (like resumes, contracts, or invoices), then sending each to a specialized workflow for analysis.
### Centralized Orchestration
A single “planner” component (usually an LLM prompt or system prompt acting as a controller) decomposes a task and delegates subtasks to downstream “executors” or function-specific workers.
Each executor has one job. For example, one or the other might:
* Search the web
* Summarize documents
* Extract facts from a source
The planner maintains the overall flow: it tracks the current state, handles intermediate results, and manages branching or retries.
This approach differs from simple routing. Routing picks a path and stops. Orchestration, on the other hand, manages the full lifecycle: breaking the task apart, assigning work, passing context between steps, and fixing errors along the way.
This pattern is hierarchical and centrally coordinated, ideal for complex workflows where subcomponents cannot operate independently.
It’s also the only agentic technique in this list. Here, the "agents" are focused units that follow instructions; they don’t act independently, but are always guided by the central planner.
Examples of centralized orchestration:
* A research assistant that breaks a big research project into steps: planning, gathering sources, summarizing, and combining results, with each handled by a different helper.
* A grant proposal writer that assigns each section (problem, background, solution, budget) to a different executor, while the planner keeps the writing consistent and on track.
* A fact-checked content creator, where one agent drafts the article, another fact-checks the claims, and a third adjusts the tone. The orchestrator then brings all these together into a final article.
### Parallel Execution
In parallel execution, a task is split into smaller, independent parts that can be executed simultaneously across multiple LLM calls or workers. Because they don’t depend on each other, they can be run concurrently to improve throughput, efficiency, or latency.
Once all the parts are done, a separate synthesis step merges the outputs into a final combined result. This technique is strictly about concurrency, not planning, routing, or agent role assignment.
Examples of parallel execution include:
* Processing multiple product reviews at the same time to find the overall sentiment, then combining the results into a single summary.
* Translating the same article into several languages at once, then bundling all the translations into one output.
* Summarizing different parts of a long report in parallel, then combining those summaries into a clear, high-level overview.
### Conditional Branching
This technique uses logic gates, based on user inputs, LLM-generated classifications, or intermediate outputs, to determine which path a workflow should follow.
Here’s how it works:
* After a step finishes, the system checks certain conditions, like user input, model confidence, or analysis results.
* Based on what it finds, it chooses one of several possible next steps. This creates a kind of decision tree or state machine.
* The logic can be **explicit** (like asking the LLM “Does this contain personal information?”) or **implicit** (like checking if a confidence score is too low).
This is different from routing, which knows in advance to send the information down a certain path before the workflow begins. Such branching (which happens during the process) enables adaptive behavior, where the system can reconfigure itself based on context or feedback rather than following a static sequence.
Common use cases include:
* Customer support bots that escalate issues only if the first solution fails.
* Feedback analysis systems that respond differently depending on whether input is positive, negative, or neutral.
* Content review tools that send drafts back for improvement if they’re not good enough yet.
Examples:
* Check if a message includes sensitive info. If yes, send it through a redaction step before continuing.
* Analyze user feedback for tone. If it’s negative, trigger an apology message. If it’s positive, thank the user.
* Review a generated draft. If it’s incomplete or unclear, run a revision step; otherwise, move on to formatting and delivery.
## Challenges of Prompt Orchestration
While prompt orchestration makes complex AI workflows possible, it also introduces its own set of challenges. Each step adds complexity, and managing logic, state, and errors across prompts can be difficult. In this section, we’ll break down some of the most common obstacles developers face.
### Errors Introduced Early in a Chain Are Hard to Trace and Can Propagate Silently
As we’ve mentioned before, if something goes wrong early in a chain, that mistake can get passed along to the next step.
Because workflows can be complex, they need regular checking. If the final answer looks wrong, developers often have to work backward to figure out where things broke. This can be time-consuming and frustrating, especially when the system doesn’t show clearly how each step worked.
Many orchestration frameworks and LLM workflows like LangChain and LlamaIndex lack built-in inspection or [LLM monitoring tools](/blog/llm-monitoring-tools), making it difficult to pinpoint where a breakdown occurred when the final output is incorrect or unexpected. Without step-by-step visibility into how inputs and outputs evolve across the chain, developers are left guessing where things went wrong.
It can get even harder when the system doesn't separate steps clearly. Without that separation, it’s difficult to add checks, retries, or fixes without reworking the entire chain.
