Prompt testing allows developers to verify how an LLM responds to different prompts, inputs, and scenarios, helping ensure its behavior is accurate, consistent, and aligned with expectations. Over time, this improves reliability by identifying which prompts, instructions, or model settings produce the most desirable outcomes.
But testing prompts isn’t like testing regular code. Traditional techniques like unit tests and test-driven development assume deterministic outputs. LLMs, by contrast, are probabilistic: their responses can vary between runs, even with identical inputs. And while software tests often boil down to binary pass or fail outcomes, prompt evaluations tend to involve degrees of quality, requiring fuzzier scoring systems like 1–5 scales or qualitative review.
We built [Lilypad](/docs/lilypad), our open source prompt engineering platform, to address the unique challenges of prompt testing. Lilypad treats prompt engineering like software development, capturing not just the prompt and model settings, but the entire execution context that influences LLM outputs.
In this article, we’ll explore four strategies for systematically testing prompts, then highlight three leading platforms that help developers put these into practice.
## 4 Strategies for Testing Prompts
As prompt design goes from individual experimentation to a team effort, informal or ad hoc workflows start to break down. To keep things organized and repeatable, teams need better ways to test and improve prompts through structured, collaborative [prompt optimization](/blog/prompt-optimization).
The four strategies below promote collaborative development to make prompt testing structured and easy to review.