If you don’t check the outputs along the way, using things like structured responses, validators, or confidence scores, you only find out there’s a problem at the end of a workflow. And the longer the chain is, or the more agents, tools, or branches it includes, the harder it is to debug.
That’s why good prompt orchestration isn’t just about linking steps together but also about building checkpoints that catch errors early, so you can fix or rerun them before they affect the rest of the workflow.
### Orchestrating Across Models and APIs Increases Complexity and Duplication
When orchestration isn’t planned carefully, or when everything is done in an ad hoc or monolithic way, systems can quickly become messy and fragile. Prompts, memory, and logic often get tangled together in long workflows that are hard to read, debug, or maintain.
When an LLM must collaborate with external tools or services, like calling APIs, retrieving documents from a vector database, or invoking a calculator function, the orchestration system must handle not just the prompt logic, but also tool selection, function execution, and response merging. This increases surface area for bugs and slows down the iteration cycle.
Things get even trickier when orchestration requires decision-making. For instance, the system might have to:
* Pick between two different models
* Choose a path based on the previous output
* Retry a step if the confidence is low
These decisions require logic rules, fallback options, and if-this-then-that flows, all of which must be designed and updated over time.
Without a shared structure or framework, it’s common for prompt logic to be duplicated across different workflows or services. If you later change a prompt, you may have to update it in several places, raising the risk of bugs, hallucinations, or inconsistent behavior.
Finally, many systems mix together prompt logic, memory handling, and application code in a way that’s hard to separate. This makes parts of the system hard to reuse, test, or improve without breaking something else.
### Lack of Standardized Prompt Structure
Prompts serve as the LLM’s instruction set: they carry not just the task, but the tone, context, and constraints. When prompts are unmanaged, unstructured, or embedded without control, the system loses predictability, maintainability, and long-term scalability.
In most [LLM applications](/blog/llm-applications), prompts are written as one-off strings that are tightly connected to specific parts of the program. This makes them hard to test, reuse, or improve. Unlike well-designed code or APIs, prompts often have no clear structure, versioning, or separation from the rest of the app.
Here are some common problems this creates:
* When prompts are buried in scripts, developers can’t easily test or update them without running the whole system.
* Without a standard format, it’s unclear who manages which prompts or how they’re supposed to work.
* Similar prompts are written again and again in slightly different ways, which leads to inconsistency and unexpected behavior.
* When a prompt causes an issue, it’s hard to know where it came from, what it was supposed to do, or why it failed.
* Even small edits, like changing a word or a constraint, can break downstream steps or introduce bugs, because everything is connected.
To build scalable and reliable AI workflows, prompts need to be given structure, use version control, be written as modular components, and separated from business logic, just like good software architecture.
### Tooling and Version Control Issues
There’s no common system for versioning prompts, which makes it hard to see how prompts have changed or figure out which version caused a specific output. Without version control, it's risky to debug, roll back, or audit your system, especially in production.
In many teams, nobody officially "owns" the prompts, which means no one is responsible for fixing or updating them. This becomes a serious issue in high-risk or regulated settings, where you need to prove that your prompts follow rules and work as expected.
Even small edits can become time-consuming. Updating a prompt might mean searching through multiple files and scripts, making manual changes, and testing each one by hand. In many workflows, it can take over 30 minutes just to update a single prompt safely.
There’s also a lack of observability. Most [LLM frameworks](/blog/llm-frameworks) don’t track prompt history, log outputs, or link prompts to specific results. That means developers can’t easily prove what happened, when, or why, something that’s especially important for enterprise systems and audits.
Without rollback tools, going back to a working version of an [LLM prompt](/blog/llm-prompt) usually means guessing or manually recreating it from memory. And when the same prompt logic is copied into multiple places, small differences can cause the system to behave unpredictably or produce errors that are hard to trace.
Lastly, because prompts often aren’t tested or validated in a structured way in [LLM application development](/blog/llm-application-development), their outputs can change between runs. This unpredictability makes it harder to trust the system, especially when it's powering reports, decisions, or automated workflows.
## 4 Best Practices for Prompt Orchestration
### 1. Design Prompts and Workflows Using a Modular Architecture
A key best practice is to structure your prompt around clear layers that separate concerns like prompt composition, orchestration logic, response interpretation, and memory handling. This reduces coupling and makes workflows easier to debug, extend, and maintain.