### 1. Capture Full Context to Ensure Reproducibility
Managing the unpredictability of LLM outputs starts with capturing everything that could affect the response, including not just the prompt template itself, but also inputs, model settings, and surrounding code.
Recording all such factors allows you to track progress, compare outcomes over time, and ensure consistency in testing. We recommend a [prompt management tool](/blog/prompt-management-tool) that versions the prompt along with all input arguments (e.g., user query, chat history, response length), pre- and post-processing steps, helper functions or in-scope classes), and any other variables or configurations that influence how the model generates its output.
For example, Lilypad recommends wrapping a prompt and its context in a Python function as a first step to capture the full context of the interaction. When versioned, this lets you rerun identical conditions to reproduce results exactly or, when outputs differ, identify precisely what changed and why.
Lilypad allows you to add the `@lilypad.trace(“versioning="automatic"”)` decorator to turn the function into an effective prompt. This enables automatic versioning and traces all changes made within the function closure, i.e., the prompt itself, model settings, input arguments, any pre-processing code, and others.
```python{7}
from openai import OpenAI
import lilypad
lilypad.configure()
client = OpenAI()
@lilypad.trace(versioning="automatic")
def answer_question(question: str) -> str:
completion = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": question}],
)
return str(completion.choices[0].message.content)
response = answer_question("What is the largest planet in the solar system?")
print(response)
# > The largest planet in the solar system is Jupiter.
```
Every prompt execution becomes a fully traceable event that can be inspected, compared, or rolled back later, letting developers identify exactly how and why an LLM’s behavior changed across versions, and ensuring true reproducibility.
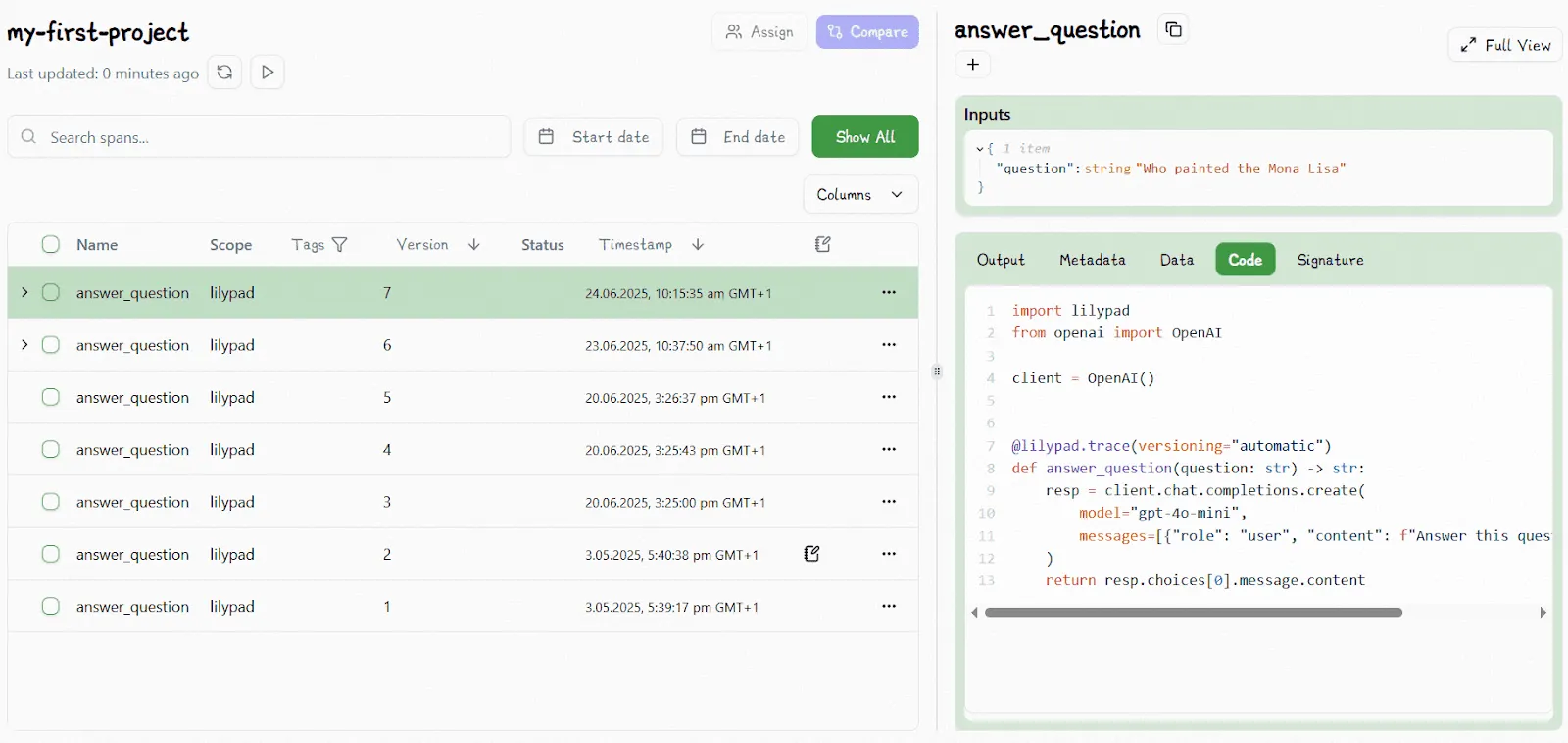
Lilypad displays all versions and traces in its UI (described below), which is a no-code user interface where non-technical SMEs can experiment with different prompts and settings, allowing them to visualize how different versions perform.
For example, all versioned iterations appear in the UI:
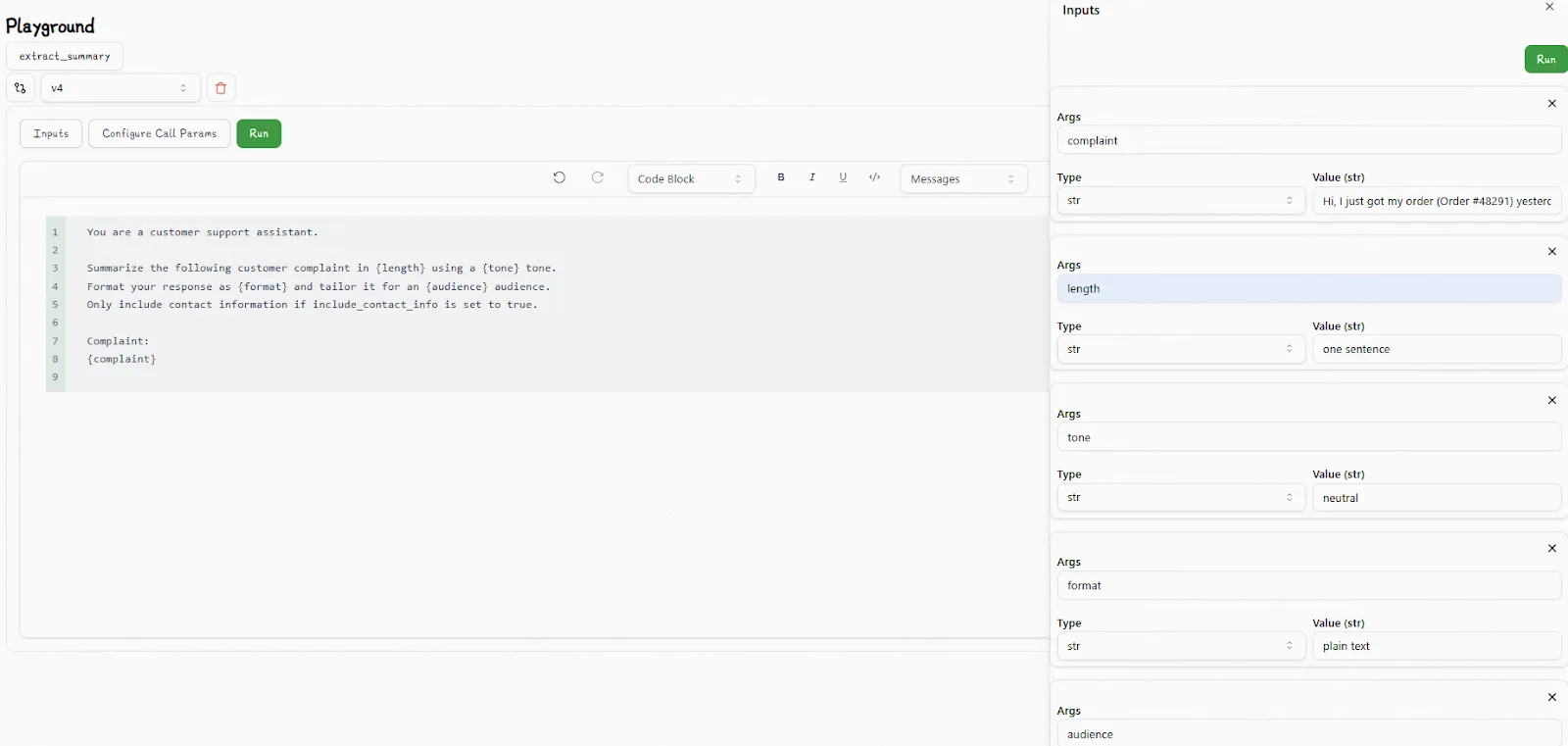
Lilypad also provides a playground that’s a no-code [prompt editor](/blog/prompt-editor) where domain experts can interact with prompt templates using Markdown-based templates that generate type-safe function signatures for input variables based on the underlying Python function.
### 2. Implement Trace-First Observability
You need full visibility into the execution context to debug LLM outputs effectively. In stochastic systems like LLMs, that level of observability isn’t optional but is required. By logging the complete history of each run, you create an inspectable record that helps your team spot regressions and track changes.
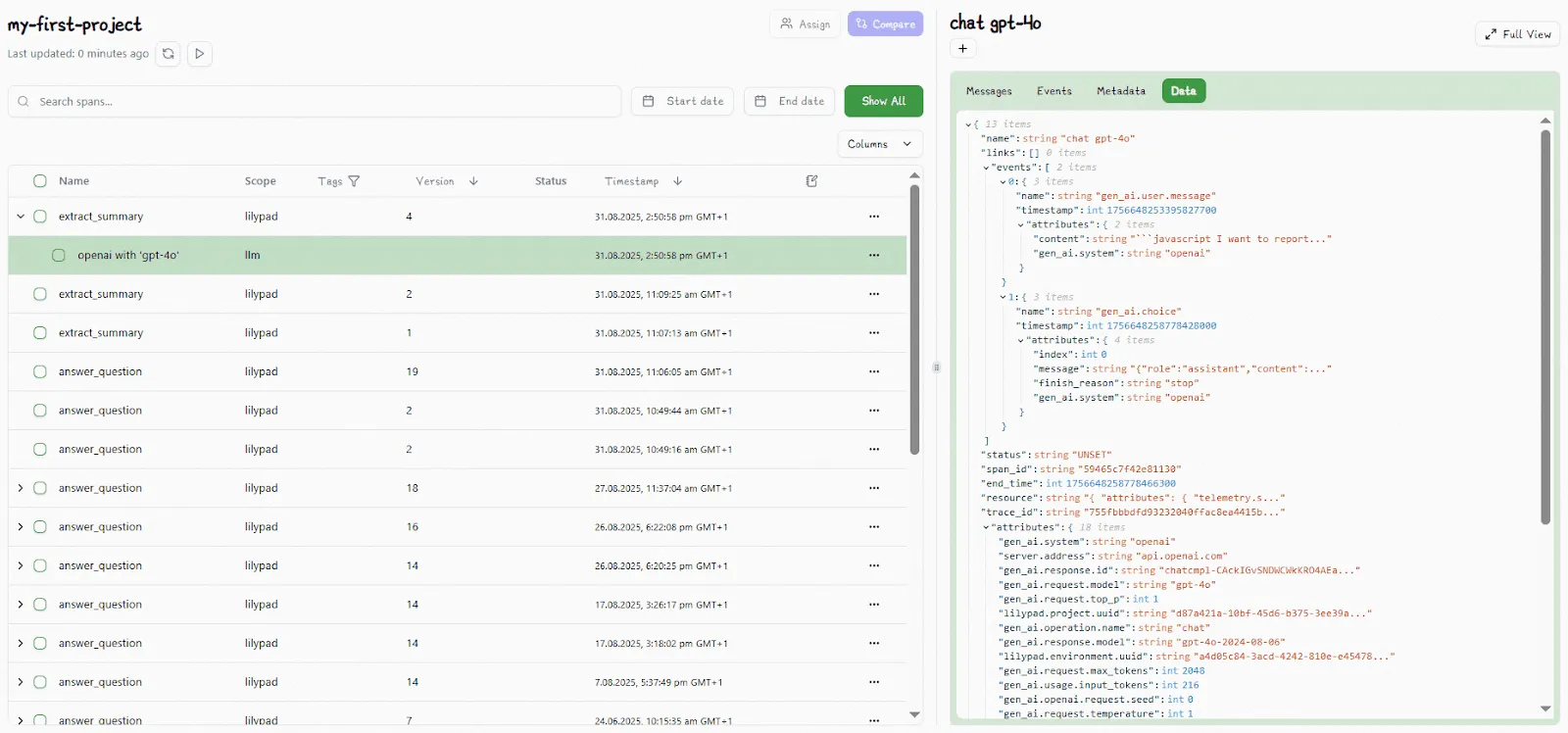
[LLM monitoring tools](/blog/llm-monitoring-tools) like Lilypad turn every prompt run into a versioned trace with full metadata, capturing what was run, how it was configured, and what the model returned. By automatically recording this execution context, Lilypad builds a real-world dataset to give teams the visibility needed to debug or troubleshoot issues, and track changes across versions.
When you add the line `lilypad.configure()`, it traces raw API requests to the model, capturing an API-level call footprint that’s represented as a detailed span, which includes input and output tokens, costs, and model metadata. Traces are instrumented using the [OpenTelemetry Gen AI spec](https://opentelemetry.io/).
Adding the `@lilypad.trace` decorator to a function (that we described earlier) allows you to follow not just the API call, but the full logic that generated it, including the code, prompt logic, inputs, and version, so you can trace every output back to its exact origin.
This provides the full story into the code that was run, what inputs it used, and what output it returned.
### 3. A/B Test Prompts
A/B testing involves setting up test cases to compare the results of different versions of prompts under consistent conditions, including running the same prompt side-by-side on different LLMs like OpenAI, Claude, Gemini, and Llama, and comparing performance to see the differences in responses.
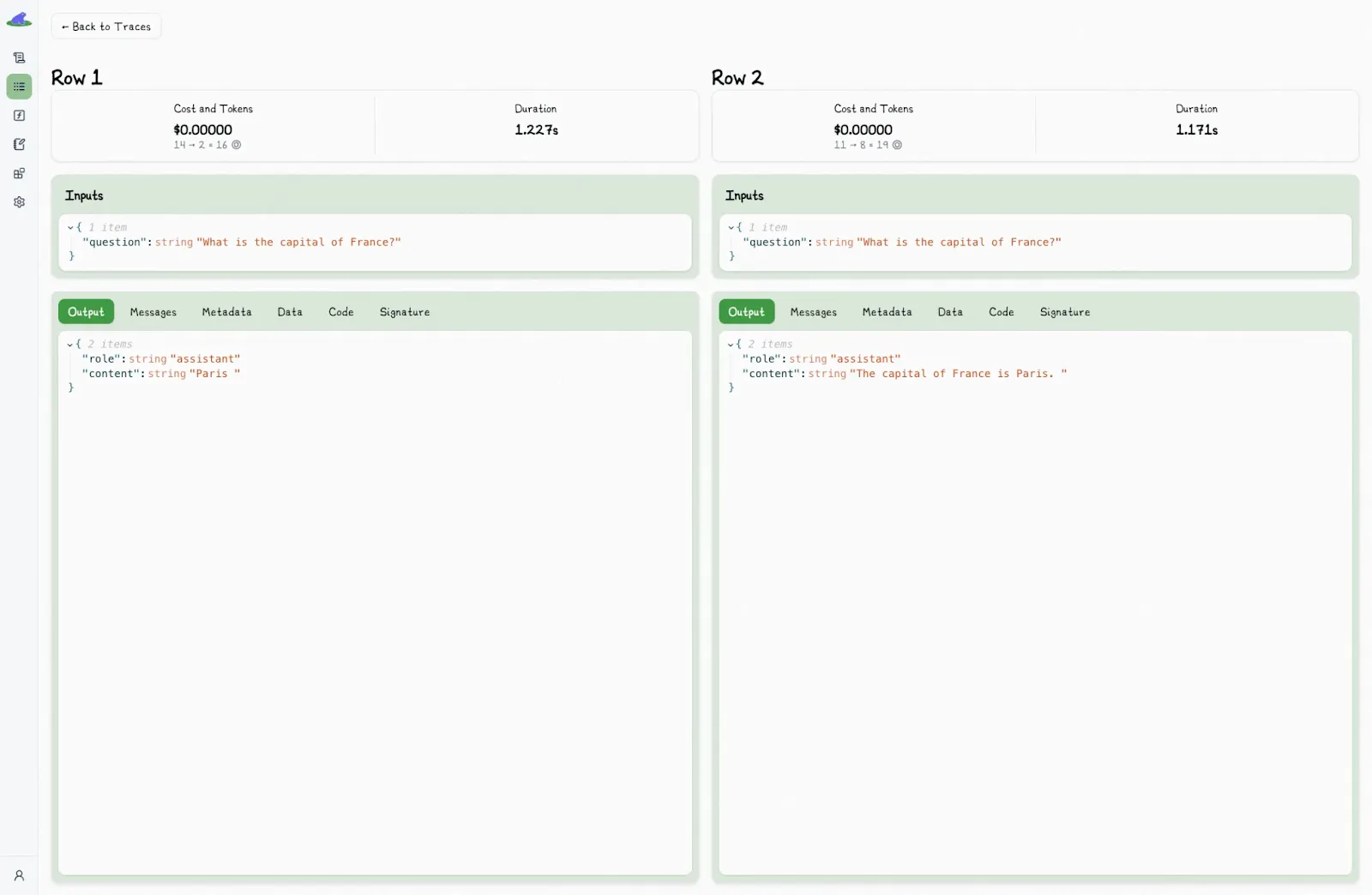
For instance, testing platforms like Lilypad offer functionality for comparing the outputs of different versions of prompts. Lilypad’s UI lets you easily compare different spans by clicking “Compare” to view the underlying code and outputs side-by-side:
Clicking displays a comparison view to see the differences in spans side-by-side:
Downstream, developers can also set up test cases for A/B testing different versions using the `.version(n)`method:
```python