You should also treat each prompt like a mini API or self-contained unit that can be reused, tested on its own, and plugged into different parts of your system. This turns prompts from fragile strings into manageable software components.
For example, in Mirascope, you define a prompt using a Python function and implement standard behaviors using separate decorators like `@llm.call`, which cleanly separate prompt logic from orchestration code.
```python{8-10}
from mirascope import llm, prompt_template
from pydantic import BaseModel
class Book(BaseModel):
title: str
author: str
@llm.call(provider="openai", model="gpt-4o-mini", response_model=Book)
@prompt_template("Extract {text}")
def extract_book(text: str): ...
book = extract_book("Pride and Prejudice by Jane Austen")
print(book)
# Output: title='Pride and Prejudice' author='Jane Austen'
```
In this example, the prompt content is separated from the control flow logic with the `@prompt_template` decorator defining how the prompt is written and the `@llm.call` decorator handling how the model is called, including choosing the provider, selecting the model, and managing the response.
The `extract_book` function wraps the prompt logic and is easy to reuse, test, or swap out without touching other parts of the system.
The `response_model=Book` parameter of the call separates how the model’s output is interpreted so instead of writing manual parsing logic, the response is automatically validated and structured using the Pydantic `Book` class.
### 2. Build Prompt Chains with Workflow Control
Break complex tasks into smaller, focused steps using [LLM chaining](/blog/llm-chaining), where the output of one prompt becomes the input for the next. This approach improves clarity, helps isolate errors, and makes debugging easier.
Use routing logic or agent-based delegation to direct different tasks to the right tools, large language models, or workflows based on factors like user intent, task type, or required precision.
For tasks that can run independently, take advantage of parallel processing to improve efficiency. Then, combine the results to produce a final output faster and more reliably.
When detailed reasoning is needed, guide the model to "think aloud" using chain-of-thought prompting. This encourages the LLM to break down its logic step-by-step before producing a final answer.
For example, in Mirascope we can build chains directly using computed fields in Python:
```py
from mirascope.core import llm, prompt_template
@llm.call(provider="openai", model="gpt-4o-mini")
@prompt_template("Name an expert known for insights on {industry} trends")
def select_expert(industry: str): ...
@llm.call(provider="openai", model="gpt-4o-mini")
@prompt_template(
"""
Imagine that you are {expert}, a renowned expert in {industry}.
Provide insights on a key {industry} trend related to {topic}.
"""
)
def identify_trend(industry: str, topic: str) -> openai.OpenAIDynamicConfig:
return {"computed_fields": {"expert": select_expert(industry)}}
print(identify_trend("AI", "automation"))
```
In the code, we generate a B2B trend insights report starting with identifying an expert in a particular industry (`select_expert`), followed by finding insights using that person’s persona (`identify_trend`).
Because `select_expert` is treated as a computed field, it runs automatically before the main prompt is filled in, making the chain both dynamic and declarative. This design keeps each step focused and reusable, while letting orchestration logic happen entirely within standard Python.
### 3. Manage Prompts Like Code Using Versioning, Governance, and Tooling
Use version control to track how prompts change over time, apply semantic versioning, and keep clear documentation of when and why each update was made.
Implement rollback mechanisms using feature flags, performance monitoring, and CI/CD integration. This ensures that if a prompt starts failing or producing bad results, you can quickly revert to a stable version without disrupting your entire pipeline.
Also, adopt orchestration frameworks or SDKs that provide [LLM observability](/blog/llm-observability), logging, and debugging tools. These help you monitor LLM behavior across chains, detect issues early, and gain insight into how your system is actually working in production.
As an example, our prompt engineering framework Lilypad lets you track prompts and monitor LLM behavior when you add the `lilypad.trace` decorator. This automatically captures changes inside a prompt function’s closure, saving a full snapshot of its state with no manual saving required.
Below, `answer_question()` encapsulates both the prompt and model settings, and is wrapped with `@lilypad.trace` in order to capture all changes that might affect the model’s output.