response = answer_question.version(3)("What is the capital of France?")
```
Also adding the line `lilypad sync` in your code ensures that the `.version` method returns type-safe function signatures matching the expected arguments for that version, which you can then run in a sandbox.
### 4. Use Systematic Evaluation Frameworks to Compare Prompt Quality
Evaluations provide the empirical data needed to build trust in your AI models, but only when each result is grounded in reproducible conditions. To make these evaluations meaningful, you need clear, consistent criteria and test cases for what success looks like.
In many workflows and use cases, this involves assigning a success score, such as a value between 0 and 1, to represent the quality of a response. [LLM evaluation](/blog/llm-evaluation) criteria can also be tailored to specific goals and metrics, such as:
* Response quality (e.g., clarity, helpfulness, tone)
* Semantic accuracy (e.g., whether key ideas or phrases are present)
* Technical correctness (e.g., valid JSON structure or schema adherence)
Lilypad was built with this philosophy in mind. Its evaluation system is based on versioned traces that capture not just the model’s output, but the full context that produced it, including inputs, prompt content, code version, parameters, and model settings.
This trace-first approach creates a real-world dataset automatically, rather than relying on predefined datasets that may not reflect current prompt logic or usage scenarios. Because every trace includes full execution context, evaluators can see exactly what code and prompt version generated each result to ensure evaluations are grounded in reality.
When it comes to subjective use cases like summarization or reasoning, where there’s often no single “correct” answer, Lilypad simplifies evaluation by focusing on one core question: is the output acceptable or good enough?
For many use cases, we therefore recommend using simple Pass or Fail judgments instead of numerical scoring metrics (like a 1–5 scale), which often suffer from ambiguity and inconsistency across different reviewers, as they might interpret the scale differently. For instance, what feels like a "3" to one person might feel like a "4" to another.
We find pass or fail metrics to generally be faster, clearer, and more practical to apply, while still guiding effective prompt iteration and refinement.
In Lilypad, teams can use the UI to assign outputs to specific reviewers, turning individual judgments into structured data tied to concrete test cases. The outputs to evaluate appear in structured queues, where reviewers can label them as pass or fail and add reasoning notes.
(To reduce bias, existing annotations remain hidden until the review is complete.)
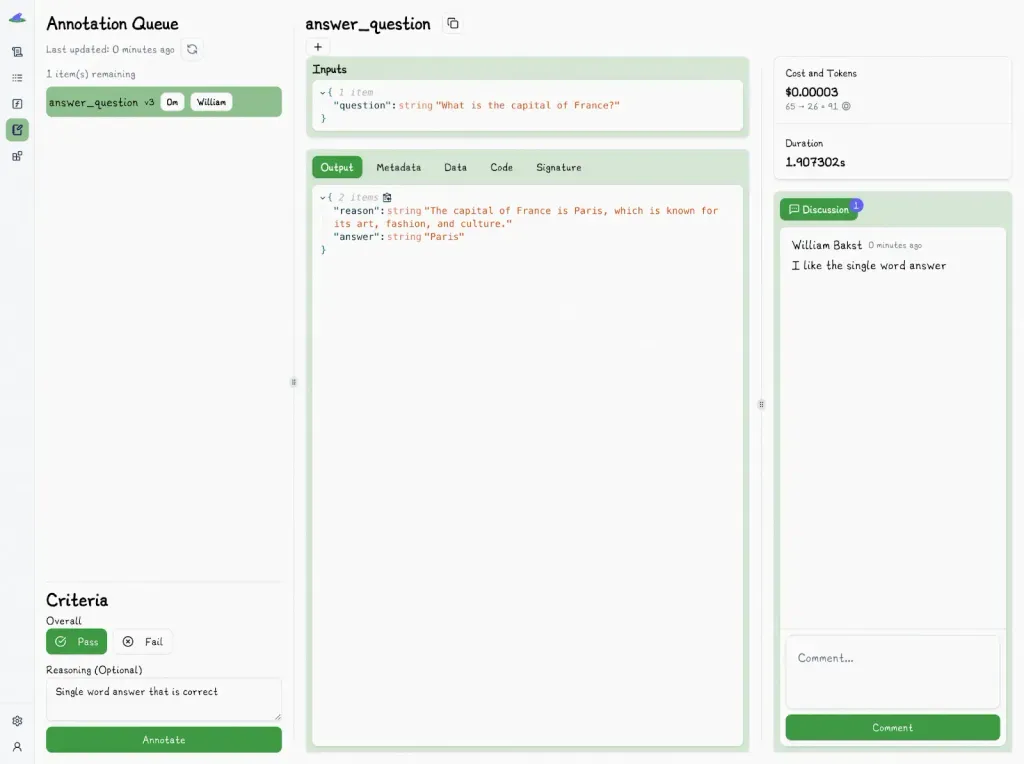
This manual labeling process helps build a high-quality, human-annotated dataset with metrics that strengthen [LLM observability](/blog/llm-observability).
Developers can use the `@lilypad.trace(mode="wrap")` decorator to make the function’s return value annotatable through `.annotate()`. This enables automation use cases like adding evaluations directly in code, running automated checks, or integrating prompt assessments and metrics into CI/CD pipelines, without needing to rely on the UI.
```python{7,19-25}
from google.genai import Client
import lilypad
client = Client()
lilypad.configure()
@lilypad.trace(name="Answer Question", versioning="automatic", mode="wrap")
def answer_question(question: str) -> str | None:
response = client.models.generate_content(
model="gemini-2.0-flash-001",
contents=f"Answer this question: {question}",
)
return response.text
trace: lilypad.Trace[str | None] = answer_question("Who painted the Mona Lisa?")
print(trace.response) # original response
# > The Mona Lisa was painted by the Italian artist Leonardo da Vinci..
annotation = lilypad.Annotation(
label="pass",
reasoning="The answer was correct",
data=None,
type=None,
)
trace.annotate(annotation)
```
In the long term, such a human-labeled dataset can be used to train an [LLM-as-judge](/blog/llm-as-judge) system. The evaluation automation workflow then shifts human effort from manual labeling to the verification or rejection of proposed labels, transforming prompt evaluations into structured test cases.