```python{7-13}
from google.genai import Client
import lilypad
lilypad.configure(auto_llm=True)
client = Client()
@lilypad.trace(versioning="automatic")
def answer_question(question: str) -> str | None:
response = client.models.generate_content(
model="gemini-2.0-flash-001",
contents=f"Answer this question: {question}",
)
return response.text
response = answer_question("What is the capital of France?") # automatically versioned
print(response)
# > The capital of France is Paris.
```
Each run is preserved along with its full execution context, making it easy to revisit, compare, or re-run any version at any time. Versioned calls (both their prompts and outputs) also appear directly in the Lilypad UI (shown below), giving you a clear view into how prompts behave over time.
For tracing, Lilypad instruments LLM outputs using the [OpenTelemetry GenAI specification](https://opentelemetry.io/), which records not just the output but also the surrounding context, messages, warnings, and rich metadata to give a complete picture of each interaction.
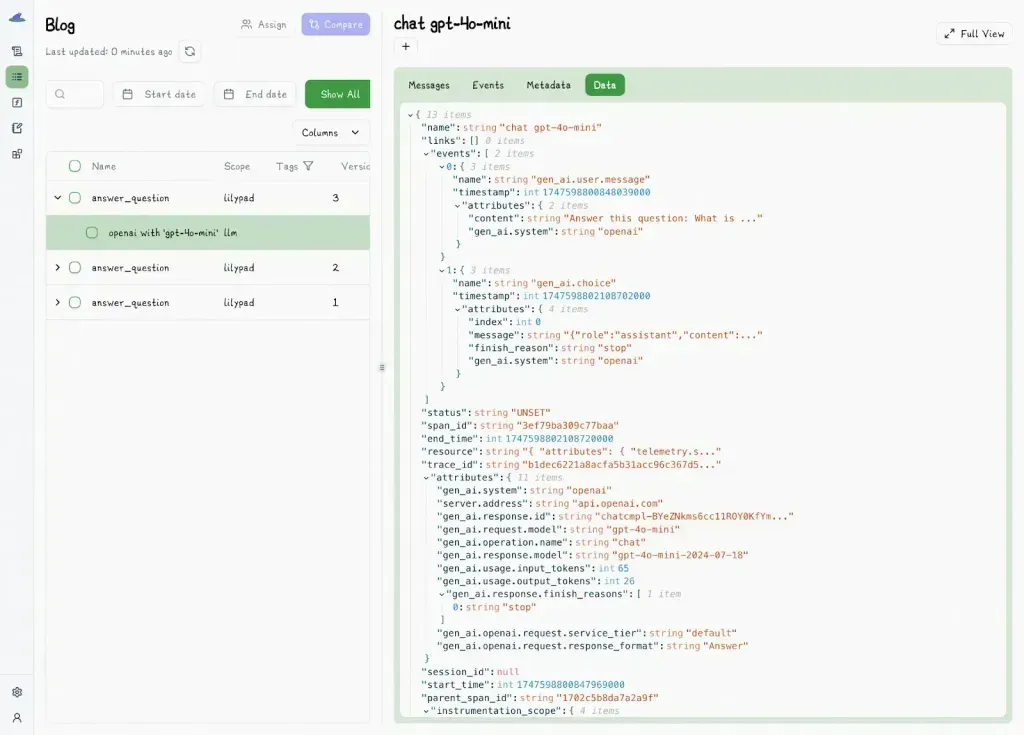
### 4. Implement Ongoing Quality Control, Feedback Loops, and Testing
Set up a consistent evaluation system that regularly tests prompt outputs using structured feedback loops. Instead of relying on gut feeling or one-time checks, use clear labels, log reasoning behind outputs, and track trends across different prompt versions and model settings.
Follow [prompt engineering best practices](/blog/prompt-engineering-best-practices) by treating it as an ongoing, data-driven process, one that values traceability, repeatability, and measurable improvement. This helps teams catch regressions, validate progress, and build their workflows over time.
* Test each prompt component on its own before adding it to a chain. This makes debugging easier and avoids long sequences of fragile steps.
* Track metrics like accuracy, clarity, coherence, and response time to understand system performance and detect issues.
* Automate evaluations with tools that benchmark prompts and flag issues like drift, hallucinations, or lower output quality after updates.
An example of operationalizing this kind of structured, version-aware evaluation is using Lilypad’s tooling for annotating traces, comparing prompt versions, and feeding real-world feedback directly into your [prompt optimization](/blog/prompt-optimization) loop.
Instead of relying on complex scoring systems or pre-made datasets, Lilypad uses a simple pass or fail system tied to specific traces. Every time you run a prompt, Lilypad automatically records the input, output, and settings. You can then label each result as a success or failure, and add comments explaining why, which creates a running history of what works and what doesn’t.
Because annotations are tied to versioned traces, you can catch regressions quickly, spot improvements over time, and build a high-quality dataset from real-world examples. This also makes it easier for teammates to review changes in context, helping everyone stay on the same page.
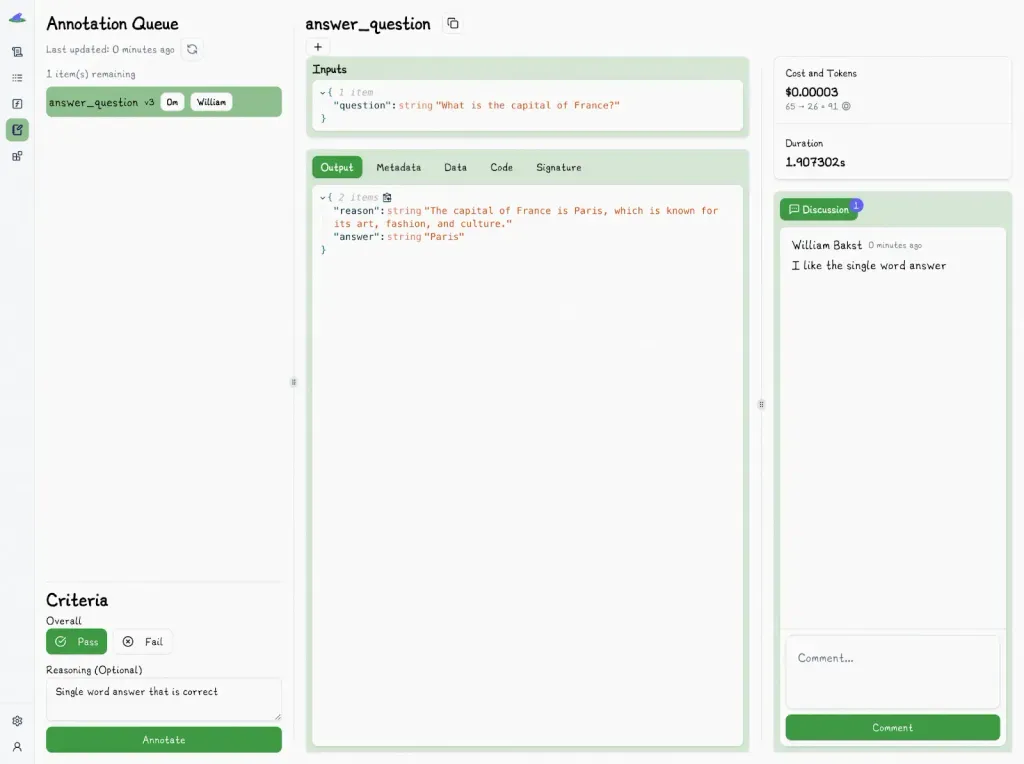
Unlike other systems that require you to create test datasets up front, Lilypad lets you evaluate as you go. You don’t need to stop everything to define your test set before you know what a “good” answer looks like. This lightweight, ongoing approach is especially helpful during early development when things are changing quickly.
Eventually, as your dataset of labeled traces grows, you can use it to train or validate automatic evaluators, like [LLM-as-judge](/blog/llm-as-judge). While this feature is still in progress, we recommend keeping a human in the loop, especially for tricky edge cases, to ensure your evaluations reflect real-world quality standards.
## Take Control of Your AI Workflow with Structured Orchestration
Stop relying on hardcoded prompts. Mirascope and Lilypad help you rapidly iterate, test, and optimize your prompt chains with version control, [LLM evaluation](/blog/llm-evaluation) loops, and modular design patterns that let your AI system learn and evolve over time.
Want to learn more? Find Mirascope’s code samples in our [docs](/docs/mirascope) and on [GitHub](https://github.com/mirascope/mirascope). You can also find code samples for [Lilypad](/docs/lilypad) on [GitHub](https://github.com/mirascope/lilypad).
Prompt Orchestration: Techniques, Challenges, and Best Practices
2025-11-26 · 11 min read · By William Bakst