This approach is typically faster and helps maintain consistency and quality. We still advise spot-checking results to verify these, though.
## Top Open Source Platforms for Prompt Testing
### 1. Lilypad

[Lilypad](/docs/lilypad) is a prompt engineering platform built for software developers that treats prompt engineering as an optimization problem rather than trial-and-error.
As a [context engineering platform](/blog/context-engineering-platform), it captures the full execution context of every LLM call, including the prompt, parameters, model settings, and surrounding code, to ensure reproducibility and traceability in the face of non-deterministic behavior.
With a single decorator, `@lilypad.trace(versioning="automatic")`, Lilypad captures a complete snapshot of the code, logic, parameters, and prompt that produce a given output. Every time a prompt-based function runs, Lilypad automatically versions and traces it, letting you compare changes, track regressions, and analyze performance over time.
Unlike other [LLM tools](/blog/llm-tools) that only version the prompt string, Lilypad versions the entire function closure, meaning that you don’t just know what changed, but why. Each run generates a trace with full metadata, including inputs, outputs, latency, cost, and token usage. You can annotate these traces, compare versions, and run A/B tests on these.
You can also self-host Lilypad on your own infrastructure. It offers a free tier to get started, and paid plans for advanced features for growing teams and enterprises.
### 2. Langfuse
[Langfuse](https://langfuse.com/) is a LLM engineering tool for structured prompt testing and management, and provides an integrated environment for building, iterating, and evaluating prompts across datasets, AI models, and versions, to make AI-powered prompt management a repeatable testing cycle.
You can create prompt templates with variables, link them to datasets, and run controlled experiments to see how prompt versions or AI models perform side by side. This allows detection of regressions when prompts change and makes iteration precise.
As a [prompt testing framework](/blog/prompt-testing-framework), it also offers a prompt playground for running structured test cases across different AI models and variables, and supports side-by-side comparison, structured outputs via JSON schemas, and tool-calling testing.
You can also run prompts against structured datasets of input-output pairs and metrics, and display results for comparison. It allows integration with LLM-as-a-judge evaluators to automatically score outputs for relevance, hallucination, or helpfulness.
Langfuse offers both free and paid tiers for different use cases, depending on whether you use its cloud service (Langfuse Cloud) or self-host the open-source version (free).
### 3. Agenta
[Agenta](https://agenta.ai/) allows you to test, evaluate, and manage prompts for building LLM applications. It provides developers and researchers with AI-powered workflows to experiment with, refine, and monitor prompts systematically, moving from ad hoc “vibe checks” toward reproducible evaluation and lifecycle control.
It versions prompt experiments, treating each variant or branch as a testing path, with every edit stored as an immutable version. This allows use cases for full rollback and traceability. Experiments can be deployed to environments such as [LLM application development](/blog/llm-application-development), staging, or production for live testing while keeping data linked to the originating version.
Each prompt version can be linked with its evaluation results, allowing users to understand the effect of changes and determine the best variant.
Agenta also lets you run A/B tests to compare different prompts or AI models in the same situation to see how the responses change, and collect ratings and datasets to measure how good the results are.
It offers both free and paid pricing models that allow you to scale beyond small projects for generative AI projects. This depends on whether you self-host the open-source version or use Agenta Cloud with managed infrastructure and collaboration features.
## Track, Compare, and Improve Your Prompts
Track every change to your prompts with full context, compare outputs across versions, and annotate results to guide iteration. Lilypad’s approach makes prompt testing for generative AI systems feel like real software development: reproducible, measurable, and collaborative.
Want to learn more about Lilypad? Check out our code samples on our [docs](/docs/lilypad) or on [GitHub](https://github.com/mirascope/lilypad). Lilypad offers first-class support for [Mirascope](https://github.com/mirascope/mirascope), our lightweight toolkit for building agents.
Prompt Testing: Strategies, Tools, and Techniques for LLM Development
2025-11-26 · 10 min read · By William Bakst